文章中引用的代碼均來自https://github.com/vczh/tinymoe。
?
實現(xiàn)Tinymoe的第一步自然是一個詞法分析器。詞法分析其所作的事情很簡單,就是把一份代碼分割成若干個token,記錄下他們所在文件的位置,以及丟掉不必要的信息。但是Tinymoe是一個按行分割的語言,自然token列表也就是二維的,第一維是行,第二維是每一行的token。在繼續(xù)講詞法分析器之前,先看看Tinymoe包含多少token:
符號:(、)、,、:、&、+、-、*、/、\、%、<、>、<=、>=、=、<>
關鍵字:module、using、phrase、sentence、block、symbol、type、cps、category、expression、argument、assignable、list、end、and、or、not
數(shù)字:123、456.789
字符串:"abc\r\ndef"
標識符:tinymoe
注釋:-- this is a comment
?
Tinymoe對于token有一個特殊的規(guī)定,就是字符串和注釋都是單行的。因此如果一個字符串在沒有結束之前就遇到了換行,那么這種寫法定義為你遇到了一個沒有右雙引號的字符串,需要報個錯,然后下一行就不是這個字符串的內容了。
?
一個詞法分析器所需要做的事情,就是把一個字符串分解成描述此法的數(shù)據(jù)結構。既然上面已經(jīng)說到Tinymoe的token列表是二維的,因此數(shù)據(jù)結構肯定會體現(xiàn)這個觀點。Tinymoe的詞法分析器代碼可以在這里找到:https://github.com/vczh/tinymoe/blob/master/Development/Source/Compiler/TinymoeLexicalAnalyzer.h。
?
首先是token:
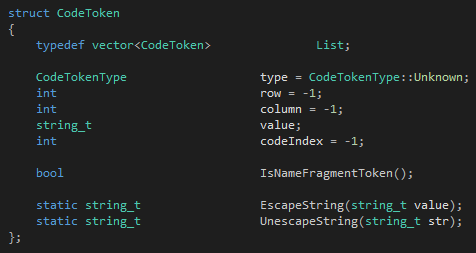
CodeTokenType是一個枚舉類型,標記一個token的類型。這個類型比較細化,每一個關鍵字有自己的類型,每一個符號也有自己的類型,剩下的按種類來分。我們可以看到token需要記錄的最關鍵的東西只有三個:類型、內容和代碼位置。在token記錄代碼位置是十分重要的,正確地記錄代碼位置可以讓你能夠報告帶位置的錯誤、從語法樹的節(jié)點還原成代碼位置、甚至在調試的時候可以把指令也換成位置。
?
這里需要提到的是,string_t是一個typedef,具體的聲明可以在這里看到:https://github.com/vczh/tinymoe/blob/master/Development/Source/TinymoeSTL.h。Tinymoe是完全由標準的C++11和STL寫成的,但是為了適應不同情況的需要,Tinymoe分為依賴code page的版本和Unicode版本。如果編譯Tinymoe代碼的時候聲明了全局的宏UNICODE_TINYMOE的話,那Tinymoe所有的字符處理將使用wchar_t,否則使用char。char的類型和Tinymoe編譯器在運行的時候操作系統(tǒng)當前的code page是綁定的。所以這里會有類似string_t啊、ifstream_t啊、char_t等類型,會在不同的編譯選項的影響下指向不同的STL類型或者原生的C++類型。github上的VC++2013工程使用的是wchar_t的版本,所以string_t就是std::wstring。
?
Tinymoe的詞法分析器除了token的類型以外,肯定還需要定義整個文件結構在詞法分析后的結果:
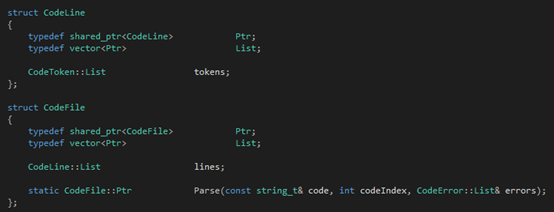
這個數(shù)據(jù)結構體現(xiàn)了"Tinymoe的token列表是二維的"的這個觀點。一個文件會被詞法分析器處理成一個shared_ptr<CodeFIle>對象,CodeFile::lines記錄了所有非空的行,CodeLine::tokens記錄了該行的所有token。
?
