在定義了架構(gòu)愿景之后�,團(tuán)隊(duì)中的所有人員應(yīng)該對(duì)待開(kāi)發(fā)的軟件有一定的了解了����。但是,面對(duì)一個(gè)龐大的軟件系統(tǒng),接下來(lái)要做些什么呢����?分而治之的思想是計(jì)算機(jī)領(lǐng)域非常重要的思想���,因此我們也從這里開(kāi)始入手�。要進(jìn)行應(yīng)用軟件的設(shè)計(jì)��,分層是非常重要的思想����,掌握好分層的思想���,設(shè)計(jì)出的軟件是可以令人賞心悅目的����。由于這一章的重要性和特殊性,本章的內(nèi)容分為上下兩節(jié)�,并不采取模式描述語(yǔ)言的方式。
分層只是將系統(tǒng)進(jìn)行有效組織的方式。
本章特別針對(duì)于企業(yè)應(yīng)用進(jìn)行討論,但其中大部分的內(nèi)容都可以應(yīng)用在其它的系統(tǒng)中,或?yàn)槠渌南到y(tǒng)所參考。
在企業(yè)應(yīng)用中����,有兩個(gè)非常重要的概念:業(yè)務(wù)邏輯和持久性����?����?梢哉f(shuō)��,企業(yè)應(yīng)用是圍繞著業(yè)務(wù)邏輯進(jìn)行開(kāi)展的。例如報(bào)銷(xiāo)����、下訂單�、貨品入庫(kù)等都是業(yè)務(wù)邏輯�����。從業(yè)務(wù)邏輯的底層實(shí)現(xiàn)來(lái)看����,業(yè)務(wù)邏輯其實(shí)是對(duì)業(yè)務(wù)實(shí)體進(jìn)行組織的過(guò)程��。這一點(diǎn)對(duì)于面向?qū)ο蟮南到y(tǒng)才成立��,因?yàn)樵诿嫦驅(qū)ο蟮南到y(tǒng)中,識(shí)別業(yè)務(wù)實(shí)體,并制定業(yè)務(wù)實(shí)體的行為是非?����;A(chǔ)的工作,而不同的業(yè)務(wù)實(shí)體的組合就形成了業(yè)務(wù)邏輯。
還有另一個(gè)重要的概念是持久性。企業(yè)應(yīng)用中大部分的數(shù)據(jù)都是需要可持久化的����。因此,基礎(chǔ)組織支持持久性就顯得非常的重要�。目前最為通行的支持持久性的機(jī)制是數(shù)據(jù)庫(kù)��,尤其是關(guān)系性數(shù)據(jù)庫(kù)-RDBMS。
除此之外����,在企業(yè)應(yīng)用中還有其它的重要概念����,例如人機(jī)交互����。
為了能夠更有效的對(duì)企業(yè)中的各種邏輯進(jìn)行組織,我們使用層技術(shù)來(lái)實(shí)現(xiàn)企業(yè)應(yīng)用��。層技術(shù)在計(jì)算機(jī)領(lǐng)域中有著悠久的歷史��,計(jì)算機(jī)的實(shí)現(xiàn)中就引用了分層的概念�。TCP/IP的七層協(xié)議棧也是典型的分層的概念���。分層的優(yōu)勢(shì)在于:
上層的邏輯不需要了解所有的底層邏輯���,它只需要了解和它鄰接的那一層的細(xì)節(jié)�����。我們知道TCP/IP協(xié)議棧就是通過(guò)不同的層對(duì)數(shù)據(jù)進(jìn)行層層封包的��,不同層間的耦合度明顯降低。通過(guò)嚴(yán)格的區(qū)分層次���,大大降低了層間的耦合度��。
某一層次的下級(jí)層可以有不同的實(shí)現(xiàn)��。例如同樣的編程語(yǔ)言可以在不同的操作系統(tǒng)和不同的機(jī)器中運(yùn)行。
和第三條類(lèi)似的���,同一個(gè)層次可以支持不同的上級(jí)層。TCP協(xié)議可以支持FTP�、HTTP等應(yīng)用層協(xié)議��。
綜合上面的考慮,我們把企業(yè)應(yīng)用分為多個(gè)層次��。企業(yè)應(yīng)用到底應(yīng)該分為幾種層次����,目前還沒(méi)有統(tǒng)一的意見(jiàn)。
在前些年的軟件開(kāi)發(fā)中,兩層結(jié)構(gòu)占有很重要的位置。例如在銀行中應(yīng)用很廣的大型主機(jī)/終端方式,以及Client/Server方式�����。兩層的體系結(jié)構(gòu)一直到現(xiàn)在還廣泛存在��,但是兩層結(jié)構(gòu)卻有著很多的缺點(diǎn)����,例如客戶(hù)端的維護(hù)成本高����、難以實(shí)現(xiàn)分布式處理。隨著在兩層結(jié)構(gòu)的終端用戶(hù)和后端服務(wù)間加入更多的層次��,多層的結(jié)構(gòu)出現(xiàn)了�����。
經(jīng)典的三層理論將應(yīng)用劃分為三個(gè)層次:
表示層(Presentation Layer)��,用于處理人機(jī)交互��。目前最主流的兩種表示層是Windows格式和WebBrowser格式���。它主要的責(zé)任是處理用戶(hù)請(qǐng)求����,例如鼠標(biāo)點(diǎn)擊、輸入、HTTP請(qǐng)求等。
領(lǐng)域邏輯層(Domain Logic Layer)��,模擬了企業(yè)中的實(shí)際活動(dòng)���,也可以認(rèn)為是企業(yè)活動(dòng)的模型����。
數(shù)據(jù)層(Data source Layer),處理數(shù)據(jù)庫(kù)�、消息系統(tǒng)�����、事務(wù)系統(tǒng)。
在實(shí)際的應(yīng)用中�,三層結(jié)構(gòu)有一些變化�。例如��,在Windows的.NET系統(tǒng)中�����,把應(yīng)用分為三個(gè)層次:表示層(Presentation Layer)、業(yè)務(wù)層(Business Layer)、數(shù)據(jù)訪問(wèn)層(Data Access Layer)����,分別對(duì)應(yīng)于經(jīng)典的三層理論中的三個(gè)層次�。值得一提的是���,.NET系統(tǒng)中表示層可以直接訪問(wèn)數(shù)據(jù)訪問(wèn)層�,即記錄集技術(shù)�。在ADO.NET中,這項(xiàng)技術(shù)已經(jīng)非常成熟�,并通過(guò)表示層中的某些數(shù)據(jù)感知組件�����,實(shí)現(xiàn)非常友好的功能。這種越層訪問(wèn)的技術(shù)通常被認(rèn)為是不被允許的,因?yàn)樗赡軙?huì)破壞層之間的依賴(lài)關(guān)系����。而在Windows平臺(tái)中����,嚴(yán)格遵守準(zhǔn)則就意味著需要大量額外的工作量�����。因此����,我們看到準(zhǔn)則也不是一成不變的�。
