之前在公叔R���l�护了一个名字服务,�q�个名字服务日常���理了近4000台机器,�?000个左右的客户端连接上来获取机器信息,�׃��其基本是一个单�Ҏ��务,所以某些模块接�q�瓶颈。后来倒是有重构计划,详细设计做了�Q�代码都写了一部分�Q�结果由于某些原因重构就被终止了�?/p>
JCM是我业余旉���用Java重写的一个版本,功能上目前只实现了基���功能。由于它是个完全分布式的架构�Q�所以理��Z��可以横向扩展�Q�大大增强系�l�的服务能力�?/p>
名字服务
在分布式�pȝ��中,某个服务��Z��提升整体服务能力�Q�通常部��v了很多实例。这里我把这些提供相同服务的实例�l�称为集��?cluster)�Q�每个实例称��Z��个节�?Node)。一个应用可能会使用很多cluster�Q�每�ơ访问一个cluster�Ӟ�����通过名字服务获取该cluster下一个可用的node。那么,名字服务臛_��需要包含的功能�Q?/p>
- �Ҏ��cluster名字获取可用的node
- 对管理的所有cluster下的所有node�q�行健康度的������,以保证始�l�返回可用的node
有些名字服务仅对node���理�Q�不参与应用与node间的通信�Q�而有些则可能作�ؓ应用与node间的通信转发器。虽然名字服务功能简单,但是要做一个分布式的名字服务还是比较复杂的�Q�因为数据一旦分布式了,��׃��存在同步、一致性问题的考虑�{��?/p>
What’s JCM
JCM围绕前面说的名字服务基础功能实现。包含的功能�Q?/p>
- ���理cluster到node的映��?/li>
- 分布式架构,可水�q�x��展以实现���理10,000个node的能力,���以���理一般公司的后台服务集群
- �Ҏ��个node�q�行健康���查,健康���查可��Z��HTTP协议层的������或TCP�q�接�����?/li>
- 持久化cluster/node数据�Q�通过zookeeper保证数据一致�?/li>
- 提供JSON HTTP API���理cluster/node数据�Q�后�l�可提供Web���理�pȝ��
- 以库的�Ş式提供与server的交互,库本�w�提供各�U�负载均衡策略,保证对一个cluster下node的访问达到负载均�?/li>
��目地址git jcm
JCM主要包含两部分:
- jcm.server�Q�JCM名字服务�Q�需要连接zookeeper以持久化数据
- jcm.subscriber�Q�客��L��库,负责与jcm.server交互�Q�提供包装了负蝲均衡的API�l�应用���?/li>
架构
��Z��JCM的系�l�整体架构如下:
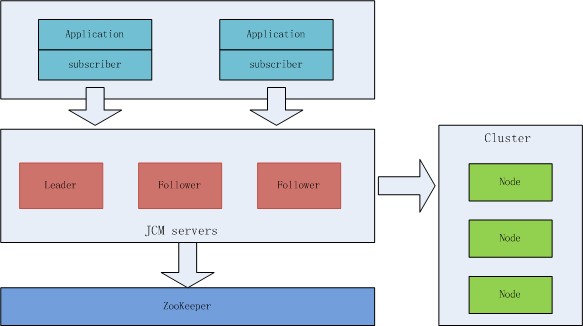
cluster本��n是不需要依赖JCM的,要通过JCM使用�q�些cluster�Q�只需要通过JCM HTTP API注册�q�些cluster到jcm.server上。要通过jcm.server使用�q�些cluster�Q�则是通过jcm.subscriber来完成�?/p>
使用
可参�?a >git READMe.md
需要jre1.7+
- 启动zookeeper
- 下蝲jcm.server git jcm.server-0.1.0.jar
- �?code>jcm.server-0.1.0.jar目录下徏�?code>config/application.properties文�g�q�行配置�Q�参�?a >config/application.properties
-
启动jcm.server
java -jar jcm.server-0.1.0.jar -
注册需要管理的集群�Q�参考cluster描述�Q?a >doc/cluster_sample.json�Q�通过HTTP API注册�Q?/p>
curl -i -X POST http://10.181.97.106:8080/c -H "Content-Type:application/json" --data-binary @./doc/cluster_sample.json
部��v好了jcm.server�Q��ƈ注册了cluster后,���可以通过jcm.subscriber使用�Q?/p>
// 传入需要��用的集群名hello9/hello�Q�以及传入jcm.server地址�Q�可以多个:127.0.0.1:8080
Subscriber subscriber = new Subscriber( Arrays.asList("127.0.0.1:8080"), Arrays.asList("hello9", "hello"));
// 使用轮询负蝲均衡�{�略
RRAllocator rr = new RRAllocator();
subscriber.addListener(rr);
subscriber.startup();
for (int i = 0; i < 2; ++i) {
// rr.alloc �Ҏ��cluster名字获取可用的node
