首先描述一下三個相關函數strcpy/strncpy、memcpy和memmove的意義。
眾所周知的,strcpy/strncpy和memcpy都是用于從一塊內存復制一段連續的數據到另一塊內存�����,區別是終結標識不同�����。strcpy會比較每個字符是否為'\0'以判定是否繼續復制�����,而memcpy就不管內存數據內容,確定復制指定的長度(不討論源串有錯誤或者目的空間不夠等出錯的情況)。所以這兩者在作用上是可以共通的��,我想這兩個函數最大的區別只能說是語義上的區別。而用法上�����,strcpy只能針對字符串��,memcpy卻沒有這個限制,用memcpy(char*pDest,char*pSource,strlen(pSource))完全能替代strcpy的功能���。
而后面兩個mem系列函數��,主要區別在memcpy對于重疊內存的復制支持不太好�����。例如對char a[10]操作的話,memcpy(a, a + 3, 5)這樣的��,源數據是a+3到a+7,目標位置是a到a+5�����,操作區域有重復�����,則應該用memmove��。
好了��,說明了這三個函數的作用,就進入本文討論的正題:用memcpy替代strcpy/strncpy���!
首先,從功能上來說���,上文已經討論過了,用memcpy(char*pDest,char*pSource,strlen(pSource))完全能替代strcpy的功能�����。之所以倡導這種用法��,在于用memcpy函數不僅功能上比strcpy/strncpy更強大,關鍵在于前者效率要高很多�����!盡管沒有這兩個函數的源代碼���,但是單從分析上��,strcpy\strncpy需要在每一步操作時都要比較字符是否為'\0',而memcpy完全不需要,甚至有更快的指令來優化塊復制�����,所以效率肯定高很多���。事實上,測試結果也是這樣���,測試程序如下:
 #include <string.h>
#include <string.h>
#include <windows.h>
int main(void)


 {
{
 char * pch = "常常有人問:我想學習內核��,需要什么基礎嗎��?LinusTorvalds本人是這樣回答的:你必須使用過Linux�����。這個……還是有點太泛了吧���,我想下面幾個基礎可能還是需要的�����,盡管不一定必需:1,關于操作系統理論的最初級的知識。不需要通讀并理解《操作系統概念》《現代操作系統》等巨著,但總要知道分時(time-shared)和實時(real-time)的區別是什么��,進程是個什么東西�����,CPU和系統總線、內存的關系(很粗略即可),等等�����。2,關于C語言���。不需要已經很精通C語言�����,只要能熟練編寫C程序��,能看懂鏈表、散列表等數據結構的C實現���,用過gcc編譯器,就可以了���。當然,如果已經精通C語言顯然是大占便宜的���。3,關于CPU的知識。這塊兒可以在學習內核過程中補��,但這樣的話你就需要看講解很詳細的書��,比方后面將會提到的《情景分析》���。你是否熟悉Intel80386CPU���?嘗試著回答這幾個問題來判斷一下:1)說出80386的中斷門和陷阱門的區別���;2)說出保護模式與實模式的區別��;3)多處理器機器上��,普通的讀-改-寫回一塊內存這樣的動作��,為什么需要特殊的手段來保護�����。等等�����。講解基于其它CPU的Linux內核的書�����,目前好象只有一本《IA64Linux內核:設計與實現》──也還是Intel的,其它都是講解基于IA32的。以上算是知識方面吧���,如果還要再補充一條,我想就是:動手編譯過內核��。好了�����,我們接下來走���。好多人裝上Linux之后�����,第一件事找到內核源碼所在的路徑,打開一個C程序文件,開始嘩嘩嘩翻頁,看看大名鼎鼎的Linux內核代碼到底長啥模樣──然后關閉。這是可理解的��,但卻不是學習的方法��。剛開始��,必須從讀書入手。[color=red:8c0c3b6f46]至少要對內核有一個Overview之后,才有可能帶著問題去試圖閱讀源代碼本身���。