#
摘要: 考慮一下多線程代碼,在設計上,App為了獲取更多的功能,從Window派生,而App同時為了獲取某個模塊的回調(所謂的Listener),App同時派生Listener,并將自己的指針交給另一個模塊,另一個模塊通過該指針多態回調到App的實現(對Listener規定的接口的implemention)。設計上只是一個很簡單的Listener回調,在單線程模式下一切都很正常(后面我會羅列代碼),但是換...
閱讀全文
很早前就想寫點總結將編程中遇到的各種錯誤刨根挖底地羅列出來。但是因為這些錯誤(VC中開調試器遇到的各種錯誤對話框)都是隨機性的,真正想總結的時候又不想不起來有哪些錯誤。恰好最近運氣比較背,各種錯誤都被我遇遍了,于是恰好有機會做個總結。
這里所說的VC下的錯誤對話框時指在VC中開調試器運行程序時,IDE彈出的對話框。
1.不是錯誤的錯誤:斷言 .
將斷言視為錯誤其實有點可笑,但是因為有些同學甚至不知道這個,所以我稍微提一下。斷言對話框大致上類似于:
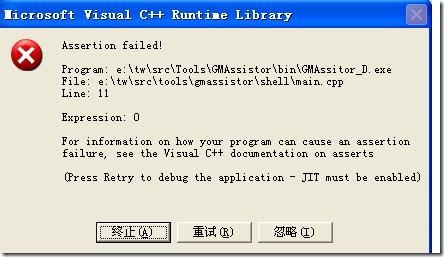
斷言對話框是由assert引起的,在對話框上通常會給出表達式,例如assert( 0 ); 彈出對話框時就會將0這個表達式顯示出來(Expression:0)。關于assert的具體信息建議自己google。這里稍微提一下一個技巧:有時候為了讓assert提供更多的信息,我們可以這樣寫一個assert:
assert( expression && "Function : invalid argument!" );
因為字符串被用在布爾表達式中時,始終為true,不會妨礙對expression的判斷,當斷言發生時(expression為false) 時,斷言對話框上就會顯示這個字符串,從而方便我們調試。
要解決這個問題,首先要確定斷言發生的位置,如果是你自己設置的斷言被引發,就很好解決,如果是系統內部的函數產生的,那么一般是因為你傳入的函數參數無效引起。
2.內存相關:最簡單的非法訪問:
C、C++程序中經常誤用無效的指針,從而大致各種各樣的非法內存訪問(寫/讀)。最簡單的情況類似于:
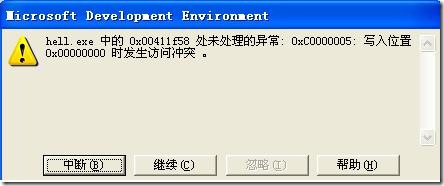
這樣的情況由類似以下代碼引起:
char *p = 0;
*p = 'a';
當你看到類似于“寫入位置XXXX時發生訪問沖突“時,那么你大致可以斷定,你的程序在某個地方訪問到非法內存。開調試器對調用堆棧進行跟蹤即可找出錯誤。
3.內存相關:不小心的棧上數組越界:
當你寫下類似以下的代碼時:
char str[3];
strcpy( str, "abc" );
就將看到如下的對話框:
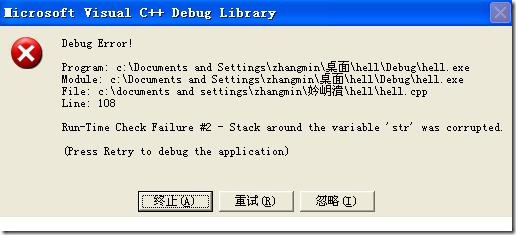
對話框大致的意思就是說str周圍的棧被破壞了,因為str本身就被放在棧上,所以strcpy(str,"abc")多寫入的'\0'就寫到非法的棧區域。看到這樣的對話框可以根據調用堆棧定位到錯誤發生的函數,然后檢查此函數內部定義的數組訪問,即可解決問題。
4.內存相關:不小心的堆上數組越界:
并不是每次數組越界都會得到上面所描述的錯誤,當數組是在堆上分配時,情況就變得隱秘得多:
char *str = new char [2];
strcpy( str, "ab" ); //執行到這里時并不見得會崩潰
delete [] str;//但是到這里時就肯定會崩潰
以上代碼導致的錯誤對話框還要詭異些:
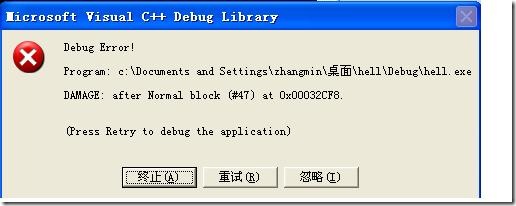
似乎不同的DAMAGE對應的錯誤號(這里是47)都不一樣,因為這里的錯誤發生在delete,而delete跟new很可能在不同的地方,所以這個錯誤調試起來不是那么容易,很多時候只能靠經驗。
當看到類似的對話框時,根據調用堆棧跟到delete時,你就可以大致懷疑堆上數組越界。
5.調用相關:函數調用約定帶來的錯誤:
這是所有我這里描述的錯誤中最詭異的一種,先看下對話框大致的樣子:

對話框大致的意思就是說(沒開調試器時對話框樣式可能不一樣),通過函數指針調用某個函數時,函數指針的類型(函數原型)可能與函數指針指向的函數的類型不一樣。這里的類型不一致主要是調用約定(call conversation)不一樣。如果函數類型(參數個數,返回值)不一樣,一般不會出錯。
調用約定是指調用一個函數時,函數參數的壓入順序、誰來清理棧的內容等。例如默認的C、C++調用約定__cdecl,對于函數的參數是從右往左壓入。而__stdcall(WIN API的調用約定)則是從左向右壓。我這里所說的函數類型不一樣,就是指一個函數是使用__cdecl,還是__stdcall。例如以下代碼:
 #include <iostream>
#include <iostream>
void __stdcall show( const char *str )


 {
{

 }
}
void __stdcall show2()
{
}
int main()
{
typedef void (*Func)( const char *);
void *p = show;
Func my_func = (Func) p;
my_func( "kevin" );
return 0;
}
因為Func默認地被處理為__cdecl,而show是__stdcall的,所以當通過函數指針my_func時,就導致了以上對話框的出現。但是當p指向show2時,又不會出錯,這是因為show2沒有參數,不同的調用約定不影響這個規則。
6.異常相關:默認終止程序
當我們使用C++庫時,因為庫本身可能會拋出C++異常,如果你不捕獲這個異常,那么C++默認就會調用abort(或者exit)函數終止程序。例如:
void test()
{
throw std::exception( "some exceptions" );
}
當你調用test函數時,如果不catch這個異常,開調試器就會得到類似的錯誤對話框:
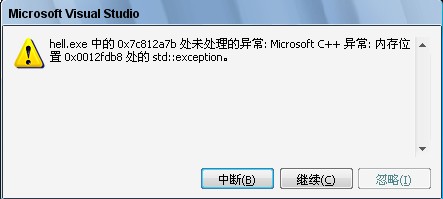
而如果不開調試器,則會得到:
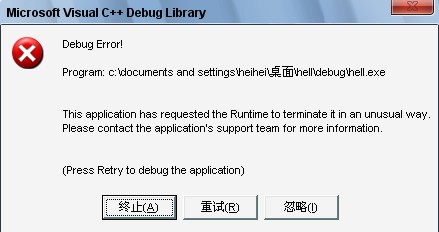
當你看到類似于“This application has requested the Runtime to terminate it…”之類的字眼時,那就表明程序調用了abort(或exit)函數,導致程序異常終止。其實這個錯誤只要開調試器,一般可以準確定位錯誤的發生點。
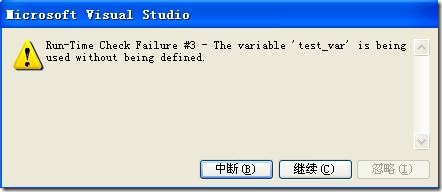
7.VC運行時檢查-未初始化變量
VC的調試器會對代碼進行運行時檢查,這可能會導致VC彈出對你看上去正確的代碼。這也許不是一個錯誤。例如:
int test_var;
if( test_var == -1 )
{
test_var = 0;
}
test_var沒有初始化就進行if判斷,當運行以上代碼開調試器時,就會得到如下對話框:
