當我們進一步研究類與對象的時候,難免的就要考慮到類本身的一些特點以及類與其它類之間的關系。在本專題開始之前,我們已經接觸到像一個類對象作為另一個類成員的嵌套關系了。本專題,我們就專心的研究一下類與類之間的繼承關系和其類本身的特點。
我們知道,類與對象的概念是來自于對現實事物的模擬,就像孩子用于其父母的一些特征,不論是木桌還是石桌都有桌子的特點。同樣,類與類之間自然的也應該擁有這些特點的。而擁有這些特點就使得我們代碼更加結構化,條理化,最大的好處則是:簡化我們的代碼,提高代碼的重用性。
好,不多廢話,先讓我們看看,這個專題大概要講些什么:
1、 體驗類的靜態多態性之重載
2、 構建類與類之間的父子關系及其訪問限制
3、 體驗類的動態多態性之虛函數
4、 淺析類的多繼承
5、 學習小結
從這個目錄可以看出這個專題內容非常的關鍵而且非常的龐雜。本來我是想將它們分成兩個專題,分別講述的。可是鑒于它們之間好多的知識點相互參雜,沒有辦法很好的分離,為了不給各位讀者遺留困惑,我決定將他們合到一起,希望各位能慢慢體會其中的奧秘,從根本上掌握它們。
好廢話不多說,我們進入正題。
一、 體驗類的靜態多態性之重載
重載,當時我理解了半天沒弄明白是什么意思,現在才知道,就是用模樣相同的東西實現不同的功能,下面我們分別看一下它們的用法。
1、 函數重載與缺省參數
A、函數重載的實現原理
假設,我們現在想要寫一個函數(如Exp01),它即可以計算整型數據又可以計算浮點數,那樣我們就得寫兩個求和函數,對于更復雜的情況,我們可能需要寫更多的函數,但是這個函數名該怎么起呢?它們本身實現的功能都差不多,只是針對不同的參數:
int sum_int(int nNum1, int nNum2)
{
return nNum1 + nNum2;
}
double sum_float(float nNum1, float nNum2)
{
return nNum1 + nNum2;
}
C++中為了簡化,就引入了函數重載的概念,大致要求如下:
1、 重載的函數必須有相同的函數名
2、 重載的函數不可以擁有相同的參數
這樣,我們的函數就可以寫成:
int sum (int nNum1, int nNum2)
{
return nNum1 + nNum2;
}
double sum (float nNum1, float nNum2)
{
return nNum1 + nNum2;
}
到現在,我們可以考慮一下,它們既然擁有相同的函數名,那他們怎么區分各個函數的呢?相信聰明的你一定根據上面的要求推測出來了,是的,名稱粉碎。很簡單,我們來驗證一下我的說法,繼續打開Exp01工程,點擊菜單欄的”project”à”settings”:
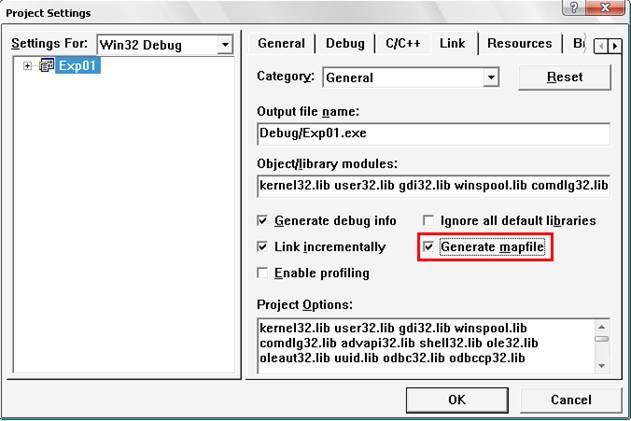
勾選“Generate mapfile”選項,然后重新編譯程序,到Debug目錄下找到Exp01.map文件,用記事本打開它:
|
Address
|
Publics by Value
|
Rva+Base
|
Lib:Obj
|
|
0001:00000050
|
?sum_int@@YAHHH@Z
|
00401050
|
f
|
Exp01.obj
|
|
0001:00000080
|
?sum_float@@YAMMM@Z
|
00401080
|
f
|
Exp01.obj
|
|
0001:000000b0
|
?TestCFun@@YAXXZ
|
004010b0
|
f
|
Exp01.obj
|
|
0001:00000130
|
?sum@@YAHHH@Z
|
00401130
|
f
|
Exp01.obj
|
|
0001:00000160
|
?sum@@YAMMM@Z
|
00401160
|
f
|
Exp01.obj
|
|
0001:00000190
|
?TestCplusFun@@YAXXZ
|
