#
我一向是不太喜歡給一些東西強(qiáng)加上個(gè)名字。但為了隨波逐流,我還是這樣做了。
在我們的游戲開發(fā)中,通常會(huì)遇到兩個(gè)模塊之間的通信。 回調(diào)估計(jì)是最常用的方式了。 回調(diào)的設(shè)計(jì)思想很簡單,就是兩個(gè)對(duì)象相互注冊(cè),然后在需要的時(shí)候調(diào)用對(duì)方的函數(shù)。
如下:
這樣,當(dāng)A執(zhí)行自己的某些動(dòng)作的時(shí)候,就調(diào)用B的函數(shù),這樣B就會(huì)進(jìn)行自己的更新或是一些處理。
但是,由于兩個(gè)對(duì)象的直接回調(diào),導(dǎo)致了許多不方便之處。特別是當(dāng)A和B的功能需要擴(kuò)展的時(shí)候。例如:現(xiàn)在A在執(zhí)行過程中,需要調(diào)用B中其它的功能函數(shù)。這時(shí)候就不得不修改A和B的接口。然后大家都重新編譯,連接,執(zhí)行。
于是,我們就會(huì)想會(huì)不會(huì)有一種更好的方法來解決這一問題。 大家可以想想,WINDOWS中的通信機(jī)制:通過解析消息類型來進(jìn)行處理。是的,消息回調(diào)的好處就是方便擴(kuò)展。 當(dāng)然我們這里要講的不是像WINDOWS中那樣的消息通信機(jī)制,對(duì)于我們來說,那種做法過繁瑣。
假設(shè)現(xiàn)在是想讓A通知B一些事情。那么,我們可以把B的void DoB();函數(shù)作一點(diǎn)點(diǎn)修改:
同理,當(dāng)B要通知A的時(shí)候,也這樣做就行了。
但是,這樣也很麻煩,關(guān)鍵在于,如果現(xiàn)在寫類A的人并不知道類B的人會(huì)怎么寫,或者說,類B不知道什么時(shí)候要寫。另外,如果我們強(qiáng)制類B要實(shí)現(xiàn)這樣的接口,會(huì)有點(diǎn)不現(xiàn)實(shí)。
此時(shí),我們決定使用一個(gè)中間對(duì)象來連接他們。
這就是我們傳說中的監(jiān)聽器了。 在OGRE或是一些廣泛采用面向?qū)ο笏枷氲脑闯绦蛑校S處可見這樣的模式。
還是假設(shè)是A需要通知B一些事情。那么,可以在A中注冊(cè)這個(gè)對(duì)象,然后調(diào)用它的方法就可以了。
而我們?cè)趯?shí)現(xiàn)B的時(shí)候,除了要實(shí)現(xiàn)B自己的東西以外,還需要將ICallBack派生并實(shí)現(xiàn) void Do(int Msg)函數(shù);
這樣,雙方便很自然地通了信。而寫類A的人根本不需要理會(huì)類B的人會(huì)怎么寫,也不用去管類B會(huì)是什么樣的類名。只要告訴寫類B的人,你需要實(shí)現(xiàn)這個(gè)Callback接口,并且對(duì)應(yīng)的MsgID是干什么用的就OK了。
也許初初的一看,這是吃力不討好的工作。畢竟一個(gè)寫A的人,會(huì)去想那么多事情。 而一個(gè)寫B(tài)的人,還要去實(shí)現(xiàn)一個(gè)Callback類。但是,從可擴(kuò)展性,和降低耦合上來講,的確會(huì)起不少的作用。
而上面的void Do(int MsgID);函數(shù),可以做得更強(qiáng)大一點(diǎn)。
寫成void Do(void* pData); 而這個(gè)pData怎么使用,就要看A和B通信的具體內(nèi)容了。
我正盡力地試著把自己想要說的講清楚,謝謝!