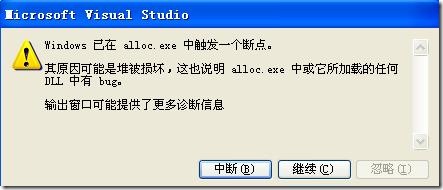
8.破壞的堆
VC對于在堆上分配的內存都做了記錄,我想這主要用于free釋放內存時做歸還處理。
char *p = (char*) malloc( 100 );
p += 10;
free( p );
當執行以上代碼時,因為p的值已經改變,提交到free的指針值變化,VC就會給出以下錯誤提示:
最近在草草地看<TCP/IP詳解>TCP那一部分,之所以草草地看是因為覺得早晚一天會回過頭去細看。手頭上
有工作要做,所以先草草地把之前隨便摘抄的TCP/IP相關概念貼出來:
繼續草草地貼:
--------------------------------------------------------------------------------------------------------------------------------------------------------
TCP segment:
Thus, we have simply “passed the buck” to TCP, which must take the stream from the application
and divide it into discrete messages for IP. These messages are called TCP segments.
On regular intervals, it forms segments to be transmitted using IP. The size of the segment is
controlled by two primary factors. The first issue is that there is an overall limit to the size
of a segment, chosen to prevent unnecessary fragmentation at the IP layer. This is governed by a
parameter called the maximum segment size (MSS), which is determined during connection establishment.
The second is that TCP is designed so that once a connection is set up, each of the devices tells the
other how much data it is ready to accept at any given time. If this is lower than the MSS value, a
smaller segment must be sent. This is part of the sliding window system described in the next topic.
Since TCP works with individual bytes of data rather than discrete messages, it must use an
identification scheme that works at the byte level to implement its data transmission and tracking
system. This is accomplished by assigning each byte TCP processes a sequence number.
Since applications send data to TCP as a stream of bytes and not prepackaged messages, each
application must use its own scheme to determine where one application data element ends and the
next begins.
--------------------------------------------------------------------------------------------------------------------------------------------------------
TCP MSS:
http://www.tcpipguide.com/free/t_TCPMaximumSegmentSizeMSSandRelationshiptoIPDatagra.htm
In addition to the dictates of the current window size, each TCP device also has associated
with it a ceiling on TCP size—a segment size that will never be exceeded regardless of how
large the current window is. This is called the maximum segment size (MSS). When deciding
how much data to put into a segment, each device in the TCP connection will choose the amount
based on the current window size, in conjunction with the various algorithms described in
the reliability section, but it will never be so large that the amount of data exceeds the
MSS of the device to which it is sending.
Note: I need to point out that the name “maximum segment size” is in fact misleading. The
value actually refers to the maximum amount of data that a segment can hold—it does not
include the TCP headers. So if the MSS is 100, the actual maximum segment size could be 120
(for a regular TCP header) or larger (if the segment includes TCP options).
