

posted @
2023-10-24 15:25 春秋十二月 閱讀(206) |
評論 (0) |
編輯 收藏1. 區間圖:用于局部寄存器分配,基本塊內的每個活躍范圍看作一個區間(最早定義位置+最新使用位置),所有活躍范圍構成區間圖。區間圖是一種不精確的沖突圖(因為高估了活躍范圍的范圍而導致偽沖突,比如認為一個復制操作連接的或兩個源相同目標不同的復制操作產生重疊的兩個活躍范圍沖突,但實際沒有沖突),優勢在于著色是P(復雜度O(|V|)或O(|E|))而非NP問題。llvm早期的線性掃描分配器是基于區間圖在全局的擴展,比較適用于JIT編譯(減少編譯時間)
2. 一般圖:用于全局寄存器分配,是一種精確的沖突圖(由一組定義與一組使用構成的網絡)。優勢在于努力最小化溢出活躍范圍而生成高效執行的代碼,但會犧牲編譯時間。llvm的greedy寄存器分配是基于一般圖的代表。編譯器使用的沖突圖可能會將機器約束條件比如多寄存器值/調用約定編碼進去而存在重復邊,導致不滿足圖論中的簡單圖定義,故這里采用一般圖
3. 弦圖:定義詳見
https://oi-wiki.org/graph/chord。基于靜態單賦值形式名建立的沖突圖是弦圖。優勢在于可以做到最佳著色(復雜度O(|V|+|E|))而非啟發式(基于一般圖的全局寄存器分配使用啟發式),利于減少寄存器壓力。劣勢在于必須將指派寄存器后的仍然為靜態單賦值代碼轉換為機器碼,而這種轉換可能增加寄存器壓力,以及插入一些可能非必要的復制操作,若復制操作實現的數據流與ssa phi函數對應,則分配器無法合并這種復制,這將破壞弦圖的性質
4. 沖突圖拆分:查找其中的團分割即連通子圖,移除它劃分得到不相交的一些子圖,這樣一來,各子圖可獨立著色(有點類似活躍范圍拆分)而利于減少寄存器壓力,另外實現上還能節省下三角布爾矩陣(用于快速判斷兩結點是否沖突)的規模
#############################
寄存器分配與圖論的染色理論相關。其它的比如常量傳播與格代數及不動點相關,循環優化與多面體、矩陣相關。這三方面是我目前看到的編譯器所用數學理論
posted @
2023-10-04 13:08 春秋十二月 閱讀(3881) |
評論 (0) |
編輯 收藏posted @
2023-09-30 08:47 春秋十二月 閱讀(105) |
評論 (0) |
編輯 收藏
有單向、雙向、三向3種認證方式,前兩者必須檢查時間戳以防重放攻擊,單向因為只有一個消息傳遞,如果僅靠一次性隨機數是無法判斷消息是否重放。雙向有兩個消息傳遞,一來一回,僅靠一次性隨機數只能檢測到發響應那方的重放。最后者則不必,可僅通過一次性隨機數檢測自己是否遭遇重放攻擊,因為接收第二個消息的那方,通過判斷第二個消息中隨機數是否等于自己先前已發送第一個消息中的那個,若不等于則為重放,若等于則發第三個確認消息給對方,對方收到并判斷確認消息中的隨機數是否等于先前它已發送第二個消息中的隨機數,若等于則說明第它收到的第一個消息的確是另一方發送的即非重放,否則為重放。因此三向認證可不必同步雙方時鐘。但正因為不強制檢查時間戳而可能導致
中間人攻擊:假設通信雙方為A、B,中間人為C,攻擊步驟如下
1. C與B認證時,發送先前已截獲的A到B請求消息給B
2. 截獲并存儲B到A的響應消息x,但不轉發,開始與A認證
3. 收到A的請求消息后,解密x取出其中的隨機數Rb作為響應給A消息中的隨機數,用自己私鑰簽署整個消息后發給A
4. 收到并轉發A的確認消息給B
以上完成后,C就能冒充A與B通信了。一種簡單的改進方法是先用對方的公鑰加密消息中的隨機數,再用自己的私鑰簽署整個消息。關于網絡協議的安全性分析,主流方法是形式化分析,可以借助相關工具來驗證找出漏洞
posted @
2023-09-30 08:00 春秋十二月 閱讀(455) |
評論 (0) |
編輯 收藏
1.