00401190
|
f
|
Exp01.obj
|
|
0001:00000210
|
_main
|
00401210
|
f
|
Exp01.obj
|
哈哈,將參數信息與函數名粉碎了并整合成了一個新的函數名,今后,我們在編寫C++程序的時候,調試、排錯都難免與這些粉碎后的函數名打交道,好多的朋友為了解決這個問題想出了各種方法,記得在看雪壇子上有一篇名叫《史上最牛資料助你解惑c++調試》的文章,大致上把粉碎后的函數名各部分的含義都解釋出來了,其實沒有這個必要的,我們用的VC開發環境中已經提供了一個工具(UNDNAME.EXE),它可以解析這些粉碎后的函數,當然如果我們逆向分析它,很容易就可以知道,其實就是調用一個API函數:
UnDecorateSymbolName(m_szFuncName, m_szResultInfo.GetBuffer(0), MAX_PATH,\
UNDNAME_32_BIT_DECODE|UNDNAME_NO_RETURN_UDT_MODEL|\
UNDNAME_NO_MEMBER_TYPE|UNDNAME_NO_THROW_SIGNATURES|\
UNDNAME_NO_THISTYPE|UNDNAME_NO_CV_THISTYPE);
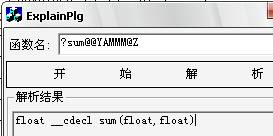
OK,我們隨便輸入粉碎的一個函數名看看效果:
B、缺省參數
如果用Win32API寫過程序的朋友一定知道,好多的函數存在許多參數,而且大部分都是NULL,倘若我們有個函數大部分的時候,某個參數都是固定值,僅有的時候需要改變一下,而我們每次調用它時都要很費勁的輸入參數豈不是很痛苦?C++提供了一個給參數加默認參數的功能,例如:
double sum (float nNum1, float nNum2 = 10);
我們調用時,默認情況下,我們只需要給它第一個參數傳遞參數即可,但是使用這個功能時需要注意一些事項,以免出現莫名其妙的錯誤,下面我簡單的列舉一下大家了解就好。
A、 默認參數只要寫在函數聲明中即可。
B、 默認參數應盡量靠近函數參數列表的最右邊,以防止二義性。比如
double sum (float nNum2 = 10,float nNum1);
這樣的函數聲明,我們調用時:sum(15);程序就有可能無法匹配正確的函數而出現編譯錯誤。
2、 淺析運算符重載
運算符重載也是C++多態性的基本體現,在我們日常的編碼過程中,我們經常進行+、—、*、/等操作。在C++中,要想讓我們定義的類對象也支持這些操作,以簡化我們的代碼。這就用到了運算符重載。
比如,我們要讓一個日期對象減去另一個日期對象以便得到他們之間的時間差。再如:我們要讓一個字符串通過“+”來連接另一個字符串……
要想實現運算符重載,我們一般用到operator關鍵字,具體用法如下:
返回值 operator 運算符(參數列表)
{
// code
}
例如:
CMyString Operator +(CMyString & csStr)
{
int nTmpLen = strlen(msString.GetData());
if (m_nSpace <= m_nLen+nTmpLen)
{
char *tmpp = new char[m_nLen+nTmpLen+sizeof(char)*2];
strcpy(tmpp, m_szBuffer);
strcat(tmpp, msString.GetData());
delete[] m_szBuffer;
m_szBuffer = tmpp;
}
}
當然,運算符重載也存在一些限制,在我們編碼的過程中需要注意一下:
A、 不能使用不存在的運算符(如:@、**等等)
B、 “::、. 、.*”運算符不可以被重載。
C、 不能改變運算符原有的優先級和結核性。
D、不能改變操作數的數量。
E、 只能針對自定義的類型做重載。
F、 保留運算符原本的含義