System.out.println(rr.alloc("hello9", ProtoType.HTTP));
}
subscriber.shutdown();JCM实现
JCM目前的实现比较简单,参考模块图�Q?/p>
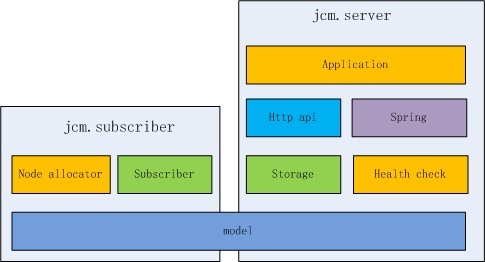
- model�Q�即cluster/node�q�些数据�l�构的描�q�ͼ�同时被jcm.server和jcm.subscriber依赖
- storage�Q�持久化数据到zookeeper�Q�同时包含jcm.server实例之间的数据同�?/li>
- health check�Q�健��h��查模块,对各个node�q�行健康����?/li>
以上模块都不依赖Spring�Q�基于以上模块又有:
- http api�Q���用spring-mvc�Q�包装了一些JSON HTTP API
- Application�Q�基于spring-boot�Q�将各个基础模块�l�装��h���Q�提供standalone的模式启动,不用部��v到tomcat之类的servlet容器�?/li>
jcm.subscriber的实现更���单,主要是负责与jcm.server�q�行通信�Q�以更新自己当前的model层数据,同时提供各种负蝲均衡�{�略接口�Q?/p>
- subscriber�Q�与jcm.server通信�Q�定期增量拉取数�?/li>
- node allocator�Q�通过listener方式从subscriber中获取数据,同时实现各种负蝲均衡�{�略�Q�对外统一提供
alloc node的接�?/li>
接下来看看关键功能的实现
数据同步
既然jcm.server是分布式的,每一个jcm.server instance(实例)都是支持数据��d��写的�Q�那么当jcm.server���理着一堆cluster上万个node�Ӟ��每一个instance是如何进行数据同步的�Q�jcm.server中的数据主要有两�c�:
- cluster本��n的数据,包括cluster/node的描�q�ͼ�例如cluster name、node IP、及其他附属数据
- node健康���查的数据
对于cluster数据�Q�因为cluster对node的管理是一个两层的树状�l�构�Q�而对cluster有增删node的操作,所以�ƈ不能在每一个instance上都提供真正的数据写入,�q�样会导致数据丢失。假讑�一时刻在instance A和instance B上同时对cluster c1��d��节点N1和N2�Q�那么instance A写入c1(N1)�Q�而instance B�q�没�{�到数据同步���写入c1(N2)�Q�那么c1(N1)���p��覆盖为c1(N2)�Q�从而导致添加的节点N1丢失�?/p>
所以,jcm.server instance是分�?code>leader�?code>follower的,真正的写入操作只有leader�q�行�Q�follower收到写操作请求时转发�l�leader。leader写数据优先更新内存中的数据再写入zookeeper�Q�内存中的数据更新当然是需要加锁互斥的�Q�从而保证数据的正确性�?/p>
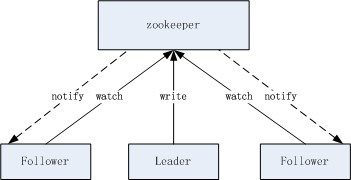
leader和follower是如何确定角色的�Q�这个很���单,标准的利用zookeeper来进行主�?a >选�D的实�?/a>�?/p>
jcm.server instance数据间的同步是基于zookeeper watch机制的。这个可以算做是一个JCM的一个瓶颈,每一个instance都会作�ؓ一个watch�Q���得实际上jcm.server�q�不能无限水�q�x��展,扩展��C��定程度后�Q�watch的效率就可能不��以满���x��能了,参�?a >zookeeper节点��C��watch的性能���试 (那个时候我���在考虑�Ҏ��们系�l�的重构�? �?/p>
jcm.server中对node健康���查的数据采用同样的同步机�Ӟ��但node健康���查数据是每一个instance都会写入的,下面看看jcm.server是如何通过分布式架构来分担压力的�?/p>
健康����?/h3>
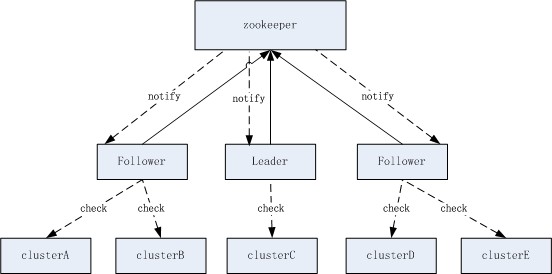
jcm.server的另一个主要功能的是对node的健��h��查,jcm.server集群可以���理几万的node�Q�既然已�l�是分布式了�Q�那么显然是要把node均分到多个instance的。这里我是以cluster来分配的�Q�方法就是简单的使用一致性哈希。通过一致性哈希,军_��一个cluster是否属于某个instance负责。每个instance都有一个server spec�Q�也���是该instance对外提供服务的地址(IP+port)�Q�这样在��M��一个instance上,它看到的所有instance server spec都是相同的,从而保证在每一个instance上计���cluster的分配得到的�l�果都是一致的�?/p>