[/color:8c0c3b6f46]下面就講一下我讀過的幾本書:1,《Linux內核設計與實現》��,英文名LinuxKernelDevelopment(所以有人叫它LKD),機械工業出版社���,¥35,美國RobertLove著,陳莉君譯者��。評說:此書是當今首屈一指的入門最佳圖書���。作者是為2.6內核加入了搶占的人��,對調度部分非常精通��,而調度是整個系統的核心�����,因此本書是很權威的�����。這本書講解淺顯易懂,全書沒有列舉一條匯編語句,但是給出了整個Linux操作系統2.6內核的概觀�����,使你能通過閱讀迅速獲得一個overview��。而且對內核中較為混亂的部分(如下半部)�����,它的講解是最透徹的。對沒怎么深入內核的人來說,這是強烈推薦的一本書�����。翻譯:翻譯水平�����、負責任程度都不錯,但是印刷存在一些錯誤���。買了此書的朋友可以參考我在Linux高級應用版的《Linux內核設計與實現中文版勘誤》:\
char * pch = "常常有人問:我想學習內核��,需要什么基礎嗎��?LinusTorvalds本人是這樣回答的:你必須使用過Linux�����。這個……還是有點太泛了吧���,我想下面幾個基礎可能還是需要的�����,盡管不一定必需:1,關于操作系統理論的最初級的知識。不需要通讀并理解《操作系統概念》《現代操作系統》等巨著,但總要知道分時(time-shared)和實時(real-time)的區別是什么��,進程是個什么東西�����,CPU和系統總線、內存的關系(很粗略即可),等等�����。2,關于C語言���。不需要已經很精通C語言�����,只要能熟練編寫C程序��,能看懂鏈表、散列表等數據結構的C實現���,用過gcc編譯器,就可以了���。當然,如果已經精通C語言顯然是大占便宜的���。3,關于CPU的知識。這塊兒可以在學習內核過程中補��,但這樣的話你就需要看講解很詳細的書��,比方后面將會提到的《情景分析》���。你是否熟悉Intel80386CPU���?嘗試著回答這幾個問題來判斷一下:1)說出80386的中斷門和陷阱門的區別���;2)說出保護模式與實模式的區別��;3)多處理器機器上��,普通的讀-改-寫回一塊內存這樣的動作��,為什么需要特殊的手段來保護�����。等等�����。講解基于其它CPU的Linux內核的書�����,目前好象只有一本《IA64Linux內核:設計與實現》──也還是Intel的,其它都是講解基于IA32的。以上算是知識方面吧���,如果還要再補充一條,我想就是:動手編譯過內核��。好了�����,我們接下來走���。好多人裝上Linux之后�����,第一件事找到內核源碼所在的路徑,打開一個C程序文件,開始嘩嘩嘩翻頁,看看大名鼎鼎的Linux內核代碼到底長啥模樣──然后關閉。這是可理解的��,但卻不是學習的方法��。剛開始��,必須從讀書入手。[color=red:8c0c3b6f46]至少要對內核有一個Overview之后,才有可能帶著問題去試圖閱讀源代碼本身���。[/color:8c0c3b6f46]下面就講一下我讀過的幾本書:1,《Linux內核設計與實現》��,英文名LinuxKernelDevelopment(所以有人叫它LKD),機械工業出版社���,¥35,美國RobertLove著,陳莉君譯者��。評說:此書是當今首屈一指的入門最佳圖書���。作者是為2.6內核加入了搶占的人��,對調度部分非常精通��,而調度是整個系統的核心�����,因此本書是很權威的�����。這本書講解淺顯易懂,全書沒有列舉一條匯編語句,但是給出了整個Linux操作系統2.6內核的概觀�����,使你能通過閱讀迅速獲得一個overview��。而且對內核中較為混亂的部分(如下半部)�����,它的講解是最透徹的。對沒怎么深入內核的人來說,這是強烈推薦的一本書�����。翻譯:翻譯水平�����、負責任程度都不錯,但是印刷存在一些錯誤���。買了此書的朋友可以參考我在Linux高級應用版的《Linux內核設計與實現中文版勘誤》:\