二、 構建類與類之間的父子關系及其訪問限制
1、 繼承代碼的定義方法及其內存布局
看代碼:
// 基類
class BaseCls
{
private:
int m_na;
int m_nb;
public:
int GetAValue() const
{
return m_na;
}
int GetBValue() const
{
return m_nb;
}
void SetAValue(int nA);
void SetBValue(int nB);
BaseCls();
~BaseCls();
};
相信大家看明白上面的代碼應該是非常容易的。OK,我們繼續:
class SubCls : public BaseCls // 以共有的方式繼承BaseCls
{
private:
int m_nc;
public:
int GetCValue() const
{
return m_nc;
}
void SetCValue(int nC);
SubCls();
~SubCls();
};
OK,倘若我們要給SubCls增加一個成員函數,來計算m_nA+m_nB+m_nC的和:
int SubCls::GetSum()
{
//return m_na+m_nb+m_nc; // 沒有權限訪問m_na、m_nb
return GetAValue()+ GetBValue() + m_nc;
}
現在我們來看下它的內存結構:
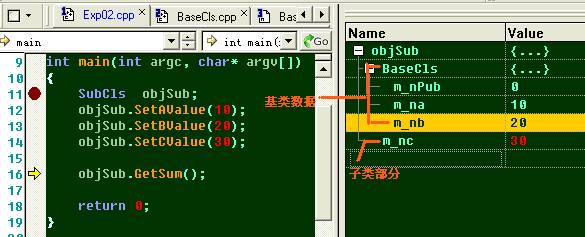
由此可見,對于簡單的繼承關系,其子類內存布局,是先有基類數據成員,然后再是子類的數據成員,當然后面講的復雜情況,本規律不一定成立。
2、 關于繼承權限的說明及其改變
什么時候SubCls類才能直接使用父類中的變量呢,前人已經為我們總結了一個張表:
|
基類訪問屬性
繼承權限
|
public
|
protected
|
private
|
|
public
|
public
|
protected
|
不可訪問
|
|
protected
|
protected
|
protected
|
不可訪問
|
|
private
|
private
|
private
|
不可訪問
|
對于基類的私有成員,它的子類都無法直接訪問,只有通過相應的Get/Set方法來操作它們(get/set方法必須是public/protected權限)。換句話說:基類的private成員雖然不能直接被訪問,但是他們在子類對象的內存中仍然存在,可以通過指針來讀取它們。
當一個類中的成員變量為publi權限,但它子類繼承它時采用了priva方式繼承,這樣它就變成了private權限,我們要讓它繼續變為public權限,可以對它重新調整。比如:
class BaseCls
{
public:
int m_nPub;
};
class SubCls : private BaseCls
{
public:
using BaseCls::b3; // 調整變量權限為publi
}
注意,調整成員訪問權限的前提是:基類成員在子類中是可見的,沒有被隔離。
三、 體驗類的動態多態性之虛函數
之前我們講述的多態性,像函數重載,運算符重載,拷貝構造等都是在編譯器完成的多態性,我們稱之為靜態多太性,現在我們討論下運行期間才體現出來的多態性——動態多態性。我將分成幾個不同的小結,逐步深入的描述我對虛函數的理解。
1、 什么是虛函數,用在什么場合
之所以稱為虛函數,是因為此類函數在被調用之前誰都不確定它會被誰調用。換句話說就是:調用虛函數的方式不同于以往的立即數直接尋址,而是采用了寄存器間接尋址的方式,因此它調用的地址并不固定。所以,虛函數可以通過相同的函數實現不同的功能。這便是虛函數的特點。
我可以舉個例子來說明虛函數的用途:
假如,我們有一個家具類,他有一個成員函數來獲取家具的價格,如果家具類派生出了桌子、椅子、床、沙發……各種對象不計其數。這時,如果我們要實現一個函數來輸出用戶指定“家具”的價格,我想最常規的做法應該是用一個很深的if……else if ……else結構,當然,如果你看過我寫的switch的學習筆記的話,你或許會用一個很大的switch結構來判斷用戶選擇了那個家具,然后創建相應的對象,調用其獲取價格的方法,打印輸出……
當然,如果有虛函數,我們就不需要這樣費事的寫程序了,我們大可以創建一個家具類的對象指針,然后讓它直接指向用戶選擇的家具對象,當用戶選擇“家具”時,我們不需要確定用戶選擇的是哪個“家具”,只需要簡單的調用基類的虛函數即可。程序在運行時,會自動的根據用戶的不同選擇調用不同子類的虛函數……
2、 怎樣使用虛函數
說了一堆的廢話,或許你真的知道虛函數是怎么回事了,或許你一定很好奇虛函數是怎么實現的,也或許,你可能更加疑惑:到底什么是虛函數了。
都沒關系,我們先帶著這些問題,一步步的來,先看看如何定義和使用一個虛函數以簡化我們的程序。
要使用虛函數,異常的簡單,你只要在要制定為虛函數的聲明前加上Virtual關鍵字,當然,在使用的過程中需要遵循如下規則:
a) 虛函數必須在繼承的情況下使用。
b) 若基類中有一個虛函數,那它所派生的所有子類中所有函數名、參數、返回值都相同的成員方法都是虛函數,不論它們的聲明前是否有Virtual關鍵字。
c) 只有類的成員方法才能聲明為虛函數,但是:靜態、內聯、構造除外。
d) 析構函數建議聲明為虛函數。
e) 調用虛函數時,必須要通過基類對象的指針或者引用來完成調用,否則無法發揮虛函數的特性。
如:下來程序(見Exp03的代碼)
class CBaseCls
{
public:
int m_nBaseData;
virtual void fun(int x)
{
printf("%d in BaseCls...\r\n", x);
}
};
class CSubCls : public CBaseCls
{
public:
int m_nSubData;
// 由于它的參數返回值還有函數名等都與父類的虛函數相同,所以它也是虛函數。
void fun(int x)
{
printf("%d in subclass...\r\n", x);
}
};
相信上面的代碼,你應該能看明白吧,我們按照上面列出的規范,使用一下這兩個類:
int main(int argc, char* argv[])
{
//CSubCls *pSub = (CSubCls*)new CBaseCls;
//pSub->fun(5);
CBaseCls objBase;
CSubCls objSub;
CBaseCls *pBase = new CSubCls;
pBase->fun(5);
return 0;
}
運行結果:
3、 虛函數的運行機制
OK,我們調試一下這段代碼,看看虛函數的這鐘特性到底是怎么實現的:
32: CBaseCls objBase;
0040EDDD lea ecx,[ebp-14h] ; CBaseCls的this指針
0040EDE0 call @ILT+15(CBaseCls::CBaseCls) (00401014)
33: CSubCls objSub;
0040EDE5 lea ecx,[ebp-20h]
0040EDE8 call @ILT+0(CSubCls::CSubCls) (00401005)
34:
35: CBaseCls *pBase = new CSubCls;
0040EDED push 0Ch
0040EDEF call operator new (00401350) ; new一個空間
0040EDF4 add esp,4
0040EDF7 mov dword ptr [ebp-2Ch],eax
0040EDFA mov dword ptr [ebp-4],0
0040EE01 cmp dword ptr [ebp-2Ch],0
