
之前曾經
為Parser Combinator寫過一篇教程。這次為了處理
Vczh Library++新設計的ManagedX托管語言,我為Parser Combinator新增了三個組合子。
第一個是def,第二個是let。它們組合使用。def(pattern, defaultValue)的意思是,如果pattern成功了那么返回pattern的分析結構,否則返回defaultValue。let(pattern, value)的意思是,如果pattern成功了則返回value,否則失敗。因此他們可以一起使用。舉個例子,ManagedX跟C#一樣具有5種type accessor:public, protected, protected internal, private, internal。其中四種accessor的文法類型是token,剩下的protected internal則是tuple<token, token>。因此我們無法很方便地為它寫一個記號到語法樹的轉換函數。而且對于缺省情況要返回private的這種行為,在EBNF+handler上直接表達出來也比較困難。當def和let還不存在的時候,我們需要這么寫:
accessor = (PUBLIC[ToAccessor] | PROTECTED[ToAccessor] | PRIVATE[ToAccessor] | INTERNAL[ToAccessor] | (PROTECTED + INTERNAL)[ToProtectedInternal])[ToAccessorWithDefault];
這個時候我們需要創建三個函數,分別是ToAccessor、ToProtectedInternal和ToAccessorWithDefault。因為accessor本身不是一個重要的語法元素,所以我們不需要為accessor記錄一些源代碼的位置信息。表達式則需要位置信息,這可以在我們產生錯誤信息的時候知道錯誤發生在源代碼中的位置。而accessor總是直接屬于某一個重要的語法元素的,所以不需要保存。如果不需要保存位置信息的話,那么一個ToXXX的函數其實就是沒有必要的。這個時候可以讓def和let來簡化操作:
accessor = def(
let(PUBLIC, acc::Public) | let(PROTECTED, acc::Protected) | let(PRIVATE, acc::Private) | let(INTERNAL, acc::Internal) | let(PROTECTED+INTERNAL, acc::ProtectedInternal), acc::Private);
看起來好像差不多,但實際上我們已經減少了那三個不需要存在的函數。
============================無恥的分割線====================================
第三個是binop。做這個主要是因為那個通用的lrec(左遞歸組合子)在對付帶大量括號的表達式的時候性能表現不好。這里稍微解釋一下原因。假設我們的語言有>、+、*和()四種操作符,那文法一般都寫成:
exp0 = NUMBER | '(' exp3 ')'
exp1 = exp1 '*' exp0 | exp0
exp2 = exp2 '+' exp1 | exp1
exp3 = exp3 '>' exp2 | exp2
因此可以很容易的知道,當我們分析1*2*3的時候,走的是下面的路子:
exp3
= exp2
= exp1
= exp1 '*' exp0
= exp1 '*' exp1 '*' exp0
= '1' '*' '2' '*' '3'
現在我們做一個簡單的變換,把1*2*3變成((1*2)*3)。意義不變,但是分析的路徑卻完全改變了:
exp3
= exp2
= exp1
= exp0
= '(' exp3 ')'
= '(' exp2 ')'
= '(' exp1 ')'
= '(' exp1 '*' exp0 ')'
= '(' exo0 '*' exp0 ')'
= '(' '(' exp3 ')' '*' exp0 ')'
= '(' '(' exp2 ')' '*' exp0 ')'
= '(' '(' exp1 ')' '*' exp0 ')'
= '(' '(' exp1 '*' exp0 ')' '*' exp0 ')'
= '(' '(' exp0 '*' exp0 ')' '*' exp0 ')'
= '(' '(' '1' '*' '2' ')' '*' '3' ')'
咋一看好像沒什么區別,但是對于ManagedX這種有十幾個優先級的操作符的語言來說,如果給一個復雜的表達式的每一個節點都加上括號,等于一下子增加了上千層文法的遞歸分析。由于Parser Combinator是遞歸向下分析器,因此路徑有這么長,那么遞歸的層次也會有這么長。而且為了避免boost::Spirit那個天殺的超慢編譯速度的問題,這里犧牲了一點點性能,將組合字的Parse函數做成了虛函數,所以編譯速度提高了超多。一般來說一個需要編譯一個半小時的boost::Spirit語法分析器用我的庫只需要幾秒鐘就可以編譯完了。不過現在卻帶來了問題。括號一多,性能下降的比較明顯。但是我們顯然不能因噎廢食,因此我決定往Parser Combinator提供一個手寫的帶優先級的左右結合一二元操作符語法分析器。為了將這個手寫的分析器插入框架并變得通用,我決定采用下面的結構。下面的代碼是從ManagedX的語法分析器中截取出來的:
1 expression = binop(exp0)
