來源:http://portableapps.com/node/12561下載http://zer0dev.com/dld/download.php?id=27頭文件使用:1. !include "ProcFunc.nsh"2. 可使用范圍:$var為返回值[Section|Function]${ProcFunction} "參數(shù)1" "參數(shù)2" "..." $var[SectionEnd|FunctionEnd]${ProcessExists} "[process]" "[process]" ; Name or PID Use with a LogicLib conditional command like If or Unless. Evaluates to true if the process exists or false if it does not or the CreateToolhelp32Snapshot fails.${GetProcessPID} "[process]" $var "[process]" ; Name or PID $var(output) ; -2 - CreateToolhelp32Snapshot failed ; 0 - process does not exist ; >0 - PID${GetProcessPath} "[process]" $var "[process]" ; Name or PID $var(output) ; -2 - CreateToolhelp32Snapshot failed ; -1 - OpenProcess failed ; 0 - process does not exist ; Or path to process${GetProcessParent} "[process]" $var "[process]" ; Name or PID $var(output) ; -2 - CreateToolhelp32Snapshot failed ; 0 - process does not exist ; Or PPID${GetProcessName} "[PID]" $var "[PID]" ; PID $var(output) ; -2 - CreateToolhelp32Snapshot failed ; 0 - process does not exist ; Or process name${EnumProcessPaths} "Function" $var "Function" ; Callback function $var(output) ; -2 - EnumProcesses failed ; 1 - success Function "Function" Pop $var1 ; matching path string Pop $var2 ; matching process PID ...user commands Push [1/0] ; must return 1 on the stack to continue ; must return some value or corrupt the stack ; DO NOT save data in $0-$9 FunctionEnd${ProcessWait} "[process]" "[timeout]" $var "[process]" ; Name "[timeout]" ; -1 - do not timeout ; >0 - timeout in milliseconds $var(output) ; -2 - CreateToolhelp32Snapshot failed ; -1 - operation timed out ; Or PID${ProcessWait2} "[process]" "[timeout]" $var "[process]" ; Name "[timeout]" ; -1 - do not timeout ; >0 - timeout in milliseconds $var(output) ; -1 - operation timed out ; Or PID${ProcessWaitClose} "[process]" "[timeout]" $var "[process]" ; Name "[timeout]" ; -1 - do not timeout ; >0 - timeout in milliseconds $var(output) ; -1 - operation timed out ; 0 - process does not exist ; Or PID of ended process${CloseProcess} "[process]" $var "[process]" ; Name or PID $var(output) ; 0 - process does not exist ; Or PID of ended process${TerminateProcess} "[process]" $var "[process]" ; Name or PID $var(output) ; -1 - operation failed ; 0 - process does not exist ; Or PID of ended process${Execute} "[command]" "[working_dir]" $var "[command]" ; '"X:\path\to\prog.exe" arg1 arg2 "arg3 with space"' "[working_dir]" ; Working directory ("X:\path\to\dir") or nothing ("") $var(output) ; 0 - failed to create process ; Or PID*/本文轉(zhuǎn)自:http://www.dreams8.com/forum.php?mod=viewthread&tid=17067&fromuid=1
1 CString sTempIPs;
2 sTempIPs.Format("%s%s", CCommonFun::GetTmpPath(), "TempIPs.txt");
3
4 ::DeleteFile(sTempIPs);
5 CString sPara;
6 sPara.Format("/c ipconfig.exe | findstr \"IP Address\" > \"%s\"", sTempIPs);
7 CCommonFun::WinExecAndWait32("cmd.exe", sPara, CCommonFun::GetExecutablePath(), INFINITE);
8
9 if (CFileFind().FindFile(sTempIPs))
10 {
11 CString sLine, sIP;
12 CString sFlag = ": ";
13 CStdioFile stdFile;
14 if (stdFile.Open(sTempIPs, CFile::modeRead))
15 {
16 while (stdFile.ReadString(sLine))
17 {
18 int nPos = sLine.Find(sFlag);
19 if (nPos != -1)
20 {
21 sIP = sLine.Mid(nPos+sFlag.GetLength(), sLine.GetLength()-(nPos+sFlag.GetLength()));
22 sIP.TrimLeft();
23 sIP.TrimRight();
24 arsLocalIPs.Add(sIP);
25 }
26 }
27 }
28 }
摘要: 在開機(jī)啟動(dòng)應(yīng)用程序時(shí),可能會(huì)碰到權(quán)限不夠而啟動(dòng)失敗或者一些其他問題,所以在開機(jī)啟動(dòng)程序時(shí)可能會(huì)使用SYSTEM權(quán)限,但由于后來的操作不需要高權(quán)限來完成,就需要降低應(yīng)用程序的權(quán)限。可以通過獲取explorer.exe進(jìn)程ID來實(shí)現(xiàn)。
Code highlighting produced by Actipro CodeHigh...
閱讀全文
半個(gè)月前在豆瓣上看到了一本新書《數(shù)學(xué)之美》,評(píng)價(jià)很高。而因?yàn)樵诎肽昵翱戳恕妒裁词菙?shù)學(xué)》就對(duì)數(shù)學(xué)產(chǎn)生濃厚興趣,但苦于水平不足的我便立馬買了一本,希望能對(duì)數(shù)學(xué)多一些了解,并認(rèn)真閱讀起來。