0040EE05 je main+64h (0040ee14)
0040EE07 mov ecx,dword ptr [ebp-2Ch] ; 子類的this
0040EE0A call @ILT+0(CSubCls::CSubCls) (00401005) ; 調用子類構造創建子類的臨時對象
0040EE0F mov dword ptr [ebp-70h],eax ; 保存子類的this指針
0040EE12 jmp main+6Bh (0040ee1b)
0040EE14 mov dword ptr [ebp-70h],0
0040EE1B mov eax,dword ptr [ebp-70h] ; 子類的this
0040EE1E mov dword ptr [ebp-28h],eax ; 子類的this
0040EE21 mov dword ptr [ebp-4],0FFFFFFFFh
0040EE28 mov ecx,dword ptr [ebp-28h] ; 子類的this
0040EE2B mov dword ptr [ebp-24h],ecx ; 可見,[ebp-24h]中是子類的this
36: pBase->fun(5);
0040EE2E mov esi,esp
0040EE30 push 5
0040EE32 mov eax,dword ptr [ebp-24h]
0040EE35 mov edx,dword ptr [eax] ; this指針去內容(也就是虛函數指針表簡稱虛表)
0040EE37 mov ecx,dword ptr [ebp-24h] ; 傳遞this指針
0040EE3A call dword ptr [edx] ; 調用虛表的第0項函數
0040EE3C cmp esi,esp
這時,我們應該發現,我們對象的內存結構應該是這樣的(比以前的內存結構多了個虛函數表的指針):
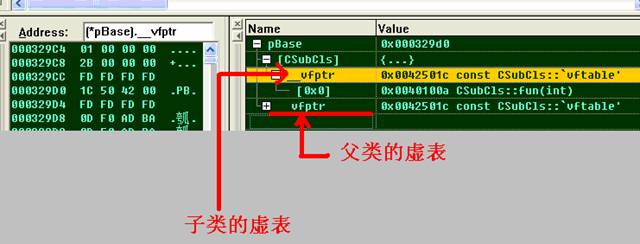
由此可知,this指針指向一個函數表的首地址,這個表的每一項都是一個函數地址(函數指針),換句話說,虛函數的指針都被存放在this指向的這個虛函數表中。
現在,我們再回頭看上述的程序,猜測一下他的編譯過程。
A、 編譯父類時,先編譯代碼,最后把虛函數的首地址加入到虛函數表中。并將虛表的首地址作為本類的第一個數據成員
B、 編譯子類時,先編譯子類的代碼,再把父類的虛函數表拷貝過來,檢查子類中重新實現了那些虛函數,一次在子類的虛表中將重新實現的虛函數表項覆蓋掉并增加子類中心實現的虛函數地址。
那它的執行過程已經是可以明白的說明了:
A、 我們先分析下上述代碼的執行:
CBaseCls *pBase = new CSubCls; // 讓一個父類指針指向子類的實例
pBase->fun(5); //調用虛函數時,傳遞的是子類的this指針,也就是子類的虛表
再根據我們上面的分析,很自然的,代碼將調用子類的函數,輸出的結果也自然的是子類虛函數的結果。
B、 倘若,我們將調用的代碼換一下:用子類的指針指向父類的實例。
CSubCls *pSub = new CBaseCls; // 編譯出錯,需要強轉
pSub ->fun(5); //輸出的是父類的虛函數的結果
編譯器不支持父類對象向子類類型的轉換,我們想一下它們的內存結構就可以知道,一般子類的數據成員比父類的多,父類想子類轉換以后,其指針取成員會存在安全隱患。
C、 由此,我們可以得出結論:
a) 調用虛函數時,傳遞不同類實例的this指針,就調用傳遞this對象的虛函數。
b) 虛函數的調用方式:
用基類的指針或引用指向子類的實例,通過基類的指針調用子類的虛函數。
說明:一定要用指針或引用去調用虛函數,否則可能會失去虛函數的特性。
4、 模擬實現虛函數機制
到這里,我想你一定對虛函數有一定的了解了,為了加深印象,我們不妨手工用C語言類模擬一個虛函數出來(代碼見Exp04):