2 .pre(ADD_SUB, ToPreUnary).pre(NOT_BITNOT, ToPreUnary).pre(INC_DEC, ToPreUnary).precedence()
3 .lbin(MUL_DIV_MOD, ToBinary).precedence()
4 .lbin(ADD_SUB, ToBinary).precedence()
5 .lbin(LT << LT, ToBinaryShift).lbin(GT >> GT, ToBinaryShift).precedence()
6 .lbin(LT, ToBinary).lbin(LE, ToBinary).lbin(GT, ToBinary).lbin(GE, ToBinary).precedence()
7 .post(AS + type, ToCasting).post(IS + type, ToIsType).precedence()
8 .lbin(EE, ToBinary).lbin(NE, ToBinary).precedence()
9 .lbin(BITAND, ToBinary).precedence()
10 .lbin(XOR, ToBinary).precedence()
11 .lbin(BITOR, ToBinary).precedence()
12 .lbin(AND, ToBinary).precedence()
13 .lbin(OR, ToBinary).precedence()
14 .lbin(QQ, ToNullChoice).precedence()
15 .lbin(QT + (expression << COLON(NeedColon)), ToChoice).precedence()
16 .rbin(OPEQ, ToBinaryEq).rbin(EQ, ToAssignment).precedence()
17 ;
binop組合子的參數代表整個帶優先級的最高優先級表達式組合字(參考上面給出的>+*()文法,可以知道這里的exp0是什么意思)。binop給出了四個子組合子,分別是pre(前綴一元操作符)、post(后綴一元操作符)、lbin(左結合二元操作符)和rbin(右結合二元操作符)。precedence代表一個優先級的所有操作符定義結束。這里我做了一個小限制,也就是每一個precedence只能包含pre、post、lbin和rbin的其中一種。實踐表明這種限制不會帶來任何問題。因此這里我們得到了一張操作符和優先級的關系表。到了這里我們就可以在Parser Combinator的框架下寫一個手寫的語法分析器(下載
源代碼并打開Library\Combinator\_Binop.h)來做了。至于如何手寫語法分析器,我之前給出了
一篇文章,大家可以參考這個來閱讀_Binop.h。
binop比起簡單的用lrec做同樣的事情,性能在debug下提高了100多倍,release下面則少一點。到了這里,Parser Combinator重新滿足了性能要求,我們可以放心大膽的用一點點無所謂的性能換取一千多倍的編譯時間了。在這里貼出當binop還沒出現的時候我用lrec給出的操作符文法的實現:
1 exp1 = exp0
2 | ((ADD_SUB | NOT_BITNOT | INC_DEC) + exp1)[ToUnary]
3 ;
4
5 exp2 = lrec(exp1 + *((MUL_DIV_MOD + exp1)[ToBinaryLrec]), ToLrecExpression);
6 exp3 = lrec(exp2 + *((ADD_SUB + exp2)[ToBinaryLrec]), ToLrecExpression);
7 exp4 = lrec(exp3 + *((((LT << LT) | (GT >> GT)) + exp3)[ToBinaryShiftLrec]), ToLrecExpression);
8 exp5 = lrec(exp4 + *(((LT | LE | GT | GE) + exp4)[ToBinaryLrec] | (AS + type)[ToCastingLrec] | (IS + type)[ToIsTypeLrec]), ToLrecExpression);
9 exp6 = lrec(exp5 + *(((EE | NE) + exp5)[ToBinaryLrec]), ToLrecExpression);
10 exp7 = lrec(exp6 + *((BITAND + exp6)[ToBinaryLrec]), ToLrecExpression);
11 exp8 = lrec(exp7 + *((XOR + exp7)[ToBinaryLrec]), ToLrecExpression);
12 exp9 = lrec(exp8 + *((BITOR + exp8)[ToBinaryLrec]), ToLrecExpression);
13 exp10 = lrec(exp9 + *((AND + exp9)[ToBinaryLrec]), ToLrecExpression);
14 exp11 = lrec(exp10 + *((OR + exp10)[ToBinaryLrec]), ToLrecExpression);
15 exp12 = lrec(exp11 + *((QQ + exp11)[ToNullChoiceLrec]), ToLrecExpression);
16 exp13 = lrec(exp12 + *((QT + (exp12 + (COLON(NeedColon) >> exp12)))[ToChoiceLrec]), ToLrecExpression);