另外,此書2005年有了第二版��,目前尚無中譯本面世���。我就是對照著2nd-en勘誤1st-cn的�����。2,《Linux內核源代碼情景分析》上�����、下。毛德操�����、胡希明著�����,浙江大學出版社���,上冊¥80,下冊¥70.評說:本書是基于2.4.0內核的��,比較早,也沒聽說會出第二版��。上冊講解內存管理��、中斷、異常與系統調用�����、進程控制��、文件系統與傳統UnixIPC�����;下冊講解socket、設備驅動���、SMP和引導。關于這套書的評價褒貶不一,我個人認為其深度是同類著作中最優秀的。本書基于IntelIA32體系,由于厚度大,很多體系上的知識都捎帶講解了���,所以如果你想深入了解內核的工作機制而又不非常熟悉IntelCPU的體系構造�����,本書是最合適的。缺點是:版本較老���,沒有TCP/IP協議棧部分(它講的socket只是Unix域協議的),圖表太少��,不適合初學者入門�����。還有就是對學生朋友來說��,可能書價偏高,這樣的話可以考慮先買上冊��,因為上冊是核心部分���,下冊一大部分都在講具體PCI/ISA/USB設備的驅動��。翻譯:沒什么翻譯,作者是國人,而且行文流暢。本人書桌上諸多計算機經典圖書當中�����,這套是唯一又經典又無閱讀障礙的��。www.linuxforum.net內核版好多朋友已經把這書讀到六七遍了��,我很慚愧,上冊差不多讀熟了,下冊就SMP部分還看過──但這就花費了整整1年的時間��,還有好多弄不懂的�����。這里順便說明另外一個研究內核常見的誤區:目標太龐大��。要知道Linux內核(最新的2.6.13)bzip2壓縮之后37M,解壓縮之后244M,根本不是哪個人能夠吃透的��。即使是內核的核心開發團隊中��,恐怕也只LinusTorvalds�����、AlanCox、DavidMiller、IngoMolnar寥寥數人會有比較全面的了解���,其它人都是做自己專門的部分。我自己來說,目前已經決定放棄內存管理的全部(slab層��、LRU��、rbtree等)��、文件系統部分、外設驅動部分,暫時也沒打算弄IA32以外的其它體系的部分�����。3,《深入理解Linux內核》第二版���。中國電力出版社���。也是陳莉君譯��。此書是Linux內核黑客在推薦圖書時的首眩評說:此書C版的converse兄送了我一本第一版,因此就沒買第二版���,比較后悔。因此只就第一版說一說���,第一版基于2.2,第二版2.4。我見O'Reilly官方主頁上說第三版的英文版將于2005年11月出版��,也不知咱們何時才能見到�����。此書圖表很多��,形象地給出了關鍵數據結構的定義���,與《情景分析》相比���,本書內容緊湊��,不會一個問題講解動輒上百頁,有提綱挈領的功用,但是深度上要遜于《情景分析》��。4,其它的幾本書�����。市面上能見到的其它的Linux內核的圖書,象《Linux設備驅動程序》���、《Linux內核源代碼完全注釋》以及新出的《Linux內核分析及編程》等?�!禠inux設備驅動程序》第二版是基于2.4的��,中文翻譯不錯�����,中國電力出版。這書強調動手實踐�����,但它是講解“設備驅動”的���,不是最核心的東西���,而且有些東西沒硬件的話無法實踐��,可能更適合驅動開發的程序員吧���,不太適合那些Forfunandprofit的人�����。此書有第三版英文版,東南大學出版社影印���,講解2.6的���,行文流暢��,講解的面也比第二版更廣泛���,我讀過其中關于同步與互斥�����、內存分配的部分,感覺很不錯。《Linux內核源代碼完全注釋》(機械工業出版社)是同濟大學的博士生趙炯的著作�����,講解0.1Linux內核���,我沒買也沒看�����,有看過的朋友說一說��。《Linux內核分析及編程》(電子工業出版社)是剛剛出版的,國人寫的��,講解2.6.11。很多人說好�����,但有人說不夠系統�����,我沒買,不敢評說。還有一本清華出的《Linux內核編程指南(第三版)》,原書應該是好書��,但是翻譯���、排版十分糟爛�����,脫字跳行�����,根本沒法看,我買了一本又扔掉了。