在J2EE的環(huán)境中,三層結(jié)構(gòu)演變?yōu)槲鍖拥慕Y(jié)構(gòu)��。在表示層這里����,J2EE將其分為運(yùn)行在客戶(hù)機(jī)上的用戶(hù)層(Client Layer),以及運(yùn)行在服務(wù)端上的Web層(Presentation Layer)����。這樣做的主要理由是Web Server已經(jīng)成為J2EE中非常核心的技術(shù)�,例如JSP和Java Servlet都和它有關(guān)系�。Web層為用戶(hù)層提供表示邏輯�����,并對(duì)用戶(hù)的請(qǐng)求產(chǎn)生回應(yīng)����。
業(yè)務(wù)層(Business Layer)并沒(méi)有發(fā)生變化�,仍然是處理應(yīng)用核心邏輯之處�。而數(shù)據(jù)層則被劃分為兩個(gè)層次:集成層(Integration Layer)和資源層(Resource Layer)�。其中,資源層并非J2EE所關(guān)心的內(nèi)容��,它可能是數(shù)據(jù)庫(kù)或是其它的老系統(tǒng)���,集成層是重要的層次�����,包括事務(wù)處理�����,數(shù)據(jù)庫(kù)映射系統(tǒng)。
實(shí)例
這一章的的組織方式和之前的模式有一些差別��。我們先從一個(gè)例子來(lái)體會(huì)架構(gòu)設(shè)計(jì)中分層的重要性�����。
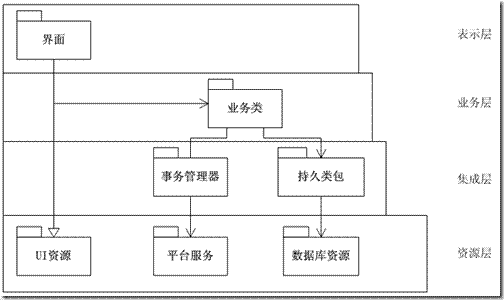
上圖是一個(gè)業(yè)務(wù)處理系統(tǒng)的軟件架構(gòu)圖����。在上圖中�,我們把軟件分為四個(gè)層次���。這種層次結(jié)構(gòu)類(lèi)似于我們前面所談的J2EE的分層����。但是和J2EE不同的是,缺少了一個(gè)Web Server層�����,這是因?yàn)槟壳拔覀冞€沒(méi)有任何對(duì)Web Server的需要�。
在資源層上,我們有三種資源:數(shù)據(jù)庫(kù)�、平臺(tái)服務(wù)�、UI�。數(shù)據(jù)庫(kù)是企業(yè)應(yīng)用的基礎(chǔ),而這里的平臺(tái)服務(wù)指的是操作系統(tǒng)系統(tǒng)或第三方軟件提供的事務(wù)管理器的功能���。值得注意的是,這里的事務(wù)管理器指的并不是數(shù)據(jù)庫(kù)內(nèi)部支持的事務(wù)�,而是指不同的業(yè)務(wù)實(shí)體間事務(wù)處理�,這對(duì)于企業(yè)應(yīng)用有著很重要的意義�。因?yàn)閷?duì)于一個(gè)企業(yè)應(yīng)用來(lái)說(shuō),常常需要處理跨模塊�、跨軟件����、甚至跨平臺(tái)的會(huì)話(Session)�����,這時(shí)候�����,單純的數(shù)據(jù)庫(kù)支持的事務(wù)往往就難以勝任了。這方面的例子包括微軟的MTS和Oracle的DBLink�����。當(dāng)然���,如果說(shuō)�����,在你處理的系統(tǒng)中,可以使用數(shù)據(jù)庫(kù)事務(wù)來(lái)處理大部分的會(huì)話的話,那就可以避免考慮這方面的設(shè)計(jì)了�����。除了典型的事務(wù)管理器���,平臺(tái)還能夠提供其它的服務(wù)。對(duì)于大部分的企業(yè)應(yīng)用來(lái)說(shuō),都是集成了多個(gè)的平臺(tái)服務(wù)���,平臺(tái)服務(wù)對(duì)架構(gòu)的設(shè)計(jì)至關(guān)重要。但是從分層的角度上考慮,上層的設(shè)計(jì)應(yīng)該盡可能的和平臺(tái)無(wú)關(guān)����。和使用平臺(tái)服務(wù)類(lèi)似的��,一般來(lái)說(shuō),企業(yè)應(yīng)用都不會(huì)從頭設(shè)計(jì)界面,大部分情況下都會(huì)使用現(xiàn)有的的UI資源。比如Window平臺(tái)的MFC中的界面部分���。因此,我們把被使用的UI資源也歸到資源層這個(gè)層次上。
資源層的上一層是集成層�����。集成層主要完成兩項(xiàng)工作����,第一項(xiàng)是使用資源層的平臺(tái)服務(wù)��,完成企業(yè)應(yīng)用中的事務(wù)管理���。有些事務(wù)處理機(jī)制已經(jīng)提供了比較好封裝機(jī)制�,直接使用資源層的平臺(tái)服務(wù)就可以了�����。但是對(duì)于大多數(shù)的應(yīng)用來(lái)說(shuō)��,平臺(tái)提供的服務(wù)往往是比較簡(jiǎn)單的,這時(shí)候集成層就派上大用場(chǎng)了���。第二項(xiàng)是對(duì)上一層的對(duì)象提供持久性機(jī)制?����?梢哉f(shuō)��,這是一組起到過(guò)渡作用的對(duì)象�。它實(shí)際上使用的是資源層的數(shù)據(jù)庫(kù)功能�����,并為上一層的對(duì)象提供服務(wù)���。這樣�,上一層的業(yè)務(wù)對(duì)象就不需要直接同數(shù)據(jù)庫(kù)打交道�。對(duì)于那些底層使用關(guān)系型數(shù)據(jù)庫(kù),編程中使用面向?qū)ο蠹夹g(shù)的系統(tǒng)來(lái)說(shuō)���,目前比較常見(jiàn)的處理持久性的做法是對(duì)象/關(guān)系映射(OR Mapping)��。
在這個(gè)層次上�����,我們可以做一些擴(kuò)展,來(lái)分析層的作用�。假設(shè)我們的系統(tǒng)需要處理多個(gè)數(shù)據(jù)庫(kù)�,而不同數(shù)據(jù)庫(kù)之間的處理方式有一定的差異�。這時(shí)候,層的作用就顯示出來(lái)了�。我們?cè)诩蓪又兄С謱?duì)多個(gè)數(shù)據(jù)庫(kù)的處理��,但對(duì)集成層以上的層次提供統(tǒng)一的接口。對(duì)于業(yè)務(wù)層來(lái)說(shuō)�����,它不知道���,也不需要知道數(shù)據(jù)庫(kù)的差別。目前我們自己開(kāi)發(fā)了集成層中的持久類(lèi)�,但是隨著功能的擴(kuò)展���,原有的類(lèi)無(wú)法再支持新增加的功能了�,新的解決方案是購(gòu)買(mǎi)商用程序。為了盡可能的保持對(duì)業(yè)務(wù)層次的影響�,我們?nèi)匀皇褂迷械慕涌?�,但是具體的實(shí)現(xiàn)已經(jīng)不同了,新的代碼是針對(duì)新的商業(yè)程序來(lái)實(shí)現(xiàn)的��。而對(duì)業(yè)務(wù)層來(lái)說(shuō)�����,最理想的狀況是不需要任何的改變���。當(dāng)然現(xiàn)實(shí)中不太可能出現(xiàn)如此美好的情況,但可以肯定的一點(diǎn)是���,引入層次比不引入層次要好的多。