對于RSA,給定大整數n分解的一對素因子p和q,p或q是否素數決定不了安全性,但決定算法的正確性,也就是說p或q不能為合數,而安全性取決于n的位數及p、q的距離,n越大則難于素因子分解(因為素數測試是一個P問題,而因子分解是一個NP問題,其耗時是關于n的指數),|p - q|要大是為抵抗一種
特殊因子分解攻擊,論證如下:由(p+q)
2/4 - n = (p+q)
2/4 - pq = (p-q)
2/4,若|p - q|小,則(p-q)
2/4也小,因此(p+q)
2/4稍大于n,(p+q)/2稍大于n
1/2即根號n。可得n的如下分解法:a) 先順序檢查大于n
1/2的每一整數x,直至找到一個x使得x
2 - n是某一整數y的平方;b) 再由x
2 - n = y
2 得 n = (x+y)(x-y)。另外,p - 1和q - 1都應有大素因子(所有因子皆是大素數),以抵抗可能的
重復加密攻擊(重復加密較少步后可恢復出明文)
2.
對于DH密鑰交換,通常選擇階為素數的有限循環(子)群,這時素數決定了安全性。因素數不能再因子分解,故避免了針對階為合數的質因子分解且利用中國剩余定理求離散對數的(已知最好)攻擊。具體講就是為了防
index-calculus方法求解離散對數,底層循環群G的素數模p要足夠大,長度1024位可實現80位安全等級,長度3072位可實現128位安全等級;另為了防
Pohlig-Hellman攻擊,G的階p-1必須不能因式分解為全部都是小整數的素數因子,且為了p-1的每個因子構成的子群防
baby-step giant-step或
Pollards's rho攻擊,要求對80位安全等級而言,p-1的最小素因子必須至少為160位,而對128位安全等級,其至少為256位
3.
對于Hash函數,安全性要求有三點:第一是單向性,由于壓縮函數理論上存在碰撞,因此單向性是指計算不可行,為什么要單向性?因為若不單向,則可從結果比如簽名逆出原文消息;第二是抗弱沖突性即
第1類生日攻擊,計算不可行;第三是抗強沖突性即
第2類生日攻擊,計算不可行。這三點要求,取決于壓縮函數是否能抗差分、線性等密碼分析
4. 周知
Shamir門限方案基于多項式的拉格朗日插值公式,普遍的設計采用GF(q)域上的多項式,秘密s為f(0),q是一個大于n的大素數(n是s被分成的部分數)。正常來講,參與者個數必須至少是設計時的k,才能恢復出正確的s。如果個數少于k比如k-1,則只能猜測s0=f(0)以構建第k個方程,那么恢復得到的多項式g(x)等同設計時的多項式f(x)的概率是1/q。因為g(x)的項系數可以看作關于s0的同余式即h(s0)=(a+b*s0)mod q的形式,因q為素數,故依模剩余系遍歷定理,當s0取GF(q)一值時,則h(s0)唯一對應另一值。所以h(s0)等于f(0)的概率為1/q。由此可見,當q取80位以上,敵手攻擊概率不大于1/2
80,這已經很低了。這種門限方案如同RSA加密,再次佐證了素數越大安全性越高
5.
PGP是密碼學經典應用,體現在首先支持保密與認證業務的正交,即獨立或組合,且組合時按認證、壓縮、加密的順序,這個順序是經考究有優勢的;其次會話密鑰是一次性的,由安全偽隨機數生成器生成,且按公鑰加密;最后使用自研的密鑰環與信任網解決公鑰管理問題。理論本質上,PGP提供的是一種保密認證業務的通用框架,因為具體的對稱加密算法、隨機數生成、公鑰算法,都可依需要靈活選配擴展。PGP有兩個問題跟組合與概率相關,一個是算密鑰環N個公鑰中,密鑰ID(64位)至少有兩個重復的概率?設所求概率為p,先算任意兩個不重復的概率q,令m=2
