散列表(Hash table,也叫哈希表),是根據關鍵碼值(Key value)而直接進行訪問的數據結構。也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度。這個映射函數叫做散列函數,存放記錄的數組叫做散列表。
哈希表算法-哈希表的構造方法
1、直接定址法
例如:有一個從1到100歲的人口數字統計表,其中,年齡作為關鍵字,哈希函數取關鍵字自身。
但這種方法效率不高,時間復雜度是O(1),空間復雜度是O(n),n是關鍵字的個數
 哈希表算法
哈希表算法
2、數字分析法
有學生的生日數據如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
經分析,第一位,第二位,第三位重復的可能性大,取這三位造成沖突的機會增加,所以盡量不取前三位,取后三位比較好。
3、平方取中法
取關鍵字平方后的中間幾位為哈希地址。
4、折疊法
將關鍵字分割成位數相同的幾部分(最后一部分的位數可以不同),然后取這幾部分的疊加和(舍去進位)作為哈希地址,這方法稱為折疊法。
例如:每一種西文圖書都有一個國際標準圖書編號,它是一個10位的十進制數字,若要以它作關鍵字建立一個哈希表,當館藏書種類不到10,000時,可采用此法構造一個四位數的哈希函數。如果一本書的編號為0-442-20586-4,則:
 哈希表算法
哈希表算法
5、除留余數法
取關鍵字被某個不大于哈希表表長m的數p除后所得余數為哈希地址。
H(key)=key MOD p (p<=m)
6、隨機數法
選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即
H(key)=random(key) ,其中random為隨機函數。通常用于關鍵字長度不等時采用此法。
5、除留余數法
取關鍵字被某個不大于哈希表表長m的數p除后所得余數為哈希地址。
H(key)=key MOD p (p<=m)
6、隨機數法
選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即
H(key)=random(key) ,其中random為隨機函數。通常用于關鍵字長度不等時采用此法。
5、除留余數法
取關鍵字被某個不大于哈希表表長m的數p除后所得余數為哈希地址。
H(key)=key MOD p (p<=m)
6、隨機數法
選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即
H(key)=random(key) ,其中random為隨機函數。通常用于關鍵字長度不等時采用此法。
處理沖突的方法 通常有兩類方法處理沖突:開放定址(Open Addressing)法和拉鏈(Chaining)法。前者是將所有結點均存放在散列表T[0..m-1]中;后者通常是將互為同義詞的結點鏈成一個單鏈表,而將此鏈表的頭指針放在散列表T[0..m-1]中。1、開放定址法(1)開放地址法解決沖突的方法 用開放定址法解決沖突的做法是:當沖突發生時,使用某種探查(亦稱探測)技術在散列表中形成一個探查(測)序列。沿此序列逐個單元地查找,直到找到給定 的關鍵字,或者碰到一個開放的地址(即該地址單元為空)為止(若要插入,在探查到開放的地址,則可將待插入的新結點存人該地址單元)。查找時探查到開放的 地址則表明表中無待查的關鍵字,即查找失敗。注意:①用開放定址法建立散列表時,建表前須將表中所有單元(更嚴格地說,是指單元中存儲的關鍵字)置空。②空單元的表示與具體的應用相關。【例】關鍵字均為非負數時,可用"-1"來表示空單元,而關鍵字為字符串時,空單元應是空串。總之:應該用一個不會出現的關鍵字來表示空單元。(2)開放地址法的一般形式開放定址法的一般形式為: hi=(h(key)+di)%m 1≤i≤m-1 其中: ①h(key)為散列函數,di為增量序列,m為表長。 ②h(key)是初始的探查位置,后續的探查位置依次是hl,h2,…,hm-1,即h(key),hl,h2,…,hm-1形成了一個探查序列。 ③若令開放地址一般形式的i從0開始,并令d0=0,則h0=h(key),則有:hi=(h(key)+di)%m 0≤i≤m-1 探查序列可簡記為hi(0≤i≤m-1)。