This was computed by starting with the minimum MTU for IP networks of 576.
Devices can indicate that they wish to use a different MSS value from the default by including
a Maximum Segment Size option in the SYN message they use to establish a connection. Each
device in the connection may use a different MSS value.
--------------------------------------------------------------------------------------------------------------------------------------------------------
delayed ACK algorithm
http://tangentsoft.net/wskfaq/intermediate.html#delayed-ack
In a simpleminded implementation of TCP, every data packet that comes in is immediately acknowledged
with an ACK packet. (ACKs help to provide the reliability TCP promises.)
In modern stacks, ACKs are delayed for a short time (up to 200ms, typically) for three reasons: a)
to avoid the silly window syndrome; b) to allow ACKs to piggyback on a reply frame if one is ready
to go when the stack decides to do the ACK; and c) to allow the stack to send one ACK for several
frames, if those frames arrive within the delay period.
The stack is only allowed to delay ACKs for up to 2 frames of data.
--------------------------------------------------------------------------------------------------------------------------------------------------------
Nagle algorithm:
Nagle's algorithm, named after John Nagle, is a means of improving the efficiency of TCP/IP networks by reducing the number of packets that need to be sent over the network.
Nagle's document, Congestion Control in IP/TCP Internetworks (RFC896) describes what he called the 'small packet problem', where an application repeatedly emits data in small chunks, frequently only 1 byte in size. Since TCP packets have a 40 byte header (20 bytes for TCP, 20 bytes for IPv4), this results in a 41 byte packet for 1 byte of useful information, a huge overhead. This situation often occurs in Telnet sessions, where most keypresses generate a single byte of data which is transmitted immediately. Worse, over slow links, many such packets can be in transit at the same time, potentially leading to congestion collapse.
Nagle's algorithm works by coalescing a number of small outgoing messages, and sending them all at once. Specifically, as long as there is a sent packet for which the sender has received no acknowledgment, the sender should keep buffering its output until it has a full packet's worth of output, so that output can be sent all at once.
[edit] Algorithm
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
where MSS = Maximum segment size
This algorithm interacts badly with TCP delayed acknowledgments, a feature introduced into TCP at roughly the same time in the early 1980s, but by a different group. With both algorithms enabled, applications which do two successive writes to a TCP connection, followed by a read, experience a constant delay of up to 500 milliseconds, the "ACK delay". For this reason, TCP implementations usually provide applications with an interface to disable the Nagle algorithm. This is typically called the TCP_NODELAY option. The first major application to run into this problem was the X Window System.
The tinygram problem and silly window syndrome are sometimes confused. The tinygram problem occurs when the window is almost empty. Silly window syndrome occurs when the window is almost full
===================================================================================================================================
3.17 - What is the Nagle algorithm?
The Nagle algorithm is an optimization to TCP that makes the stack wait until all data is acknowledged on the connection before it sends more data. The exception is that Nagle will not cause the stack to wait for an ACK if it has enough enqueued data that it can fill a network frame. (Without this exception, the Nagle algorithm would effectively disable TCP's sliding window algorithm.) For a full description of the Nagle algorithm, see RFC 896.
So, you ask, what's the purpose of the Nagle algorithm?
The ideal case in networking is that each program always sends a full frame of data with each call to send(). That maximizes the percentage of useful program data in a packet.
The basic TCP and IPv4 headers are 20 bytes each. The worst case protocol overhead percentage, therefore, is 40/41, or 98%. Since the maximum amount of data in an Ethernet frame is 1500 bytes, the best case protocol overhead percentage is 40/1500, less than 3%.
While the Nagle algorithm is causing the stack to wait for data to be ACKed by the remote peer, the local program can make more calls to send(). Because TCP is a stream protocol, it can coalesce the data in those send() calls into a single TCP packet, increasing the percentage of useful data.
Imagine a simple Telnet program: the bulk of a Telnet conversation consists of sending one character, and receiving an echo of that character back from the remote host. Without the Nagle algorithm, this results in TCP's worst case: one byte of user data wrapped in dozens of bytes of protocol overhead. With the Nagle algorithm enabled, the TCP stack won't send that one Telnet character out until the previous characters have all been acknowledged. By then, the user may well have typed another character or two, reducing the relative protocol overhead.
This simple optimization interacts with other features of the TCP protocol suite, too:
Most stacks implement the delayed ACK algorithm: this causes the remote stack to delay ACKs under certain circumstances, which allows the local stack a bit of time to "Nagle" some more bytes into a single packet.
The Nagle algorithm tends to improve the percentage of useful data in packets more on slow networks than on fast networks, because ACKs take longer to come back.
TCP allows an ACK packet to also contain data. If the local stack decides it needs to send out an ACK packet and the Nagle algorithm has caused data to build up in the output buffer, the enqueued data will go out along with the ACK packet.
The Nagle algorithm is on by default in Winsock, but it can be turned off on a per-socket basis with the TCP_NODELAY option of setsockopt(). This option should not be turned off except in a very few situations.
Beware of depending on the Nagle algorithm too heavily. send() is a kernel function, so every call to send() takes much more time than for a regular function call. Your application should coalesce its own data as much as is practical to minimize the number of calls to send().
--------------------------------------------------------------------------------------------------------------------------------------------------------
Sliding Window Acknowledgment System :
http://www.tcpipguide.com/free/t_TCPSlidingWindowAcknowledgmentSystemForDataTranspo.htm
--------------------------------------------------------------------------------------------
A basic technique for ensuring reliability in communications uses a rule that requires a
device to send back an acknowledgment each time it successfully receives a transmission.