17 expression = (exp13 + OPEQ + expression)[ToBinaryEq]
18 | (exp13 + EQ + expression)[ToAssignment]
19 | exp13
20 ;
21
22
posted @
2011-06-04 21:45 陳梓瀚(vczh) 閱讀(3642) |
評論 (10) |
編輯 收藏
摘要: 經歷了大約一個多星期的挑選,Vczh Library++3.0托管語言的語法樹大約就定下來了。跟本地語言有一個缺省的語法叫NativeX一樣,這次的語法就叫ManagedX了。當然ManagedX只是設計來直接反映托管語言語法樹的一門語言,如果愿意的話,這個語法樹還能被編譯成其他長得像(嗯,只能是像,因為必須是托管的,有類沒指針等)Basic啦Pascal那樣...
閱讀全文
posted @
2011-05-28 00:33 陳梓瀚(vczh) 閱讀(3266) |
評論 (17) |
編輯 收藏
我至今依稀還記得畢業前做
Vczh Library++3.0的偉大目標,就是實現把動態語言通過“動態語言”->“托管語言”->“本地語言”->“低級中間指令”->“X86代碼”最終編譯成機器碼,同時開放出所有中間過程。這樣的話添加一個就變成一個寫parser的簡單工作,添加一個類庫會惠及所有語言,添加一個運行是目標(譬如說可以輸出ARM等)可以讓在這上面的所有語言都能運行在該目標是。現在第一個階段完成了,就是把本地語言和低級中間指令給做了。
其實現在叫本地語言不太合適,只是那個東西就是C+泛型+concept mapping的組合體,可以輕易被翻譯成X86,所以才這么叫的。暫時還是寫了個虛擬機直接執行低級中間指令。在整個開發過程中,我還給這種語言寫了一個基本的函數庫:字符串、數學函數、內存管理、垃圾收集(只是函數庫,而不是語法,目前只有簡單的暫時的實現)、線程、同步原語和線程池。有了這些設施之后就可以開始做托管語言了。
托管語言比較麻煩的地方在于類庫是必需的。譬如說字符串、數組和函數對象這些東西其實是無法靠語言本身做出來的,所以只能成為預定義的類庫。那這些類庫用什么寫呢?當然是我們的本地語言(之前還寫了一個叫NativeX的parser)啦。現在的設想就有,先把預定義的類庫的聲明用托管語言本身寫出來,然后編譯器會提供一個功能將托管語言編譯成本地語言(目標箭頭之一),然后把所有標記成“外部函數”的函數跳過。每一個函數在生成本地語言的時候都會給出一個經過計算的名字。然后只需要再用NativeX寫出這些同名的函數實現就好了。剩下的一些能夠用托管語言自己實現的函數,就可以整個被編譯成本地語言。編譯出來的本地語言會依賴與之前寫出來的一個垃圾收集函數庫。這種函數庫在本地語言只有一個聲明,腳本引擎在運行的時候可以給這些名字bind上一個實現。所以實際上垃圾收集函數庫的實現是可以替換的(只是必須在初始化的時候指定)。將來萬一我重寫的實現不夠好,人們還能自己搞一套出來換掉,達到他們不可告人的目的。
至于托管語言本身有什么功能,肯定是抄自這個世界上最先進的
弱類型以面向對象作為主要范式的托管語言——C#啦,啊哈哈哈哈。Java的
語言本身根本沒有被抄的價值。至于之后的動態語言,肯定是被編譯到托管語言的。只是這個過程不會跟DLR那么簡單直接把類型和表達式拿去映射。這里面可以做很多有趣的事情的,譬如盡量推導出動態語言里面每一個變量的類型約束(我們很多時候其實都知道動態語言里面的某個變量是有限若干個類型的集合的),然后為他們產生出更加有效的代碼。這里可能會將一個函數編譯成目的相同但是類型不同的幾份(注意這里不是在做泛型展開)。
第二個階段就開始了。
posted @
2011-05-15 01:59 陳梓瀚(vczh) 閱讀(3634) |
評論 (21) |
編輯 收藏
主要目的是那個覺得不寫代碼就要死的室友想干點什么事情,覺得TFS太大了,所以做了個SVN。因此我們裝了一個SVN的插件“Ankh SVN2”到Visual Studio 2010里面。然后嘗試添加了個solution。Team Foundation Client有Source Control Explorer,因此這個破svn也得有個東西吧,然后我就在View目錄下看到了Repository Explorer。一打開,有目錄,欣喜若狂。然后我就在那個solution的目錄下右鍵點delete,想看看效果。
臥槽,沒有進Pending Changes!
臥槽,History不能Revert!!
臥槽,client端文件夾還在,對他任何操作都失敗!!!
臥槽,渣都不剩了啊!!!!
幸好那只是一個臨時的solution。要是在Repository Explorer里面手一抖在trunk文件夾上面Delete了,后果不堪設想啊。然后我就獲得了一個教訓。想看client端的文件夾的source control狀態,去Working Copy Explorer,那里面的Delete是進Pending Changes的。Reposiory Explorer刪除個文件夾,直接就在服務器端刪掉了,神馬都沒有了。這一輩子都不要打開Repository Explorer。然后我想起了以前看過的一篇文章《Unix Haters》里面說到unix的哲學就是,不警告,不報告,不禱告。像Delete這種東西,要是真他媽不進Pending Changes,至少告訴我他不進Pending Changes……
瞬間想起來,各位讀者們,這篇文章僅跟客戶端插件有關,這里不涉及任何svnadmin命令行內容。謝謝合作。
posted @