健康���查按cluster划分�Q�可以简化数据的写冲�H�问题,在正常情况下�Q�每个instance写入的健��h��查结果都是不同的�?/p>
健康���查一般以1�U�的频率�q�行�Q�jcm.server做了优化�Q�当���查结果和上一�ơ一��h���Q��ƈ不写入zookeeper。写入的数据包含了node的完整key (IP+Port+Spec)�Q�这样可以简化很多地方的数据同步问题�Q�但会增加写入数据的大小�Q�写入数据的大小是会影响zookeeper的性能的,所以这里简单地�Ҏ��据进行了压羃�?/p>
健康���查是可以支持多种���查实现的�Q�目前只实现了HTTP协议层的���查。健��h��查自�w�是单个�U�程�Q�在该线�E�中��Z��异步HTTP库,发�v异步��h���Q�实际的��h��在其他线�E�中发出�?/p>
jcm.subscriber通信
jcm.subscriber与jcm.server通信�Q�主要是��Z��获取最新的cluster数据。subscriber初始化时会拿��C��个jcm.server instance的地址列表�Q�访问时使用轮询�{�略以��^衡jcm.server在处理请求时的负载。subscriber每秒都会��h��一�ơ数据,��h��中描�q�C��本次��h��惌���取哪些cluster数据�Q�同时携带一个cluster的version。每�ơcluster在server变更�Ӟ��version���变��_��旉���戻I��。server回复��h���Ӟ��如果version已最斎ͼ�只需要回复node的状态�?/p>
subscriber可以拿到所有状态的node�Q�后面可以考虑只拿正常状态的node�Q�进一步减���数据大����?/p>
压力���试
目前只对健康���查部分做了压���,详细参�?a >test/benchmark.md。在A7服务器上���试�Q�发现写zookeeper及zookeeper的watch���以满��要求�Q�jcm.server发�v的HTTP��h��是主要的性能热点�Q�单jcm.server instance大概可以承蝲20000个node的健��L������?/p>
�|�络带宽�Q?/p>
1 2 3 4 5 |
|
CPU�Q�通过jstack查看主要的CPU消耗在HTTP库实现层�Q�以及健��h��查线�E�:
1 2 3 4 |
|
代码中增加了些状态监控:
1
|
|
表示�q�_��每次���查耗时542毫秒�Q�写数据因�ؓ开启了cache没有参考�h倹{�?/p>
虽然�q�可以从我自��q��代码中做不少优化�Q�但既然单机可以承蝲20000个节点的������,一般的应用�q�远���_��了�?/p>
�ȝ��
名字服务在分布式�pȝ��中虽然是基础服务�Q�但往往承担了非帔R��要的角色�Q�数据同步出现错误、节点状态出现瞬时的错误�Q�都可能�Ҏ��套系�l�造成较大影响�Q�业务上出现较大故障。所以名字服务的健壮性、可用性非帔R��要。实��C��需要考虑很多异常情况�Q�包括网�l�不�E�_��、应用层的错误等。�ؓ了提高��够的可用性,一般还会加多层的数据cache�Q�例如subscriber端的本地cache�Q�server端的本地cache�Q�以保证在�Q何情况下都不会媄响应用层的服务�?/p>
接上��?a >使用RCU技术实现读写线�E�无�?/a>�Q�在没有GC机制的语�a�中,要实现Lock free的算法,���免不了要自己处理内存回收的问题�?/p>
Hazard Pointer是另一�U�处理这个问题的���法�Q�而且相比��h��不但���单,功能也很强大�?a >锁无关的数据�l�构与Hazard指针中讲得很好,Wikipedia Hazard pointer也描�q�得比较清楚�Q�所以我�q�里��׃��讲那么细了�?/p>
一个简单的实现可以参�?a >我的github haz_ptr.c
原理
基本原理无非也是�ȝ���E�对指针�q�行标识�Q�指�?指向的内�?要释放时都会�~�存��h��延迟到确认没有读�U�程了才对其真正释放�?/p>
<Lock-Free Data Structures with Hazard Pointers>中的描述�Q?/p>
Each reader thread owns a single-writer/multi-reader shared pointer called “hazard pointer.” When a reader thread assigns the address of a map to its hazard pointer, it is basically announcing to other threads (writers), “I am reading this map. You can replace it if you want, but don’t change its contents and certainly keep your deleteing hands off it.”