現(xiàn)在讓我們來看詞法分析的具體過程。關于如何從正則表達式構造詞法分析器可以在這里(http://www.shnenglu.com/vczh/archive/2008/05/22/50763.html)看到,不過我們今天要講一講如何人肉構造詞法分析器。方法其實是一樣的,首先人肉構造狀態(tài)機,然后把用狀態(tài)機分析輸入的字符串的代碼抄過來就可以了。但是很少有人會解耦得那么開,因為這樣寫很容易看不懂,其次有可能會遇到一些極端情況是你無法用純粹的正則表達式來分詞的,譬如說C++的raw string literal:R"tinymoe(這里的字符串沒有轉義)tinymoe"。一個用【R"<一些字符>(】開始的字符串只能由【)<同樣的字符>"】來結束,要順利分析這種情況,只能通過在狀態(tài)機里面做hack才能解決。這就是為什么我們人肉構造詞法分析器的時候,會把狀態(tài)和動作都混在一起寫,因為這樣便于處理特殊情況。
?
不過幸好的是,Tinymoe并沒有這種情況發(fā)生。所以我們可以直接從狀態(tài)機入手。為了簡單起見,我在下面的狀態(tài)機中去掉所有不是+和-的符號。首先,我們需要一個起始狀態(tài)和一個結束狀態(tài):

?
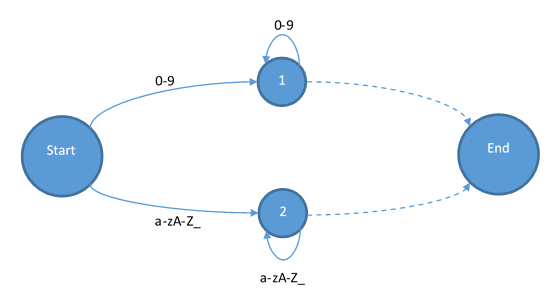
首先我們添加整數(shù)和標識符進去:
?
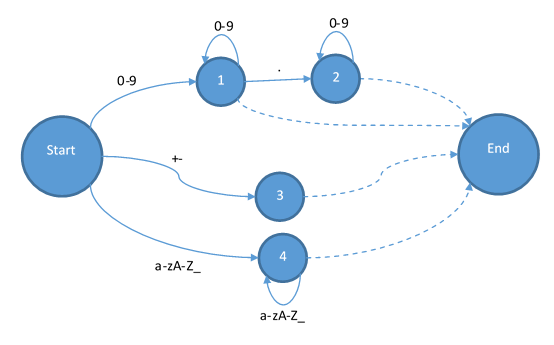
其次是加減和浮點:
?
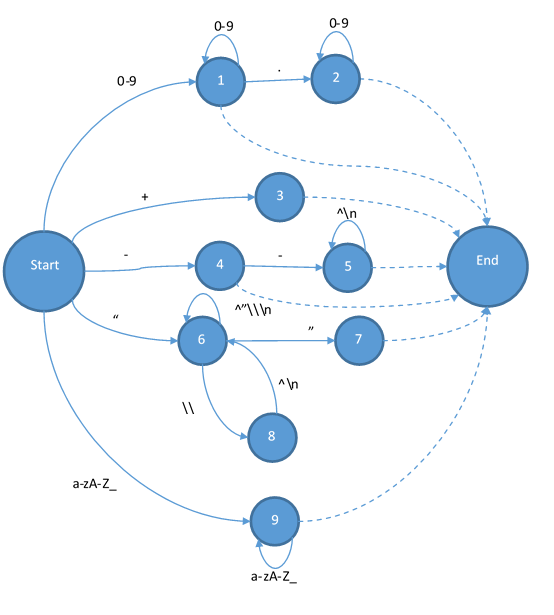
最后把字符串和注釋補全:
?