以上列舉的兩個(gè)例子都是很好的解決了耦合度的問(wèn)題�。關(guān)于分層中的耦合度的問(wèn)題���,我們?cè)谙旅孢€會(huì)討論��。
業(yè)務(wù)層的設(shè)計(jì)比較簡(jiǎn)單,暫時(shí)只是把它實(shí)現(xiàn)為一組的業(yè)務(wù)類(lèi)���。類(lèi)似的,表示層的設(shè)計(jì)也沒(méi)有做更多的處理。表示層的類(lèi)是繼承自資源層的�。這是一種處理的方法�,當(dāng)然�����,也可以是使用關(guān)系���,這和具體的實(shí)現(xiàn)環(huán)境和設(shè)計(jì)人員的偏好都有關(guān)系�,并不是唯一的做法�����。在對(duì)軟件的大致架構(gòu)有了一個(gè)初步了解之后��,我們需要進(jìn)一步挖掘需求,來(lái)細(xì)化我們的設(shè)計(jì)�。在前面的設(shè)計(jì)中���,我們對(duì)業(yè)務(wù)層的設(shè)計(jì)過(guò)于粗糙了��。在我們的應(yīng)用中,還存在一個(gè)舊系統(tǒng)�,這個(gè)系統(tǒng)中實(shí)現(xiàn)了應(yīng)用規(guī)則��,從應(yīng)用的角度來(lái)看����,這些規(guī)則目前仍然在使用,但新的系統(tǒng)中會(huì)加入新的規(guī)則�。在新系統(tǒng)啟用后���,舊的系統(tǒng)中的規(guī)則處理仍然需要發(fā)揮它的作用�����,因此不能夠簡(jiǎn)單的把所有的規(guī)則轉(zhuǎn)移到新系統(tǒng)中。(有時(shí)候我們是為了節(jié)省成本而不在新系統(tǒng)中實(shí)現(xiàn)舊系統(tǒng)的邏輯)���。我們第二步的架構(gòu)設(shè)計(jì)的細(xì)化過(guò)程中將會(huì)加入對(duì)新的要求的支持。
在細(xì)化業(yè)務(wù)層的過(guò)程中�����,我們?nèi)匀皇褂脤蛹夹g(shù)�����。這時(shí)候�,我們把原先的業(yè)務(wù)層劃分為兩個(gè)子層�����。對(duì)于大多數(shù)的企業(yè)應(yīng)用來(lái)說(shuō)��,業(yè)務(wù)層往往是最復(fù)雜的����。企業(yè)對(duì)象之間存在著錯(cuò)綜復(fù)雜的聯(lián)系��,企業(yè)的流程則需要用到這些看似獨(dú)立的企業(yè)對(duì)象。我們希望在業(yè)務(wù)層中引入新的機(jī)制����,來(lái)達(dá)到組織業(yè)務(wù)類(lèi)的目的�����。業(yè)務(wù)層的組織需要依賴(lài)于具體的應(yīng)用環(huán)境,金融行業(yè)的應(yīng)用和制造行業(yè)的應(yīng)用就有著巨大的差距���。這里,我們從一般性的設(shè)計(jì)思考的角度出發(fā)來(lái)看待我們的設(shè)計(jì):
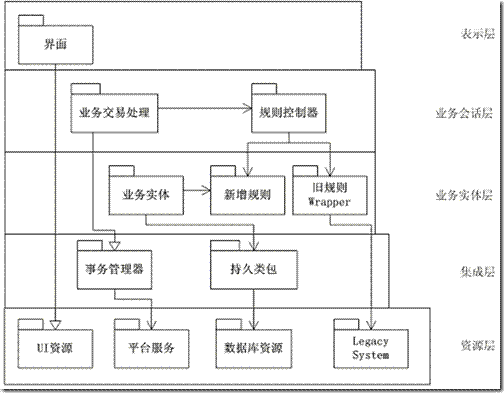
首先���,我們看到,業(yè)務(wù)層被重新組織為兩個(gè)層次��。增加層次的主要考慮是設(shè)計(jì)的重用性���。從我們前面對(duì)層的認(rèn)識(shí)�����,我們知道�。較高的層次可以重用較低的層次�����。因此����,我們把業(yè)務(wù)層中的一部分類(lèi)歸入較低的層次���,以供較高的層次使用�����。降低類(lèi)層次的主要思路是分解行為、識(shí)別共同行為�����、抽取共性���。
在Martin Fowler的分析模式中提供了一種將操作層和知識(shí)層分離的處理方法:
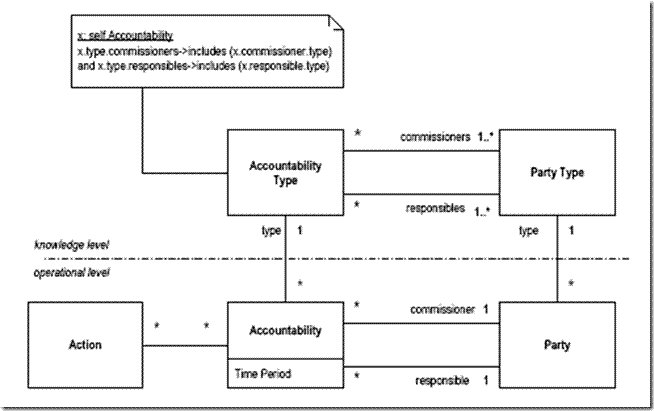
Action�����、Accountability�、Party屬于較高層次的操作層(Operational Layer)���,這一層次的特點(diǎn)是針對(duì)于特定的應(yīng)用���。但是觀察Accountability和Party���,有很多相似的職責(zé)�。也就是說(shuō),我們對(duì)于知識(shí)的處理并不合適���。因此�����,Martin Fowler提出了新的層次――屬于較低層次的知識(shí)層(Knowledge Layer)。操作層中可重用的知識(shí)被整理到知識(shí)層。從而實(shí)現(xiàn)對(duì)操作層的共性抽取。注意到雖然圖中的層次(Level)的概念和層(Layer)有所差別,但是思路是基本一致的。
另一種分層方法是利用繼承:
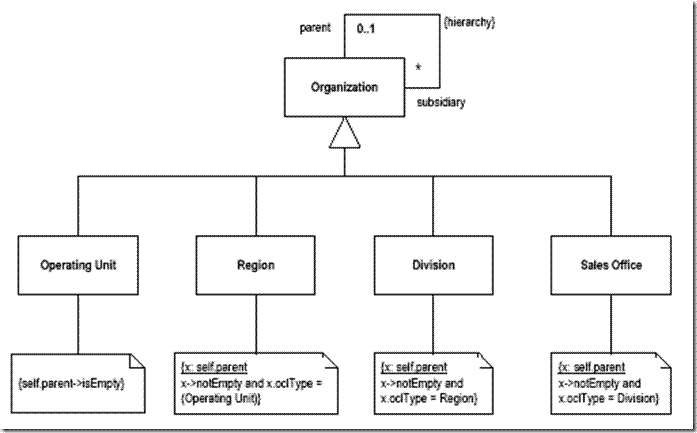
該圖中也是來(lái)自于分析模式一書(shū)。不同的部門(mén)有著差異點(diǎn)和共性,將共性提取到父類(lèi)中是繼承的基本概念����。這時(shí)候我們可以把父類(lèi)看作是較低的層次�����,而把子類(lèi)看作是較高的層次。對(duì)于一組層次結(jié)構(gòu)很深的類(lèi)來(lái)說(shuō)�����,也可以從某一個(gè)水平線上分離層次。
最后一種方法需要分解并抽象對(duì)象的行為��。C++的STL中為不同的數(shù)據(jù)類(lèi)型和不同的容器實(shí)現(xiàn)了Iterator的功能。它的實(shí)現(xiàn)是典型的降低層次的行為���。我們不考慮它對(duì)不同數(shù)據(jù)類(lèi)型的支持,因?yàn)樗褂昧吮容^獨(dú)特的模板(Template)技術(shù),只考慮它對(duì)不同的容器的實(shí)現(xiàn)。首先是對(duì)共性的分析�����,不論是數(shù)組(Array)還是向量(Vector)���,要執(zhí)行遍歷操作���,都需要知道三個(gè)條件:容器的起始點(diǎn)���、容器的長(zhǎng)度�、匹配值�����。這就是一種抽象��。通過(guò)這種方式,就可以統(tǒng)一不同容器的接口。