2011-05-03 06:56 陳梓瀚(vczh) 閱讀(5466) |
評論 (14) |
編輯 收藏
從某種意義上來說,做圖形也好,做GUI也好,做編譯器也好,大概都是一種情結。其實只要稍微想一想就知道,能把它們三者有機統一起來的,就只有游戲。我很久以前的確是為了想開發游戲才對編程產生興趣的,而學習游戲開發占據了我前六年的時間。雖然現在不做了,不過偶爾總是會覺得手癢。但是做游戲沒美工做不好怎么辦呢?就只好寫游戲代碼了。但是沒有資源寫出來的游戲又不好玩,于是就只好寫庫。那寫什么庫呢,自然就只有渲染器、界面引擎和腳本引擎了。我的博客的大部分文章也是圍繞著這三件事情建立起來,而且在中間不斷切換的。
撒,所以今天就輪到GUI了。我一直很想做出一個自繪的GUI出來,無奈一直設計不出一個好的架構。后來嘗試用原生API,但是卻又很不喜歡MFC的設計,就嘗試自己照著.NET Framework和Delphi那套VCL的樣子
封裝了一個控件庫出來。無奈原生API細節無敵多,后來沒做把所有的功能都全部做完。因此后來一段時間凡是需要界面我都直接用C#做。然后CEGUI出了,WPF和Silverlight也出了,我發現如今要做一個漂亮的GUI非自繪已經做不到了,所以我又做了一次嘗試。
去年在美帝的時候曾經試圖再設計一次,得到了一些結果。后來我發現其實根本沒辦法為GDI、DirectX、OpenGL和其它繪圖設備抽象一個公用的接口,否則就會遭遇大量性能問題。因為在很多細節上,譬如說渲染文字,為了達到較高的性能,OpenGL和DirectX需要使用幾乎相反的策略來做。因此這次我又換了一個方法,而且在
Vczh Library++ 3.0的Candidate目錄下已經checkin了一個試驗品。
我把一個自繪的GUI分成了下面若干個層次。
1、NativeWindow。NativeWindow表示的是一個頂層窗口的實現。譬如說我們想用Windows的窗口作為自繪窗口的頂層窗口(游戲里面的很多頂層窗口是繪制在游戲窗口里面的,所以頂層窗口并不一定是Windows的窗口)。
2、控件庫。控件庫包含了這個自繪GUI庫的所有預定義控件。控件本身包含對用戶輸入的相應邏輯,但是每一個控件的繪制以及鼠標點中測試不在此范圍內。
3、控件皮膚接口。每一個最終控件都會擁有一個控件皮膚接口。每當控件的狀態發生了變化,控件會調用皮膚接口更新控件的當前狀態。每當控件需要知道某一個點是否位于一個控件里面的時候,他也會去調用該控件的皮膚獲得結果。因此控件皮膚接口包含了一切關于繪制(因此理所當然也就包含了點中測試)的邏輯。
為了達到最高的性能,一套皮膚的實現只能綁定在某種繪圖設備上,也就是說缺省狀態下一套為GDI設備設計出來的皮膚是不能直接使用在DirectX設備上面的。當然我這個框架的設計也是足夠開放的,如果你非得用同一套代碼來實現不同繪圖設備上的皮膚,那么你是可以自己動手豐衣足食,做到給GDI和DirectX設計一個公共接口并插入我的GUI框架的(只不過這種做法一般情況下都會慘死)。
那么如何添加繪圖設備呢?目前NativeWindow有一個基于Windows窗口的實現,并且NativeWindow的接口要求該實現在創建、銷毀、接收到很多窗口事件的時候都調用某一個回調對象。我們可以通過注冊一個全局回調對象或者具體窗口的回調對象來獲得NativeWindow狀態的變更。基于Windows窗口的NativeWindow實現還提供了一個額外函數,可以讓你獲得一個NativeWindow的HWND(但這個函數并不被控件庫依賴)。現在我還實現了一個基于HWND+HDC的繪圖設備,主要方法就是先注冊全局回調對象,每當知道一個NativeWindow被創建了,我就會注冊一個NativeWindow的回調對象,用來維護一個窗口里面的一塊32位DIBSections位圖緩沖區。窗口的大小如果變化了,我也會在適當的時候重新創建一塊合適的緩沖區。不過為了避免每一次大小變化都會創建新的緩沖區,我創建的緩沖區的大小總會比窗口大一點。然后這個GDI繪圖設備就暴露了一個函數,可以獲得一個NativeWindow的HDC和WinGDIElementEnvironment。
WinGDIElementEnvironment是基于HWND+HDC的這一套實現上專有的、為了GDI皮膚設計出來的一個公共的資源庫(譬如用來保存各種面向業務邏輯的pen啊brush什么的,比如說disable的時候什么顏色,選中的時候什么顏色等等)。如果你想設計一個基于HWND+DirectX的皮膚,那么類似WinGDIElementEnvironment的這套東西要重新做一次——因為為了達到相同的性能。具體細節相差太大。當然HWND+HDC上面可以有多套皮膚,WinGDIElementEnvironment是公用的。WinGDIElementEnvironment要求繪制是通過一個具體的WinGDIElement對象達到的,而一套皮膚可以有自己的一套WinGDIElement的實現。WinGDIElement被設計成面向業務的、一套皮膚的基本元素組成部分,譬如說按鈕邊框啦、焦點長方形啦、文字啦,而不是帶有pen和brush的長方形啊,文字啊,各種亂七八糟的最低等級的繪圖元素。舉一個例子,按鈕邊框跟菜單邊框很像,都可以用Rectangle來組成。但是Element里面就直接是按鈕邊框和菜單邊框,而不是一個可以讓你自由修改顏色的Rectangle。因為不同的控件要共享配色方案,而配色方案是由業務邏輯+空間狀態的集合實現的,因此WinGDIElement還是一個比較高層次的概念。當一個WinGDIElement被渲染的時候,他會給你一個HDC,然后你根據被設置的狀態來調用GDI函數繪制到HDC指向的32位DIBSections位圖緩沖區上面。
