構建系統數據模型時,有2共選擇,以:group->account->son account舉例
1、系統由多個group組成;
2、一個group有多個account;
3、一個account有多個son account.
有2種數據模型構建方式選擇;
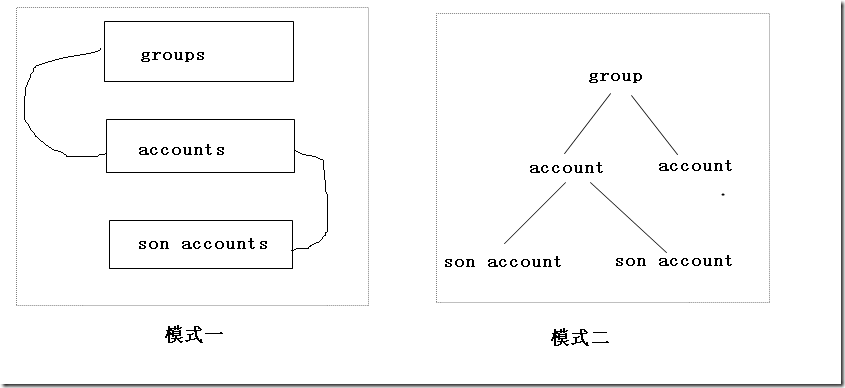
1、模式一的數據模型由3張表構成:groups表,accounts表,son accounts表。是淺層數據結構(結構型),每張表的深度是1。accounts表將有一個[group]字段關聯到groups表里面的某條記錄;son accounts表將有一個[account]字段關聯到accounts表里面的某條記錄。可以說這是一種經典的數據結構,結構型數據庫就是由這樣深度為1的二維型數據表構成,多張表之間的關系通過增加關聯字段來標明;
2、模式二的數據模型中,把group視作一個整體,它是數據層的一個基本單元(unit),數據層由多個group對象組成,group對象的深度是3,是深層數據結構(聚合型)。現實的模型對應為對象型數據庫;
現在的問題是:模式一簡單還是模式二簡單?哪一種是更為優越的選擇?我傾向于模式一,因為:
1、結構型數據建模是經典的,目前依然是主流的,得到數據庫的廣泛支持,即使不使用數據庫,也容易序列化到存儲,并且我相信群眾,相信主流意志的正確性;
2、模式二的對象型數據建模,group是數據元,是數據操作的唯一入口,所以需要提供account,son account的操作接口,account又需要提供son account的操作接口,假設對象深度再多增加幾層,那這是一個龐大且累贅的冗余。另外一點是樹形的對象不容易序列化,沒有太多數據庫支持;
3、模式二的層次太深,復雜度級數上升,違反了系統弱化成小類模型的原則(多個類,每個類的復雜度都很低),而這里,group將是一個很大的類。
4、第一感覺:模式一的復雜度我能控制,模式二就沒有把握,所以心里更認同模式一;
5、雖然模式二直觀的表明了數據的聚合-組合關系,與現實模型完全隱射,在理論上應該是更好的選擇。但是就人的理解能力的傾向來說:我認為理解廣度的事務比較理解深度的事務而言更有優勢;
6、寫到這里,我突然想說一句:化深度為廣度,符合人的認知規律,降低了復雜度。