以上我們討論了細(xì)分層次的好處和實(shí)現(xiàn)策略���。下面我們回到前例中,繼續(xù)討論層中的各個(gè)部件。
業(yè)務(wù)實(shí)體指的是企業(yè)中的一些單獨(dú)的對(duì)象�。例如訂單�����、客戶(hù)、供應(yīng)商等�����。由于業(yè)務(wù)實(shí)體可以被很多的業(yè)務(wù)流程(業(yè)務(wù)會(huì)話)所使用�,因此我們把業(yè)務(wù)實(shí)體放在業(yè)務(wù)實(shí)體層中。企業(yè)中的業(yè)務(wù)實(shí)體大多是需要持久性的���。因此在我們的設(shè)計(jì)中,業(yè)務(wù)實(shí)體將持久性的職責(zé)委托給下一個(gè)層次中的持久性包�����,而不是直接調(diào)用數(shù)據(jù)庫(kù)方法�。另一種常用的方法是使用繼承――業(yè)務(wù)實(shí)體繼承自持久類(lèi)。EJB中的Entity Bean就是典型的業(yè)務(wù)實(shí)體���,它可以支持自動(dòng)的持久性機(jī)制。
在我們的系統(tǒng)中�,規(guī)則是一個(gè)尷尬的存在�����。部分的規(guī)則處于舊系統(tǒng)中���,并使用舊系統(tǒng)的持久性機(jī)制�����。而新系統(tǒng)中有需要支持新的規(guī)則��。對(duì)于上層的用戶(hù)來(lái)說(shuō)�����,并不需要知道新舊系統(tǒng)的規(guī)則。如果我們?cè)谑褂靡?guī)則時(shí)做一個(gè)新舊規(guī)則的判斷并調(diào)用不同的系統(tǒng)函數(shù)���,那就顯得太傻了。我們的設(shè)計(jì)對(duì)上層而言應(yīng)該是透明的�。
所以我們總共設(shè)計(jì)了三個(gè)包來(lái)實(shí)現(xiàn)規(guī)則的處理�����。包裝器包裝了舊系統(tǒng)中的規(guī)則��,這樣做處于幾點(diǎn)考慮:首先�����,舊系統(tǒng)是面向過(guò)程的,因此我們需要用包裝器將函數(shù)(或過(guò)程)封裝到類(lèi)中��。其次���,對(duì)舊系統(tǒng)的使用需要額外的程序(或平臺(tái)服務(wù))的支持����,因此需要單獨(dú)的類(lèi)來(lái)處理�。最后,我們可以使用Adapter模式[GOF 94]將新舊系統(tǒng)不同的接口給統(tǒng)一起來(lái)���,以使他們能夠一起工作。新的規(guī)則類(lèi)實(shí)現(xiàn)了新的規(guī)則����,較好的做法是定義一個(gè)虛協(xié)議�,具體的表現(xiàn)形式可以是虛基類(lèi)或接口��。然后由其子類(lèi)實(shí)現(xiàn)虛協(xié)議�。再結(jié)合前面介紹的把舊規(guī)則的接口轉(zhuǎn)換為新的接口的方法���,就能夠統(tǒng)一規(guī)則接口�。從圖中我們看到,業(yè)務(wù)實(shí)體需要使用規(guī)則���,通過(guò)統(tǒng)一的接口,業(yè)務(wù)實(shí)體就能夠透明的使用新舊兩種規(guī)則���。
在定義了規(guī)則和標(biāo)準(zhǔn)的規(guī)則接口之后,上一層的規(guī)則控制器就可以通過(guò)調(diào)用規(guī)則,來(lái)實(shí)現(xiàn)不同規(guī)則組合��。因此這個(gè)規(guī)則控制器就類(lèi)似于應(yīng)用規(guī)則�。在業(yè)務(wù)交易處理中需要調(diào)用規(guī)則控制器來(lái)實(shí)現(xiàn)部分的功能。
請(qǐng)注意,這里討論的思路雖然非常的簡(jiǎn)單���、清晰,但是現(xiàn)實(shí)中的處理卻沒(méi)有這么容易。因?yàn)闉樾屡f規(guī)則制定統(tǒng)一的接口實(shí)在是太難了���。要能夠使接口在未來(lái)也相對(duì)的穩(wěn)定更是難上加難。而在應(yīng)用已經(jīng)部署之后,對(duì)已發(fā)布的接口的任何一個(gè)小改動(dòng)都意味著很高的成本�。在這個(gè)問(wèn)題上���,并沒(méi)有什么好的策略���,經(jīng)驗(yàn)是最重要的。在實(shí)際中的一個(gè)比較實(shí)用的方法是為接口增加一些額外的參數(shù)。即便可能這個(gè)參數(shù)當(dāng)前并沒(méi)有使用到�����,但是如果為了有可能使用的話��,那還是加上吧�����。舉個(gè)例子,對(duì)于商業(yè)應(yīng)用軟件而言���,數(shù)據(jù)庫(kù)���,或者說(shuō)是關(guān)系數(shù)據(jù)庫(kù)一定是不可缺少的部分�����。大量的操作都需要和數(shù)據(jù)庫(kù)結(jié)合起來(lái),因此,可以考慮在方法中加入一個(gè)數(shù)據(jù)庫(kù)連接字符串的參數(shù)�。雖然這對(duì)于很多方法而言是沒(méi)什么必要的����,但是為將來(lái)的實(shí)踐提供了一個(gè)可擴(kuò)展的空間�����。國(guó)內(nèi)的某個(gè)知名的ERP軟件的設(shè)計(jì)就采用了這種思路���。
本章的主要精力都放在實(shí)例的研究上�����,在有了一個(gè)基本的概念之后���,我們?cè)倩貋?lái)談?wù)劮謱拥囊恍┰瓌t和需要注意的問(wèn)題�。
上篇我們用了大量的篇幅來(lái)觀察了一個(gè)實(shí)際的例子,相信大家已經(jīng)對(duì)分層有了一個(gè)比較具體的概念了���。在這一篇中我們就對(duì)分層在實(shí)踐中可能會(huì)遇到的問(wèn)題做一個(gè)討論。分層在架構(gòu)設(shè)計(jì)中是一種非常常見(jiàn)的��,但是又很不容易用好的技術(shù)。因此我們這里花了很大的氣力來(lái)討論它�����。
由于這是一篇介紹軟件設(shè)計(jì)技術(shù)的文章����,為了盡可能讓更多的人理解,本應(yīng)該盡可能不涉及到過(guò)于具體的技術(shù)或平臺(tái)����。但是這個(gè)目標(biāo)可能很難實(shí)現(xiàn)�,因?yàn)檐浖O(shè)計(jì)是沒(méi)辦法脫離具體的實(shí)現(xiàn)技術(shù)的�。因此本文能夠做到的是盡可能的不涉及具體的編碼細(xì)節(jié)。
何時(shí)使用分層技術(shù)?