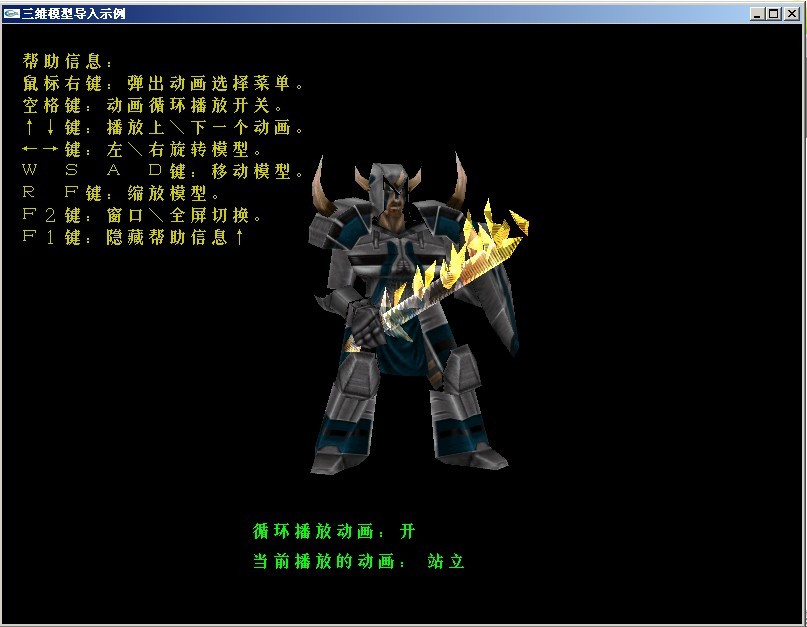
此次畢業(yè)設(shè)計(jì)的內(nèi)容很簡單,就是用OPENGL加載模型并顯示出來就OK了。本想做骨骼動(dòng)畫,或是做個(gè)自己的軟渲染器來渲染模型。看來只有畢業(yè)之后再做了。
此次演示用的是MD2文件格式。我會(huì)在畢業(yè)答辯后(估計(jì)6月份吧)給出源碼。。
雖然示例并未做出什么高深的東西。但有興趣的朋友可以拿來來看看。
另外,誰 能告訴我怎么上傳附件哇,我還是沒找到!
終于找到了兩篇讓人易懂的文章,這兩篇結(jié)合著看,很容易看清計(jì)算過程,沒有想象中的那么復(fù)雜
這是一篇老外的:http://www.terathon.com/code/tangent.html
這是另一個(gè)大哥的:http://jingli83.blog.sohu.com/94746672.html
兩篇結(jié)合看,方顯其效!
有了這兩篇的理解后,再去看其它的關(guān)于切線空間的文章,就不會(huì)再摸不著東南西北了!
SSAO全稱“Screen-Space Ambient Occlusion” (屏幕空間環(huán)境光遮蔽)。其最先運(yùn)用于 Crysis(孤島危機(jī)) 游戲中,通過GPU的 shader實(shí)現(xiàn)
SSAO通過采樣象素周圍的信息,并進(jìn)行簡單的深度值對(duì)比來計(jì)算物體身上環(huán)境光照無法到達(dá)的范圍,從而可以近似地表現(xiàn)出物體身上在環(huán)境光照下產(chǎn)生的輪廓陰影。可以利用“逐象素場(chǎng)景深度計(jì)算”技術(shù)計(jì)算得出的深度值直接參與運(yùn)算。
現(xiàn)在的效果確實(shí)錯(cuò)誤還比較大,應(yīng)該先進(jìn)行簡單的空間劃分(或類似處理)然后計(jì)算。
不過個(gè)人認(rèn)為這種方法只是近似地模擬,效果并不正確,但確實(shí)能增強(qiáng)場(chǎng)景的層次感,讓畫面更細(xì)膩,讓場(chǎng)景細(xì)節(jié)更加明顯。
不同于顯卡驅(qū)動(dòng)中普通的AO選項(xiàng),burnout的SSAO是全動(dòng)態(tài)的,無需預(yù)處理,無loading時(shí)間,無需消耗內(nèi)存,不使用CPU,全由GPU處理,對(duì)GPU有較大的消耗
SSAO默認(rèn)是關(guān)閉的,可以在游戲視頻選項(xiàng)中打開
評(píng)測(cè)
在7950GT下跑,加了ssao后,下降了15%。而且,顯卡性能越低,下降的越厲害。效率消耗主要是在于要多渲染一遍場(chǎng)景到深度以及之后進(jìn)行的ssao處理。這遍可以進(jìn)行優(yōu)化,如果物體的紋理不帶alpha,則可以把他們都合在一批或幾批渲染。至于深度圖的尺寸 ,我采用了與窗口一樣的尺寸,這樣精度高。也可以采用低分辨率,但效果會(huì)有鋸齒,還需要進(jìn)行模糊處理才比較自然。當(dāng)然,如果本來就用了延遲渲染技術(shù),本來就有深度圖了,那就可以直接拿來用了。
與PRT對(duì)比
PRT用于靜態(tài)場(chǎng)景確實(shí)是個(gè)比較好的方案,畢竟可以預(yù)計(jì)算。但是對(duì)于動(dòng)態(tài)的場(chǎng)景,還需要?jiǎng)討B(tài)更新。另外,PRT的質(zhì)量依賴于網(wǎng)格的細(xì)分程度,要是模型太簡,則效果也糟糕。
因此 ,PRT對(duì)于虛擬現(xiàn)實(shí)項(xiàng)目里的高樓大廈等場(chǎng)景(這些模型都是很精簡的)來說,就顯得不合適了
目前已發(fā)行的游戲中,運(yùn)用SSAO的游戲有
Crysis(孤島危機(jī))
Burnout(TM) Paradise The Ultimate Box(火爆狂飆5天堂)
帝國:全面戰(zhàn)爭
另外,星際爭霸2的開發(fā)也運(yùn)用到了SSAO
什么是SSAO?