If a transmission is not acknowledged after a period of time, it is retransmitted by its
sender. This system is called positive acknowledgment with retransmission (PAR). One
drawback with this basic scheme is that the transmitter cannot send a second message
until the first has been acknowledged.
--------------------------------------------------------------------------------------------
http://www.ssfnet.org/Exchange/tcp/tcpTutorialNotes.html
The sliding window serves several purposes:
(1) it guarantees the reliable delivery of data
(2) it ensures that the data is delivered in order,
(3) it enforces flow control between the sender and the receiver.
------------------to be continued
Ascent網絡模塊
Author: Kevin Lynx
Ascent是WoW的服務器模擬器,你可以從它的SVN上獲取它的全部代碼,并從它的WIKI頁面獲取架構起整個服務器的相關步驟。
基本架構:
Ascent網絡模塊核心的幾個類關系如下圖所示:
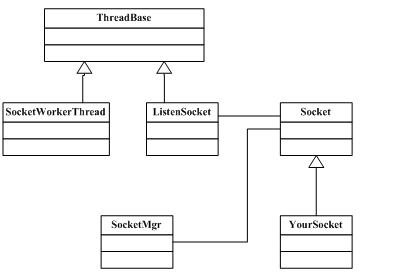
ThreadBase屬于Ascent線程池模塊中的類,它實現了一個job類,當其被加入到線程池中開始執行時,線程池管理器會為其分配一個線程(如果有線程資源)并多態調用到ThreadBase派生類的run函數。
SocketWorkerThread用以代表IOCP網絡模型中的一個工作者線程,它會從IOCP結果隊列里取出異步IO的操作結果。這里的IOCP使用的完成鍵是Socket對象指針。SocketWorkerThread獲取到IO操作結果后,根據獲得的完成鍵將結果通知給具體的Socket對象。(Socket的說明見后面)
ListenSocket代表一個監聽套接字。該網絡模塊其實只是簡單地將socket中的概念加以封裝。也就說,它依然把一個套接字分為兩種類型:監聽套接字和數據套接字(代表一個網絡連接)。所謂的監聽套接字,是指只可以在該套接字上進行監聽操作;而數據套接字則只可以在此套接字上進行發送、接收數據的操作。
Socket代表我上面說的數據套接字。ListenSocket是一個類模板,為這個模板指定的模板參數通常是派生于Socket的類。其實這里使用了這個小技巧隱藏了工廠模式的細節。因為ListenSocket被放在一個單獨的線程里運作,當其接受到一個新的網絡連接時,就創建一個Socket派生類對象。(ListenSocket類如何知道這個派生類的類名?這就是通過類模板的那個模板參數)
上層模塊通常會派生Socket類,實現一些IO操作的回調。也就說,當某個IO操作完成后,會通過Socket基類讓上層模塊獲取通知。
SocketMgr是一個全局單件類。它主要負責一些網絡庫的全局操作(例如winsock庫的初始化),它還維護了一個容器,保存所有的Socket對象。這其實是它的主要作用。
運作之一,接收新的連接:
接收新的網絡連接是通過ListenSocket實現的。在創建一個ListenSocket對象時,你需要指定它的模板參數。這個參數通常是一個派生于Socket的類。如下:
ascent-logonserver/Main.cpp
ListenSocket<AuthSocket> * cl = new ListenSocket<AuthSocket>(host.c_str(), cport);
AuthSocket派生于Socket。創建ListenSocket時構造函數指定監聽IP和監聽端口。
因為ListenSocket派生于ThreadBase,屬于線程池job,因此要讓ListenSocket工作起來,只需要將其加入到線程池管理器:
ascent-logonserver/Main.cpp
ThreadPool.ExecuteTask(cl);
ListenSocket開始運作起來后,會阻塞式地WSAAccept。如果WSAAccept返回一個有效的套接字,ListenSocket就創建一個Socket派生類對象(類型由模板參數指定),在上面舉的例子中,也就是AuthSocket:
ascent-logonserver/ ListenSocketWin32.h
socket = new T(aSocket); //創建AuthSocket并保存網絡套接字aSocket
socket->SetCompletionPort(m_cp);//保存完成端口對象
socket->Accept(&m_tempAddress); //關聯到完成端口等
Accept函數最終會將新創建的Socket對象保存到SocketMgr對象內部維護的容器里。在這里,還會回調到上層模塊的OnConnect函數,從而實現信息捕獲。
運作之二,接收數據
在windows平臺下,該網絡模塊使用的是IOCP模型,屬于異步IO。當接收新的連接時,即發出WSARecv的IO操作。在工作者線程中,也就是SocketWorkerThread中,會根據IOCP完成鍵得到Socket對象指針,然后根據不同的IO操作結果多態回調到Socket派生類對應的函數。例如如果是WSARecv完成,則調用到AuthSocket::OnRead函數(上述例子)。OnRead函數直接可以獲取到保存數據的緩沖區指針。事實上,每一個Socket對象在被創建時,就會自動創建接收緩沖區以及發送緩沖區。
運作之三,發送數據
分析到這里,我們可以看出,該網絡模塊實現得很一般。在接受數據部分,網絡工作者線程回調到對應的Socket對象,Socket直接對數據進行上層邏輯處理。更好的做法是當工作者線程回調到上層Socket(Socket的派生類)時,這里應該簡單地將數據組織成上層數據包并放入上層數據包隊列,讓上層邏輯稍后處理,而不是讓網絡模塊自己去處理。這樣做主要是考慮到多線程模型。
同樣,該網絡模塊的發送模塊也是一樣,沒有緩沖機制。當要發送數據時,直接調用到Socket的Send函數。該函數拷貝用戶數據到自己維護的發送緩沖區,然后將自己的緩沖區指針直接提交給IOCP,WSASend發送。
結束
該網絡模塊實現的似乎有點簡陋,在該模塊之上也沒有數據校驗、數據加密的模塊(這些動作散亂地分布在最上層邏輯)。在架構上也沒能很好地將概念區分開來,Socket套用了原始socket中的數據套接字,而不是我所希望的NetSession。可以圈點的地方在于該模塊很多地方使用了回調函數表,從而方便地實現事件傳送。
摘要: 探究CRC32算法實現原理-why table-driven implemention
Author : Kevin Lynxemail : zmhn320@163.com
Preface
基于不重造輪子的原則,本文盡量不涉及網絡上遍地都是的資料。
What's CRC ?
