多元數據是最常見的數據類型���。人們經常都要作出一系列的決定�����,比如吃什么���,買什么新手機�����,去哪里旅游���,住什么旅館��,等等。這類決策往往是基于多元數據的分析:食物中熱量有多高,碳水化合物多少,是否含有反式脂肪�����,三聚氰胺等添加劑等���;相機的價格��,像素多少�����,光圈大小,焦距范圍,能否紅外拍攝�����,等等��。多元數據的分析還能幫助我們發現一些數據間的聯系,并進行預測。
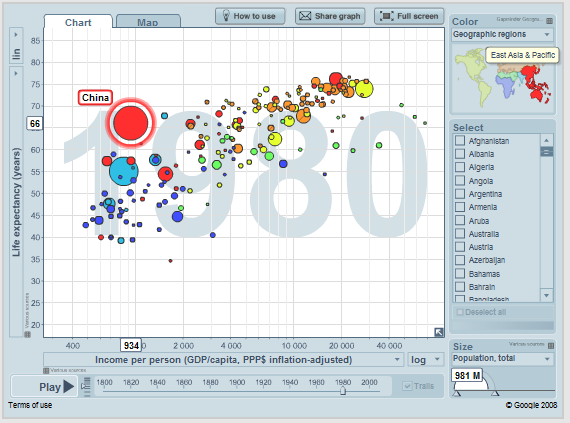
對于簡單的多元數據,最常見的可視化方法是散點圖(scatterplot)。比如���,對于二維數據,通常的方法就把它們直接畫成二維坐標上的一系列點,從而可以看出數據變化趨勢��。對于更高維的數據��,一種方法是把數據的每種屬性用不同的圖形�����,顏色,紋理等���,表示在二維坐標上。比如下面的圖是由www.gapminder.org生成的�����,用來顯示了世界上國家的財富和人均壽命的關系�����。橫軸是人均收入�����,縱軸是平均壽命,每個國家表示一個圓��,圓的大小表示該國的人口�����,圓的顏色對應于所在的區域��。這樣一張圖表達了一個國家的4個屬性。左邊的圖是基于1980年的數據��,而右邊的圖是基于2009年的數據�����。圖中那個大大的紅圓就是我們中國��,我們可以很直觀的看出這30年中國的發展還是很給力!網站上還能生成動畫�����,演示各個圓的位置變換���,像中國那么大的圓還能動那么快���,也是獨一無二的�����。

對于有更多屬性的數據��,用上面的方法就往往不能顯示了。常見的方法是用散點圖矩陣(scatterplot matrix)�����,如果數據有N維(N個屬性)���,所有的屬性兩兩組合就生成N x N個二維散點圖�����。把這些圖排列成N x N的矩陣。這樣可以觀察任意兩個屬性間的關系�����。比如下面這張圖就顯示了汽車的主要屬性間的散點圖【1】��。其中MPG代表了汽車的油耗(每加侖油能開的旅程)��,從圖里我們看出,發動機馬力越大MPG越小���,車越重MPG越小,年齡越大MPG越小,等等���。
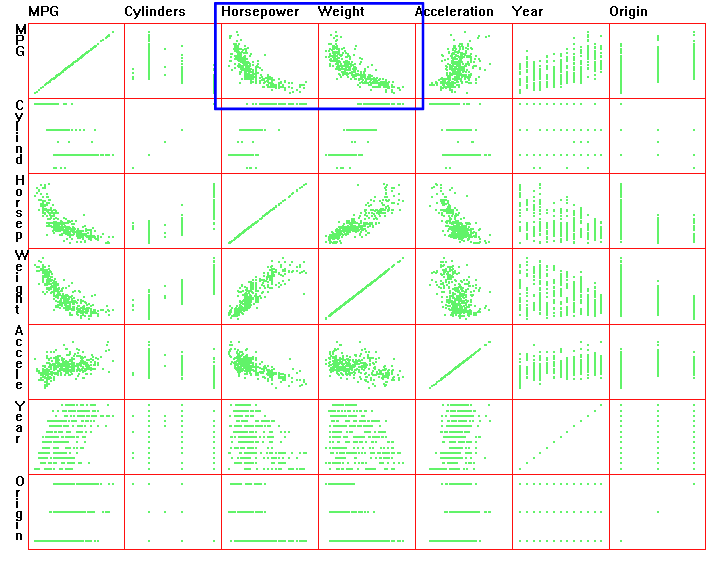
【1】M. O. Ward. Xmdvtool: Integrating multiple methods for visualizing multivariate data. In Proceedings of IEEE Conference on Visualization, 1994.
散點圖可以很好的顯示少量屬性的數據。但是,即使用散點圖矩陣也無法解決屬性更多的情況,而且每個小圖只能顯示2個屬性間的聯系����,多個屬性間的關系并不是很 直觀��。這種局限性主要來自將數據投影在了二維直角坐標系上。人們提出一系列的方法來解決這個局限性,而其中最著名的是1981年Alfred Inselberg 提出的平行坐標系(Parallel Coordinates)��。這種方法把各個屬性表示成一系列的平行的軸��,組成一個平行坐標系�,每條數據就表示成這個坐標系里的一條直線�。比如我們有這樣一 組數據