#include <stdio.h>
// 定義函數指針
class CPerson;
typedef void (*PFUN_TYPE)();
typedef void (CPerson::*PBASEFUN_TYPE)();
// 基類的成員。
class CPerson
{
public:
PBASEFUN_TYPE *m_pFunPoint;//定義函數指針
CPerson()
{
m_pFunPoint = (PBASEFUN_TYPE*)new PFUN_TYPE[2]; // 保存虛函數指針表
m_pFunPoint[0] = (PBASEFUN_TYPE)vsayHello; // 填充虛表項
m_pFunPoint[1] = (PBASEFUN_TYPE)vsayGoodbye;
}
~CPerson()
{
// 釋放資源,防止內存泄露
delete [] m_pFunPoint;
}
void sayHello()
{
printf("person::Hello\r\n");
}
void sayGoodbye()
{
printf("person::Goodbye\r\n");
}
void vsayHello()
{
sayHello();
}
void vsayGoodbye()
{
sayGoodbye();
}
};
class CStudent:public CPerson
{
public:
CStudent()
{
// 填充虛表項,覆蓋父類的成員地址
m_pFunPoint[0] = (PBASEFUN_TYPE)vsayHello;
m_pFunPoint[1] = (PBASEFUN_TYPE)vsayGoodbye;
}
void sayHello()
{
printf("CStudent::Hello\r\n");
}
void sayGoodbye()
{
printf("CStudent::Goodbye\r\n");
}
void vsayHello()
{
sayHello();
}
void vsayGoodbye()
{
sayGoodbye();
}
};
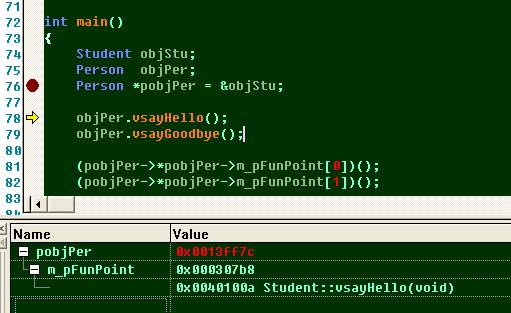
int main()
{
CStudent objStu;
CPerson objPer;
CPerson *pobjPer = &objStu; // 用基類指針指向子類對象
objPer.vsayHello(); // 用基類對象直接調用
objPer.vsayGoodbye();
(pobjPer->*pobjPer->m_pFunPoint[0])(); // 用基類指針調用
(pobjPer->*pobjPer->m_pFunPoint[1])();
return 0;
}
運行結果:
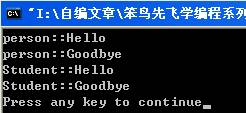
四、 淺析類的多繼承
一個類可以從多個基類中派生,也就是說:一個類可以同時擁有多個類的特性,是的,他有多個基類。這樣的繼承結構叫作“多繼承”,最典型的例子就是 沙發-床了:
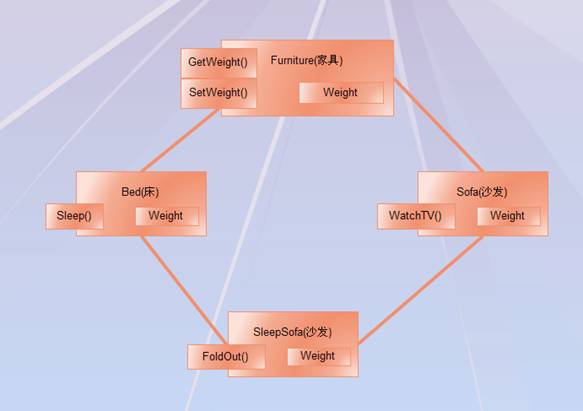
1、 基本概念
相信上圖描述的結構大家應該都可以看明白的,SleepSofa類繼承自Bed和Sofa兩個類,因此,SleepSofa類擁有這兩個類的特性,但在實際編碼中會存在如下幾個問題。
a) SleepSofa類該如何定義?
Class SleepSofa : public Bed, public Sofa
{
….
}
構造順序為:Bed à sofa à sleepsofa (也就是書寫的順序)
b) Bed和Sofa類中都有Weight屬性頁都有GetWeight和SetWeight方法,在SleepSofa類中使用這些屬性和方法時,如何確定調用的是哪個類的成員?