簡而言之,CRC是一個數值。該數值被用于校驗數據的正確性。CRC數值簡單地說就是通過讓你需要做處理的數...
閱讀全文
Author : Kevin Lynx
當軟件作為release模式被發布給用戶時,當程序崩潰時我們很難去查找原因。常見的手法是輸出LOG文件,根據LOG文件分析
程序崩潰時的運行情況。我們可以通過SEH來捕獲程序錯誤,然后輸出一些有用的信息作為我們分析錯誤的資料。一般我們需要
輸出的信息包括:系統信息、CPU寄存器信息、堆棧信息、調用堆棧等。而調用堆棧則是最有用的部分,它可以直接幫我們定位
到程序崩潰時所處的位置(在何處崩潰)。(codeproject上關于這個專題的常見開場白 = =#)
要獲取call stack(所謂的調用堆棧),就需要查看(unwind)stack的內容。We could conceivably attempt to unwind the
stack ourselves using inline assembly. But stack frames can be organized in different ways, depending on compiler
optimizations and calling conventions, so it could become complicated to do it that way.(摘自vld文檔)要獲取棧的
內容,我們可以自己使用內聯匯編獲取,但是考慮到兼容性,內聯匯編并不是一個好的解決方案。我們可以使用微軟的dbghelp
中的StackWalk64來獲取棧的內容。
StackWalk64聲明如下:
BOOL StackWalk64(
DWORD MachineType,
HANDLE hProcess,
HANDLE hThread,
LPSTACKFRAME64 StackFrame,
PVOID ContextRecord,
PREAD_PROCESS_MEMORY_ROUTINE64 ReadMemoryRoutine,
PFUNCTION_TABLE_ACCESS_ROUTINE64 FunctionTableAccessRoutine,
PGET_MODULE_BASE_ROUTINE64 GetModuleBaseRoutine,
PTRANSLATE_ADDRESS_ROUTINE64 TranslateAddress
);
具體每個參數的含義可以參見MSDN。這里說下ContextRecord參數,該參數指定了CPU各個寄存器的內容。StackFrame指定了stack
frame的內容。stack frame是什么,我也不知道。(= =) StackWalk64函數需要用戶指定當前frame的地址,以及當前程序的指令
地址。這兩個信息都被填充進ContextRecord,然后傳進StackWalk64函數。
那么如何獲取當前的stack frame地址和當前程序指令地址呢?如前所說,你可以使用內聯匯編。(對于程序指令地址,因為要獲取
EIP寄存器的內容,而該寄存器不能被軟件訪問)也可以使用GetThreadContext一次性獲取當前線程當前運行情況下的CPU各個寄存器
內容。補充下,當前frame地址被放在EBP寄存器里,當前程序指令地址放在EIP寄存器里。但是,如同MSDN對GetThreadContext函數
的說明一樣,該函數可能獲取到錯誤的寄存器內容(You cannot get a valid context for a running thread)。
另一種獲取Context(包含EBP and EIP)的方法就是使用SEH(結構化異常處理),在__except中使用GetExceptionInformation獲取。
GetExceptionInformation 傳回一個LPEXCEPTION_POINTERS指針,該指針指向一個EXCEPTION_POINTERS結構,該結構里包含一個
Context的指針,即達到目標,可以使用StackWalk函數。
補充一下,你可以直接使用StackWalk函數,StackWalk被define為StackWalk64(windows平臺相關)。
unwind棧后,可以進一步獲取一個stack frame的內容,例如函數名。這里涉及到SymFromAddr函數,該函數可以根據一個地址返回
符號名(函數名)。還有一個有意思的函數:SymGetLineFromAddr,可以獲取函數對應的源代碼的文件名和行號。
當然,這一切都依賴于VC產生的程序數據庫文件(pdb),以及提供以上API函數的dbghelp.dll。
參考一段簡單的代碼:
/**////
///
///#include <windows.h>
#include <stdio.h>
#include <dbghelp.h>
#pragma comment( lib, "dbghelp.lib" )
void dump_callstack( CONTEXT *context )
{
STACKFRAME sf;
memset( &sf, 0, sizeof( STACKFRAME ) );
sf.AddrPC.Offset = context->Eip;
sf.AddrPC.Mode = AddrModeFlat;
sf.AddrStack.Offset = context->Esp;
sf.AddrStack.Mode = AddrModeFlat;
sf.AddrFrame.Offset = context->Ebp;
sf.AddrFrame.Mode = AddrModeFlat;
DWORD machineType = IMAGE_FILE_MACHINE_I386;
HANDLE hProcess = GetCurrentProcess();
HANDLE hThread = GetCurrentThread();
for( ; ; )

 {
{
if( !StackWalk(machineType, hProcess, hThread, &sf, context, 0, SymFunctionTableAccess, SymGetModuleBase, 0 ) )
{
break;
 }
}
if( sf.AddrFrame.Offset == 0 )
{
break;
}
BYTE symbolBuffer[ sizeof( SYMBOL_INFO ) + 1024 ];
PSYMBOL_INFO pSymbol = ( PSYMBOL_INFO ) symbolBuffer;
pSymbol->SizeOfStruct = sizeof( symbolBuffer );
pSymbol->MaxNameLen = 1024;
DWORD64 symDisplacement = 0;
if( SymFromAddr( hProcess, sf.AddrPC.Offset, 0, pSymbol ) )
{
printf( "Function : %s\n", pSymbol->Name );
}
else
{
printf( "SymFromAdd failed!\n" );
}
IMAGEHLP_LINE lineInfo = { sizeof(IMAGEHLP_LINE) };
DWORD dwLineDisplacement;
if( SymGetLineFromAddr( hProcess, sf.AddrPC.Offset, &dwLineDisplacement, &lineInfo ) )
{