(3)開放地址法堆裝填因子的要求 開放定址法要求散列表的裝填因子α≤l,實用中取α為0.5到0.9之間的某個值為宜。(4)形成探測序列的方法 按照形成探查序列的方法不同,可將開放定址法區分為線性探查法、二次探查法、雙重散列法等。①線性探查法(Linear Probing)該方法的基本思想是:將散列表T[0..m-1]看成是一個循環向量,若初始探查的地址為d(即h(key)=d),則最長的探查序列為:d,d+l,d+2,…,m-1,0,1,…,d-1 即:探查時從地址d開始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循環到T[0],T[1],…,直到探查到T[d-1]為止。探查過程終止于三種情況: (1)若當前探查的單元為空,則表示查找失敗(若是插入則將key寫入其中); (2)若當前探查的單元中含有key,則查找成功,但對于插入意味著失敗; (3)若探查到T[d-1]時仍未發現空單元也未找到key,則無論是查找還是插入均意味著失敗(此時表滿)。利用開放地址法的一般形式,線性探查法的探查序列為:hi=(h(key)+i)%m 0≤i≤m-1 //即di=i利用線性探測法構造散列表【例9.1】已知一組關鍵字為(26,36,41,38,44,15,68,12,06,51),用除余法構造散列函數,用線性探查法解決沖突構造這組關鍵字的散列表。解答:為了減少沖突,通常令裝填因子α 由除余法的散列函數計算出的上述關鍵字序列的散列地址為(0,10,2,12,5,2,3,12,6,12)。 前5個關鍵字插入時,其相應的地址均為開放地址,故將它們直接插入T[0],T[10),T[2],T[12]和T[5]中。 當插入第6個關鍵字15時,其散列地址2(即h(15)=15%13=2)已被關鍵字41(15和41互為同義詞)占用。故探查h1=(2+1)%13=3,此地址開放,所以將15放入T[3]中。 當插入第7個關鍵字68時,其散列地址3已被非同義詞15先占用,故將其插入到T[4]中。 當插入第8個關鍵字12時,散列地址12已被同義詞38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址開放,可將12插入其中。 類似地,第9個關鍵字06直接插入T[6]中;而最后一個關鍵字51插人時,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。 構造散列表的具體過程【參見動畫演示】聚集或堆積現象用線性探查法解決沖突時,當表中i,i+1,…,i+k的位置上已有結點時,一個散列地址為i,i+1,…,i+k+1的結點都將插入在位置i+k+1 上。把這種散列地址不同的結點爭奪同一個后繼散列地址的現象稱為聚集或堆積(Clustering)。這將造成不是同義詞的結點也處在同一個探查序列之 中,從而增加了探查序列的長度,即增加了查找時間。若散列函數不好或裝填因子過大,都會使堆積現象加劇。【例】上例中,h(15)=2,h(68)=3,即15和68不是同義詞。但由于處理15和同義詞41的沖突時,15搶先占用了T[3],這就使得插入68時,這兩個本來不應該發生沖突的非同義詞之間也會發生沖突。 為了減少堆積的發生,不能像線性探查法那樣探查一個順序的地址序列(相當于順序查找),而應使探查序列跳躍式地散列在整個散列表中。②二次探查法(Quadratic Probing) 二次探查法的探查序列是:hi=(h(key)+i*i)%m 0≤i≤m-1 //即di=i2即探查序列為d=h(key),d+12,d+22,…,等。 該方法的缺陷是不易探查到整個散列空間。③雙重散列法(Double Hashing) 該方法是開放定址法中最好的方法之一,它的探查序列是:hi=(h(key)+i*h1(key))%m 0≤i≤m-1 //即di=i*h1(key) 即探查序列為:d=h(key),(d+h1(key))%m,(d+2h1(key))%m,…,等。 該方法使用了兩個散列函數h(key)和h1(key),故也稱為雙散列函數探查法。注意:定義h1(key)的方法較多,但無論采用什么方法定義,都必須使h1(key)的值和m互素,才能使發生沖突的同義詞地址均勻地分布在整個表中,否則可能造成同義詞地址的循環計算。