那么,當我們使用HWND+HDC的實現,創建了一個布滿了控件的窗口,那實際上是發生了什么事情呢?首先控件自己會組成一棵樹。其次,控件的皮膚也會組成一棵樹。現在就有控件樹跟皮膚樹兩顆樹了。控件樹負責所有用戶輸入變更狀態的邏輯部分,而皮膚樹負責繪圖和點中測試。而一個HWND+HDC實現的皮膚樹,會在皮膚組合成樹的時候,在底下又組合出了一顆WinGDIElement樹。因此大局上就是:
控件樹(負責相應輸入變更狀態)--> 皮膚樹(負責儲存控件狀態的可視部分并決定什么時候需要刷新)-->WinGDIElement樹(負責繪圖整個窗口)
這個時候,如果我們僅僅需要簡單的重新繪制窗口的話,那么控件樹跟皮膚樹都不需要被訪問到,底層僅需要讓WinGDIElement樹重新繪制一遍即可。而WinGDIElement的粒度實際上也不小,因此不會每一個圖元都有一個WinGDIElement從而使得創建出了一大堆對象的。
最后一個設計就是在什么時候才重繪窗口的問題。假設說我們現在收到了一個WM_KEYDOWN消息,最終傳播到了控件樹里面去,然后修改了10個控件上面的文字。每當你修改文字的時候實際上都需要重繪,那如何將無數次不可控的重繪合并成一次呢?SendMessage(WM_PAINT)是立刻執行的,所以Windows自帶的合并WM_PAINT的方法在這個時候是無效的。我所采取的解決方法就是:反正控件樹的所有消息來源都是從NativeWindow里面來的,那實際上控件樹發出一個重繪請求的時候,我就會把NativeWindow的HWND實現里面的一個bool變量設成true,然后當NativeWindow每一個傳播到控件樹的消息結束傳播之后,才讀一次那個變量,如果是true,那么就調用WinGDIElement進行重繪并把變量設計成false。壞處是每一個傳播到控件樹的消息在處理完之后都必須檢查是否需要重繪,好處是這個東西被封裝在了NativeWindow的HWND實現里面里面,無論是控件樹、皮膚樹還是WinGDIElement樹也好,都在也不需要關心繪圖時機的事情了。
因為GUI被分割成了很多層,而且每一層的都關心業務邏輯的不同部分,所以他們都是可以被替換的。譬如說我們可以做成:
HWND+HDC實現:最普通的方法
HWND+DirectX:WPF和Silverlight地方法
單一HWND+多個虛擬窗口+DirectX:可以在游戲里面用
無論下面的繪圖設備和窗口實現如何發生變化,GUI控件的邏輯部分都跟這些實現嚴格分離,因此不會受到影響。而且大部分情況下,我們是不需要擁有一個跨繪圖設備的皮膚庫的,譬如說游戲和應用程序,外表總不能做成一樣的。對于那些需要同時在DirectX和OpenGL上面運行的程序(譬如說3dsmax),它已經有DirectX和OpenGL的公共接口了,因此這些軟件可以利用它們的公共接口來實現GUI的繪圖設備部分,從而在上面構造起來的皮膚自然是可以跨DirectX和OpenGL的。
這比起一年前作的GUI實現又進了一大步。上一次的GUI嘗試為不同的繪圖設備抽象一套公共接口,后來慘死。不知道這次實際上做出來的效果如何,拭目以待吧。
posted @
2011-04-29 19:50 陳梓瀚(vczh) 閱讀(5669) |
評論 (13) |
編輯 收藏
為了避免留言再次被刪掉,我還是直接在這里說幾句話好了。
在這里展示一下飯同學所珍愛的原創代碼“
http://www.shnenglu.com/johndragon/archive/2011/04/27/145123.html”。
匹配一個通配符的方法很多。譬如說我之前還寫過處理正則表達式的“
http://www.shnenglu.com/vczh/archive/2008/05/22/50763.html”,或者說飯同學的那個帖子,或者說《beautiful code》里面那個遞歸的做法。飯同學在cppblog上還算是出鏡率比較高的,因此他以前在博客上干過些什么事情我都是看了的。我猜他大概就不知道那個《beautiful code》(結果他自己承認了),因此靠著記憶貼了出來。我們都知道沒有編譯過的代碼出了點bug是正常的。后面還說了一句啥“寥寥幾行瞬間搞定”,其實也就是調侃一下。《beautiful code》這本書很出名,我不會認為會有什么人會誤以為那個遞歸的算法是我自己原創的,當然也就猜不出飯同學后面竟然會說我是為了證明自己聰明。
不過事情的發展比較出乎我意料。因為留言都被刪掉了,所以我拿不出證據,大家要質疑也隨便你們。
飯同學自己說努力研讀了“我的”代碼,然后指出這個問題有bug。好,這都是正常的。那他雖然文章里面寫了bug出現在*的處理里面,但是實際上這是后來加上去的,在留言里面他從來沒說bug在哪里,取而代之的是什么我為了證明自己聰明得逞啦,對人態度不好啦,對待程序的態度不好啦,各種亂七八糟的東西。我就想說一句“臥槽”。
在這里對z某同學再次感激。雖然言辭比較激動,但好歹不會隨便覺得人家在轉發別人的代碼是為了證明自己聰明(怎么可能呢)。
后面還有,我簡單回應了一下這代碼是我貼過來的,然后說了幾句飯同學不應該反應大,不要隨便猜測我是為了如何如何。然后飯同學回復了一句大概說的是我的留言沒有意思的事情。沒意思你就忽略嘛,你覺得整個事情就向著沒意思的方向發展你可以關閉回復嘛。你還回復我豈不是更沒意思。我最后一句留言說的是“還是說代碼吧,說我更沒意思”,然后所有留言就壽終正寢了。
所以說做程序員還是不能太激動。有人貼代碼你看代碼就好了,何必要通過否定一個人的行為來否定他所寫的代碼(更何況這是別人寫的)呢? 還有,要是動不動就覺得別人貼代碼是在挑戰你的話,那只會浪費時間在處理這些破事情而已。還是寫自己的代碼吧,這么做劃不來。