关键的结构包括:Hazard pointer�?code>Thread Free list
Hazard pointer�Q�一个读�U�程要��用一个指针时�Q�就会创��Z��个Hazard pointer包装�q�个指针。一个Hazard pointer会被一个线�E�写�Q�多个线�E�读�?/p>
struct HazardPointer {
void *real_ptr; // 包装的指�?/span>
... // 不同的实现有不同的成�?/span>
};
void func() {
HazardPointer *hp = accquire(_real_ptr);
... // use _real_ptr
release(hp);
}Thread Free List�Q�每个线�E�都有一个这��L��列表�Q�保存着���要释放的指针列表,�q�个列表仅对应的�U�程��d��
void defer_free(void *ptr) {
_free_list.push_back(ptr);
}当某个线�E�要���试释放Free List中的指针�Ӟ��例如指针ptr�Q�就���查所有其他线�E���用的Hazard pointer�Q�检查是否存在包装了ptr的Hazard pointer�Q�如果没有则说明没有�ȝ���E�正在���?code>ptr�Q�可以安全释�?code>ptr�?/p>
void gc() {
for(ptr in _free_list) {
conflict = false
for (hp in _all_hazard_pointers) {
if (hp->_real_ptr == ptr) {
confilict = true
break
}
}
if (!conflict)
delete ptr
}
}以上�Q�其实就�?code>Hazard Pointer的主要内宏V�?/p>
Hazard Pointer的管�?/h2>
上面的代码中没有提到_all_hazard_pointers�?code>accquire的具体实玎ͼ��q�就是Hazard Pointer的管理问题�?/p>
《锁无关的数据结构与Hazard指针》文中创��Z��一个Lock free的链表来表示�q�个全局的Hazard Pointer List。每个Hazard Pointer有一个成员标识其是否可用。这个List中也��׃��存了已经被��用的Hazard Pointer集合和未被��用的Hazard Pointer集合�Q�当所有Hazard Pointer都被使用�Ӟ����׃��新分配一个加�q�这个List。当�ȝ���E�不使用指针�Ӟ��需要归�q�Hazard Pointer�Q�直接设�|�可用成员标识即可。要gc()�Ӟ�����q��接遍历这个List�?/p>
要实��C��个Lock free的链表,�q�且仅需要实现头插入�Q�还是非常简单的。本�w�Hazard Pointer标识某个指针�Ӟ��都是用了后立��x��识,所以这个实现直接支持了动态线�E�,支持�U�程的挂��L���?/p>
�?a >nbds��目中也有一个Hazard Pointer的实玎ͼ�相对要弱一炏V��它为每个线�E�都讄���了自��q��Hazard Pointer池,写线�E�要释放指针�Ӟ�����p��问所有其他线�E�的Hazard Pointer池�?/p>
typedef struct haz_local {
// Free List
pending_t *pending; // to be freed
int pending_size;
int pending_count;
// Hazard Pointer 池,动态和静态两�U?/span>
haz_t static_haz[STATIC_HAZ_PER_THREAD];
haz_t **dynamic;
int dynamic_size;
int dynamic_count;
} __attribute__ ((aligned(CACHE_LINE_SIZE))) haz_local_t;
static haz_local_t haz_local_[MAX_NUM_THREADS] = {};每个�U�程当然���涉及到 最后,附上一些�ƈ行编�E�中的一些概��c�?/p>
常常看到haz_local_索引(ID)的分配,���像使用RCU技术实现读写线�E�无�?/a>中的一栗���这个实��Cؓ了支持线�E�动态创建,���需要一套线�E�ID的重用机�Ӟ��相对复杂多了�?/p>
附录
Lock Free & Wait Free
Lock Free�?code>Wait Free的概念,�q�些概念用于衡量一个系�l�或者说一�D�代码的�q�行�U�别�Q��ƈ行��别可参�?a >�q�行�~�程——�q�发�U�别