分層技術(shù)實(shí)際上是把技術(shù)復(fù)雜化了��。和以往簡(jiǎn)單的CS結(jié)構(gòu)的系統(tǒng)不同����,分層往往需要使用特定的技術(shù)平臺(tái)來(lái)實(shí)現(xiàn)。當(dāng)然�,不使用這些技術(shù)平臺(tái)也是可能的����,但是效果可能就沒(méi)有那么好了���。支持分層技術(shù)的平臺(tái)有很多�,包括目前主流的J2EE和.NET��。甚至在不同廠商的開(kāi)發(fā)平臺(tái)上��,要求也不一樣。使用分層技術(shù)實(shí)現(xiàn)的多層架構(gòu)����,成本要比普通的CS架構(gòu)高得多�����。
這就產(chǎn)生了一個(gè)非常現(xiàn)實(shí)的問(wèn)題-并不是所有的軟件都適合采用分層技術(shù)的����。一般來(lái)說(shuō),小型的軟件使用分層并沒(méi)有太大的意義���,因?yàn)榉謱訉?dǎo)致的成本超過(guò)它所能帶來(lái)的好處。在一般的CS結(jié)構(gòu)中����,可以把界面控制���、邏輯處理和數(shù)據(jù)庫(kù)訪問(wèn)都放在一塊兒�����。這種設(shè)計(jì)方式在純粹的多層主義者看來(lái)簡(jiǎn)直就是十惡不赦。但是對(duì)于小型的軟件而言�,這并不是什么大不了的事情���。因?yàn)閺谋硎緦拥綌?shù)據(jù)層的整套功能都被囊括在一個(gè)功能塊中,同樣能夠?qū)崿F(xiàn)較好的封裝����。而且����,如果結(jié)構(gòu)設(shè)計(jì)的足夠好���,也能夠避免表示層���、業(yè)務(wù)層和數(shù)據(jù)層之間出現(xiàn)過(guò)高的耦合度�����。因此�����,除非確實(shí)需要,不然沒(méi)有必要使用分層技術(shù)����。
尤其在處理一些特殊的項(xiàng)目時(shí)����,嚴(yán)格的區(qū)分三層結(jié)構(gòu)并不理想�。比如在快速開(kāi)發(fā)windows界面的應(yīng)用時(shí),往往會(huì)用到一些對(duì)數(shù)據(jù)庫(kù)敏感的控件����,這種處理方法跨越了三個(gè)層次����,但是卻很實(shí)用���,成本也比較低�����。又比如一些框架,給出了從界面層到數(shù)據(jù)庫(kù)的綜合的解決方案���,和windows的應(yīng)用類(lèi)似,嚴(yán)格的三層技術(shù)也不適用于這種情況�。
如何使用分層技術(shù)�?
從某種意義上來(lái)看���,層其實(shí)是一個(gè)粗粒度的組件�。就像我們使用組件技術(shù)是為了對(duì)系統(tǒng)進(jìn)行一種劃分一樣,層的一個(gè)很大的作用也是如此。其目的是為了系統(tǒng)更容易被理解���,不同的部分能夠被較容易的替換。
使用分層技術(shù)的依據(jù)是軟件開(kāi)發(fā)人員的實(shí)際需要。如果你是在使用某些優(yōu)秀的面向?qū)ο蟮能浖_(kāi)發(fā)平臺(tái)的話��,那它們一般都會(huì)建議(或是強(qiáng)制)你使用某一種分層機(jī)制��。這是你采用分層技術(shù)的一大參考���。
對(duì)于大多數(shù)有一定經(jīng)驗(yàn)的軟件團(tuán)隊(duì)而言�����,一般都會(huì)積累一些軟件開(kāi)發(fā)經(jīng)驗(yàn)����。其中包含了很多在某些特定的領(lǐng)域中使用的基礎(chǔ)的類(lèi)或組件����。這些元素構(gòu)成了一個(gè)系統(tǒng)的通用層次�。這個(gè)層次也是分層時(shí)需要考慮的。例如一些應(yīng)用軟件中使用的一些通用的Currency對(duì)象或是Organization對(duì)象����。分析模式一書(shū)對(duì)此類(lèi)的對(duì)象進(jìn)行了充分細(xì)致的闡述���。這個(gè)層次一般被稱(chēng)為跨領(lǐng)域?qū)樱?span lang="EN-US">cross-domain layer)�,或稱(chēng)為工具層(utility layer)���。
目前的很多軟件都采用了數(shù)據(jù)庫(kù)映射技術(shù)���。數(shù)據(jù)庫(kù)映射層對(duì)于企業(yè)應(yīng)用系統(tǒng)非常的重要�,因此也需要納入考慮之列。數(shù)據(jù)庫(kù)映射技術(shù)用起來(lái)簡(jiǎn)單�����,但是要實(shí)現(xiàn)可不容易�。如果不是非常有必要,盡可能使用現(xiàn)成的框架��,或是采用其中部分的設(shè)計(jì)思路���。試圖構(gòu)建一個(gè)大而全的映射層次的代價(jià)是非常高昂的�����,認(rèn)識(shí)不到這一點(diǎn)會(huì)帶來(lái)很大的麻煩��。數(shù)據(jù)庫(kù)映射技術(shù)的知識(shí),我們?cè)谙挛闹羞€有專(zhuān)門(mén)的篇幅來(lái)討論���。
如何存放數(shù)據(jù)(狀態(tài))�?