可以使用完全限定名的方式,比如:
Sleepsofa objsofa;
Objsofa.Bed::SetWeight(); // 給方法加上一個作用域,問題就解決了。
2、 虛繼承
上節對多繼承作了大概的描述,相信大家對SleepSofa類有了大概的認識,我們回頭仔細看下Furniture類:
倘若,我們定義一個SleepSofa對象,讓我們分析一下它的構造過程:它會構造Bed類和Sofa類,但Bed類和Sofa類都有一個父類,因此Furniture類被構造了兩次,這是不合理的,因此,我們引入了虛繼承的概念。
class Furniture{……};
class Bed : virtual public Furniture{……}; // 這里我們使用虛繼承
class Sofa : virtual public Furniture{……};// 這里我們使用虛繼承
class sleepSofa : public Bed, public Sofa {……};
這樣,Furniture類就之構造一次了……
3、 總結下繼承情況中子類對象的內存結構
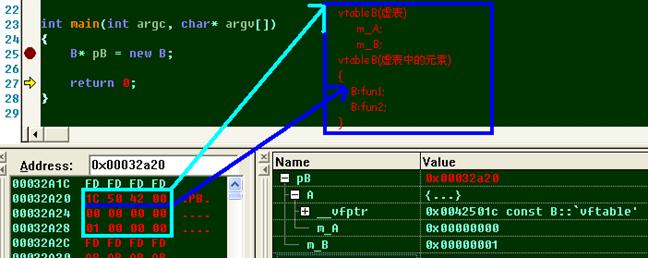
A. 單繼承情況下子類實例的內存結構
// 描述單繼承情況下子類實例的內存結構
#include "stdafx.h"
class A
{
public:
A(){m_A = 0;}
virtual fun1(){};
int m_A;
};
class B:public A
{
public:
B(){m_B = 1;}
virtual fun1(){};
virtual fun2(){};
int m_B;
};
int main(int argc, char* argv[])
{
B* pB = new B;
return 0;
}
B. 多繼承情況下子類實例的內存結構
// 描述多繼承情況下子類實例的內存結構
#include "stdafx.h"
#include <stdio.h>
class A
{
public:
A(){m_A = 1;};
~A(){};
virtual int funA(){printf("in funA\r\n"); return 0;};
int m_A;
};
class B
{
public:
B(){m_B = 2;};
~B(){};
virtual int funB(){printf("in funB\r\n"); return 0;};
int m_B;
};
class C
{
public:
C(){m_C = 3;};
~C(){};
virtual int funC(){printf("in funC\r\n"); return 0;};
int m_C;
};
class D:public A,public B,public C
{
public:
D(){m_D = 4;};
~D(){};
virtual int funD(){printf("in funD\r\n"); return 0;};
int m_D;
};

C. 部分虛繼承的情況下子類實例的內存結構
// 描述部分虛繼承的情況下,子類實例的內存結構
#include "stdafx.h"
class A
{
public:
A(){m_A = 0;};
virtual funA(){};
int m_A;
};
class B
{
public:
B(){m_B = 1;};
virtual funB(){};
int m_B;
};
class C
{
public:
C(){m_C = 2;};
virtual funC(){};
int m_C;
};
class D:virtual public A,public B,public C
{
public:
D(){m_D = 3;};
virtual funD(){};
int m_D;
};
int main(int argc, char* argv[])
{
D* pD = new D;
return 0;
}
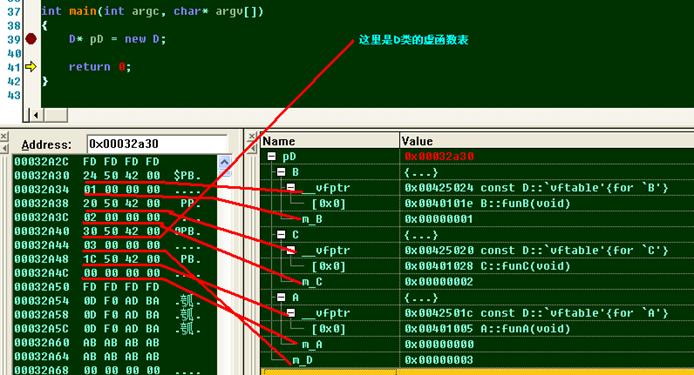