---------------------------------這里refer一下后來多出來的那個文章的部分--------------------------------------
話說我從來沒有“堅持自己是在做學術研究”,那其實是飯同學在被刪掉的那部分留言中堅持自己做學術研究。而且也沒有“不少人匿名來支持”,我看到的就是z某同學一個人而已(難道后來人數暴增?)。態度問題的話那隨便你怎么看,我又不吝嗇傳播別人的知識,你愛看不看。
關于遞歸的方法:
VCZH提供了一個遞歸的解法,并且“寥寥數行,瞬間搞定”。
不過,遞歸會帶來堆棧的問題。
而且他的方法里存在BUG,我就不貼上來了。
據他稱那種方法來自一本 beautiful code的書。此書我沒看過,所以不清楚。
從他的方法本身看,他只能提供是否匹配的一個結果,并且匹配模版和待匹配的字符串必須是0結尾,并且不返回結束匹配時的匹配進度。
并且在處理*的時候,有些許小BUG。
雖然他一直在堅持自己是在做學術研究,也有不少人匿名來支持他,不過我覺得他還是有些態度問題。
總是喜歡在別人的貼上表現自己。做的太過了就是顯擺了。
從他回帖說的那些話,比如“寥寥數行,瞬間搞定”這些,以及并不完善的代碼看來,他根本就沒有看過我的代碼,只是憑字面意思就開始貼代碼。
我實在不清楚他說這些話和貼代碼的原因是什么。這些我就不再討論了,我也刪除了他的回復。
不過我想說,如果你一直以這種態度來回別人的帖子,那你會成為一個令人討厭的人。
posted @
2011-04-27 23:04 陳梓瀚(vczh) 閱讀(3457) |
評論 (20) |
編輯 收藏 每次完成一個任務的時候,都要看看有沒有什么潛在的可以把功能是現成庫的地方。這十分有利于提高自己的水平。但至于你寫出來的庫會不會有人用,那是另一回事情了。
這次為了完成一個多編程語言+多自然語言的文檔編寫工具,不得不做一個可以一次生成一大批文本文件的模板結構出來。有了模板必然有元數據,元數據必然是類似字符串的東西,所以順手就支持了xml和json。為了應付巨大的xml和json,必然要做出xml和json的流式讀寫。大家應該聽說過SAX吧,大概就是那樣的。
有了xml和json之后,就可以在上面實現query了。把xml和json統一起來是一個比較麻煩的問題,因為本身從結構上來看他們是不相容的。而且為了便于給vlscript.dll添加compiler service的支持,勢必要在dll上面做出字符串到語法樹或者語法樹到字符串這樣子的操作。本地dll接口顯然不可能做出一個順眼的異構樹結構,因此勢必要把語法樹表示成xml或者json。因此就有了下面的結構:
1、一顆簡潔但是功能強大的字符串,在上面可以存放xml、json和強類型數據。
2、可以把xml和樹相互轉換。
3、可以把json和樹相互轉換。
4、當樹存放的是強類型數據(基本類型都會用字符串存放)的時候,樹可以映射到一個帶有約束的xml或者json結構上去。
在這里可以展示一下什么是強類型數據。我們知道json表達的結構是弱類型的。當你拿到一個object的時候你不知道它的類型,你只知道他有多少個成員變量。強類型結構要求object有一個類型標記,數組也有一個類型標記(因為我們不能從數組的元素類型推斷出數組本身的類型——因為類型可以擁有繼承關系),基本類型還要可擴展(json只支持數字、字符串、布爾值和null,顯然是不夠的)。下面貼一個強類型數據結構的xml和json的表現形式:
1 <Developer>
2 <Languages>
3 <array:String>
4 <primitive:String value = "C++"/>
5 <primitive:String value = "C#"/>
6 <primitive:String value = "F#"/>
7 <primitive:String value = "Haskell"/>
8 </array:String>
9 </Languages>
10 <Name>
11 <primitive:String value = "vczh"/>
12 </Name>
13 <Project>
14 <Project>
15 <Host>
16 <primitive:String value = "Codeplex"/>
17 </Host>
18 <Language>
19 <primitive:String value = "C++"/>
20 </Language>
21 </Project>
22 </Project>
23 </Developer>
1 {
2 "$object" : "Developer",
3 "Languages" : {
4 "$array" : "String",
5 "value" : [{
6 "$primitive" : "String",
7 "value" : "C++"
8 }, {
9 "$primitive" : "String",
10 "value" : "C#"
11 }, {
12 "$primitive" : "String",
13 "value" : "F#"
14 }, {
15 "$primitive" : "String",
16 "value" : "Haskell"
17 }]
18 },
19 "Name" : {
20 "$primitive" : "String",
21 "value" : "vczh"
22 },
23 "Project" : {
24 "$object" : "Project",