我自��q��理解�Q�例如《锁无关的数据结构与Hazard指针》中实现的Hazard Pointer链表���可以说是Lock Free的,注意它在插入新元素到链表头时�Q�因��Z���?code>CAS�Q���d��不了一个busy loop�Q�有�q�个特征的情况下���q���?code>Lock Free�Q�虽然没锁,但某个线�E�的执行情况也受其他�U�程的媄响�?/p>
相对而言�Q?code>Wait Free则是每个�U�程的执行都是独立的�Q�例如《锁无关的数据结构与Hazard指针》中�?code>Scan函数�?code>“每个�U�程的执行时间都不依赖于其它��M���U�程的行�?#8221;
锁无�?Lock-Free)意味着�pȝ��中��d��在某个线�E�能够得以���l�执行;而等待无�?Wait-Free)则是一个更强的条�g�Q�它意味着所有线�E�都能往下进行�?/p>
ABA问题
在实�?code>Lock Free���法的过�E�中�Q���L��要���?code>CAS原语的,�?code>CAS��׃��带来ABA问题�?/p>
在进行CAS操作的时候,因�ؓ在更改V之前�Q�CAS主要询问“V的值是否仍然�ؓA”�Q�所以在�W�一�ơ读取V之后以及对V执行CAS操作之前�Q�如果将��g��A改�ؓB�Q�然后再改回A�Q�会使基于CAS的算法�乱。在�q�种情况下,CAS操作会成功。这�c�问题称为ABA问题�?/p>
Wiki Hazard Pointer提到了一个ABA问题的好例子�Q�在一个Lock free的栈实现中,现在要出栈,栈里的元素是[A, B, C]�Q?code>head指向栈顶�Q�那么就�?code>compare_and_swap(target=&head, newvalue=B, expected=A)。但是在�q�个操作中,其他�U�程�?code>A B都出栈,且删除了B�Q�又�?code>A压入栈中�Q�即[A, C]。那么前一个线�E�的compare_and_swap能够成功�Q�此�?code>head指向了一个已�l�被删除�?code>B。stackoverflow上也有个例子 Real-world examples for ABA in multithreading
对于CAS产生的这个ABA问题�Q�通常的解��x��案是采用CAS的一个变�U�DCAS。DCAS�Q�是对于每一个V增加一个引用的表示修改�ơ数的标记符。对于每个V�Q�如果引用修改了一�ơ,�q�个计数器就�?。然后再�q�个变量需要update的时候,���同时检查变量的值和计数器的倹{�?/p>
但也早有人提�?code>DCAS也不�?a >ABA problem 的银�?/a>�?/p>
现象
�U�上的服务出现coredump�Q�堆栈�ؓ�Q?/p>
#0 0x000000000045d145 in GetStackTrace(void**, int, int) ()
#1 0x000000000045ec22 in tcmalloc::PageHeap::GrowHeap(unsigned long) ()
#2 0x000000000045eeb3 in tcmalloc::PageHeap::New(unsigned long) ()
#3 0x0000000000459ee8 in tcmalloc::CentralFreeList::Populate() ()
#4 0x000000000045a088 in tcmalloc::CentralFreeList::FetchFromSpansSafe() ()
#5 0x000000000045a10a in tcmalloc::CentralFreeList::RemoveRange(void**, void**, int) ()
#6 0x000000000045c282 in tcmalloc::ThreadCache::FetchFromCentralCache(unsigned long, unsigned long) ()
#7 0x0000000000470766 in tc_malloc ()
#8 0x00007f75532cd4c2 in __conhash_get_rbnode (node=0x22c86870, hash=30)
at build/release64/cm_sub/conhash/conhash_inter.c:88
#9 0x00007f75532cd76e in __conhash_add_replicas (conhash=0x24fbc7e0, iden=<value optimized out>)
at build/release64/cm_sub/conhash/conhash_inter.c:45
#10 0x00007f75532cd1fa in conhash_add_node (conhash=0x24fbc7e0, iden=0) at build/release64/cm_sub/conhash/conhash.c:72