從HL2開始,眾多游戲公司開始對(duì)于如何表現(xiàn)“間接光照”進(jìn)行研究,這些曇花一現(xiàn)的技術(shù)有:
運(yùn)用于HL2的radiosity Normal Maps技術(shù),效果比較垃圾
運(yùn)用于Stalker的GI(?)技術(shù),算法不好,開銷巨大。
初期Crytek準(zhǔn)備運(yùn)用在Crysis上的Photon Mapping(光子映射)技術(shù),開銷同樣比較垃圾,被拋棄。
隨后Crytek又準(zhǔn)備運(yùn)用在Crysis上的Real-Time Ambient Map(實(shí)時(shí)環(huán)境光照貼圖,簡稱RAM),這個(gè)是與之前Stalker使用的技術(shù)比較類似的,也是最接近SSAO的一個(gè)技術(shù)。
不過Crytek不愧為“間接光照”研究上的先鋒,其技術(shù)員對(duì)于RAM進(jìn)行了改進(jìn),新的算法成為了如今的SSAO
SSAO開與關(guān)的區(qū)別所在
SSAO(Screen-Space Ambient Occlusion)是一個(gè)純粹的渲染技術(shù),或者說,是一個(gè)算法。雖然從上文知道是為了實(shí)現(xiàn)“間接光照”的效果,不過從技術(shù)上講,就是一個(gè)對(duì)于AO(Ambient Occlusion環(huán)境光吸收,也就是NV 185.20驅(qū)動(dòng)加入的那個(gè),一個(gè)渲染技術(shù),我們可以在Maya等3D軟件中可以見到)的一個(gè)逼近函數(shù),并且以此為據(jù)進(jìn)行實(shí)時(shí)渲染。
SSAO比起185.20驅(qū)動(dòng)中AO的優(yōu)點(diǎn):
與場(chǎng)景復(fù)雜性無關(guān)
無數(shù)據(jù)預(yù)處理,無loading時(shí)間,無系統(tǒng)內(nèi)存分配
動(dòng)態(tài)渲染
每個(gè)像素工作方式始終一致
無CPU占用,完全通過GPU執(zhí)行
與流行顯卡的管線整合相當(dāng)容易
缺點(diǎn)也是有的:
由于采樣全部在可見點(diǎn)上進(jìn)行的,對(duì)于不可見點(diǎn)的遮擋影響會(huì)有錯(cuò)誤的估算。
顆粒感比較重,需要與動(dòng)態(tài)模糊緊密配合才能取得較好效果。
SSAO屏幕空間環(huán)境光遮蔽的運(yùn)作方式
其實(shí)了解了AO環(huán)境光遮蔽的原理,SSAO(屏幕空間環(huán)境光遮蔽)已經(jīng)可以融會(huì)貫通,SSAO通過采樣像素周圍的信息,并進(jìn)行簡單的深度值對(duì)比來計(jì)算物體身上環(huán)境光照無法到達(dá)的范圍,從而可以近似地表現(xiàn)出物體身上在環(huán)境光照下產(chǎn)生的輪廓陰影。
具體的運(yùn)作方式上,SSAO會(huì)利用GPU計(jì)算出指定像素的空間坐標(biāo),然后以此坐標(biāo)為基點(diǎn),在周圍選擇數(shù)個(gè)采樣點(diǎn)進(jìn)行采樣,然后將采樣點(diǎn)的空間坐標(biāo)投影回屏幕坐標(biāo),對(duì)深度緩沖進(jìn)行采樣,最后得到采樣點(diǎn)的深度值,再進(jìn)行后續(xù)計(jì)算,最終得到一個(gè)遮擋值。
現(xiàn)了較好的全局光照效果")
SSAO實(shí)現(xiàn)了較好的全局光照效果
SSAO屏幕空間環(huán)境光遮蔽實(shí)現(xiàn)了較好的全局光照效果
因?yàn)槭腔谥付臻g的全局計(jì)算模式,因此SSAO實(shí)現(xiàn)效果的優(yōu)劣取決于算法,包括空間的指定范圍和采樣點(diǎn)的選取等等。需要指明的是,不同游戲(引擎)在SSAO的細(xì)節(jié)算法方面可能不盡相同,另外SSAO還會(huì)結(jié)合其它光照技術(shù)共同達(dá)成游戲畫面的渲染,所以SSAO在很多游戲中不會(huì)有專門的開關(guān)選項(xiàng),其最終的表現(xiàn)結(jié)果可能是與其它技術(shù)共同作用的結(jié)果。