64,則q=m!/((m-N)!*m
N),則p=1-q,不難看出,N越小則q越大則p越小,因實際應用N<<m,故p非常小可忽略,即PGP取公鑰中最低64有效位作密鑰ID,是可行的。另一個是簽名摘要暴露了前16位明文,對哈希函數安全的影響有多大?這問題意思應該是敵手拿到消息后但沒發送方的私鑰作簽名,只能窮舉變換原消息并求哈希值,使之與消息摘要剩余位組相等。這本質是求
兩類生日攻擊碰撞概率大于0.5時所需的輸入量。在僅認證模式中,抗弱碰撞計算量降低為原來的1/2
16,抗強碰撞計算量至少降低為原來的1/2
8。另外,考慮到這16位明文可能的特殊性,有沒更快的代數攻擊,需進一步研究
posted @
2023-09-28 08:04 春秋十二月 閱讀(3037) |
評論 (0) |
編輯 收藏posted @
2023-09-26 16:47 春秋十二月 閱讀(2161) |
評論 (0) |
編輯 收藏
周知編譯原理龍書闡述的基本塊指令調度算法,它所使用的空的資源預約表RTD與每個指令的資源預約表RT,可以看作二維矩陣,行表示時鐘周期、列表示cpu資源,其定位的元素值1表示占用/預約,0表示空閑/非預約。前者是隨周期遞增而動態擴大的矩陣,后者是固定尺寸(維數)的矩陣(指令花費周期與每周期預約資源皆已知)。在調度時,按帶優先級比如關鍵路徑的拓撲排序基本塊內的指令,順序選取一條指令Inst,計算每前驅發射周期加延遲的結果tmp,取所有tmp的最大值tmax作為Inst的發射周期,再判斷處理器資源是否可用,即RTD和RT作
與運算,得到一個新矩陣RTN,若RTN為
全零矩陣則tmax為Inst的最終發射周期,否則遞增tmax再做矩陣與運算,直至得到全零矩陣。最后更新RTD,即RTD與RT作
或運算結果存于RTD。重復上述過程直到基本塊末尾。
綜上不難看出,如果一個基本塊很大比如有1000條指令,平均每指令花2個周期,則RTD需要2000個條目,若一條目即矩陣每行占用32字節(256種資源數),則總量約64k。當然這對于現代內存體量來說不算什么,但可以有更好的節省內存的做法:RTD尺寸其實可以相對固定,其上限為基本塊中耗費周期最多指令的周期的一個大于1常數因子倍(為兼顧指令并行性),這樣一來就要增加當指令完成時(當前指令發射周期大于前一條的終止周期時復位前一條指令的RTD)從發射周期處復位RTD即作一個矩陣反運算的操作,其它步驟對應的矩陣與、矩陣或運算的操作保留不變。另由于RTD固定了尺寸,因此發射周期遞增后要取模
【備注】以上是我針對簡單機器模型(每種資源數量僅一個,比如整數運算單元1個,內存訪問單元1個,浮點運算單元1個)用布爾矩陣作的優化。如果是復雜的超標量機器即每種資源數有多個,那么只需修改如下:布爾矩陣換成整數矩陣;新增一個機器資源可用總數整數矩陣RDA(單列資源數同值),布爾矩陣與運算換成加法并與RDA比較,若大于RDA則遞增tmax;布爾矩陣或運算換成加法;布爾矩陣反運算換成減法,RTD減RT存于RTD
posted @
2023-09-23 12:14 春秋十二月 閱讀(365) |
評論 (0) |
編輯 收藏曾因朋友問到監控,致使我探究了kretprobe的實現,想到編譯中的尾調用優化,作個小結
?1. kretprobe_trampoline_holder該跳轉函數無參是必須的或說最好的通用設計,因為替換返回地址是非正常程序流程,即被探測函數的調用者無感知,不存在為跳轉函數準備入參。若要設計傳參且只讀,則不會破壞被探測函數調用者的上下文,但跳轉函數內部流程怎么用參數是個問題,這需要一種約定