D. 全部虛繼承的情況下,子類實例的內存結構
// 描述全部虛繼承的情況下,子類實例的內存結構
#include "stdafx.h"
class A
{
public:
A(){m_A = 0;}
virtual funA(){};
int m_A;
};
class B
{
public:
B(){m_B = 1;}
virtual funB(){};
int m_B;
};
class C:virtual public A,virtual public B
{
public:
C(){m_C = 2;}
virtual funC(){};
int m_C;
};
int main(int argc, char* argv[])
{
C* pC = new C;
return 0;
}
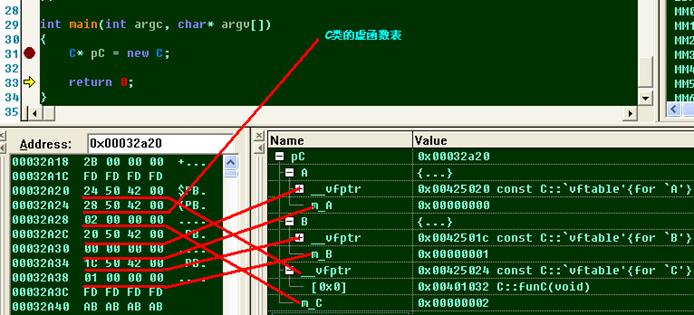
E. 菱形結構繼承關系下子類實例的內存結構
// 描述菱形結構繼承關系下子類實例的內存結構
#include "stdafx.h"
class A
{
public:
A(){m_A = 0;}
virtual funA(){};
int m_A;
};
class B :virtual public A
{
public:
B(){m_B = 1;}
virtual funB(){};
int m_B;
};
class C :virtual public A
{
public:
C(){m_C = 2;}
virtual funC(){};
int m_C;
};
class D: public B, public C
{
public:
D(){m_D = 3;}
virtual funD(){};
int m_D;
};
int main(int argc, char* argv[])
{
D* pD = new D;
return 0;
}
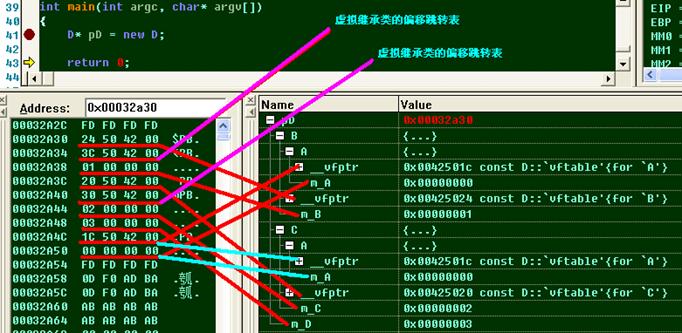
上圖中,多出兩個未知的地址,它們并不是類成員的地址,如果我們跟蹤它,得到的結果如下圖:
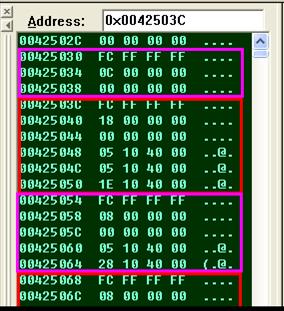
如果留意觀察這兩個地址,就會發現,它們都緊跟著虛繼承的兩個子類:
A、00425024 à 是B類的虛表指針,B類虛繼承與A類
B、00425020 à 是C類的虛表指針,C類虛繼承與A類
知道了這兩點,我們先跟蹤0x00425030這個地址,我們得到一個-4和0x0C兩個數,這兩個數字很難不讓我們想到這個是偏移。
0x00425030 所在的位置減去4,就是C類的虛表指針。
0x00425030 所在的位置加上C,就是A類的虛表指針。
同理,我們在看3C這個位置:
0x0042503C 所在的位置減去4,就是B類的虛表指針。
0x0042503C 所在的位置加上0x18,就是A類的虛表指針
由此,我們可以大膽的猜測,這個偏移表是用來關聯虛繼承的基類和子類的,比如:
0x00425030這個偏移表,將A類和C類的虛繼承關系聯系到了一起,0x0042503C這個偏移表則是把A類和B類聯系到了一起。
4、 總結下多繼承情況下對象的構造順序
A. 虛繼承的構造函數按照被繼承的順序先構造。
B. 非虛繼承的構造函數按照被繼承的順序再構造。
C. 成員對象的構造函數按照聲明順序構造。
D. 類自己的構造函數最后構造。
五、 學習小結
本專題本來是想分成兩個專題分別講述類的繼承和多態性的。可是由于這兩個特性聯系的實在是太緊密,這樣穿插在一起,我著實沒想到更好的分類方法。索性將這兩個特性放在一個專題中一并講述。
但是我的言語表達能力實在是有限,總是不能把文章中的知識點講述到我想象中的那樣簡單、清晰,這個專題,不求能教給大家點什么,只希望在大家的學習過程中能起到墊腳石的作用。我就心滿意足了。
本專題的內容可以說是C++語言的精華所在,講述的知識雖然重要,但也僅限于我現在這個知識層面上的理解,或許過些日子又會發現更多更重要的知識我沒有講到或者講的不對……
如果你在閱讀本文章個過程中,如果發現我哪里講的不對,麻煩通知我,以便我及時改正,以免誤人子弟……
—— besterChen
2010年5月20日星期四