令我意外并欣喜的是,這本書里邊的數(shù)學(xué)內(nèi)容并不晦澀難懂,而且作者為了講述數(shù)學(xué)之美而搭配的一些工程實(shí)例都是和我學(xué)習(xí)并感興趣的模式識(shí)別,目標(biāo)分類相關(guān)算法相關(guān)聯(lián)的。這讓我覺得撿到了意外的寶藏。
書中每一個(gè)章節(jié)都或多或少是作者親身經(jīng)歷過的,比如世界級(jí)教授的小故事,或者Google的搜索引擎原理,又或者是Google的云計(jì)算等。作者用其行云流水般的語言將各個(gè)知識(shí)點(diǎn)像講故事一樣有趣的敘述出來。
這本書著實(shí)讓我印象深刻,所以我把筆記分享出來,希望更多和我學(xué)習(xí)研究領(lǐng)域一樣的人會(huì)喜歡并親自閱讀這本書,并能支持作者。畢竟國內(nèi)這種書實(shí)在是太少了,也希望能有更多領(lǐng)域內(nèi)的大牛能再寫出一些這種書籍來讓我們共同提高。
1. 因?yàn)樾枰獋鞑バ畔⒘康脑黾樱煌穆曇舨⒉荒芡耆磉_(dá)信息,語言便產(chǎn)生了。
2. 當(dāng)文字增加到?jīng)]有人能完全記住所有文字時(shí),聚類和歸類就開始了。例如日代表太陽或者代表一天。
3. 聚類會(huì)帶來歧義性,但上下文可以消除歧義。信息冗余是信息安全的保障。例如羅塞塔石碑上同一信息重復(fù)三次。
4. 最短編碼原理即常用信息短編碼,生僻信息長編碼。
5. 因?yàn)槲淖种皇切畔⒌妮d體而非信息本身,所以翻譯是可以實(shí)現(xiàn)的。
6. 2012,其實(shí)是瑪雅文明采用二十進(jìn)制,即四百年是一個(gè)太陽紀(jì),而2012年恰巧是當(dāng)前太陽紀(jì)的最后一年,2013年是新的太陽紀(jì)的開始,故被誤傳為世界末日。
7. 字母可以看為是一維編碼,而漢字可以看為二維編碼。
8. 基于統(tǒng)計(jì)的自然語言處理方法,在數(shù)學(xué)模型上和通信是相通的,甚至是相同的。
9. 讓計(jì)算機(jī)處理自然語言的基本問題就是為自然語言這種上下文相關(guān)的特性建立數(shù)學(xué)模型,即統(tǒng)計(jì)語言模型(Statistical Language Modal)。
10. 根據(jù)大數(shù)定理(Law of Large Numbers),只要統(tǒng)計(jì)量足夠,相對(duì)頻度就等于概率。
11. 二元模型。對(duì)于p(w1,w2,…,wn)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1)的展開問題,因?yàn)閜(w3|w1,w2)難計(jì)算,p(wn|w1,w2,…,wn-1)更難計(jì)算,馬爾科夫給出了一個(gè)偷懶但是頗為有效的方法,也就是每當(dāng)遇到這種情況時(shí),就假設(shè)任意wi出現(xiàn)的概率只與它前面的wi-1有關(guān),即p(s)=p(w1)p(w2|w1)p(w3|w2)…p(wi|wi-1)…p(wn|wn-1)。現(xiàn)在這個(gè)概率就變的簡單了。對(duì)應(yīng)的語言模型為2元模型(Bigram Model)。
12. *N元模型。wi只與前一個(gè)wi-1有關(guān)近似的過頭了,所以N-1階馬爾科夫假設(shè)為p(wi|w1,w2,…,wi-1)=p(wi|wi-N+1,wi-N+2,…,wi-1),對(duì)應(yīng)的語言模型成為N元模型(N-Gram Model)。一元模型就是上下文無關(guān)模型,實(shí)際應(yīng)用中更多實(shí)用的是三元模型。Google的羅塞塔翻譯系統(tǒng)和語言搜索系統(tǒng)實(shí)用的是四元模型,存儲(chǔ)于500臺(tái)以上的Google服務(wù)器中。
13. *卡茲退避法(Katz backoff),對(duì)于頻率超過一定閾值的詞,它們的概率估計(jì)就是它們?cè)谡Z料庫中的相對(duì)頻度,對(duì)于頻率小于這個(gè)閾值的詞,它們的概率估計(jì)就小于他們的相對(duì)頻度,出現(xiàn)次數(shù)越少,頻率下調(diào)越多。對(duì)于未看見的詞,也給予一個(gè)比較小的概率(即下調(diào)得到的頻率總和),這樣所有詞的概率估計(jì)都平滑了。這就是卡茲退避法(Katz backoff)。
14. 訓(xùn)練數(shù)據(jù)通常是越多越好,通過平滑過渡的方法可以解決零概率和很小概率的問題,畢竟在數(shù)據(jù)量多的時(shí)候概率模型的參數(shù)可以估計(jì)的比較準(zhǔn)確。
15. 利用統(tǒng)計(jì)語言模型進(jìn)行分詞,即最好的分詞方法應(yīng)該保證分完詞后這個(gè)句子出現(xiàn)的概率最大。根據(jù)不同應(yīng)用,漢語分詞的顆粒度大小應(yīng)該不同。
16. 符合馬爾科夫假設(shè)(各個(gè)狀態(tài)st的概率分布只與它前一個(gè)狀態(tài)st-1有關(guān))的隨即過程即成為馬爾科夫過程,也稱為馬爾科夫鏈。
17. 隱含馬爾科夫模型是馬爾科夫鏈的擴(kuò)展,任意時(shí)刻t的狀態(tài)st是不可見的,所以觀察者沒法通過觀察到一個(gè)狀態(tài)序列s1,s2,s3,…,sT來推測(cè)轉(zhuǎn)移概率等參數(shù)。但是隱馬爾科夫模型在每個(gè)時(shí)刻t會(huì)輸出一個(gè)符號(hào)ot,而且ot和st相關(guān)且僅和ot相關(guān)。這個(gè)被稱為獨(dú)立輸出假設(shè)。其中隱含的狀態(tài)s1,s2,s3,…是一個(gè)典型的馬爾科夫鏈。
18. 隱含馬爾科夫模型是機(jī)器學(xué)習(xí)主要工具之一,和幾乎所有機(jī)器學(xué)習(xí)的模型工具一樣,它需要一個(gè)訓(xùn)練算法(鮑姆-韋爾奇算法)和使用時(shí)的解碼算法(維特比算法)。掌握了這兩類算法,就基本上可以使用隱含馬爾科夫模型這個(gè)工具了。
19. 鮑姆-韋爾奇算法(Baum-Welch Algorithm),首先找到一組能夠產(chǎn)生輸出序列O的模型參數(shù),這個(gè)初始模型成為Mtheta0,需要在此基礎(chǔ)上找到一個(gè)更好的模型,假定不但可以算出這個(gè)模型產(chǎn)生O的概率P(O|Mtheta0),而且能夠找到這個(gè)模型產(chǎn)生O的所有可能的路徑以及這些路徑的概率。并算出一組新的模型參數(shù)theta1,從Mtheta0到Mtheta1的過程稱為一次迭代。接下來從Mtheta1出發(fā)尋找更好的模型Mtheta2,并一直找下去,直到模型的質(zhì)量沒有明顯提高為止。這樣一直估計(jì)(Expectation)新的模型參數(shù),使得輸出的概率達(dá)到最大化(Maximization)的過程被稱為期望值最大化(Expectation-Maximization)簡稱EM過程。EM過程能保證一定能收斂到一個(gè)局部最優(yōu)點(diǎn),但不能保證找到全局最優(yōu)點(diǎn)。因此,在一些自然語言處理的應(yīng)用中,這種無監(jiān)督的鮑姆-韋爾奇算法訓(xùn)練處的模型比有監(jiān)督的訓(xùn)練得到的模型效果略差。
20. 熵,信息熵的定義為H(X)=-SumP(x)logP(x),變量的不確定性越大,熵也越大。
21. 一個(gè)事物內(nèi)部會(huì)存在隨機(jī)性,也就是不確定性,假定為U,而從外部消除這個(gè)不確定性唯一的辦法是引入信息I,而需要引入的信息量取決于這個(gè)不確定性的大小,即I>U才行。當(dāng)I<U時(shí),這些信息可以消除一部分不確定性,U'=U-I。反之,如果沒有信息,任何公示或者數(shù)字的游戲都無法排除不確定性。
22. 信息的作用在于消除不確定性。
23. 互信息,對(duì)兩個(gè)隨機(jī)事件相關(guān)性的量化度量,即隨機(jī)事件X的不確定性或者說熵H(X),在知道隨機(jī)事件Y條件下的不確定性,或者說條件熵H(X|Y)之間的差異,即I(X;Y)=H(X)-H(X|Y)。所謂兩個(gè)事件相關(guān)性的量化度量,即在了解了其中一個(gè)Y的前提下,對(duì)消除另一個(gè)X不確定性所提供的信息量。