5,其它資源���。TLDP(TheLinuxDocumentationProject)有大量文檔,其中不少是關于內核的,有些是在國外出版過的,象《LinuxKernelInterls》《TheLinuxKernel》《LinuxKernelModuleProgrammingGuide》等,作者都是親身參加開發的人���,著作較為可信。該版是研究內核的中文Linux社區中水平最高的,有很多專家級別的牛人�����,強烈推薦去學習一下(但建議不要問太過分簡單的問題���,人家脾氣再好也會煩的^_^)��,它的置頂貼簡直是一個包羅萬象的FAQ���,精華區也有很多資料�����。只可惜太過曲高和寡�����,人氣不是很旺��。6,一本不是講解Linux的書:《現代體系結構上的Unix系統:內核程序員的SMP和Caching技術》,人民郵電出版社2003版��,定價¥39.本書雖然不是講解Linux�����,但是對所有Unix內核都是適用的��,適合對SMP和CPU的Cache這些組成原理知識不是很熟的朋友,而且是很多國外牛人推薦的書���。中文版翻譯非常負責。還有個很重要的問題:怎樣瀏覽內核源代碼�����。有的朋友喜歡在Windows上工作���,用SourceInsight�����;有的在Linux���,用SourceNavigator���;還有專門瀏覽源代碼的軟件�����,象lxr(LinuxCrossReference);還有用ctags/ectags/cscope等�����,這些都是很優秀的軟件���。我個人用Vim+ctags瀏覽(參考了www.linuxforum.net內核版wheelz大俠的文檔��,)���。此外���,前邊已經提到的一個重要的問題是:你研究內核的目的是什么���,開發���?樂趣��?如果是開發,而且是國內做開發��,把kernelAPI熟悉一下就差不太多了(你也知道國內的水平有多差)���,比方說copy_from_user()��、kmalloc()函數等���,kernelAPI在Internet上找得到���,編譯內核時也可以用DocBook生成(具體請參考內核源代碼包下的README文件);如果是研究,那就差別很大了���,需要下很大的苦功:會用kmalloc()絕不說明你懂得Linux內核的虛存管理子系統,正如同會講漢語不說明你懂中國文化一樣";
int len = strlen(pch);
char * pDest = new char[len+1];
int number = 1000000;
printf("源字符串長度:%d�����;運行次數:%d次\n", len,number);
DWORD take = GetTickCount();
for (int i=0;i < number;++i)

 {
{
strcpy(pDest,pch);
 }
}
printf("strcpy消耗時間:%ldms\n", GetTickCount() - take);
take = GetTickCount();
for (int i=0;i < number;++i)
{
memcpy(pDest,pch,strlen(pch));
}
printf("memcpy算len消耗時間:%ldms\n", GetTickCount() - take);
take = GetTickCount();
for (int i=0;i < number;++i)
{
memcpy(pDest,pch,len);
}
printf("memcpy消耗時間:%ldms\n", GetTickCount() - take);
while(1);
return 0;
 }
}
運行結果如下:
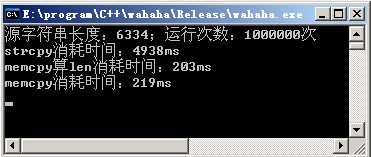
注:我的機器是Inter Core2 4G內存�����。編譯器是Visual Studio2010��。
由此可見,strcpy消耗的時間是memcpy消耗時間的24倍!
結論:倡導用memcpy替代strcpy/strncpy!