在學(xué)習(xí)EJB的過(guò)程中,最先要理解的一定是有狀態(tài)和無(wú)狀態(tài)的概念�?�?梢哉f(shuō),整個(gè)概念是多層體系的核心。為什么這么說(shuō)呢?這里的狀態(tài)指的是類(lèi)的狀態(tài)�,例如類(lèi)的屬性��、變量等。由于狀態(tài)的不同,類(lèi)也表現(xiàn)出差異來(lái)����。而對(duì)于多層結(jié)構(gòu)的軟件���,創(chuàng)建和銷(xiāo)毀一個(gè)類(lèi)的開(kāi)銷(xiāo)是很大的�,如果該軟件支持分布式的話尤為如此�。所以如果系統(tǒng)的不同層次間進(jìn)行頻繁的調(diào)用-創(chuàng)建一個(gè)類(lèi),再銷(xiāo)毀一個(gè)類(lèi)�。這種做法是非常消耗資源的�����。在應(yīng)用系統(tǒng)的設(shè)計(jì)中,一般不單獨(dú)使用COM�,就是這個(gè)原因�����。所以我們很自然的想到了一種經(jīng)典的設(shè)計(jì)-緩沖池。把對(duì)象存放在緩沖池中�����,當(dāng)需要的時(shí)候從池中取出一個(gè),當(dāng)不需要的時(shí)候再把對(duì)象放入池中����。這種設(shè)計(jì)思路能夠大幅度的提高效率�����。但是這對(duì)能夠放在池中的對(duì)象也提出了苛刻的要求-所有的對(duì)象必須是無(wú)差異的�����,也就是無(wú)狀態(tài)的�����。只有這樣才能夠?qū)崿F(xiàn)緩沖池。
一般來(lái)說(shuō)����,對(duì)象緩沖池的技術(shù)是用在中間的業(yè)務(wù)層上的�。既然中間業(yè)務(wù)層上不能夠保留有狀態(tài)��,那就出現(xiàn)了一個(gè)狀態(tài)轉(zhuǎn)移的問(wèn)題�。這里有兩種的選擇�,一種是前移,把狀態(tài)移到用戶(hù)端,最典型的是使用cookie�����。這種選擇一般是由于狀態(tài)和用戶(hù)端有關(guān)�,不需要長(zhǎng)時(shí)間保存。另一種選擇是后移,把狀態(tài)移到數(shù)據(jù)層��,由數(shù)據(jù)庫(kù)來(lái)實(shí)現(xiàn)持久性狀態(tài)�����,當(dāng)需要時(shí)才把狀態(tài)提交給業(yè)務(wù)層�。這種方式是企業(yè)應(yīng)用軟件中采用最多的����,但是也增大了數(shù)據(jù)庫(kù)的負(fù)擔(dān)�。
處理好接口
由于使用了分層技術(shù),因此原先那種在CS結(jié)構(gòu)中類(lèi)之間存在復(fù)雜關(guān)系就有必要重新評(píng)估了。一般層間的耦合度不宜過(guò)大��。因此需要慎重的設(shè)計(jì)層之間的類(lèi)調(diào)用方式�。一些分布式軟件體系(例如J2EE)對(duì)層之間的調(diào)用方式以接口的形式給出了要求。同時(shí),不同層之間僅僅知道目標(biāo)層的接口�����,而不知道目標(biāo)層的具體實(shí)現(xiàn)���。EJB的home接口和remote接口就是這樣�。在COM+體系中,也需要在設(shè)計(jì)類(lèi)的同時(shí)����,把接口公布出來(lái)�����,以供客戶(hù)方使用。
在設(shè)計(jì)層間的接口時(shí)����,除了考慮開(kāi)發(fā)平臺(tái)的約束之外����,還有一點(diǎn)是開(kāi)發(fā)人員必須考慮的�。那就是業(yè)務(wù)需要。業(yè)務(wù)層中往往有非常多的對(duì)象和方法���,它們之間的關(guān)系也非常的負(fù)責(zé),但對(duì)于其它的層次來(lái)說(shuō)�,它并不關(guān)心這些細(xì)節(jié)�����。因此業(yè)務(wù)層公布的接口必須要簡(jiǎn)單,而且和實(shí)現(xiàn)無(wú)關(guān)�����。因此�����,可以使用設(shè)計(jì)模式的Facade模式來(lái)簡(jiǎn)化層間的接口��。這種做法非常有效,EJB中的SessionBean和EntityBean區(qū)分就含有這種設(shè)計(jì)思路���。
同樣的,不同層之間的數(shù)據(jù)傳遞也存在問(wèn)題��。如果不同層的物理節(jié)點(diǎn)在一起還好辦����,如果不在一起,那就需要使用到分布式技術(shù)了�����。因?yàn)椴煌瑱C(jī)器的內(nèi)存地址編碼是不同的�����,如果接口之間采用對(duì)象引用的方式�����,那一定會(huì)出現(xiàn)問(wèn)題����。因此會(huì)將對(duì)象打包成字符串,發(fā)送到目標(biāo)機(jī)器后再還原為對(duì)象�����。所有的分布式平臺(tái)都提供了對(duì)這種技術(shù)的支持���,這里就不多說(shuō)了�。但是這種實(shí)現(xiàn)技術(shù)會(huì)對(duì)我們的設(shè)計(jì)思路產(chǎn)生影響,少量的數(shù)據(jù)直接使用字符串來(lái)傳遞���,數(shù)據(jù)量大的話,就需要使用封裝了數(shù)據(jù)的對(duì)象��。這類(lèi)對(duì)象的設(shè)計(jì)需要非常的小心����。在設(shè)計(jì)過(guò)程中可以參照開(kāi)發(fā)平臺(tái)提供的一些標(biāo)準(zhǔn)做法。同樣的,數(shù)據(jù)的請(qǐng)求的頻率也是難點(diǎn)之一�����。過(guò)于頻繁的操作來(lái)自后端的數(shù)據(jù)會(huì)加大系統(tǒng)的開(kāi)銷(xiāo)��。因此�,在設(shè)計(jì)調(diào)用方法時(shí)同樣需要結(jié)合實(shí)際應(yīng)用來(lái)考慮��。
兼顧效率
一般來(lái)說(shuō)���,純粹的面向?qū)ο笤O(shè)計(jì)者設(shè)計(jì)出的軟件都會(huì)比較完美���。但是需要付出一定的代價(jià)��。在一些大的軟件平臺(tái)上編程的時(shí)候,往往需要利用到平臺(tái)的一些機(jī)制���。最典型的就是平臺(tái)的事務(wù)機(jī)制(最典型的包括J2EE平臺(tái)的JTS���,以及COM+平臺(tái)的MTS)��,但是事務(wù)機(jī)制的實(shí)現(xiàn)往往需要平臺(tái)大量對(duì)象的支撐。這種情況下,創(chuàng)建一個(gè)支持事務(wù)的對(duì)象的開(kāi)銷(xiāo)是很大的。處理這種問(wèn)題有一種變通的辦法��,就是僅僅對(duì)需要事務(wù)支撐的對(duì)象提供事務(wù)支持��。這就意味著��,一個(gè)單獨(dú)的業(yè)務(wù)實(shí)體類(lèi)�����,可能需要根據(jù)是否支持事務(wù)分為兩種類(lèi):對(duì)該業(yè)務(wù)實(shí)體的select方法不需要事務(wù)的支持���,只有update和delete方法才需要有事務(wù)的支持�。這是不符合純面向?qū)ο笤O(shè)計(jì)者的觀點(diǎn)的���。但是這種做法卻可以獲得比較優(yōu)秀的效率�����。
圖1 將單個(gè)的業(yè)務(wù)實(shí)體分為不同的實(shí)現(xiàn)