24. 相對(duì)熵(Kullback-Leibler Divergence)也叫交叉熵,對(duì)兩個(gè)完全相同的函數(shù),他們的相對(duì)熵為零;相對(duì)熵越大,兩個(gè)函數(shù)差異越大,反之,相對(duì)熵越小,兩個(gè)函數(shù)差異越小;對(duì)于概率分布或者概率密度函數(shù),如果取值均大于零,相對(duì)熵可以度量兩個(gè)隨機(jī)分布的差異性。
25. 弗里德里克·賈里尼克(Frederek Jelinek)是自然語言處理真諦的先驅(qū)者。
26. 技術(shù)分為術(shù)和道兩種,具體的做事方法是術(shù),做事的原理和原則是道。術(shù)會(huì)從獨(dú)門絕技到普及再到落伍,追求術(shù)的人會(huì)很辛苦,只有掌握了道的本質(zhì)和精髓才能永遠(yuǎn)游刃有余。
27. 真理在形式上從來是簡單的,而不是復(fù)雜和含混的。
28. 搜索引擎不過是一張大表,表的每一行對(duì)應(yīng)一個(gè)關(guān)鍵字,而每一個(gè)關(guān)鍵字后面跟著一組數(shù)字,是包含該關(guān)鍵詞的文獻(xiàn)序號(hào)。但當(dāng)索引變的非常大的時(shí)候,這些索引需要通過分布式的方式存儲(chǔ)到不同的服務(wù)器上。
29. 網(wǎng)絡(luò)爬蟲(Web Crawlers),圖論的遍歷算法和搜索引擎的關(guān)系。互聯(lián)網(wǎng)雖然復(fù)雜,但是說穿了其實(shí)就是一張大圖……可以把每一個(gè)網(wǎng)頁當(dāng)做一個(gè)節(jié)點(diǎn),把那些超鏈接當(dāng)做連接網(wǎng)頁的弧。有了超鏈接,可以從任何一個(gè)網(wǎng)頁出發(fā),用圖的遍歷算法,自動(dòng)訪問到每一個(gè)網(wǎng)頁并且把他們存儲(chǔ)起來。完成這個(gè)功能的程序叫網(wǎng)絡(luò)爬蟲。
30. 哥尼斯堡七橋,如果一個(gè)圖能從一個(gè)頂點(diǎn)出發(fā),每條邊不重復(fù)的遍歷一遍回到這個(gè)頂點(diǎn),那么每一個(gè)頂點(diǎn)的度必須為偶數(shù)。
31. 構(gòu)建網(wǎng)絡(luò)爬蟲的工程要點(diǎn):1.用BFS(廣度優(yōu)先搜索)還是DFS(深度優(yōu)先搜索),一般是先下載完一個(gè)網(wǎng)站,再進(jìn)入下一個(gè)網(wǎng)站,即BFS的成分多一些。2.頁面的分析和URL的提取,如果有些網(wǎng)頁明明存在,但搜索引擎并沒有收錄,可能的原因之一是網(wǎng)絡(luò)爬蟲中的解析程序沒能成功解析網(wǎng)頁中不規(guī)范的腳本程序。3.記錄哪些網(wǎng)頁已經(jīng)下載過的URL表,可以用哈希表。最終,好的方法一般都采用了這樣兩個(gè)技術(shù):首先明確每臺(tái)下載服務(wù)器的分工,也就是在調(diào)度時(shí),一看到某個(gè)URL就知道要交給哪臺(tái)服務(wù)器去下載,這樣就避免了很多服務(wù)器對(duì)同一個(gè)URL做出是否需要下載的判斷。然后,在明確分工的基礎(chǔ)上,判斷URL是否下載就可以批處理了,比如每次向哈希表(一組獨(dú)立的服務(wù)器)發(fā)送一大批詢問,或者每次更新一大批哈希表的內(nèi)容,這樣通信的次數(shù)就大大減少了。
32. PageRank衡量網(wǎng)頁質(zhì)量的核心思想,在互聯(lián)網(wǎng)上,如果一個(gè)網(wǎng)頁被很多其他網(wǎng)頁所鏈接,說明它受到普遍的承認(rèn)和信賴,那么它的排名就高。同時(shí),對(duì)于來自不同網(wǎng)頁的鏈接區(qū)別對(duì)待,因?yàn)榫W(wǎng)頁排名高的那些網(wǎng)頁的鏈接更可靠,于是要給這些鏈接比較大的權(quán)重。
33. TF-IDF(Term Frequency / Inverse Document Frequency) ,關(guān)鍵詞頻率-逆文本頻率值,其中,TF為某個(gè)網(wǎng)頁上出現(xiàn)關(guān)鍵詞的頻率,IDF為假定一個(gè)關(guān)鍵詞w在Dw個(gè)網(wǎng)頁中出現(xiàn)過,那么Dw越大,w的權(quán)重越小,反之亦然,公式為log(D/Dw)。1.一個(gè)詞預(yù)測(cè)主題的能力越強(qiáng),權(quán)重越大,反之,權(quán)重越小。2.停止詞的權(quán)重為零。
34. 動(dòng)態(tài)規(guī)劃(Dynamic Programming)的原理,將一個(gè)尋找全程最優(yōu)的問題分解成一個(gè)個(gè)尋找局部最優(yōu)的小問題。
35. 一個(gè)好的算法應(yīng)該像輕武器中最有名的AK-47沖鋒槍那樣:簡單、有效、可靠性好而且容易讀懂(易操作)而不應(yīng)該故弄玄虛。選擇簡單方案可以容易解釋每個(gè)步驟和方法背后的道理,這樣不僅便于出問題時(shí)的查錯(cuò),也容易找到今后改進(jìn)的目標(biāo)。
36. 在實(shí)際的分類中,可以先進(jìn)行奇異值分解(得到分類結(jié)果略顯粗糙但能較快得到結(jié)果),在粗分類結(jié)果的基礎(chǔ)上,利用計(jì)算向量余弦的方法(對(duì)范圍內(nèi)的分類做兩兩計(jì)算),在粗分類結(jié)果的基礎(chǔ)上,進(jìn)行幾次迭代,得到比較精確的結(jié)果。
37. 奇異值分解(Singular Value Decomposition),在需要用一個(gè)大矩陣A來描述成千上萬文章和幾十上百萬詞的關(guān)聯(lián)性時(shí),計(jì)算量非常大,可以將A奇異值分解為X、B和Y三個(gè)矩陣,Amn=Xmm*Bmn*Ynn,X表示詞和詞類的相關(guān)性,Y表示文本和主題的相關(guān)性,B表示詞類和主題的相關(guān)性,其中B對(duì)角線上的元素很多值相對(duì)其他的非常小,或者為零,可以省略。對(duì)關(guān)聯(lián)矩陣A進(jìn)行一次奇異值分解,就可以同時(shí)完成近義詞分類和文章的分類,同時(shí)能得到每個(gè)主題和每個(gè)詞義類之間的相關(guān)性,這個(gè)結(jié)果非常漂亮。
38. 信息指紋。如果能夠找到一種函數(shù),將5000億網(wǎng)址隨即地映射到128位二進(jìn)制,也就是16字節(jié)的整數(shù)空間,就稱這16字節(jié)的隨機(jī)數(shù)做該網(wǎng)址的信息指紋。信息指紋可以理解為將一段信息映射到一個(gè)多維二進(jìn)制空間中的一個(gè)點(diǎn),只要這個(gè)隨即函數(shù)做的好,那么不同信息對(duì)應(yīng)的點(diǎn)不會(huì)重合,因此這個(gè)二進(jìn)制的數(shù)字就變成了原來信息所具有的獨(dú)一無二的指紋。
39. 判斷兩個(gè)集合是否相同,最笨的方法是這個(gè)集合中的元素一一比較,復(fù)雜度O(squareN),稍好的是將元素排序后順序比較,復(fù)雜度O(NlogN),最完美的方法是計(jì)算這兩個(gè)集合的指紋,然后直接進(jìn)行比較,計(jì)算復(fù)雜度O(N)。
40. 偽隨機(jī)數(shù)產(chǎn)生器算法(Pseudo-Random Number Generator,PRNG),這是產(chǎn)生信息指紋的關(guān)鍵算法,通過他可以將任意長的整數(shù)轉(zhuǎn)換成特定長度的偽隨機(jī)數(shù)。最早的PRNG是將一個(gè)數(shù)的平方掐頭去尾取中間,當(dāng)然這種方法不是很隨即,現(xiàn)在常用的是梅森旋轉(zhuǎn)算法(Mersenne Twister)。
41. 在互聯(lián)網(wǎng)上加密要使用基于加密的偽隨機(jī)數(shù)產(chǎn)生器(Cryptography Secure Pseudo-Random Number Generator,CSPRNG),常用的算法有MD5或者SHA-1等標(biāo)準(zhǔn),可以將不定長的信息變成定長的128位或者160位二進(jìn)制隨機(jī)數(shù)。