這樣狀態(tài)機就已經(jīng)完成了。讀過編譯原理的可能會問,為什么終結狀態(tài)都是由虛線而不是帶有輸入的實現(xiàn)指向的?因為虛線在這里有特殊的意義,也就是說它不能移動輸入的字符串的指針,而且他還要負責添加一個token。當狀態(tài)跳到End之后,那他就會變成Start,所以實際上Start和End是同一個狀態(tài)。這個狀態(tài)機也不是輸入什么字符都能跳轉到下一個狀態(tài)的。所以當你發(fā)現(xiàn)輸入的字符讓你無路可走的時候,你就是遇到了一個詞法錯誤。
?
這樣我們的設計就算完成了,接下來就是如何用C++來實現(xiàn)它了。為了讓代碼更容易閱讀,我們應該給Start和1-9這么多狀態(tài)起名字,做法如下:
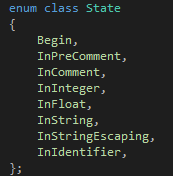
在這里類似狀態(tài)3這樣的狀態(tài)被我省略掉了,因為這個狀態(tài)唯一的出路就是虛線,所以跳到這個狀態(tài)意味著你要立刻執(zhí)行虛線,也就是說你不需要做"跳到這個狀態(tài)"這個動作。因此它不需要有一個名字。
?
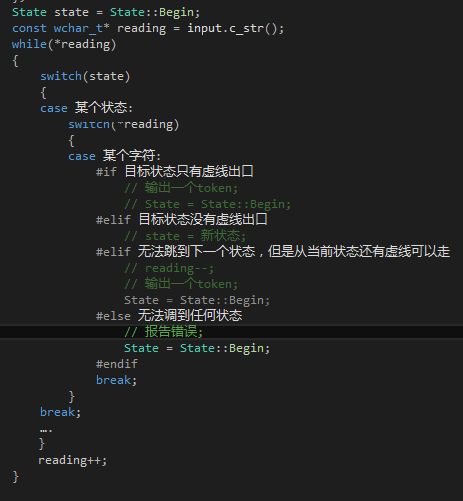
然后你只要按照下面的做法翻譯這個狀態(tài)機就可以了:
?
只要寫到這里,那么我們就初步完成了詞法分析器了。其實任何系統(tǒng)的主要功能都是相對容易實現(xiàn)的,往往是次要的功能才需要花費大量的精力來完成,而且還很容易出錯。在這里"次要的功能"就是——記錄token的行列號,還有維護CodeFile::lines避免空行的出現(xiàn)!
?
盡管我已經(jīng)做過了那么多次詞法分析器,但是我仍然無法一氣呵成寫對,仍然會出一些bug。面對編譯器這種純計算程序,debug的最好方法就是寫單元測試。不過對于不熟悉單元測試的人來講可能很難一下子想到要做什么測試,在這里我可以把我給Tinymoe謝的一部分單元測試在這里貼一下。
?
第一個,當然是傳說中的"Hello, world!"測試了:
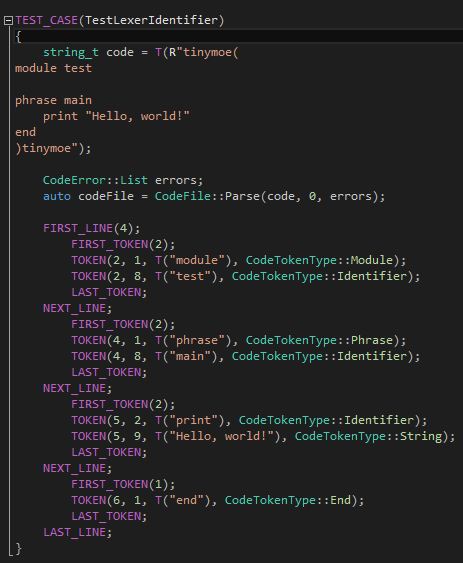
?