25 "Host" : {
26 "$primitive" : "String",
27 "value" : "Codeplex"
28 },
29 "Language" : {
30 "$primitive" : "String",
31 "value" : "C++"
32 }
33 }
34 }
上面的xml和json都是對一個相同的強類型數據結構的表示。我們可以看到$array、$object和$primitive是用來區分他們的實際類型的。
下面是流式xml和json的讀寫的接口。可以很容易的看出用這種方法來讀寫xml和json必須將代碼做成一個超級復雜的狀態機才可以。這里太長貼不下,如果大家有興趣的話可以去
Vczh Library++3.0下載最新代碼并打開
Library\Entity\TreeXml.cpp
Library\Entity\TreeJson.cpp
Library\Entity\TreeQuery.cpp
1 class XmlReader
2 {
3 public:
4 enum ComponentType
5 {
6 ElementHeadOpening, // name
7 ElementHeadClosing, //
8 ElementClosing, //
9 Attribute, // name, value
10 Text, // value
11 CData, // value
12 Comment, // value
13
14 BeginOfFile,
15 EndOfFile,
16 WrongFormat,
17 };
18 public:
19 XmlReader(stream::TextReader& _reader);
20 ~XmlReader();
21
22 ComponentType CurrentComponentType()const { return componentType; }
23 const WString& CurrentName()const { return name; }
24 const WString& CurrentValue()const { return value; }
25 bool Next();
26 bool IsAvailable()const { return componentType!=EndOfFile && componentType!=WrongFormat; }
27 };
28
29 class XmlWriter
30 {
31 public:
32 XmlWriter(stream::TextWriter& _writer, bool _autoNewLine=true, const WString& _space=L" ");
33 ~XmlWriter();
34
35 bool OpenElement(const WString& name);
36 bool CloseElement();
37 bool WriteElement(const WString& name, const WString& value);
38 bool WriteAttribute(const WString& name, const WString& value);
39 bool WriteText(const WString& value);
40 bool WriteCData(const WString& value);
41 bool WriteComment(const WString& value);
42 };
43
44 class JsonReader
45 {
46 public:
47 enum ComponentType
48 {
49 ObjectOpening,
50 ObjectClosing,
51 Field,
52 ArrayOpening,
53 ArrayClosing,
54 Bool,
55 Int,
56 Double,
57 String,
58 Null,
59
60 BeginOfFile,
61 EndOfFile,
62 WrongFormat,
63 };
64 public:
65 JsonReader(stream::TextReader& _reader);
66 ~JsonReader();
67
68 ComponentType CurrentComponentType()const { return componentType; }
69 const WString& CurrentValue()const { return value; }
70 bool Next();
71 bool IsAvailable()const { return componentType!=EndOfFile && componentType!=WrongFormat; }
72 };
73
74 class JsonWriter
75 {
76 public:
77 JsonWriter(stream::TextWriter& _writer, bool _autoNewLine=true, const WString& _space=L" ");
78 ~JsonWriter();
79
80 bool OpenObject();
81 bool CloseObject();
82 bool AddField(const WString& name);
83 bool OpenArray();
84 bool CloseArray();
85 bool WriteBool(bool value);