42. 最大熵模型(Maximum Entropy)的原理就是保留全部的不確定性,將風(fēng)險(xiǎn)降到最小。最大熵原理指出,需要對(duì)一個(gè)隨機(jī)事件的概率分布進(jìn)行預(yù)測(cè)時(shí),我們的預(yù)測(cè)應(yīng)當(dāng)滿足全部已知的條件,而對(duì)未知的情況不要做任何主觀假設(shè)。在這種情況下,概率分布最均勻,預(yù)測(cè)的風(fēng)險(xiǎn)最小。I.Csiszar證明,對(duì)任何一組不自相矛盾的信息,這個(gè)最大熵模型不僅存在,而且是唯一的,此外,他們都有同一個(gè)非常簡單的形式-指數(shù)函數(shù)。
43. 通用迭代算法(Generalized Iterative Scaling,GIS)是最原始的最大熵模型的訓(xùn)練方法。1.假定第零次迭代的初始模型為等概率的均勻分布。2.用第N次迭代的模型來估算每種信息特征在訓(xùn)練數(shù)據(jù)中的分布。如果超過了實(shí)際的,就把相應(yīng)的模型參數(shù)變小,反之變大。3.重復(fù)步驟2直至收斂。這是一種典型的期望值最大化(Expectation Maximization,EM)算法。IIS(Improved Iterative Scaling)比GIS縮短了一到兩個(gè)數(shù)量級(jí)。
44. 布隆過濾器實(shí)際上是一個(gè)很長的二進(jìn)制向量和一系列隨機(jī)映射的函數(shù)。
45. 貝葉斯網(wǎng)絡(luò)從數(shù)學(xué)的層面講是一個(gè)加權(quán)的有向圖,是馬爾科夫鏈的擴(kuò)展,而從知識(shí)論的層面看,貝葉斯網(wǎng)絡(luò)克服了馬爾科夫那種機(jī)械的線性的約束,它可以把任何有關(guān)聯(lián)的事件統(tǒng)一到它的框架下面。在網(wǎng)絡(luò)中,假定馬爾科夫假設(shè)成立,即每一個(gè)狀態(tài)只與和它直接相連的狀態(tài)有關(guān),而和他間接相連的狀態(tài)沒有直接關(guān)系,那么它就是貝葉斯網(wǎng)絡(luò)。在網(wǎng)絡(luò)中每個(gè)節(jié)點(diǎn)概率的計(jì)算,都可以用貝葉斯公式來進(jìn)行,貝葉斯網(wǎng)絡(luò)也因此得名。由于網(wǎng)絡(luò)的每個(gè)弧都有一個(gè)可信度,貝葉斯網(wǎng)絡(luò)也被稱作信念網(wǎng)絡(luò)(Belief Networks)。
46. 條件隨機(jī)場(chǎng)是計(jì)算聯(lián)合概率分布的有效模型。在一個(gè)隱含馬爾科夫模型中,以x1,x2,...,xn表示觀測(cè)值序列,以y1,y2,...,yn表示隱含的狀態(tài)序列,那么xi只取決于產(chǎn)生它們的狀態(tài)yi,和前后的狀態(tài)yi-1和yi+1都無關(guān)。顯然很多應(yīng)用里觀察值xi可能和前后的狀態(tài)都有關(guān),如果把xi和yi-1,yi,yi+1都考慮進(jìn)來,這樣的模型就是條件隨機(jī)場(chǎng)。它是一種特殊的概率圖模型(Probablistic Graph Model),它的特殊性在于,變量之間要遵守馬爾科夫假設(shè),即每個(gè)狀態(tài)的轉(zhuǎn)移概率只取決于相鄰的狀態(tài),這一點(diǎn)和另一種概率圖模型貝葉斯網(wǎng)絡(luò)相同,它們的不同之處在于條件隨機(jī)場(chǎng)是無向圖,而貝葉斯網(wǎng)絡(luò)是有向圖。
47. 維特比算法(Viterbi Algoritm)是一個(gè)特殊但應(yīng)用最廣的動(dòng)態(tài)規(guī)劃算法,利用動(dòng)態(tài)規(guī)劃,可以解決任何一個(gè)圖中的最短路徑問題。它之所以重要,是因?yàn)榉彩鞘褂秒[含馬爾科夫模型描述的問題都可以用它來解碼。1.從點(diǎn)S出發(fā),對(duì)于第一個(gè)狀態(tài)x1的各個(gè)節(jié)點(diǎn),不妨假定有n1個(gè),計(jì)算出S到他們的距離d(S,x1i),其中x1i代表任意狀態(tài)1的節(jié)點(diǎn)。因?yàn)橹挥幸徊剑赃@些距離都是S到他們各自的最短距離。2.對(duì)于第二個(gè)狀態(tài)x2的所有節(jié)點(diǎn),要計(jì)算出從S到他們的最短距離。d(S,x2i)=min_I=1,n1_d(S,x1j)+d(x1j,x2i),由于j有n1種可能性,需要一一計(jì)算,然后找到最小值。這樣對(duì)于第二個(gè)狀態(tài)的每個(gè)節(jié)點(diǎn),需要n1次乘法計(jì)算。假定這個(gè)狀態(tài)有n2個(gè)節(jié)點(diǎn),把S這些節(jié)點(diǎn)的距離都算一遍,就有O(n1*n2)次運(yùn)算。3.按照上述方法從第二個(gè)狀態(tài)走到第三個(gè)狀態(tài)一直走到最后一個(gè)狀態(tài),這樣就得到整個(gè)網(wǎng)絡(luò)從頭到尾的最短路徑。
48. 擴(kuò)頻傳輸(Spread-Spectrum Transmission)和固定頻率的傳輸相比,有三點(diǎn)明顯的好處:1.抗干擾能力強(qiáng)。2.信號(hào)能量非常低,很難獲取。3.擴(kuò)頻傳輸利用帶寬更充分。
49. Google針對(duì)云計(jì)算給出的解決工具是MapReduce,其根本原理就是計(jì)算機(jī)算法上常見的分治算法(Divide-and-Conquer)。將一個(gè)大任務(wù)拆分成小的子任務(wù),并完成子任務(wù)的計(jì)算,這個(gè)過程叫Map,將中間結(jié)果合并成最終結(jié)果,這個(gè)過程叫Reduce。
50. 邏輯回歸模型(Logistic Regression)是將一個(gè)事件出現(xiàn)的概率適應(yīng)到一條邏輯曲線(Logistic Curve)上。典型的邏輯回歸函數(shù):f(z)=e`z/e`z+1=1/1+e`-z。邏輯曲線是一條S型曲線,其特點(diǎn)是開始變化快,逐漸減慢,最后飽和。邏輯自回歸的好處是它的變量范圍從負(fù)無窮到正無窮,而值域范圍限制在0-1之間。因?yàn)橹涤虻姆秶?-1之間,這樣邏輯回歸函數(shù)就可以和一個(gè)概率分別聯(lián)系起來了。因?yàn)樽宰兞糠秶谪?fù)無窮到正無窮之間,它就可以把信號(hào)組合起來,不論組合成多大或者多小的值,最后依然能得到一個(gè)概率分布。
51. 期望最大化算法(Expectation Maximization Algorithm),根據(jù)現(xiàn)有的模型,計(jì)算各個(gè)觀測(cè)數(shù)據(jù)輸入到模型中的計(jì)算結(jié)果,這個(gè)過程稱為期望值計(jì)算過程(Expectation),或E過程;接下來,重新計(jì)算模型參數(shù),以最大化期望值,這個(gè)過程稱為最大化的過程(Maximization),或M過程。這一類算法都稱為EM算法,比如隱含馬爾科夫模型的訓(xùn)練方法Baum-Welch算法,以及最大熵模型的訓(xùn)練方法GIS算法。
本文轉(zhuǎn)自:http://www.shnenglu.com/humanchao
摘要: 一、預(yù)備知識(shí)—程序的內(nèi)存分配
一個(gè)由c/C++編譯的程序占用的內(nèi)存分為以下幾個(gè)部分
1、棧區(qū)(stack)— 由編譯器自動(dòng)分配釋放 ,存放函數(shù)的參數(shù)值,局部變量的值等。其操作方式類似于數(shù)據(jù)結(jié)構(gòu)中的棧。
2、堆區(qū)(heap) — 一般由程序員分配釋放, 若程序員不釋放,程序結(jié)束時(shí)可能由OS回收 。注意它與數(shù)據(jù)結(jié)構(gòu)中的堆是兩回事,分配方式倒是類似于鏈表,呵呵。
3、全局區(qū)(靜態(tài)區(qū))(static)—,全局變量和靜態(tài)變量的存儲(chǔ)是放在一塊的,初始化的全局變量和靜態(tài)變量在一塊區(qū)域, 未初始化的全局變量和未初始化的靜態(tài)變量在相鄰的另一塊區(qū)域。 - 程序結(jié)束后有系統(tǒng)釋放
4、文字常量區(qū)—常量字符串就是放在這里的。 程序結(jié)束后由系統(tǒng)釋放
5、程序代碼區(qū)—存放函數(shù)體的二進(jìn)制代碼。
閱讀全文
author : Kevin Lynx
什么是完成包?