printf( "[Source File : %s]\n", lineInfo.FileName );
printf( "[Source Line : %u]\n", lineInfo.LineNumber );
}
else
{
printf( "SymGetLineFromAddr failed!\n" );
}
}
}
DWORD excep_filter( LPEXCEPTION_POINTERS lpEP )
{
/**//// init dbghelp.dll
if( SymInitialize( GetCurrentProcess(), NULL, TRUE ) )
{
printf( "Init dbghelp ok.\n" );
}
dump_callstack( lpEP->ContextRecord );
if( SymCleanup( GetCurrentProcess() ) )
{
printf( "Cleanup dbghelp ok.\n" );
}
return EXCEPTION_EXECUTE_HANDLER;
}
void func1( int i )
{
int *p = 0;
*p = i;
}
void func2( int i )
{
func1( i - 1 );
}
void func3( int i )
{
func2( i - 1 );
}
void test( int i )
{
func3( i - 1 );
}
int main()
{
__try
{
test( 10 );
}
__except( excep_filter( GetExceptionInformation() ) )
{
printf( "Some exception occures.\n" );
}
return 0;
}
以上代碼在release模式下需要關掉優化,否則調用堆棧顯示不正確(某些函數被去掉了?),同時需要pdb文件。
參考資料:
http://www.codeproject.com/KB/threads/StackWalker.aspx
http://www.cnblogs.com/protalfox/articles/84723.html
http://www.codeproject.com/KB/debug/XCrashReportPt1.aspx
http://www.codeproject.com/KB/applications/visualleakdetector.aspx
ps,本文技術淺嘗輒止,部分內容是否完全準確(正確)我個人都持保留態度,僅供參考。:D
Author : Kevin Lynx
眾多C++書籍都忠告我們C語言宏是萬惡之首,但事情總不如我們想象的那么壞,就如同goto一樣。宏有
一個很大的作用,就是自動為我們產生代碼。如果說模板可以為我們產生各種型別的代碼(型別替換),
那么宏其實可以為我們在符號上產生新的代碼(即符號替換、增加)。
關于宏的一些語法問題,可以在google上找到。相信我,你對于宏的了解絕對沒你想象的那么多。如果你
還不知道#和##,也不知道prescan,那么你肯定對宏的了解不夠。
我稍微講解下宏的一些語法問題(說語法問題似乎不妥,macro只與preprocessor有關,跟語義分析又無關):
1. 宏可以像函數一樣被定義,例如:
#define min(x,y) (x<y?x:y) //事實上這個宏存在BUG
但是在實際使用時,只有當寫上min(),必須加括號,min才會被作為宏展開,否則不做任何處理。
2. 如果宏需要參數,你可以不傳,編譯器會給你警告(宏參數不夠),但是這會導致錯誤。如C++書籍中所描
述的,編譯器(預處理器)對宏的語法檢查不夠,所以更多的檢查性工作得你自己來做。
3. 很多程序員不知道的#和##
#符號把一個符號直接轉換為字符串,例如:
#define STRING(x) #x
const char *str = STRING( test_string ); str的內容就是"test_string",也就是說#會把其后的符號
直接加上雙引號。
##符號會連接兩個符號,從而產生新的符號(詞法層次),例如:
#define SIGN( x ) INT_##x
int SIGN( 1 ); 宏被展開后將成為:int INT_1;
4. 變參宏,這個比較酷,它使得你可以定義類似的宏:
#define LOG( format, ... ) printf( format, __VA_ARGS__ )
LOG( "%s %d", str, count );
__VA_ARGS__是系統預定義宏,被自動替換為參數列表。
5. 當一個宏自己調用自己時,會發生什么?例如:
#define TEST( x ) ( x + TEST( x ) )
TEST( 1 ); 會發生什么?為了防止無限制遞歸展開,語法規定,當一個宏遇到自己時,就停止展開,也就是
說,當對TEST( 1 )進行展開時,展開過程中又發現了一個TEST,那么就將這個TEST當作一般的符號。TEST(1)
最終被展開為:1 + TEST( 1) 。
6. 宏參數的prescan,
當一個宏參數被放進宏體時,這個宏參數會首先被全部展開(有例外,見下文)。當展開后的宏參數被放進宏體時,
預處理器對新展開的宏體進行第二次掃描,并繼續展開。例如:
#define PARAM( x ) x
#define ADDPARAM( x ) INT_##x
PARAM( ADDPARAM( 1 ) );
因為ADDPARAM( 1 ) 是作為PARAM的宏參數,所以先將ADDPARAM( 1 )展開為INT_1,然后再將INT_1放進PARAM。
例外情況是,如果PARAM宏里對宏參數使用了#或##,那么宏參數不會被展開:
#define PARAM( x ) #x
#define ADDPARAM( x ) INT_##x
PARAM( ADDPARAM( 1 ) ); 將被展開為"ADDPARAM( 1 )"。
使用這么一個規則,可以創建一個很有趣的技術:打印出一個宏被展開后的樣子,這樣可以方便你分析代碼:
#define TO_STRING( x ) TO_STRING1( x )
#define TO_STRING1( x ) #x
TO_STRING首先會將x全部展開(如果x也是一個宏的話),然后再傳給TO_STRING1轉換為字符串,現在你可以這樣:
const char *str = TO_STRING( PARAM( ADDPARAM( 1 ) ) );去一探PARAM展開后的樣子。
7. 一個很重要的補充:就像我在第一點說的那樣,如果一個像函數的宏在使用時沒有出現括號,那么預處理器只是
將這個宏作為一般的符號處理(那就是不處理)。
我們來見識一下宏是如何幫助我們自動產生代碼的。如我所說,宏是在符號層次產生代碼。我在分析Boost.Function
模塊時,因為它使用了大量的宏(宏嵌套,再嵌套),導致我壓根沒看明白代碼。后來發現了一個小型的模板庫ttl,說的
是開發一些小型組件去取代部分Boost(這是一個好理由,因為Boost確實太大)。同樣,這個庫也包含了一個function庫。
這里的function也就是我之前提到的functor。ttl.function庫里為了自動產生很多類似的代碼,使用了一個宏:
#define TTL_FUNC_BUILD_FUNCTOR_CALLER(n) \
template< typename R, TTL_TPARAMS(n) > \
struct functor_caller_base##n \
///...
