本文轉自:
http://www.cnblogs.com/jillzhang/archive/2006/11/02/547679.html
哈希表和哈希函數是大學數據結構中的課程,實際開發中我們經常用到Hashtable這種結構,當遇到鍵-值對存儲,采用Hashtable比ArrayList查找的性能高。為什么呢?我們在享受高性能的同時,需要付出什么代價(這幾天看紅頂商人胡雪巖,經典臺詞:在你享受這之前,必須受別人吃不了的苦,忍受別人受不了的屈辱),那么使用Hashtable是否就是一樁無本萬利的買賣呢?就此疑問,做以下分析,希望能拋磚引玉。
1)hash它為什么對于鍵-值查找性能高
學過數據結構的,都應該曉得,線性表和樹中,記錄在結構中的相對位置是隨機的,記錄和關鍵字之間不存在明確的關系,因此在查找記錄的時候,需要進行一系列的關鍵字比較,這種查找方式建立在比較的基礎之上,在.net中(Array,ArrayList,List)這些集合結構采用了上面的存儲方式。
比如,現在我們有一個班同學的數據,包括姓名,性別,年齡,學號等。假如數據有
| 姓名 |
性別 |
年齡 |
學號 |
| 張三 |
男 |
15 |
1 |
| 李四 |
女 |
14 |
2 |
| 王五 |
男 |
14 |
3 |
假如,我們按照姓名來查找,假設查找函數FindByName(string name);
1)查找“張三”
只需在第一行匹配一次。
2)查找"王五"
在第一行匹配,失敗,
在第二行匹配,失敗,
在第三行匹配,成功
上面兩種情況,分別分析了最好的情況,和最壞的情況,那么平均查找次數應該為 (1+3)/2=2次,即平均查找次數為(記錄總數+1)的1/2。
盡管有一些優化的算法,可以使查找排序效率增高,但是復雜度會保持在log2n的范圍之內。
如何更更快的進行查找呢?我們所期望的效果是一下子就定位到要找記錄的位置之上,這時候時間復雜度為1,查找最快。如果我們事先為每條記錄編一個序號,然后讓他們按號入位,我們又知道按照什么規則對這些記錄進行編號的話,如果我們再次查找某個記錄的時候,只需要先通過規則計算出該記錄的編號,然后根據編號,在記錄的線性隊列中,就可以輕易的找到記錄了 。
注意,上述的描述包含了兩個概念,一個是用于對學生進行編號的規則,在數據結構中,稱之為哈希函數,另外一個是按照規則為學生排列的順序結構,稱之為哈希表。
仍以上面的學生為例,假設學號就是規則,老師手上有一個規則表,在排座位的時候也按照這個規則來排序,查找李四,首先該教師會根據規則判斷出,李四的編號為2,就是在座位中的2號位置,直接走過去,“李四,哈哈,你小子,就是在這!”
看看大體流程:
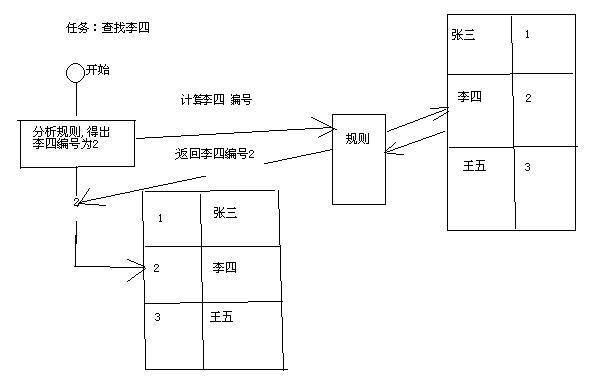
從上面的圖中,可以看出哈希表可以描述為兩個筒子,一個筒子用來裝記錄的位置編號,另外一個筒子用來裝記錄,另外存在一套規則,用來表述記錄與編號之間的聯系。這個規則通常是如何制定的呢?
a)直接定址法:
我在前一篇文章對GetHashCode()性能比較的問題中談到,對于整形的數據GetHashCode()函數返回的就是整形 本身,其實就是基于直接定址的方法,比如有一組0-100的數據,用來表示人的年齡
那么,采用直接定址的方法構成的哈希表為:
| 0 |
1 |
2 |
3 |
4 |
5 |
| 0歲 |
1歲 |
2歲 |
3歲 |
4歲 |
5歲 |
.....
這樣的一種定址方式,簡單方便,適用于元數據能夠用數字表述或者原數據具有鮮明順序關系的情形。
b)數字分析法:
有這樣一組數據,用于表述一些人的出生日期
| 年 |
月 |
日 |
| 75 |
10 |
1 |
| 75 |
12 |
10 |
| 75 |
02 |
14 |
分析一下,年和月的第一位數字基本相同,造成沖突的幾率非常大,而后面三位差別比較大,所以采用后三位
c)平方取中法
取關鍵字平方后的中間幾位作為哈希地址
d) 折疊法:
將關鍵字分割成位數相同的幾部分,最后一部分位數可以不相同,然后去這幾部分的疊加和(取出進位)作為哈希地址,比如有這樣的數據20-1445-4547-3
可以
5473
+ 4454
+ 201
= 10128
取出進位1,取0128為哈希地址
e)取余法
取關鍵字被某個不大于哈希表表長m的數p除后所得余數為哈希地址。H(key)=key MOD p (p<=m)
f) 隨機數法
選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即H(key)=random(key) ,其中random為隨機函數。通常用于關鍵字長度不等時采用此法。
總之,哈希函數的規則是:通過某種轉換關系,使關鍵字適度的分散到指定大小的的順序結構中。越分散,則以后查找的時間復雜度越小,空間復雜度越高。
2)使用hash,我們付出了什么?