完成包,即IO Completion Packet,是指異步IO操作完畢后OS提交給應(yīng)用層的通知包。IOCP維護(hù)了一個(gè)IO操作結(jié)果隊(duì)列,里面
保存著各種完成包。應(yīng)用層調(diào)用GQCS(也就是GetQueueCompletionStatus)函數(shù)獲取這些完成包。
最大并發(fā)線程數(shù)
在一個(gè)典型的IOCP程序里,會(huì)有一些線程調(diào)用GQCS去獲取IO操作結(jié)果。最大并發(fā)線程數(shù)指定在同一時(shí)刻處理完成包的線程數(shù)目。
該參數(shù)在調(diào)用CreateIoCompletionPort時(shí)由NumberOfConcurrentThreads指定。
工作者線程
工作者線程一般指的就是調(diào)用GQCS函數(shù)的線程。要注意的是,工作者線程數(shù)和最大并發(fā)線程數(shù)并不是同一回事(見下文)。工作者
線程由應(yīng)用層顯示創(chuàng)建(_beginthreadex 之類)。工作者線程通常是一個(gè)循環(huán),會(huì)不斷地GQCS到完成包,然后處理完成包。
調(diào)度過程
工作者線程以是否阻塞分為兩種狀態(tài):運(yùn)行狀態(tài)和等待狀態(tài)。當(dāng)線程做一些阻塞操作時(shí)(線程同步,甚至GQCS空的完成隊(duì)列),線程
處于等待狀態(tài);否則,線程處于運(yùn)行狀態(tài)。
另一方面,OS會(huì)始終保持某一時(shí)刻處于運(yùn)行狀態(tài)的線程數(shù)小于最大并發(fā)線程數(shù)。每一個(gè)調(diào)用GQCS函數(shù)的線程OS實(shí)際上都會(huì)進(jìn)行記錄,
當(dāng)完成隊(duì)列里有完成包時(shí),OS會(huì)首先檢查當(dāng)前處于運(yùn)行狀態(tài)的工作線程數(shù)是否小于最大并發(fā)線程數(shù),如果小于,OS會(huì)按照LIFO的順
序讓某個(gè)工作者線程從GQCS返回(此工作者線程轉(zhuǎn)換為運(yùn)行狀態(tài))。如何決定這個(gè)LIFO?這是簡單地通過調(diào)用GQCS函數(shù)的順序決定的。
從這里可以看出,這里涉及到線程喚醒和睡眠的操作。如果兩個(gè)線程被放置于同一個(gè)CPU上,就會(huì)有線程切換的開銷。因此,為了消
除這個(gè)開銷,最大并發(fā)線程數(shù)被建議為設(shè)置成CPU數(shù)量。
從以上調(diào)度過程還可以看出,如果某個(gè)處于運(yùn)行狀態(tài)的工作者線程在處理完成包時(shí)阻塞了(例如線程同步、其他IO操作),那么就有
CPU資源處于空閑狀態(tài)。因此,我們也看到很多文檔里建議,工作者線程數(shù)為(CPU數(shù)*2+2)。
在一個(gè)等待線程轉(zhuǎn)換到運(yùn)行狀態(tài)時(shí),有可能會(huì)出現(xiàn)短暫的時(shí)間運(yùn)行線程數(shù)超過最大并發(fā)線程數(shù),這個(gè)時(shí)候OS會(huì)迅速地讓這個(gè)新轉(zhuǎn)換
的線程阻塞,從而減少這個(gè)數(shù)量。(關(guān)于這個(gè)觀點(diǎn),MSDN上只說:by not allowing any new active threads,卻沒說明not allowing
what)
調(diào)度原理
這個(gè)知道了其實(shí)沒什么意義,都是內(nèi)核做的事,大致上都是操作線程control block,直接摘錄<Inside IO Completion Ports>:
The list of threads hangs off the queue object. A thread's control block data structure has a pointer in it that
references the queue object of a queue that it is associated with; if the pointer is NULL then the thread is not
associated with a queue.
So how does NT keep track of threads that become inactive because they block on something other than the completion
port" The answer lies in the queue pointer in a thread's control block. The scheduler routines that are executed
in response to a thread blocking (KeWaitForSingleObject, KeDelayExecutionThread, etc.) check the thread's queue
pointer and if its not NULL they will call KiActivateWaiterQueue, a queue-related function. KiActivateWaiterQueue
decrements the count of active threads associated with the queue, and if the result is less than the maximum and
there is at least one completion packet in the queue then the thread at the front of the queue's thread list is
woken and given the oldest packet. Conversely, whenever a thread that is associated with a queue wakes up after
blocking the scheduler executes the function KiUnwaitThread, which increments the queue's active count.
參考資料
<Inside I/O Completion Ports>:
http://technet.microsoft.com/en-us/sysinternals/bb963891.aspx
<I/O Completion Ports>:
http://msdn.microsoft.com/en-us/library/aa365198(VS.85).aspx
<INFO: Design Issues When Using IOCP in a Winsock Server>:
http://support.microsoft.com/kb/192800/en-us/
本文轉(zhuǎn)自:http://www.shnenglu.com/kevinlynx/archive/2008/06/23/54390.html
Author : Kevin Lynx
主要部分,四次握手:
斷開連接其實(shí)從我的角度看不區(qū)分客戶端和服務(wù)器端,任何一方都可以調(diào)用close(or closesocket)之類
的函數(shù)開始主動(dòng)終止一個(gè)連接。這里先暫時(shí)說正常情況。當(dāng)調(diào)用close函數(shù)斷開一個(gè)連接時(shí),主動(dòng)斷開的
一方發(fā)送FIN(finish報(bào)文給對(duì)方。有了之前的經(jīng)驗(yàn),我想你應(yīng)該明白我說的FIN報(bào)文時(shí)什么東西。也就是
一個(gè)設(shè)置了FIN標(biāo)志位的報(bào)文段。FIN報(bào)文也可能附加用戶數(shù)據(jù),如果這一方還有數(shù)據(jù)要發(fā)送時(shí),將數(shù)據(jù)附
加到這個(gè)FIN報(bào)文時(shí)完全正常的。之后你會(huì)看到,這種附加報(bào)文還會(huì)有很多,例如ACK報(bào)文。我們所要把握
的原則是,TCP肯定會(huì)力所能及地達(dá)到最大效率,所以你能夠想到的優(yōu)化方法,我想TCP都會(huì)想到。
當(dāng)被動(dòng)關(guān)閉的一方收到FIN報(bào)文時(shí),它會(huì)發(fā)送ACK確認(rèn)報(bào)文(對(duì)于ACK這個(gè)東西你應(yīng)該很熟悉了)。這里有個(gè)
東西要注意,因?yàn)門CP是雙工的,也就是說,你可以想象一對(duì)TCP連接上有兩條數(shù)據(jù)通路。當(dāng)發(fā)送FIN報(bào)文
時(shí),意思是說,發(fā)送FIN的一端就不能發(fā)送數(shù)據(jù),也就是關(guān)閉了其中一條數(shù)據(jù)通路。被動(dòng)關(guān)閉的一端發(fā)送
了ACK后,應(yīng)用層通常就會(huì)檢測(cè)到這個(gè)連接即將斷開,然后被動(dòng)斷開的應(yīng)用層調(diào)用close關(guān)閉連接。
我可以告訴你,一旦當(dāng)你調(diào)用close(or closesocket),這一端就會(huì)發(fā)送FIN報(bào)文。也就是說,現(xiàn)在被動(dòng)
關(guān)閉的一端也發(fā)送FIN給主動(dòng)關(guān)閉端。有時(shí)候,被動(dòng)關(guān)閉端會(huì)將ACK和FIN兩個(gè)報(bào)文合在一起發(fā)送。主動(dòng)