可以方便的表示成這樣的平行坐標

平行坐標系的優勢在于發現大規模數據間的屬性聯系。比如再回到前面的汽車的數據�,用平行坐標可以表示成【1】
多個屬性間的聯系比散點圖要清晰����。比如可以清楚看出來Cylinder多的車�,MPG相對小,但是馬力大��;Cylinder小的車�,MPG相對大,但是馬力 小��。在平行坐標里��,我們還可以方便的進行交互式刪選數據,方便觀察��,比如下面的圖,我們可以看一下,Cylinders多,MPG小,馬力大的車的其他屬性怎么樣。
當數據過多的時候,平行坐標系里的線就會很多��,數據間的聯系就看不清楚了�,就像下面的左圖。一種解決方法是把線畫成半透明,這樣主要的線的趨勢就會隨著線的數目的增加而清晰��,像下面的右圖【2】��。當數據很大的時候��,主要的趨勢的分析通常是數據的分析的第一步。

再回到我們前面第一個例子,雖然看上去學歷和收入成反比����,但是如果我們有更多的數據��,像汽車的例子一樣,平行坐標也可以給我們更清楚顯示收入和學歷,年齡等等的關系��,所以還在讀高學位的朋友先不要灰心啊����。
【1】M. O. Ward. Xmdvtool: Integrating multiple methods for visualizing multivariate data. In Proceedings of IEEE Conference on Visualization, 1994.
【2】 Chad Jones, et al. An Integrated Exploration Approach to Visualizing Multivariate Particle Data. Computing in Science & Engineering, Volume 10, Number 4, July/August, 2008, pp. 20-29
作為多元數據可視化的主要兩種方法,散點圖和平行坐標各有優缺點�。散點圖通常只能顯現兩個屬性間的聯系����,但是每條數據都表示成一個點����,從而減少了總的像素數 量和視覺復雜度;平行坐標能顯示多個屬性間的聯系,但是每條數據(多條屬性)表示成一條線��,增加了像素的數量����,當數據量很大的時候��,復雜度就大大增加�,而無法顯示數據間的聯系����。2009年北大的袁曉如教授在IEEE VisWeek 上發表了篇文章【1】,提出了一種技術將兩種方法結合在一塊�?�;镜南敕ㄊ窃谄叫凶鴺死锏妮S之間顯示散點圖,從而使原來在平行坐標里看不清的數據趨勢用散點圖表示����。像下面的左圖顯示的是平行坐標圖�,而右圖結合了散點圖�。


在兩個平行軸之間畫散點圖的基本思路是把右邊的軸旋轉90圖,這樣與左邊的形成直角坐標系,散點圖的繪制和解讀也就與傳統的一致。畫散點圖的區域中原來的直線變成穿過散點圖的曲線����,這樣保持了原來平行坐標里的連接關系�,也支持通過線來進行數據篩選的功能����。這種新的技術也用到了前面所說的汽車數據的例子,有興趣的話找這篇論文讀一讀吧�。
【1】 Xiaoru Yuan, et al. Scattering Points in Parallel Coordinates. IEEE Transactions on Visualzation and Computer Graphics, November/December 2009 (vol. 15 no. 6)
在科學計算可視化的時候��,看到了這篇blog,文章講解得非常好�!作者也是非常牛的��!特此轉載到此!
http://www.vizinsight.com/2010/12/%E6%B5%85%E8%B0%88%E5%A4%9A%E5%85%83%E6%95%B0%E6%8D%AE%E7%9A%84%E5%8F%AF%E8%A7%86%E5%8C%96%E6%8A%80%E6%9C%AF%EF%BC%88%E4%B8%8B%EF%BC%89/
大家可以去頂一下這個blog
http://www.vizinsight.com/