hash是一種典型以空間換時間的算法,比如原來一個長度為100的數組,對其查找,只需要遍歷且匹配相應記錄即可,從空間復雜度上來看,假如數組存儲的是byte類型數據,那么該數組占用100byte空間。現在我們采用hash算法,我們前面說的hash必須有一個規則,約束鍵與存儲位置的關系,那么就需要一個固定長度的hash表,此時,仍然是100byte的數組,假設我們需要的100byte用來記錄鍵與位置的關系,那么總的空間為200byte,而且用于記錄規則的表大小會根據規則,大小可能是不定的,比如在lzw算法中,如果一個很長的用于記錄像素的byte數組,用來記錄位置與鍵關系的表空間,算法推薦為一個12bit能表述的整數大小,那么足夠長的像素數組,如何分散到這樣定長的表中呢,lzw算法采用的是可變長編碼,具體會在深入介紹lzw算法的時候介紹。
注:hash表最突出的問題在于沖突,就是兩個鍵值經過哈希函數計算出來的索引位置很可能相同,這個問題,下篇文章會令作闡述。
注:之所以會簡單得介紹了hash,是為了更好的學習lzw算法,學習lzw算法是為了更好的研究gif文件結構,最后,我將詳細的闡述一下gif文件是如何構成的,如何高效操作此種類型文件。
HASH如何處理沖突:
1)沖突是如何產生的?
上文中談到,哈希函數是指如何對關鍵字進行編址的規則,這里的關鍵字的范圍很廣,可視為無限集,如何保證無限集的原數據在編址的時候不會出現重復呢?規則本身無法實現這個目的。舉一個例子,仍然用班級同學做比喻,現有如下同學數據
張三,李四,王五,趙剛,吳露.....
假如我們編址規則為取姓氏中姓的開頭字母在字母表的相對位置作為地址,則會產生如下的哈希表
...
...
..
我們注意到,灰色背景標示的兩行里面,關鍵字王五,吳露被編到了同一個位置,關鍵字張三,趙剛也被編到了同一個位置。老師再拿號來找張三,座位上有兩個人,"你們倆誰是張三?"
2)如何解決沖突問題
既然不能避免沖突,那么如何解決沖突呢,顯然需要附加的步驟。通過這些步驟,以制定更多的規則來管理關鍵字集合,通常的辦法有:
a)開放地址法開放地執法有一個公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中,m為哈希表的表長。di 是產生沖突的時候的增量序列。如果di值可能為1,2,3,...m-1,稱線性探測再散列。
如果di取1,則每次沖突之后,向后移動1個位置.如果di取值可能為1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
稱二次探測再散列。如果di取值可能為偽隨機數列。稱偽隨機探測再散列。仍然以學生排號作為例子,
現有兩名同學,李四,吳用。李四與吳用事先已排好序,現新來一名同學,名字叫王五,對它進行編制
| 10.. |
.... |
22 |
.. |
.. |
25 |
| 李四.. |
.... |
吳用 |
.. |
.. |
25 |
趙剛未來之前
| 10.. |
.. |
22 |
23 |
25 |
| 李四.. |
|
吳用 |
王五 |
|
(a)線性探測再散列對趙剛進行編址,且di=1
| 10... |
20 |
22 |
.. |
25 |
| 李四.. |
王五 |
吳用 |
|
|
(b)二次探測再散列,且di=-2
| 1... |
10... |
22 |
.. |
25 |
| 王五.. |
李四.. |
吳用 |
|
|
(c)偽隨機探測再散列,偽隨機序列為:5,3,2 b)再哈希法 當發生沖突時,使用第二個、第三個、哈希函數計算地址,直到無沖突時。缺點:計算時間增加。
比如上面第一次按照姓首字母進行哈希,如果產生沖突可以按照姓字母首字母第二位進行哈希,再沖突,第三位,直到不沖突為止
c)鏈地址法
將所有關鍵字為同義詞的記錄存儲在同一線性鏈表中。如下:
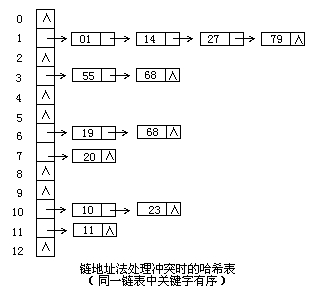
因此這種方法,可以近似的認為是筒子里面套筒子
d.建立一個公共溢出區假設哈希函數的值域為[0,m-1],則設向量HashTable[0..m-1]為基本表,另外設立存儲空間向量OverTable[0..v]用以存儲發生沖突的記錄。
經過以上方法,基本可以解決掉hash算法沖突的問題。
posted on 2012-05-28 15:54
王海光 閱讀(1348)
評論(0) 編輯 收藏 引用 所屬分類:
算法