關(guān)閉端收到FIN后也發(fā)送ACK,然后整個(gè)連接關(guān)閉(事實(shí)上還沒完全關(guān)閉,只是關(guān)閉需要交換的報(bào)文發(fā)送
完畢),四次握手完成。如你所見,因?yàn)楸粍?dòng)關(guān)閉端可能會(huì)將ACK和FIN合到一起發(fā)送,所以這也算不上
嚴(yán)格的四次握手---四個(gè)報(bào)文段。
在前面的文章中,我一直沒提TCP的狀態(tài)轉(zhuǎn)換。在這里我還是在猶豫是不是該將那張四處通用的圖拿出來,
不過,這里我只給出斷開連接時(shí)的狀態(tài)轉(zhuǎn)換圖,摘自<The TCP/IP Guide>:
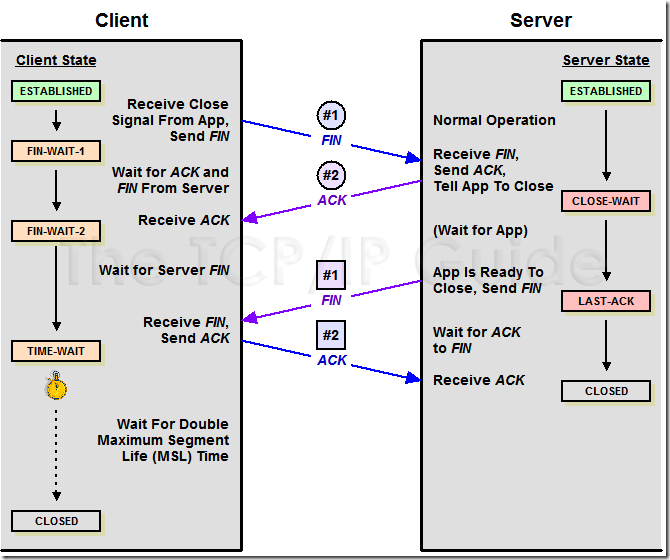
給出一個(gè)正常關(guān)閉時(shí)的windump信息:
 14:00:38.819856 IP cd-zhangmin.1748 > 220.181.37.55.80: F 1:1(0) ack 1 win 65535
14:00:38.819856 IP cd-zhangmin.1748 > 220.181.37.55.80: F 1:1(0) ack 1 win 65535
14:00:38.863989 IP 220.181.37.55.80 > cd-zhangmin.1748: F 1:1(0) ack 2 win 2920
14:00:38.864412 IP cd-zhangmin.1748 > 220.181.37.55.80: . ack 2 win 65535
補(bǔ)充細(xì)節(jié):
關(guān)于以上的四次握手,我補(bǔ)充下細(xì)節(jié):
1. 默認(rèn)情況下(不改變socket選項(xiàng)),當(dāng)你調(diào)用close( or closesocket,以下說close不再重復(fù))時(shí),如果
發(fā)送緩沖中還有數(shù)據(jù),TCP會(huì)繼續(xù)把數(shù)據(jù)發(fā)送完。
2. 發(fā)送了FIN只是表示這端不能繼續(xù)發(fā)送數(shù)據(jù)(應(yīng)用層不能再調(diào)用send發(fā)送),但是還可以接收數(shù)據(jù)。
3. 應(yīng)用層如何知道對(duì)端關(guān)閉?通常,在最簡單的阻塞模型中,當(dāng)你調(diào)用recv時(shí),如果返回0,則表示對(duì)端
關(guān)閉。在這個(gè)時(shí)候通常的做法就是也調(diào)用close,那么TCP層就發(fā)送FIN,繼續(xù)完成四次握手。如果你不調(diào)用
close,那么對(duì)端就會(huì)處于FIN_WAIT_2狀態(tài),而本端則會(huì)處于CLOSE_WAIT狀態(tài)。這個(gè)可以寫代碼試試。
4. 在很多時(shí)候,TCP連接的斷開都會(huì)由TCP層自動(dòng)進(jìn)行,例如你CTRL+C終止你的程序,TCP連接依然會(huì)正常關(guān)
閉,你可以寫代碼試試。
特別的TIME_WAIT狀態(tài):
從以上TCP連接關(guān)閉的狀態(tài)轉(zhuǎn)換圖可以看出,主動(dòng)關(guān)閉的一方在發(fā)送完對(duì)對(duì)方FIN報(bào)文的確認(rèn)(ACK)報(bào)文后,
會(huì)進(jìn)入TIME_WAIT狀態(tài)。TIME_WAIT狀態(tài)也稱為2MSL狀態(tài)。
什么是2MSL?MSL即Maximum Segment Lifetime,也就是報(bào)文最大生存時(shí)間,引用<TCP/IP詳解>中的話:“
它(MSL)是任何報(bào)文段被丟棄前在網(wǎng)絡(luò)內(nèi)的最長時(shí)間。”那么,2MSL也就是這個(gè)時(shí)間的2倍。其實(shí)我覺得沒
必要把這個(gè)MSL的確切含義搞明白,你所需要明白的是,當(dāng)TCP連接完成四個(gè)報(bào)文段的交換時(shí),主動(dòng)關(guān)閉的
一方將繼續(xù)等待一定時(shí)間(2-4分鐘),即使兩端的應(yīng)用程序結(jié)束。你可以寫代碼試試,然后用netstat查看下。
為什么需要2MSL?根據(jù)<TCP/IP詳解>和<The TCP/IP Guide>中的說法,有兩個(gè)原因:
其一,保證發(fā)送的ACK會(huì)成功發(fā)送到對(duì)方,如何保證?我覺得可能是通過超時(shí)計(jì)時(shí)器發(fā)送。這個(gè)就很難用
代碼演示了。
其二,報(bào)文可能會(huì)被混淆,意思是說,其他時(shí)候的連接可能會(huì)被當(dāng)作本次的連接。直接引用<The TCP/IP Guide>
的說法:The second is to provide a “buffering period” between the end of this connection
and any subsequent ones. If not for this period, it is possible that packets from different
connections could be mixed, creating confusion.
TIME_WAIT狀態(tài)所帶來的影響:
當(dāng)某個(gè)連接的一端處于TIME_WAIT狀態(tài)時(shí),該連接將不能再被使用。事實(shí)上,對(duì)于我們比較有現(xiàn)實(shí)意義的
是,這個(gè)端口將不能再被使用。某個(gè)端口處于TIME_WAIT狀態(tài)(其實(shí)應(yīng)該是這個(gè)連接)時(shí),這意味著這個(gè)TCP
連接并沒有斷開(完全斷開),那么,如果你bind這個(gè)端口,就會(huì)失敗。
對(duì)于服務(wù)器而言,如果服務(wù)器突然crash掉了,那么它將無法再2MSL內(nèi)重新啟動(dòng),因?yàn)閎ind會(huì)失敗。解決這
個(gè)問題的一個(gè)方法就是設(shè)置socket的SO_REUSEADDR選項(xiàng)。這個(gè)選項(xiàng)意味著你可以重用一個(gè)地址。
對(duì)于TIME_WAIT的插曲:
當(dāng)建立一個(gè)TCP連接時(shí),服務(wù)器端會(huì)繼續(xù)用原有端口監(jiān)聽,同時(shí)用這個(gè)端口與客戶端通信。而客戶端默認(rèn)情況
下會(huì)使用一個(gè)隨機(jī)端口與服務(wù)器端的監(jiān)聽端口通信。有時(shí)候,為了服務(wù)器端的安全性,我們需要對(duì)客戶端進(jìn)行
驗(yàn)證,即限定某個(gè)IP某個(gè)特定端口的客戶端。客戶端可以使用bind來使用特定的端口。
對(duì)于服務(wù)器端,當(dāng)設(shè)置了SO_REUSEADDR選項(xiàng)時(shí),它可以在2MSL內(nèi)啟動(dòng)并listen成功。但是對(duì)于客戶端,當(dāng)使
用bind并設(shè)置SO_REUSEADDR時(shí),如果在2MSL內(nèi)啟動(dòng),雖然bind會(huì)成功,但是在windows平臺(tái)上connect會(huì)失敗。
而在linux上則不存在這個(gè)問題。(我的實(shí)驗(yàn)平臺(tái):winxp, ubuntu7.10)
要解決windows平臺(tái)的這個(gè)問題,可以設(shè)置SO_LINGER選項(xiàng)。SO_LINGER選項(xiàng)決定調(diào)用close時(shí),TCP的行為。
SO_LINGER涉及到linger結(jié)構(gòu)體,如果設(shè)置結(jié)構(gòu)體中l(wèi)_onoff為非0,l_linger為0,那么調(diào)用close時(shí)TCP連接
會(huì)立刻斷開,TCP不會(huì)將發(fā)送緩沖中未發(fā)送的數(shù)據(jù)發(fā)送,而是立即發(fā)送一個(gè)RST報(bào)文給對(duì)方,這個(gè)時(shí)候TCP連
接就不會(huì)進(jìn)入TIME_WAIT狀態(tài)。
如你所見,這樣做雖然解決了問題,但是并不安全。通過以上方式設(shè)置SO_LINGER狀態(tài),等同于設(shè)置SO_DONTLINGER
狀態(tài)。
斷開連接時(shí)的意外:
這個(gè)算不上斷開連接時(shí)的意外,當(dāng)TCP連接發(fā)生一些物理上的意外情況時(shí),例如網(wǎng)線斷開,linux上的TCP實(shí)現(xiàn)
會(huì)依然認(rèn)為該連接有效,而windows則會(huì)在一定時(shí)間后返回錯(cuò)誤信息。
這似乎可以通過設(shè)置SO_KEEPALIVE選項(xiàng)來解決,不過不知道這個(gè)選項(xiàng)是否對(duì)于所有平臺(tái)都有效。
總結(jié):
個(gè)人感覺,越寫越爛。接下來會(huì)講到TCP的數(shù)據(jù)發(fā)送,這會(huì)涉及到滑動(dòng)窗口各種定時(shí)器之類的東西。我真誠
希望各位能夠多提意見。對(duì)于TCP連接的斷開,我們只要清楚:
1. 在默認(rèn)情況下,調(diào)用close時(shí)TCP會(huì)繼續(xù)將數(shù)據(jù)發(fā)送完畢;
2. TIME_WAIT狀態(tài)會(huì)導(dǎo)致的問題;
3. 連接意外斷開時(shí)可能會(huì)出現(xiàn)的問題。
4. maybe more...