轉(zhuǎn)自:
http://www.abc188.com/info/html/wangzhanyunying/jianzhanjingyan/20080417/71683.html
文檔簡介: 提高3D圖像程式的性能是個(gè)很大的課題。圖像程式的優(yōu)化大致能夠分成兩大任務(wù),一是要有好的場(chǎng)景管理程式,能快速剔除不可見多邊形,并根據(jù)對(duì)象距相機(jī)遠(yuǎn)近選擇合適的細(xì)節(jié)(LOD);二是要有好的渲染程式,能快速渲染送入渲染管線的可見多邊形。 我們知道,使用
文檔簡介:
提高3D圖像程式的性能是個(gè)很大的課題。圖像程式的優(yōu)化大致能夠分成兩大任務(wù),一是要有好的場(chǎng)景管理程式,能快速剔除不可見多邊形,并根據(jù)對(duì)象距相機(jī)遠(yuǎn)近選擇合適的細(xì)節(jié)(LOD);二是要有好的渲染程式,能快速渲染送入渲染管線的可見多邊形。
我們知道,使用OpenGL或Direct3D渲染圖像時(shí),首先要配置渲染狀態(tài),渲染狀態(tài)用于控制渲染器的渲染行為。應(yīng)用程式能夠通過改變渲染狀態(tài)來控制OpenGL或Direct3D的渲染行為。比如配置Vertex/Fragment Program、綁定紋理、打開深度測(cè)試、配置霧效等。
改變渲染狀態(tài)對(duì)于顯卡而言是比較耗時(shí)的操作,而假如能合理管理渲染狀態(tài),避免多余的狀態(tài)轉(zhuǎn)換,將明顯提升圖像程式性能。這篇文章將討論渲染狀態(tài)的管理。
文檔目錄:
基本思想
實(shí)際問題
渲染腳本
文檔內(nèi)容:
基本思想
我們考慮一個(gè)典型的游戲場(chǎng)景,包含人、動(dòng)物、植物、建筑、交通工具、武器等。稍微分析一下就會(huì)發(fā)現(xiàn),實(shí)際上場(chǎng)景里很多對(duì)象的渲染狀態(tài)是相同的,比如任何的人和動(dòng)物的渲染狀態(tài)一般都相同,任何的植物渲染狀態(tài)也相同,同樣建筑、交通工具、武器也是如此。我們能夠把具備相同的渲染狀態(tài)的對(duì)象歸為一組,然后分組渲染,對(duì)每組對(duì)象只需要在渲染前配置一次渲染狀態(tài),并且還能夠保存當(dāng)前的渲染狀態(tài),配置渲染狀態(tài)時(shí)只需改變和當(dāng)前狀態(tài)不相同的狀態(tài)。這樣能夠大大減少多余的狀態(tài)轉(zhuǎn)換。下面的代碼段演示了這種方法:
// 渲染狀態(tài)組鏈表,由場(chǎng)景管理程式填充
RenderStateGroupList groupList;
// 當(dāng)前渲染狀態(tài)
RenderState curState;
……
// 遍歷鏈表中的每個(gè)組
RenderStateGroup *group = groupList.GetFirst();
while ( group != NULL )
{
// 配置該組的渲染狀態(tài)
RenderState *state = group->GetRenderState();
state->ApplyRenderState( curState );
// 該渲染狀態(tài)組的對(duì)象鏈表
RenderableObjectList *objList = group->GetRenderableObjectList();
// 遍歷對(duì)象鏈表的每個(gè)對(duì)象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
// 渲染對(duì)象
obj->Render();
obj = objList->GetNext();
}
group = groupList.GetNext();
}
其中RenderState類的ApplyRenderState方法形如:
void RenderState::ApplyRenderState( RenderState &curState )
{
// 深度測(cè)試
if ( depthTest != curState.depthTest )
{
SetDepthTest( depthTest );
curState.depthTest = depthTest;
}
// Alpha測(cè)試
if ( alphaTest != curState.alphaTest )
{
SetAlphaTest( alphaTest );
curState.alphaTest = alphaTest;
}
// 其他渲染狀態(tài)
……
}
這些分組的渲染狀態(tài)一般被稱為Material或Shader。這里Material不同于OpenGL和Direct3D里面用于光照的材質(zhì),Shader也不同于OpenGL里面的Vertex/Fragment Program和Direct3D里面的Vertex/Pixel Shader。而是指封裝了的顯卡渲染圖像需要的狀態(tài)(也包括了OpenGL和Direct3D原來的Material和Shader)。
從字面上看,Material(材質(zhì))更側(cè)重于對(duì)象表面外觀屬性的描述,而Shader(這個(gè)詞實(shí)在不好用中文表示)則有用程式控制對(duì)象表面外觀的含義。由于顯卡可編程管線的引入,渲染狀態(tài)中包含了Vertex/Fragment Program,這些小程式能夠控制物體的渲染,所以我覺得將封裝的渲染狀態(tài)稱為Shader更合適。這篇文章也將稱之為Shader。
上面的代碼段只是簡單的演示了渲染狀態(tài)管理的基本思路,實(shí)際上渲染狀態(tài)的管理需要考慮很多問題。
渲染狀態(tài)管理的問題
消耗時(shí)間問題
改變渲染狀態(tài)時(shí),不同的狀態(tài)消耗的時(shí)間并不相同,甚至在不同條件下改變渲染狀態(tài)消耗的時(shí)間也不相同。比如綁定紋理是個(gè)很耗時(shí)的操作,而當(dāng)紋理已在顯卡的紋理緩存中時(shí),速度就會(huì)很快。而且隨著硬件和軟件的發(fā)展,一些很耗時(shí)的渲染狀態(tài)的消耗時(shí)間可能會(huì)有減少。因此并沒有一個(gè)準(zhǔn)確的消耗時(shí)間的數(shù)據(jù)。
雖然消耗時(shí)間無法量化,情況不同消耗的時(shí)間也不相同,但一般來說下面這些狀態(tài)轉(zhuǎn)換是比較消耗時(shí)間的:
Vertex/Fragment Program模式和固定管線模式的轉(zhuǎn)換(FF,F(xiàn)ixed Function Pipeline)
Vertex/Fragment Program本身程式的轉(zhuǎn)換
改變Vertex/Fragment Program常量
紋理轉(zhuǎn)換
頂點(diǎn)和索引緩存(Vertex & Index Buffers)轉(zhuǎn)換
有時(shí)需要根據(jù)消耗時(shí)間的多少來做折衷,下面將會(huì)碰到這種情況。
渲染狀態(tài)分類
實(shí)際場(chǎng)景中,往往會(huì)出現(xiàn)這樣的情況,一類對(duì)象其他渲染狀態(tài)都相同,只是紋理和頂點(diǎn)、索引數(shù)據(jù)不同。比如場(chǎng)景中的人,只是身材、長相、服裝等不同,也就是說只有紋理、頂點(diǎn)、索引數(shù)據(jù)不同,而其他如Vertex/Fragment Program、深度測(cè)試等渲染狀態(tài)都相同。相反,一般不會(huì)存在紋理和頂點(diǎn)、索引數(shù)據(jù)相同,而其他渲染狀態(tài)不同的情況。我們能夠把紋理、頂點(diǎn)、索引數(shù)據(jù)不歸入到Shader中,這樣場(chǎng)景中任何的人都能夠用一個(gè)Shader來渲染,然后在這個(gè)Shader下對(duì)紋理進(jìn)行分組排序,相同紋理的人放在一起渲染。