#11 0x00007f75532c651b in cm_sub::TopoCluster::initLBPolicyInfo (this=0x2593a400)
at build/release64/cm_sub/topo_cluster.cpp:114
#12 0x00007f75532cad73 in cm_sub::TopoClusterManager::processClusterMapTable (this=0xa219e0, ref=0x267ea8c0)
at build/release64/cm_sub/topo_cluster_manager.cpp:396
#13 0x00007f75532c5a93 in cm_sub::SubRespMsgProcess::reinitCluster (this=0x9c2f00, msg=0x4e738ed0)
at build/release64/cm_sub/sub_resp_msg_process.cpp:157
...
查看了应用层相关数据�l�构�Q�基本数据都是没有问题的。所以最初怀疑是tcmalloc内部�l�护了错误的内存�Q�在分配内存时出错,�q�个堆栈只是问题的表象。几天后�Q�线上的另一个服务,��Z��同样的库�Q�也core了,堆栈�q�是一��L���?/p>
最初定位问题都是从最�q�更新的东西入手�Q�包括依赖的server环境�Q�但都没有明昄���问题�Q�所以最后只能从core的直接原因入手�?/p>
分析GetStackTrace
���认core的详�l�位�|�:
# core在该指��o
0x000000000045d145 <_Z13GetStackTracePPvii+21>: mov 0x8(%rax),%r9
(gdb) p/x $rip # core 的指令位�|?
$9 = 0x45d145
(gdb) p/x $rax
$10 = 0x4e73aa58
(gdb) x/1a $rax+0x8 # rax + 8 = 0x4e73aa60
0x4e73aa60: 0x0
该指令尝试从[0x4e73aa60]处读取内容,然后出错�Q�这个内存单元不可读。但是具体这个指令在代码中是什么意思,需要将�q�个指��o对应��C��码中。获取tcmalloc的源码,发现GetStackTrace�Ҏ���~�译选项有很多实玎ͼ�所以这里选择最可能的实玎ͼ�然后�Ҏ��汇编以确认代码是否匹配。最初选择的是stacktrace_x86-64-inl.h�Q�后来发现完全不匚w���Q�又选择�?code>stacktrace_x86-inl.h。这个实现版本里也有�?4位��^台的支持�?/p>
stacktrace_x86-inl.h里��用了一些宏来生成函数名和参敎ͼ��_����后代码大概�ؓ�Q?/p>
int GET_STACK_TRACE_OR_FRAMES {
void **sp;
unsigned long rbp;
__asm__ volatile ("mov %%rbp, %0" : "=r" (rbp));
sp = (void **) rbp;
int n = 0;
while (sp && n < max_depth) {
if (*(sp+1) == reinterpret_cast<void *>(0)) {
break;
}
void **next_sp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(sp, ucp);
if (skip_count > 0) {
skip_count--;
} else {
result[n] = *(sp+1);
n++;
}
sp = next_sp;
}
return n;
}NextStackFrame是一个模板函敎ͼ�包含一大堆代码�Q�精���后非常简单:
template<bool STRICT_UNWINDING, bool WITH_CONTEXT>
static void **NextStackFrame(void **old_sp, const void *uc) {
void **new_sp = (void **) *old_sp;
if (STRICT_UNWINDING) {
if (new_sp <= old_sp) return NULL;
if ((uintptr_t)new_sp - (uintptr_t)old_sp > 100000) return NULL;
} else {
if (new_sp == old_sp) return NULL;
if ((new_sp > old_sp)
&& ((uintptr_t)new_sp - (uintptr_t)old_sp > 1000000)) return NULL;
}
if ((uintptr_t)new_sp & (sizeof(void *) - 1)) return NULL;
return new_sp;