?2. 跳轉函數為調用trampoline_handler準備入參,即在棧上構造一個(不完整的)pt_regs,再把它地址即棧頂賦給rdi,rdi是x86_64上傳入第一參數使用的寄存器,同時預留一個棧單元存放原返回地址(為什么要預留?因為被探測函數返回時,其調用者存放返回地址的棧空間被釋放了,所以得在跳轉函數內造一個)。由于trampoline_handler內調到用戶自定義handler而傳入pt_regs,因此自定義handler內要注意最好別改動pt_regs,否則會破壞被探測函數調用者的上下文
posted @
2023-09-13 02:26 春秋十二月 閱讀(360) |
評論 (0) |
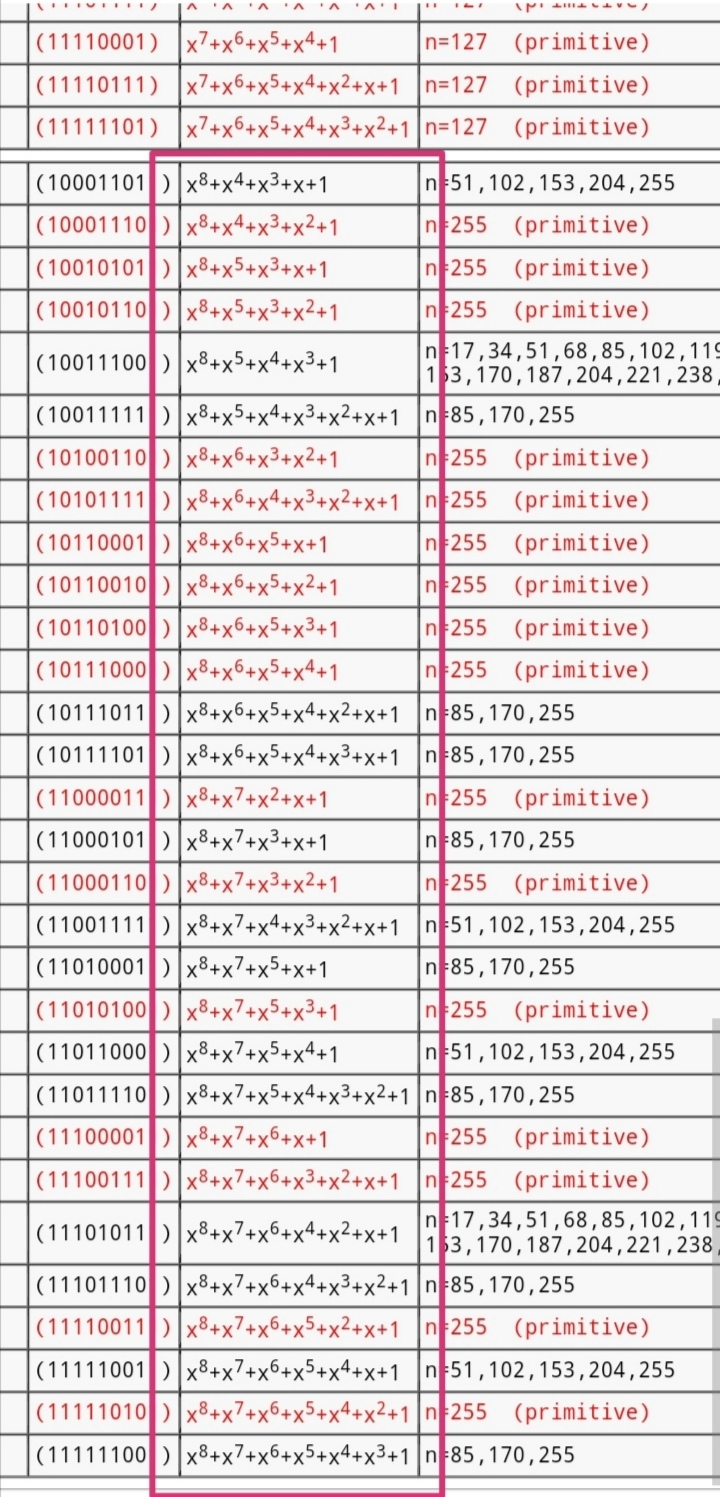
編輯 收藏有理數域的本原多項式與有限域的本原多項式定義不同,前者不要求不可約(由高斯引理知兩個本原多項式的乘積還是本原),后者則必須不可約(確保生成的有限域其每個元素有逆元)。aes基于有限域F{0,1}設計,故使用的模8次多項式不可約
P(x)=x^8+x^4+x^3+x+1,但不是本原多項式,因為它的階是51而非255。有限域次數為8的本原多項式有16個、不可約多項式有30個(由莫比烏斯反演推出),具體多項式影響s盒與列混合操作的實現。不可約加之0的逆元規定為0,保證正確加解密。若0的逆元規定為非0比如x,則導致x有兩個逆元,便違反了逆元唯一性,除非s盒不用有限域設計。逆元等于其自身的非0元素只有1,原因可類比模素數二次剩余的求解
posted @
2023-09-13 02:00 春秋十二月 閱讀(404) |
評論 (0) |
編輯 收藏1. 若DFA D是用子集構造法從NFA N構造出來的,則L(D)=L(N)
2. 一個語言L被某個DFA接受,當且僅當被某個NFA接受
3. 一個語言L被某個£-NFA接受,當且僅當被某個DFA接受
4. 若對于某個DFA A,L=L(A),則存在一個正則表達式R使得L=L(R)
5. 每一個用正則表達式定義的語言也可用有窮自動機定義
6. 若通過填表算法不能區分兩個狀態,則它們是等價的
7. DFA的狀態等價性是傳遞的
8. 若對于DFA每個狀態q及與q等價的所有狀態組成塊,則不同的狀態塊形成狀態集合的劃分。也就是說,每個狀態恰好屬于一個塊,同一塊中的所有成員都是等價的,從不同塊中選擇的狀態對都不是等價的
9. 根據等價狀態劃分算法最小化DFA D得到的DFA M是唯一的。也就是說,不存在其它等價于D的DFA N,其狀態數比M少
----------------------------------------------------------------------------------------
10. 對于正則表達式,空集是并運算的單位元、連接運算的零元,空串是連接運算的單位元
11. 若L和M都是正則語言,則L和M的并、交、差也是
12. 若L是字母表T上的正則語言,則~L=T*—L也是
13. 若L是正則語言,則L的反轉也是
14. 若L是字母表T上的正則語言,h是T上的一個同態,則h(L)也是正則的
15. 若h是字母表A到字母表T的同態,且L是T上的正則語言,則逆同態h^-1(L)也是正則的
posted @
2023-09-09 08:11 春秋十二月 閱讀(1146) |
評論 (0) |
編輯 收藏