多道渲染(Multipass Rendering)
有些比較復(fù)雜的圖像效果,在低檔顯卡上需要渲染多次,每次渲染一種效果,然后用GL_BLEND合成為最終效果。這種方法叫多道渲染Multipass Rendering,渲染一次就是個(gè)pass。比如做逐像素凹凸光照,需要計(jì)算環(huán)境光、漫射光凹凸效果、高光凹凸效果,在NV20顯卡上只需要1個(gè)pass,而在NV10顯卡上則需要3個(gè)pass。Shader應(yīng)該支持多道渲染,即一個(gè)Shader應(yīng)該分別包含每個(gè)pass的渲染狀態(tài)。
不同的pass往往渲染狀態(tài)和紋理都不同,而頂點(diǎn)、索引數(shù)據(jù)是相同的。這帶來一個(gè)問題:是以對(duì)象為單位渲染,一次渲染一個(gè)對(duì)象的任何pass,然后渲染下一個(gè)對(duì)象;還是以pass為單位渲染,第一次渲染任何對(duì)象的第一個(gè)pass,第二次渲染任何對(duì)象的第二個(gè)pass。下面的程式段演示了這兩種方式:
以對(duì)象為單位渲染
// 渲染狀態(tài)組鏈表,由場(chǎng)景管理程式填充
ShaderGroupList groupList;
……
// 遍歷鏈表中的每個(gè)組
ShaderGroup *group = groupList.GetFirst();
while ( group != NULL )
{
Shader *shader = group->GetShader();
RenderableObjectList *objList = group->GetRenderableObjectList();
// 遍歷相同Shader的每個(gè)對(duì)象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
// 獲取shader的pass數(shù)
int iNumPasses = shader->GetPassNum();
for ( int i = 0; i < iNumPasses; i )
{
// 配置shader第i個(gè)pass的渲染狀態(tài)
shader->ApplyPass( i );
// 渲染對(duì)象
obj->Render();
}
obj = objList->GetNext();
}
group = groupList->GetNext();
}
以pass為單位渲染
// 渲染狀態(tài)組鏈表,由場(chǎng)景管理程式填充
ShaderGroupList groupList;
……
for ( int i = 0; i < MAX_PASSES_NUM; i )
{
// 遍歷鏈表中的每個(gè)組
ShaderGroup *group = groupList.GetFirst();
while ( group != NULL )
{
Shader *shader = group->GetShader();
int iNumPasses = shader->GetPassNum();
// 假如shader的pass數(shù)小于循環(huán)次數(shù),跳過此shader
if( i >= iNumPasses )
{
group = groupList->GetNext();
continue;
}
// 配置shader第i個(gè)pass的渲染狀態(tài)
shader->ApplyPass( i );
RenderableObjectList *objList =
group->GetRenderableObjectList();
// 遍歷相同Shader的每個(gè)對(duì)象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
obj->Render();
obj = objList->GetNext();
}
group = groupList->GetNext();
}
}
這兩種方式各有什么優(yōu)缺點(diǎn)呢?