TEST_CASE和TEST_ASSERT(這里暫時沒有直接用到TEST_ASSERT)是我為了開發(fā)Tinymoe隨手擼的一個宏,可以在Tinymoe的代碼里看到。為了檢查我們有沒有粗心大意,我們有必要檢查詞法分析器的任何一個輸出的數(shù)據(jù),譬如每一行有多少token,譬如每一個token的行號列好內容和類型。我為了讓這些枯燥的測試用例容易看懂,在這個文件(
?
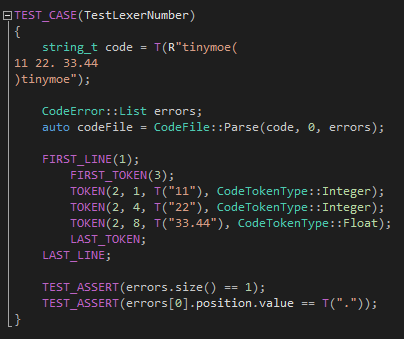
第二個測試用例針對的是整數(shù)和浮點的輸出和報錯上,重點在于檢查每一個token的列號是不是正確的計算了出來:
?
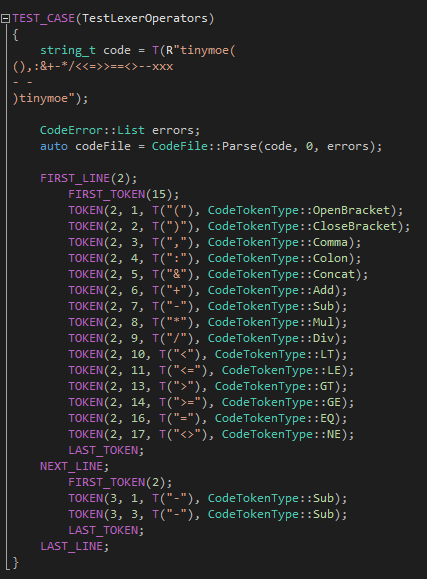
第三個測試用例的重點主要是-符號和—注釋的分析:
?
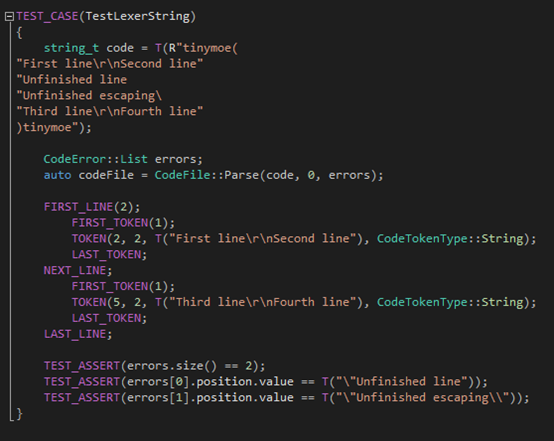
第四個測試用例則是測試字符串的escaping和在面對換行的時候是否正確的處理(之前提到字符串不能換行,遇到一個突然的換行將會被看成缺少雙引號):
?
鑒于詞法分析本來內容也不多,所以這篇文章也不會太長。相信有前途的程序員也會在這里得到一些編譯原理以外的知識。下一篇文章將會描述Tinymoe的函數(shù)頭的語法分析部分,將會描述一個編譯器的不帶歧義的語法分析是如何人肉出來的。敬請期待。
posted on 2014-03-02 07:44
陳梓瀚(vczh) 閱讀(13024)
評論(10) 編輯 收藏 引用 所屬分類:
跟vczh看實例學編譯原理