該宏的最終目的是:通過類似于TTL_FUNC_BUILD_FUNCTOR_CALLER(1)的調用方式,自動產生很多functor_caller_base模板:
template <typename R, typename T1> struct functor_caller_base1
template <typename R, typename T1, typename T2> struct functor_caller_base2
template <typename R, typename T1, typename T2, typename T3> struct functor_caller_base3
///...
那么,核心部分在于TTL_TPARAMS(n)這個宏,可以看出這個宏最終產生的是:
typename T1
typename T1, typename T2
typename T1, typename T2, typename T3
///...
我們不妨分析TTL_TPARAMS(n)的整個過程。分析宏主要把握我以上提到的一些要點即可。以下過程我建議你翻著ttl的代碼,
相關代碼文件:function.hpp, macro_params.hpp, macro_repeat.hpp, macro_misc.hpp, macro_counter.hpp。
so, here we go
分析過程,逐層分析,逐層展開,例如TTL_TPARAMS(1):
#define TTL_TPARAMS(n) TTL_TPARAMSX(n,T)
=> TTL_TPARAMSX( 1, T )
#define TTL_TPARAMSX(n,t) TTL_REPEAT(n, TTL_TPARAM, TTL_TPARAM_END, t)
=> TTL_REPEAT( 1, TTL_TPARAM, TTL_TPARAM_END, T )
#define TTL_TPARAM(n,t) typename t##n,
#define TTL_TPARAM_END(n,t) typename t##n
#define TTL_REPEAT(n, m, l, p) TTL_APPEND(TTL_REPEAT_, TTL_DEC(n))(m,l,p) TTL_APPEND(TTL_LAST_REPEAT_,n)(l,p)
注意,TTL_TPARAM, TTL_TPARAM_END雖然也是兩個宏,他們被作為TTL_REPEAT宏的參數,按照prescan規則,似乎應該先將
這兩個宏展開再傳給TTL_REPEAT。但是,如同我在前面重點提到的,這兩個宏是function-like macro,使用時需要加括號,
如果沒加括號,則不當作宏處理。因此,展開TTL_REPEAT時,應該為:
=> TTL_APPEND( TTL_REPEAT_, TTL_DEC(1))(TTL_TPARAM,TTL_TPARAM_END,T) TTL_APPEND( TTL_LAST_REPEAT_,1)(
TTL_TPARAM_END,T)
這個宏體看起來很復雜,仔細分析下,可以分為兩部分:
TTL_APPEND( TTL_REPEAT_, TTL_DEC(1))(TTL_TPARAM,TTL_TPARAM_END,T)以及
TTL_APPEND( TTL_LAST_REPEAT_,1)(TTL_TPARAM_END,T)
先分析第一部分:
#define TTL_APPEND( x, y ) TTL_APPEND1(x,y) //先展開x,y再將x,y連接起來
#define TTL_APPEND1( x, y ) x ## y
#define TTL_DEC(n) TTL_APPEND(TTL_CNTDEC_, n)
根據先展開參數的原則,會先展開TTL_DEC(1)
=> TTL_APPEND(TTL_CNTDEC_,1) => TTL_CNTDEC_1
#define TTL_CNTDEC_1 0 注意,TTL_CNTDEC_不是宏,TTL_CNTDEC_1是一個宏。
=> 0 , 也就是說,TTL_DEC(1)最終被展開為0。回到TTL_APPEND部分:
=> TTL_REPEAT_0 (TTL_TPARAM,TTL_TPARAM_END,T)
#define TTL_REPEAT_0(m,l,p)
TTL_REPEAT_0這個宏為空,那么,上面說的第一部分被忽略,現在只剩下第二部分:
TTL_APPEND( TTL_LAST_REPEAT_,1)(TTL_TPARAM_END,T)
=> TTL_LAST_REPEAT_1 (TTL_TPARAM_END,T) // TTL_APPEND將TTL_LAST_REPEAT_和1合并起來
#define TTL_LAST_REPEAT_1(m,p) m(1,p)
=> TTL_TPARAM_END( 1, T )
#define TTL_TPARAM_END(n,t) typename t##n
=> typename T1 展開完畢。
雖然我們分析出來了,但是這其實并不是我們想要的。我們應該從那些宏里去獲取作者關于宏的編程思想。很好地使用宏
看上去似乎是一些偏門的奇技淫巧,但是他確實可以讓我們編碼更自動化。
參考資料:
macro語法: http://developer.apple.com/documentation/DeveloperTools/gcc-4.0.1/cpp/Macros.html
ttl(tiny template library) : http://tinytl.sourceforge.net/
摘要: 作者:Kevin Lynx
需求:
開發一種組件,用以包裝C函數、通常的函數對象、成員函數,使其對外保持一種一致的接口。我將最終的組件稱為functor,這里的functor與loki中的functor以及boost中的function功能一致,同STL中的functor在概念層次上可以說也是一樣的。那么,functor其實也可以進一步傳進其他functor構成新的functor。
C++世...