以對(duì)象為單位渲染,渲染一個(gè)對(duì)象的第一個(gè)pass后,馬上緊接著渲染這個(gè)對(duì)象的第二個(gè)pass,而每個(gè)pass的頂點(diǎn)和索引數(shù)據(jù)是相同的,因此第一個(gè)pass將頂點(diǎn)和索引數(shù)據(jù)送入顯卡后,顯卡Cache中已有了這個(gè)對(duì)象頂點(diǎn)和索引數(shù)據(jù),后續(xù)pass不必重新將頂點(diǎn)和索引數(shù)據(jù)拷到顯卡,因此速度會(huì)很快。而問題是每個(gè)pass的渲染狀態(tài)都不同,這使得實(shí)際上每次渲染都要配置新的渲染狀態(tài),會(huì)產(chǎn)生大量的多余渲染狀態(tài)轉(zhuǎn)換。
以pass為單位渲染則正好相反,以Shader分組,相同Shader的對(duì)象一起渲染,能夠只在這組開始時(shí)配置一次渲染狀態(tài),相比以對(duì)象為單位,大大減少了渲染狀態(tài)轉(zhuǎn)換。可是每次渲染的對(duì)象不同,因此每次都要將對(duì)象的頂點(diǎn)和索引數(shù)據(jù)拷貝到顯卡,會(huì)消耗不少時(shí)間。
可見想減少渲染狀態(tài)轉(zhuǎn)換就要頻繁拷貝頂點(diǎn)索引數(shù)據(jù),而想減少拷貝頂點(diǎn)索引數(shù)據(jù)又不得不增加渲染狀態(tài)轉(zhuǎn)換。魚和熊掌不可兼得 :-(
由于硬件條件和場(chǎng)景數(shù)據(jù)的情況比較復(fù)雜,具體哪種方法效率較高并沒有定式,兩種方法都有人使用,具體選用那種方法需要在實(shí)際環(huán)境測(cè)試后才能知道。
多光源問題
待續(xù)……
陰影問題
待續(xù)……
渲染腳本
現(xiàn)在很多圖像程式都會(huì)自己定義一種腳本文檔來描述Shader。
比如較早的OGRE(Object-oriented Graphics Rendering Engine,面向?qū)ο髨D像渲染引擎)的Material腳本,Quake3的Shader腳本,連同剛問世不久的Direct3D的Effect File,nVIDIA的CgFX腳本(文檔格式和Direct3D Effect File兼容),ATI RenderMonkey使用的xml格式的腳本。OGRE Material和Quake3 Shader這兩種腳本比較有歷史了,不支持可編程渲染管線。而后面三種比較新的腳本都支持可編程渲染管線。
腳本 特性 范例
OGRE Material 封裝各種渲染狀態(tài),不支持可編程渲染管線 >>>>
Quake3 Shader 封裝渲染狀態(tài),支持一些特效,不支持可編程渲染管線 >>>>
Direct3D Effect File 封裝渲染狀態(tài),支持multipass,支持可編程渲染管線 >>>>
nVIDIA CgFX腳本 封裝渲染狀態(tài),支持multipass,支持可編程渲染管線 >>>>
ATI RenderMonkey腳本 封裝渲染狀態(tài),支持multipass,支持可編程渲染管線 >>>>
使用腳本來控制渲染有很多好處:
能夠很方便的修改一個(gè)物體的外觀而不需重新編寫或編譯程式
能夠用外圍工具以所見即所得的方式來創(chuàng)建、修改腳本文檔(類似ATI RenderMonkey的工作方式),便于美工、關(guān)卡設(shè)計(jì)人員設(shè)定對(duì)象外觀,建立外圍工具和圖像引擎的聯(lián)系
能夠在渲染時(shí)將相同外觀屬性及渲染狀態(tài)的對(duì)象(也就是Shader相同的對(duì)象)歸為一組,然后分組渲染,對(duì)每組對(duì)象只需要在渲染前配置一次渲染狀態(tài),大大減少了多余的狀態(tài)轉(zhuǎn)換