86 bool WriteInt(vint value);
87 bool WriteDouble(double value);
88 bool WriteString(const WString& value);
89 bool WriteNull();
90 };
有xml自然要有xpath,只不過xpath用來處理json和強類型數據結構都有點力不從心,所以我打算修改xpath,做成適合查詢我這種跟它們稍微有點不同的樹的查詢語句,然后加入到Vczh Library++3.0里面去。有了這個之后就可以做很多事情了,譬如說在模板生成器里面使用query來查詢復雜的配置,譬如說在腳本語言里面支持xml和json,還有很多其他的等等。query寫完之后就可以開始寫一個可以一次生成一大批文本文件的模板生成器了。我會將模板生成本身寫成一個可以擴展功能的庫,最后再寫一個DocWrite.exe利用這個庫實現一個文檔生成器。
posted @
2011-04-18 05:34 陳梓瀚(vczh) 閱讀(3319) |
評論 (3) |
編輯 收藏
在微軟亞洲研究院上班已經長達4天了。我找了我本科的同班同學一起住,他也在微軟,如果他不加班的話還可以一起吃飯上下班。頭一個星期四處見同學,也結識了幾個新朋友,然后在家里寫寫代碼。
Vczh Library++3.0最近的進展比較緩慢。我要用一種類似模板+生成器的方法來讓我可以很方便地給多個編程語言撰寫中英雙語的文檔,然后分開編譯成多個文檔,當然每個文檔只有一門程序語言以及一門自然語言。因此最近正在著手給VL++3.0添加xml、json以及模板文件的支持。這個模板的編譯過程跟xml+xslt比較類似,唯一的區別是我的編譯過程可以控制多個步驟產生一大堆文件,譬如說文檔本身,譬如說各個腳本實例及其makefile等等。
室友也很喜歡沒事寫代碼,所以我在維護VL++3.0的同時還會跟他一起做一些有意思的小工程來玩一玩。最近在搞一個跟鋼琴譜有關的軟件及其一些小研究。恰好我跟他小時候都學過鋼琴(唯一的區別是他沒有斷,我斷了……),總之都是閑著沒事充實生活用的。
工作之后沒有在學校的那么多時間,無法維持兩天至少能做一個東西來寫博客的速度了,降低到了一個月兩篇。不容易啊……
posted @
2011-04-11 05:32 陳梓瀚(vczh) 閱讀(6151) |
評論 (16) |
編輯 收藏
項目主頁:
http://vlpp.codeplex.com 下載頁面:
http://vlpp.codeplex.com/releases/view/62850 該Release對應的源代碼:
http://vlpp.codeplex.com/SourceControl/changeset/view/70602 第一個release沒有文檔,因此接下去我得做一個雙語的文檔生成工具了,然后會在下一個release里面添加完整的NativeX語言和腳本引擎API的文檔。因此現在要學習如何使用NativeX和腳本引擎的API的話,可以下載源代碼然后到下面的目錄尋找資料:
1、UnitTest\Binary\TestFiles\Code:我的單元測試工程使用的NativeX腳本代碼
2、UnitTest\Binary\ScriptCoreLibrary:NativeX預定義函數庫的源代碼
3、Tools\Release\VleSource\VlScriptDotNet:vlscript.dll的.NET封裝
4、Tools\Release\VleSource\VlTurtle:使用vlscriptdotnet.dll開發的“強大的烏龜”
因此下載release之后,可以打開Turtle\VlTurtle.exe,然后玩之。一個簡單的方法是,打開內置的sample然后點Run,如圖:
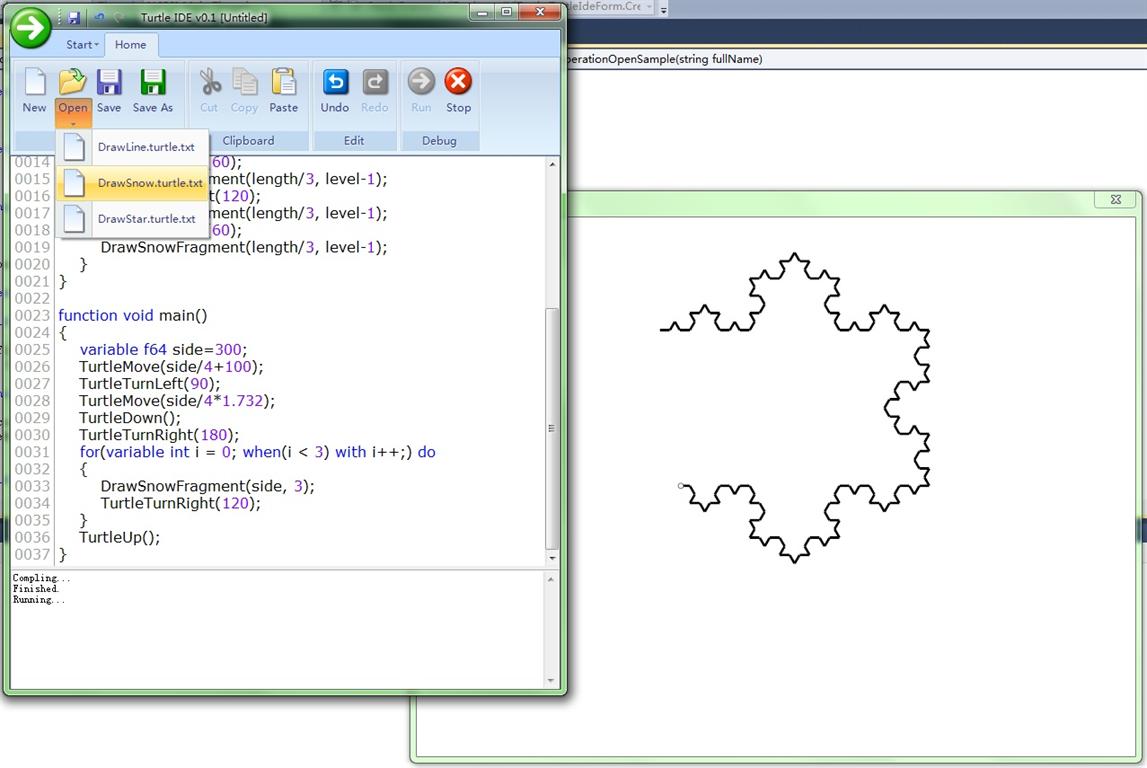
posted @
2011-03-19 21:07 陳梓瀚(vczh) 閱讀(11525) |
評論 (16) |
編輯 收藏
這是一個小Demo,用來介紹如何使用C#來調用我C++給出的NativeX編譯器和虛擬機的。具體的代碼可以在
Vczh Library++3.0里面找到。
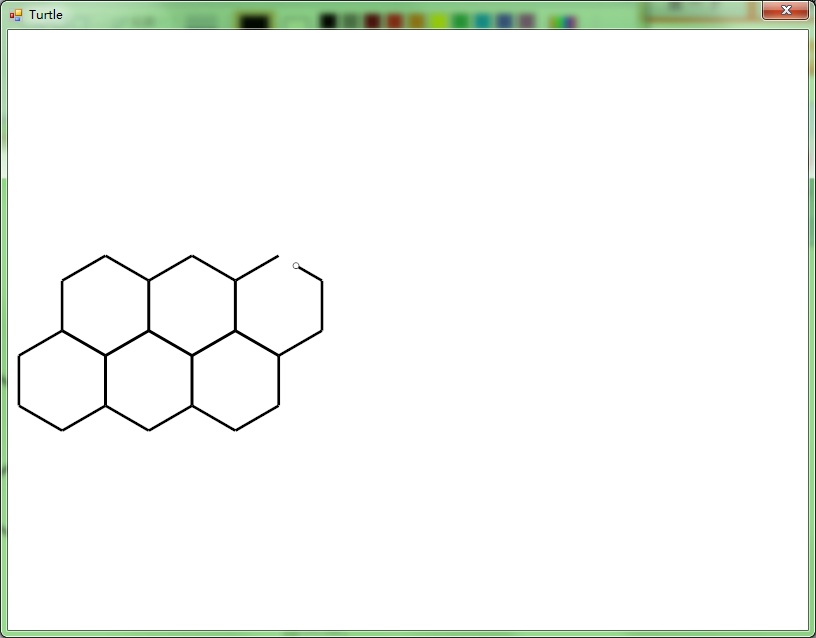
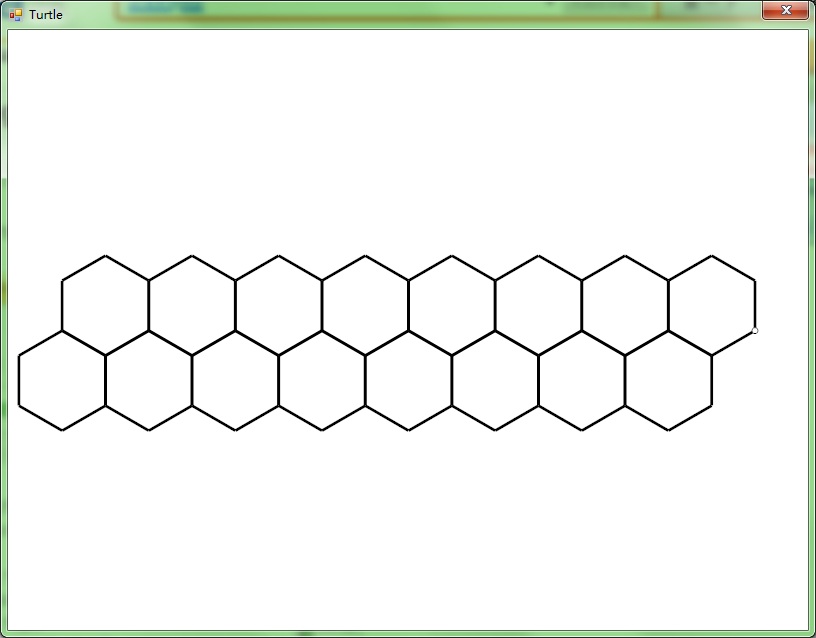
VlTurtle.exe的工作原理十分簡單。首先界面由Ribbon和Intellisense構成(超難寫,難免會有些問題……),其次按Run的時候會將代碼保存到Script\NativeX\NativeX.txt里面,使用Vle.exe編譯Script\NativeX\Make.txt,生成assembly文件。如果編譯失敗,就會出現Error.txt,然后這個編輯器將這個文件讀回去顯示在界面上。編譯成功之后,使用參數“Execute”再啟動自己一次,新進程會讀生成的assembly文件并使用vlscript.dll的虛擬機函數初始化,尋找main函數并執行。
第一個alpha版本的Release我并不打算把編譯器也做進vlscript.dll(其實代碼都在,就是沒extern),而打算讓Vle.exe充當編譯器的作用。目前這個破Demo還沒做完,New/Open/Save/Save As/Stop點了沒反應,而且Run是阻塞的——也就是執行進程沒退出,編輯器就會假死。先偷懶了,過幾天再改好他,順便給那只破烏龜加點功能美化一下……
下面先貼圖。
posted @
2011-03-11 06:20 陳梓瀚(vczh) 閱讀(3583) |
評論 (3) |
編輯 收藏