閱讀全文
從SGI的STl文檔來看,STL functor(function object)模塊主要分為兩個部分:預先定義的functor
以及functor adaptors。除此之外,為了使客端程序員寫出適用于functor adaptor的functor,STL
又定義了一系列基本上只包含typedef的空類型(例如unary_function)。用戶只需要派生這些類,即
可讓自己寫的functor被functor adaptor使用。以下稱類基類型為base functor。
base functor包括: unary_function, binary_function,分別表示只有一個參數的函數和有兩個參數
的函數。實際上STL里還有一個所謂的generator,代表沒有參數的函數。因為STL泛型算法一般最多
只會使用兩個參數的函數,所以這里并沒有定義更多參數的base functor。
可被functor adaptor使用的functor又稱為adaptable function,根據參數的個數,會被命名為諸如
adaptable unary function, adaptable binary function。
一個返回值為bool的functor又被稱為predicate,可被用于functor adaptor的predicate被稱為
adaptable predicate。其實所謂的adaptable,只需要在類型內部typedef一些類型即可,一般包括
first_argument_type, second_argument_type, result_type。functor adaptor會使用這些定義。
預定義的functors都是些很簡單的functor,基本上就是封裝諸如plus, minus, equal_to之類的算術
運算,列舉一個predefined functor的代碼:
template <class _Tp>
struct plus : public binary_function<_Tp, _Tp, _Tp>
{
_Tp operator()(const _Tp& __x, const _Tp& __y) const
{
return __x + __y;
}
};
因為從binary_function(即我所謂的base functor)派生,因此這些predefined functor也是adaptable
function。
functor adaptors里有很多有趣的東西,其實functor adaptor也是一些functor(從SGI的觀點來看,一般
的C函數,函數指針都算作functor)。所不同的是,他們通常會適配(adapt)一種functor到另一種。例如:
std::binder1st,嚴格地說它是一個函數模板,它會把一個adaptable binary function轉換為一個
adaptable unary function,并綁定一個參數。又如: std::ptr_fun,它會將一個只有一個參數的C函數
適配成一個pointer_to_unary_function的functor。
下面列舉一些具體的代碼:
關于base functor,基本上就只有unary_function, binary_function :
template <class _Arg, class _Result>
struct unary_function
{
typedef _Arg argument_type;
typedef _Result result_type;
};
關于predefined functor,如之前列舉的plus一樣,再列舉一個:
template <class _Tp>
struct greater : public binary_function<_Tp, _Tp, bool>
{
bool operator()(const _Tp& __x, const _Tp& __y) const
{
return __x > __y;
}
};
關于functor adaptors,也是我覺得比較有趣的部分,多列舉幾個:
template <class _Operation, class _Tp>
inline binder1st<_Operation>
bind1st(const _Operation& __fn, const _Tp& __x)
{
typedef typename _Operation::first_argument_type _Arg1_type;
return binder1st<_Operation>(__fn, _Arg1_type(__x));
}
bind1st返回的binder1st定義為:
template <class _Operation>
class binder1st : public unary_function<typename _Operation::second_argument_type,
typename _Operation::result_type>
{
protected:
_Operation op;
typename _Operation::first_argument_type value;
public:
binder1st(const _Operation& __x, const typename _Operation::first_argument_type& __y):
op(__x), value(__y)
{}
typename _Operation::result_type
operator()(const typename _Operation::second_argument_type& __x) const
{
return op(value, __x);
}
typename _Operation::result_type
operator()(typename _Operation::second_argument_type& __x) const
{
return op(value, __x);
}
};
值得一提的是,ptr_fun以及相關的pointer_to_unary_function, pointer_to_binary_function,基本上
就是用來綁定C函數的組件,不過這里采用了很基礎的模板技術,因此只實現了綁定一個參數和兩個參數
的C函數。這種組件類似于loki中的functor,以及boost中的bind,只是功能弱很多。與之相關的還有
mem_fun, mem_fun_ref, mem_fun1, mem_fun1_ref等,這些都是用于綁定成員函數的。另一方面,與其說
是綁定,還不如說適配,即將函數適配為functor(特指重載operator()的類)。( Mem_fun_t is an adaptor
for member functions )采用這些(ptr_fun, mem_fun之類的東西)組件,客端程序員可以很容易地將各種
運行體(Kevin似乎很喜歡發明各種名字)(C函數、成員函數)適配成functor,從而與STL泛型算法結合。
例如, SGI文檔中給出的mem_fun例子:
struct B {
virtual void print() = 0;
};
struct D1 : public B {
void print() { cout << "I'm a D1" << endl; }
};
struct D2 : public B {
void print() { cout << "I'm a D2" << endl; }
};
int main()
{
vector<B*> V;
V.push_back(new D1);
V.push_back(new D2);
V.push_back(new D2);
V.push_back(new D1);
for_each(V.begin(), V.end(), mem_fun(&B::print));
}
注:以上分析基于dev-cpp中自帶的stl,源代碼見stl_functional.h。