【例】若m為素數,則h1(key)取1到m-1之間的任何數均與m互素,因此,我們可以簡單地將它定義為:h1(key)=key%(m-2)+1【例】對例9.1,我們可取h(key)=key%13,而h1(key)=key%11+1。【例】若m是2的方冪,則h1(key)可取1到m-1之間的任何奇數。2、拉鏈法(1)拉鏈法解決沖突的方法 拉鏈法解決沖突的做法是:將所有關鍵字為同義詞的結點鏈接在同一個單鏈表中。若選定的散列表長度為m,則可將散列表定義為一個由m個頭指針組成的指針數 組T[0..m-1]。凡是散列地址為i的結點,均插入到以T[i]為頭指針的單鏈表中。T中各分量的初值均應為空指針。在拉鏈法中,裝填因子α可以大于 1,但一般均取α≤1。【例9.2】已知一組關鍵字和選定的散列函數和例9.1相同,用拉鏈法解決沖突構造這組關鍵字的散列表。解答:不妨和例9.1類似,取表長為13,故散列函數為h(key)=key%13,散列表為T[0..12]。注意:當把h(key)=i的關鍵字插入第i個單鏈表時,既可插入在鏈表的頭上,也可以插在鏈表的尾上。這是因為必須確定key不在第i個鏈表時,才能將它插入 表中,所以也就知道鏈尾結點的地址。若采用將新關鍵字插入鏈尾的方式,依次把給定的這組關鍵字插入表中,則所得到的散列表如下圖所示。 具體構造過程【參見動畫演示】。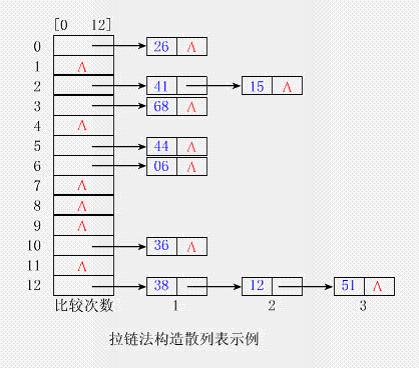 (2)拉鏈法的優點 與開放定址法相比,拉鏈法有如下幾個優點:(1)拉鏈法處理沖突簡單,且無堆積現象,即非同義詞決不會發生沖突,因此平均查找長度較短;(2)由于拉鏈法中各鏈表上的結點空間是動態申請的,故它更適合于造表前無法確定表長的情況;(3)開放定址法為減少沖突,要求裝填因子α較小,故當結點規模較大時會浪費很多空間。而拉鏈法中可取α≥1,且結點較大時,拉鏈法中增加的指針域可忽略不計,因此節省空間;(4)在用拉鏈法構造的散列表中,刪除結點的操作易于實現。只要簡單地刪去鏈表上相應的結點即可。而對開放地址法構造的散列表,刪除結點不能簡單地將 被刪結點的空間置為空,否則將截斷在它之后填人散列表的同義詞結點的查找路徑。這是因為各種開放地址法中,空地址單元(即開放地址)都是查找失敗的條件。 因此在用開放地址法處理沖突的散列表上執行刪除操作,只能在被刪結點上做刪除標記,而不能真正刪除結點。(3)拉鏈法的缺點 拉鏈法的缺點是:指針需要額外的空間,故當結點規模較小時,開放定址法較為節省空間,而若將節省的指針空間用來擴大散列表的規模,可使裝填因子變小,這又減少了開放定址法中的沖突,從而提高平均查找速度。
(2)拉鏈法的優點 與開放定址法相比,拉鏈法有如下幾個優點:(1)拉鏈法處理沖突簡單,且無堆積現象,即非同義詞決不會發生沖突,因此平均查找長度較短;(2)由于拉鏈法中各鏈表上的結點空間是動態申請的,故它更適合于造表前無法確定表長的情況;(3)開放定址法為減少沖突,要求裝填因子α較小,故當結點規模較大時會浪費很多空間。而拉鏈法中可取α≥1,且結點較大時,拉鏈法中增加的指針域可忽略不計,因此節省空間;(4)在用拉鏈法構造的散列表中,刪除結點的操作易于實現。只要簡單地刪去鏈表上相應的結點即可。而對開放地址法構造的散列表,刪除結點不能簡單地將 被刪結點的空間置為空,否則將截斷在它之后填人散列表的同義詞結點的查找路徑。這是因為各種開放地址法中,空地址單元(即開放地址)都是查找失敗的條件。 因此在用開放地址法處理沖突的散列表上執行刪除操作,只能在被刪結點上做刪除標記,而不能真正刪除結點。(3)拉鏈法的缺點 拉鏈法的缺點是:指針需要額外的空間,故當結點規模較小時,開放定址法較為節省空間,而若將節省的指針空間用來擴大散列表的規模,可使裝填因子變小,這又減少了開放定址法中的沖突,從而提高平均查找速度。本文轉自:http://bbs.csdn.net/topics/320198804
http://www.cnblogs.com/jiewei915/archive/2010/08/09/1796042.html
posted on 2012-11-21 14:22
王海光 閱讀(724)
評論(0) 編輯 收藏 引用 所屬分類:
算法