本文轉(zhuǎn)自:http://www.shnenglu.com/kevinlynx/archive/2008/05/14/49825.html
Author : Kevin Lynx
準(zhǔn)備:
在這里本文將遵循上一篇文章的風(fēng)格,只提TCP協(xié)議中的要點(diǎn),這樣我覺得可以更容易地掌握TCP。或者
根本談不上掌握,對(duì)于這種純理論的東西,即使你現(xiàn)在掌握了再多的細(xì)節(jié),一段時(shí)間后也會(huì)淡忘。
在以后各種細(xì)節(jié)中,因?yàn)槲覀儠?huì)涉及到分析一些TCP中的數(shù)據(jù)報(bào),因此一個(gè)協(xié)議包截獲工具必不可少。在
<TCP/IP詳解>中一直使用tcpdump。這里因?yàn)槲业南到y(tǒng)是windows,所以只好使用windows平臺(tái)的tcpdump,
也就是WinDump。在使用WinDump之前,你需要安裝該程序使用的庫WinpCap。
關(guān)于WinDump的具體用法你可以從網(wǎng)上其他地方獲取,這里我只稍微提一下。要讓W(xué)inDump開始監(jiān)聽數(shù)據(jù),
首先需要確定讓其監(jiān)聽哪一個(gè)網(wǎng)絡(luò)設(shè)備(或者說是網(wǎng)絡(luò)接口)。你可以:
windump -D
獲取當(dāng)前機(jī)器上的網(wǎng)絡(luò)接口。然后使用:
windump -i 2
開始對(duì)網(wǎng)絡(luò)接口2的數(shù)據(jù)監(jiān)聽。windump如同tcpdump(其實(shí)就是tcpdump)一樣支持過濾表達(dá)式,windump
將會(huì)根據(jù)你提供的過濾表達(dá)式過濾不需要的網(wǎng)絡(luò)數(shù)據(jù)包,例如:
windump -i 2 port 4000
那么windump只會(huì)顯示端口號(hào)為4000的網(wǎng)絡(luò)數(shù)據(jù)。
序號(hào)和確認(rèn)號(hào):
要講解TCP的建立過程,也就是那個(gè)所謂的三次握手,就會(huì)涉及到序號(hào)和確認(rèn)號(hào)這兩個(gè)東西。翻書到TCP
的報(bào)文頭,有兩個(gè)很重要的域(都是32位)就是序號(hào)域和確認(rèn)號(hào)域。可能有些同學(xué)會(huì)對(duì)TCP那個(gè)報(bào)文頭有所
疑惑(能看懂我在講什么的會(huì)產(chǎn)生這樣的疑惑么?),這里我可以告訴你,你可以假想TCP的報(bào)文頭就是個(gè)
C語言結(jié)構(gòu)體(假想而已,去翻翻bsd對(duì)TCP的實(shí)現(xiàn),肯定沒這么簡單),那么大致上,所謂的TCP報(bào)文頭就是:
typedef struct _tcp_header


 {
{

 /**//// 16位源端口號(hào)
/**//// 16位源端口號(hào)
 unsigned short src_port;
unsigned short src_port;
/**//// 16位目的端口號(hào)
unsigned short dst_port;
/**//// 32位序號(hào)
unsigned long seq_num;
/**//// 32位確認(rèn)號(hào)
unsigned long ack_num;
/**//// 16位標(biāo)志位[4位首部長度,保留6位,ACK、SYN之類的標(biāo)志位]
unsigned short flag;
/**//// 16位窗口大小
unsigned short win_size;
/**//// 16位校驗(yàn)和
short crc_sum;
/**//// 16位緊急指針
short ptr;
/**//// 可選選項(xiàng)
 /// how to implement this ?
/// how to implement this ?
 } tcp_header;
} tcp_header;
那么,這個(gè)序號(hào)和確認(rèn)號(hào)是什么?TCP報(bào)文為每一個(gè)字節(jié)都設(shè)置一個(gè)序號(hào),覺得很奇怪?這里并不是為每一
字節(jié)附加一個(gè)序號(hào)(那會(huì)是多么可笑的編程手法?),而是為一個(gè)TCP報(bào)文附加一個(gè)序號(hào),這個(gè)序號(hào)表示報(bào)文
中數(shù)據(jù)的第一個(gè)字節(jié)的序號(hào),而其他數(shù)據(jù)則是根據(jù)離第一個(gè)數(shù)據(jù)的偏移來決定序號(hào)的,例如,現(xiàn)在有數(shù)據(jù):
abcd。如果這段數(shù)據(jù)的序號(hào)為1200,那么a的序號(hào)就是1200,b的序號(hào)就是1201。而TCP發(fā)送的下一個(gè)數(shù)據(jù)包
的序號(hào)就會(huì)是上一個(gè)數(shù)據(jù)包最后一個(gè)字節(jié)的序號(hào)加一。例如efghi是abcd的下一個(gè)數(shù)據(jù)包,那么它的序號(hào)就
是1204。通過這種看似簡單的方法,TCP就實(shí)現(xiàn)了為每一個(gè)字節(jié)設(shè)置序號(hào)的功能(終于明白為什么書上要告訴
我們‘為每一個(gè)字節(jié)設(shè)置一個(gè)序號(hào)’了吧?)。注意,設(shè)置序號(hào)是一種可以讓TCP成為’可靠協(xié)議‘的手段。
TCP中各種亂七八糟的東西都是有目的的,大部分目的還是為了’可靠‘兩個(gè)字。別把TCP看高深了,如果
讓你來設(shè)計(jì)一個(gè)網(wǎng)絡(luò)協(xié)議,目的需要告訴你是’可靠的‘,你就會(huì)明白為什么會(huì)產(chǎn)生那些亂七八糟的東西了。
接著看,確認(rèn)號(hào)是什么?因?yàn)門CP會(huì)對(duì)接收到的數(shù)據(jù)包進(jìn)行確認(rèn),發(fā)送確認(rèn)數(shù)據(jù)包時(shí),就會(huì)設(shè)置這個(gè)確認(rèn)號(hào),
確認(rèn)號(hào)通常表示接收方希望接收到的下一段報(bào)文的序號(hào)。例如某一次接收方收到序號(hào)為1200的4字節(jié)數(shù)舉報(bào),
那么它發(fā)送確認(rèn)報(bào)文給發(fā)送方時(shí),就會(huì)設(shè)置確認(rèn)號(hào)為1204。
大部分書上在講確認(rèn)號(hào)和序號(hào)時(shí),都會(huì)說確認(rèn)號(hào)是序號(hào)加一。這其實(shí)有點(diǎn)誤解人,所以我才在這里廢話了
半天(高手寬容下:D)。
開始三次握手:
如果你還不會(huì)簡單的tcp socket編程,我建議你先去學(xué)學(xué),這就好比你不會(huì)C++基本語法,就別去研究vtable
之類。
三次握手開始于客戶端試圖連接服務(wù)器端。當(dāng)你調(diào)用諸如connect的函數(shù)時(shí),正常情況下就會(huì)開始三次握手。
隨便在網(wǎng)上找張三次握手的圖:

如前文所述,三次握手也就是產(chǎn)生了三個(gè)數(shù)據(jù)包。客戶端主動(dòng)連接,發(fā)送SYN被設(shè)置了的報(bào)文(注意序號(hào)和
確認(rèn)號(hào),因?yàn)檫@里不包含用戶數(shù)據(jù),所以序號(hào)和確認(rèn)號(hào)就是加一減一的關(guān)系)。服務(wù)器端收到該報(bào)文時(shí),正
常情況下就發(fā)送SYN和ACK被設(shè)置了的報(bào)文作為確認(rèn),以及告訴客戶端:我想打開我這邊的連接(雙工)。客戶
端于是再對(duì)服務(wù)器端的SYN進(jìn)行確認(rèn),于是再發(fā)送ACK報(bào)文。然后連接建立完畢。對(duì)于阻塞式socket而言,你
的connect可能就返回成功給你。
在進(jìn)行了鋪天蓋地的羅利巴索的基礎(chǔ)概念的講解后,看看這個(gè)連接建立的過程,是不是簡單得幾近無聊?