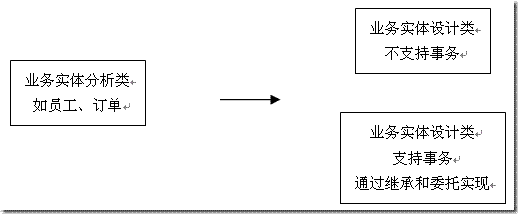
應(yīng)該承認(rèn)���,這種提高效率的做法加大了復(fù)雜度�����。因?yàn)閷?duì)于客戶(hù)端來(lái)說(shuō),它們并不關(guān)心具體的實(shí)現(xiàn)技術(shù)�����。要求客戶(hù)端在某一種情況下調(diào)用這個(gè)類(lèi)��,在其它情況下又調(diào)用另一個(gè)類(lèi),這種做法既不符合面向?qū)ο蟮脑O(shè)計(jì)思路,也增大了層間耦合度及復(fù)雜性�。因此��,我們可以考慮使用接口或是外觀類(lèi)(參見(jiàn)設(shè)計(jì)模式一書(shū)中的facade模式),把具體的實(shí)現(xiàn)封裝起來(lái),而只把用戶(hù)關(guān)心的部分提供給用戶(hù)���。這方面的技巧我們?cè)谙旅娴恼鹿?jié)中還會(huì)提到。
以迭代的方式進(jìn)行分層
軟件設(shè)計(jì)中的迭代做法同樣可以適用于分層�。根據(jù)自己的經(jīng)驗(yàn)�����,在一開(kāi)始就定義好所有的層次是很難的。除非有著非常豐富的經(jīng)驗(yàn)���,都則實(shí)現(xiàn)和原先的設(shè)計(jì)總有或大或小的差距。因此調(diào)整勢(shì)在必行�����。每一次的迭代都能夠?qū)Ψ謱蛹夹g(shù)進(jìn)行改進(jìn)�����,并為后一個(gè)項(xiàng)目積累了經(jīng)驗(yàn)�����。
這里的分層迭代不可以過(guò)于頻繁�����,每一次的迭代都是對(duì)架構(gòu)的重大修改�,都是需要投入人力的�,而且會(huì)影響到軟件開(kāi)發(fā)的進(jìn)度。但是成功的迭代的效果是非常明顯的���,能夠在接下來(lái)的開(kāi)發(fā)周期中起到穩(wěn)定架構(gòu),減少代碼量�,提升軟件質(zhì)量的功效�。注意���,不要讓新潮技術(shù)成為分層迭代的推動(dòng)力����。這是開(kāi)發(fā)人員都常犯的毛病,這并不是什么缺點(diǎn)����,只能稱(chēng)為一種職業(yè)病吧��。分層迭代的推動(dòng)力應(yīng)該源自于需求的演進(jìn)以及現(xiàn)有架構(gòu)的不穩(wěn)定已經(jīng)妨礙了軟件進(jìn)一步的開(kāi)發(fā)�。因此這需要團(tuán)隊(duì)中的技術(shù)主管對(duì)技術(shù)有著非常好的把握�。
重構(gòu)能夠?qū)Φ兴鶐椭P岢龃a中隱藏的壞味道并加以改進(jìn)。應(yīng)該說(shuō)����,迭代是一種比較激烈的做法�,更好的做法是在開(kāi)發(fā)中不斷的對(duì)架構(gòu)����、層次進(jìn)行調(diào)整。但這對(duì)團(tuán)隊(duì)、技術(shù)����、方法、過(guò)程都有著很高的要求���。因此迭代仍然是一種主要的改進(jìn)手段。
層內(nèi)的細(xì)分
分層的思路還可以適用于層的內(nèi)部�����。層內(nèi)的細(xì)分并沒(méi)有固定的方式�����,其驅(qū)動(dòng)因素往往是出于封裝性和重用的考慮�。例如�����,在EJB體系中的業(yè)務(wù)層中�,實(shí)體Bean負(fù)責(zé)實(shí)現(xiàn)業(yè)務(wù)對(duì)象��,因此一個(gè)應(yīng)用往往擁有大量的實(shí)體Bean��。而用戶(hù)端并不需要了解每一個(gè)的實(shí)體Bean,對(duì)它們來(lái)說(shuō)�,只要能夠完全一些業(yè)務(wù)邏輯就可以了�,但完成這些業(yè)務(wù)邏輯則需要和多個(gè)實(shí)體Bean打交道��。因此EJB提供了會(huì)話Bean�����,來(lái)負(fù)責(zé)把實(shí)體Bean封裝起來(lái),用戶(hù)只知道會(huì)話Bean�����,不知道實(shí)體Bean的存在���。這樣既保證了實(shí)體Bean的重用性�,又很好的實(shí)現(xiàn)了封裝��。
面向接口編程
在前面的章節(jié)中���,我們提到一個(gè)接口設(shè)計(jì)的例子�����。為什么我們提倡接口的設(shè)計(jì)呢?Martin Fowler在他的分析模式一書(shū)中指出���,分析問(wèn)題應(yīng)該站在概念的層次上,而不是站在實(shí)現(xiàn)的層次上�。什么叫做概念的層次呢����?簡(jiǎn)單的說(shuō)就是分析對(duì)象該做什么���,而不是分析對(duì)象怎么做���。前者屬于分析的階段�����,后者屬于設(shè)計(jì)甚至是實(shí)現(xiàn)的階段����。在需求工程中有一種稱(chēng)為CRC卡片的玩藝兒,是用來(lái)分析類(lèi)的職責(zé)和關(guān)系的���,其實(shí)那種方法就是從概念層次上進(jìn)行面向?qū)ο笤O(shè)計(jì)�。因此,如果要從概念層次上進(jìn)行分析����,這就要求你從領(lǐng)域?qū)<业慕嵌葋?lái)看待程序是如何表示現(xiàn)實(shí)世界中的概念的����。下面的這句話有些拗口�,從實(shí)現(xiàn)的角度上來(lái)說(shuō),概念層次對(duì)應(yīng)于合同�����,合同的實(shí)現(xiàn)形式包括接口和基類(lèi)��。簡(jiǎn)單的說(shuō)吧�����,在概念層次上進(jìn)行分析就是設(shè)計(jì)出接口(或是基類(lèi)),而不用關(guān)心具體的接口實(shí)現(xiàn)(實(shí)現(xiàn)推遲到子類(lèi)再實(shí)現(xiàn))。結(jié)合上面的論述,我們也可以這樣推斷��,接口應(yīng)該是要符合現(xiàn)實(shí)世界的觀念的�����。
在Martin Fowler的另一篇著作中提到了這樣一個(gè)例子�����,非常好的解釋了接口編程的思路:
interface Person { public String name(); public void name(String newName); public Money salary (); public void salary (Money newSalary); public Money payAmount (); public void makeManager (); } interface Engineer extends Person{ public void numberOfPatents (int value); public int numberOfPatents (); } interface Salesman extends Person{ public void numberOfSales (int numberOfSales); public int numberOfSales (); } interface Manager extends Person{ public void budget (Money value); public Money budget (); } |
可以看到,為了表示現(xiàn)實(shí)世界中人(這里其實(shí)指的是員工的概念)、工程師�����、銷(xiāo)售員�、經(jīng)理的概念�,代碼根據(jù)人的自然觀點(diǎn)設(shè)計(jì)了繼承層次結(jié)構(gòu),并很好的實(shí)現(xiàn)了重用。而且�,我們可以認(rèn)定該接口是相對(duì)穩(wěn)定的���。我們?cè)賮?lái)看看實(shí)現(xiàn)部分:
public class PersonImpFlag implements Person, Salesman, Engineer,Manager{// Implementing Salesman public static Salesman newSalesman (String name){ PersonImpFlag result; result = new PersonImpFlag (name); result.makeSalesman(); return result; }; public void makeSalesman () { _jobTitle = 1; }; public boolean isSalesman () { return _jobTitle == 1; }; public void numberOfSales (int value){ requireIsSalesman () ; _numberOfSales = value; }; public int numberOfSales () { requireIsSalesman (); return _numberOfSales; }; private void requireIsSalesman () { if (! isSalesman()) throw new PreconditionViolation ("Not a Salesman") ;}; private int _numberOfSales; private int _jobTitle; } |
這是其中一種被稱(chēng)為內(nèi)部標(biāo)示(Internal Flag)的實(shí)現(xiàn)方法�����。這里我們只是舉出一個(gè)例子,實(shí)際上我們還有非常多的解決方法�,但我們并不關(guān)心�����。因?yàn)橹灰涌谧銐蚍€(wěn)定,內(nèi)部實(shí)現(xiàn)發(fā)生再大的變化都是允許的�����。如果對(duì)實(shí)現(xiàn)的方式感興趣���,可以參考Matrin Fowler的角色建模的文章或是我在閱讀這篇文章的一篇筆記�����。
通過(guò)上面的例子�����,我們可以了解到�����,接口和實(shí)現(xiàn)分離的最大好處就是能夠在客戶(hù)端未知的情況下修改實(shí)現(xiàn)代碼�����。這個(gè)特性對(duì)于分層技術(shù)是非常適用的���。一種是用在層和層之間的調(diào)用�。層和層之間是最忌諱耦合度過(guò)高或是改變過(guò)于頻繁的���。設(shè)計(jì)優(yōu)秀的接口能夠解決這個(gè)問(wèn)題�。另一種是用在那些不穩(wěn)定的部分上。如果某些需求的變化性很大���,那么定義接口也是一種解決之道。舉個(gè)不恰當(dāng)?shù)睦?,設(shè)計(jì)良好的接口就像是我們?nèi)粘J褂玫娜f(wàn)用插座一樣�����,不論插頭如何變化,都可以使用�。
最后強(qiáng)調(diào)一點(diǎn)�,良好的接口定義一定是來(lái)自于需求的�����,它絕對(duì)不是程序員絞盡腦汁想出來(lái)的�����。
數(shù)據(jù)映射層
在各個(gè)層的設(shè)計(jì)中,可能比較令人困惑的就是數(shù)據(jù)映射層了���。由于篇幅的關(guān)系���,我們不可能在這個(gè)問(wèn)題上討論太多�,只能是拋磚引玉。如果有機(jī)會(huì)�����,我們還可以來(lái)談?wù)勥@方面的話題�����。
面向?qū)ο蠹夹g(shù)已經(jīng)成為軟件開(kāi)發(fā)的一種趨勢(shì)�,越來(lái)越多的人開(kāi)始了解�、學(xué)習(xí)和使用面向?qū)ο蠹夹g(shù)。而大多數(shù)的面向?qū)ο蠹夹g(shù)都只是解決了內(nèi)存中的面向?qū)ο蟮膯?wèn)題。但是鮮有提到持久性的面向?qū)ο髥?wèn)題。
面向?qū)ο笤O(shè)計(jì)的機(jī)制與關(guān)系模型有很大的不同,這造成了面向?qū)ο笤O(shè)計(jì)與關(guān)系數(shù)據(jù)庫(kù)設(shè)計(jì)之間的不匹配���。面向?qū)ο笤O(shè)計(jì)的基本理論包括耦合、聚合、封裝�����、繼承��、多態(tài)���,而關(guān)系數(shù)據(jù)模型的理論則完全不同�,它的基本原理是數(shù)據(jù)庫(kù)的三大范式�。最明顯的一個(gè)例子是,Order對(duì)象包括一組的OrderItem對(duì)象�,因此我們需要在Order類(lèi)中設(shè)計(jì)一個(gè)容器(各個(gè)編程語(yǔ)言都提供了一組的容器對(duì)象及相關(guān)操作以供使用)來(lái)存儲(chǔ)OrderItem���,也就是說(shuō)Order類(lèi)中的指針指向OrderItem���。假設(shè)Order類(lèi)和OrderItem分別對(duì)應(yīng)于數(shù)據(jù)庫(kù)的兩張表(最簡(jiǎn)單的映射情況)���,那么,我們要實(shí)現(xiàn)二者之間的關(guān)系���,是通過(guò)在OrderItem表(假設(shè)名稱(chēng)一樣)增加指向Order表的外鍵�����。這是兩種完全不同的設(shè)置。數(shù)據(jù)映射層的作用就是向用戶(hù)端隱藏關(guān)系數(shù)據(jù)庫(kù)的存在。
自己開(kāi)發(fā)一個(gè)對(duì)象/關(guān)系映射工具是非常誘人的。但是應(yīng)該考慮到�����,開(kāi)發(fā)這樣一個(gè)工具并不是一件容易的事���,需要付出很大的成本���。尤其是手工處理數(shù)據(jù)一致性和事務(wù)處理的問(wèn)題上�����。它比你想象的要難的多�。因此����,獲取一個(gè)對(duì)象/關(guān)系映射工具的最好途徑是購(gòu)買(mǎi),而不是開(kāi)發(fā)。
總結(jié)
分層對(duì)現(xiàn)代的軟件開(kāi)發(fā)而言是非常重要的概念。也是我們必須學(xué)習(xí)的知識(shí)�。分層的總體思路并沒(méi)有什么特別的地方�����,但是要和自己的開(kāi)發(fā)環(huán)境、應(yīng)用環(huán)境結(jié)合起來(lái),你還需要付出很多的努力才行。
在完成了分層之后�����,軟件架構(gòu)其實(shí)已經(jīng)清晰化了�����。下面的討論將圍繞著如何改進(jìn)架構(gòu),如何使架構(gòu)穩(wěn)定方面的問(wèn)題進(jìn)行�����。
關(guān)于作者
|

|
|
|

|
林星�����,辰訊軟件工作室項(xiàng)目管理組資深項(xiàng)目經(jīng)理���,有多年項(xiàng)目實(shí)施經(jīng)驗(yàn)�。辰訊軟件工作室致力于先進(jìn)軟件思想�、軟件技術(shù)的應(yīng)用,主要的研究方向在于軟件過(guò)程思想�、Linux集群技術(shù)���、OO技術(shù)和軟件工廠模式�。您可以通過(guò)電子郵件 iamlinx@21cn.com和他聯(lián)系���。 |