我們來實(shí)際點(diǎn),寫個(gè)最簡單的客戶端代碼:
sockaddr_in addr;
memset( &addr, 0, sizeof( addr ) );
addr.sin_family = AF_INET;
addr.sin_port = htons( 80 );
/**//// 220.181.37.55 addr.sin_addr.s_addr = inet_addr( "220.181.37.55" );
printf( "%s : connecting to server.\n", _str_time() );
int err = connect( s, (sockaddr*) &addr, sizeof( addr ) );
主要就是connect。運(yùn)行程序前我們運(yùn)行windump:
windump -i 2 host 220.181.37.55
00:38:22.979229 IP noname.domain.4397 > 220.181.37.55.80: S 2523219966:2523219966(0) win 65535 <mss 1460,nop,nop,sackOK>
00:38:23.024254 IP 220.181.37.55.80 > noname.domain.4397: S 1277008647:1277008647(0) ack 2523219967 win 2920 <mss 1440,nop,nop,sackOK>
00:38:23.024338 IP noname.domain.4397 > 220.181.37.55.80: . ack 1 win 65535
如何分析windump的結(jié)果,建議參看<tcp/ip詳解>中對(duì)于tcpdump的描述。
建立連接的附加信息:
雖然SYN、ACK之類的報(bào)文沒有用戶數(shù)據(jù),但是TCP還是附加了其他信息。最為重要的就是附加的MSS值。這個(gè)
可以被協(xié)商的MSS值基本上就只在建立連接時(shí)協(xié)商。如以上數(shù)據(jù)表示,MSS為1460字節(jié)。
連接的意外:
連接的意外我大致分為兩種情況(也許還有更多情況):目的主機(jī)不可達(dá)、目的主機(jī)并沒有在指定端口監(jiān)聽。
當(dāng)目的主機(jī)不可達(dá)時(shí),也就是說,SYN報(bào)文段根本無法到達(dá)對(duì)方(如果你的機(jī)器根本沒插網(wǎng)線,你就不可達(dá)),
那么TCP收不到任何回復(fù)報(bào)文。這個(gè)時(shí)候,你會(huì)看到TCP中的定時(shí)器機(jī)制出現(xiàn)了。TCP對(duì)發(fā)出的SYN報(bào)文進(jìn)行
計(jì)時(shí),當(dāng)在指定時(shí)間內(nèi)沒有得到回復(fù)報(bào)文時(shí),TCP就會(huì)重傳剛才的SYN報(bào)文。通常,各種不同的TCP實(shí)現(xiàn)對(duì)于
這個(gè)超時(shí)值都不同,但是據(jù)我觀察,重傳次數(shù)基本上都是3次。例如,我連接一個(gè)不可達(dá)的主機(jī):
12:39:50.560690 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
12:39:53.538734 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
12:39:59.663726 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
發(fā)出了三個(gè)序號(hào)一樣的SYN報(bào)文,但是沒有得到一個(gè)回復(fù)報(bào)文(廢話)。每一個(gè)SYN報(bào)文之間的間隔時(shí)間都是
有規(guī)律的,在windows上是3秒6秒9秒12秒。上面的數(shù)據(jù)你看不到12秒這個(gè)數(shù)據(jù),因?yàn)檫@是第三個(gè)報(bào)文發(fā)出的
時(shí)間和connect返回錯(cuò)誤信息時(shí)的時(shí)間之差。另一方面,如果連接同一個(gè)網(wǎng)絡(luò),這個(gè)間隔時(shí)間又不同。例如
直接連局域網(wǎng),間隔時(shí)間就差不多為500ms。
(我強(qiáng)烈建議你能運(yùn)行windump去試驗(yàn)這里提到的每一個(gè)現(xiàn)象,如果你在ubuntu下使用tcpdump,記住sudo :D)
出現(xiàn)意外的第二種情況是如果主機(jī)數(shù)據(jù)包可達(dá),但是試圖連接的端口根本沒有監(jiān)聽,那么發(fā)送SYN報(bào)文的這
方會(huì)收到RST被設(shè)置的報(bào)文(connect也會(huì)返回相應(yīng)的信息給你),例如:
13:37:22.202532 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:22.202627 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 2417354282 win 0
13:37:22.711415 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:22.711498 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 1 win 0
13:37:23.367733 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:23.367826 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 1 win 0
可以看出,7AURORA-CCTEST.7100返回了RST報(bào)文給我,但是我這邊根本不在乎這個(gè)報(bào)文,繼續(xù)發(fā)送SYN報(bào)文。
三次過后connect就返回了。(數(shù)據(jù)反映的事實(shí)是這樣)
關(guān)于listen:
TCP服務(wù)器端會(huì)維護(hù)一個(gè)新連接的隊(duì)列。當(dāng)新連接上的客戶端三次握手完成時(shí),就會(huì)將其放入這個(gè)隊(duì)列。這個(gè)隊(duì)
列的大小是通過listen設(shè)置的。當(dāng)這個(gè)隊(duì)列滿時(shí),如果有新的客戶端試圖連接(發(fā)送SYN),服務(wù)器端丟棄報(bào)文,
同時(shí)不做任何回復(fù)。
總結(jié):
TCP連接的建立的相關(guān)要點(diǎn)就是這些(or more?)。正常情況下就是三次握手,非正常情況下就是SYN三次超時(shí),
以及收到RST報(bào)文卻被忽略。
本文轉(zhuǎn)自:http://www.shnenglu.com/kevinlynx/archive/2008/05/11/49482.html
摘要: 考慮一下多線程代碼,在設(shè)計(jì)上,App為了獲取更多的功能,從Window派生,而App同時(shí)為了獲取某個(gè)模塊的回調(diào)(所謂的Listener),App同時(shí)派生Listener,并將自己的指針交給另一個(gè)模塊,另一個(gè)模塊通過該指針多態(tài)回調(diào)到App的實(shí)現(xiàn)(對(duì)Listener規(guī)定的接口的implemention)。設(shè)計(jì)上只是一個(gè)很簡單的Listener回調(diào),在單線程模式下一切都很正常(后面我會(huì)羅列代碼),但是換...
閱讀全文