}上面�q�个代码到汇�~�的�Ҏ���q�程�q�是�׃��些时��_��其中汇编中出现的一些常量可以大大羃短对比时��_��例如上面出现�?code>100000�Q�汇�~�中���有�Q?/p>
0x000000000045d176 <_Z13GetStackTracePPvii+70>: cmp $0x186a0,%rbx # 100000=0x186a0
注意NextStackFrame中的 if (STRICT_UNWINDING)使用的是模板参数�Q�这��D��生成的代码中�Ҏ��没有else部分�Q�也���没�?code>1000000�q�个帔R��
在对比代码的�q�程中,可以知道关键的几个寄存器、内存位�|�对应到代码中的变量�Q�从而可以还原core时的现场环境。分析过�E�中不一定要从第一行汇�~�读�Q�可以从较明昄���位置读,从而还原整个代码,函数�q�回指��o、蟩转指令、比较指令、读内存指��o、参数寄存器�{�都是比较明昑֯�应的地方�?/p>
另外注意GetStackTrace�?code>RecordGrowth中调用,传入�?个参敎ͼ�
GetStackTrace(t->stack, kMaxStackDepth-1, 3); // kMaxStackDepth = 31
以下是我分析的简单注解:
(gdb) disassemble
Dump of assembler code for function _Z13GetStackTracePPvii:
0x000000000045d130 <_Z13GetStackTracePPvii+0>: push %rbp
0x000000000045d131 <_Z13GetStackTracePPvii+1>: mov %rsp,%rbp
0x000000000045d134 <_Z13GetStackTracePPvii+4>: push %rbx
0x000000000045d135 <_Z13GetStackTracePPvii+5>: mov %rbp,%rax
0x000000000045d138 <_Z13GetStackTracePPvii+8>: xor %r8d,%r8d
0x000000000045d13b <_Z13GetStackTracePPvii+11>: test %rax,%rax
0x000000000045d13e <_Z13GetStackTracePPvii+14>: je 0x45d167 <_Z13GetStackTracePPvii+55>
0x000000000045d140 <_Z13GetStackTracePPvii+16>: cmp %esi,%r8d # while ( .. max_depth > n ?
0x000000000045d143 <_Z13GetStackTracePPvii+19>: jge 0x45d167 <_Z13GetStackTracePPvii+55>
0x000000000045d145 <_Z13GetStackTracePPvii+21>: mov 0x8(%rax),%r9 # 关键位置�Q?(sp+1) -> r9, rax 对应 sp变量
0x000000000045d149 <_Z13GetStackTracePPvii+25>: test %r9,%r9 # *(sp+1) == 0 ?
0x000000000045d14c <_Z13GetStackTracePPvii+28>: je 0x45d167 <_Z13GetStackTracePPvii+55>
0x000000000045d14e <_Z13GetStackTracePPvii+30>: mov (%rax),%rcx # new_sp = *old_sp�Q�这里已�l�是NextStackFrame的代�?
0x000000000045d151 <_Z13GetStackTracePPvii+33>: cmp %rcx,%rax # new_sp <= old_sp ?
0x000000000045d154 <_Z13GetStackTracePPvii+36>: jb 0x45d170 <_Z13GetStackTracePPvii+64> # new_sp > old_sp 跌��{
0x000000000045d156 <_Z13GetStackTracePPvii+38>: xor %ecx,%ecx
0x000000000045d158 <_Z13GetStackTracePPvii+40>: test %edx,%edx # skip_count > 0 ?
0x000000000045d15a <_Z13GetStackTracePPvii+42>: jle 0x45d186 <_Z13GetStackTracePPvii+86>
0x000000000045d15c <_Z13GetStackTracePPvii+44>: sub $0x1,%edx # skip_count--
0x000000000045d15f <_Z13GetStackTracePPvii+47>: mov %rcx,%rax
0x000000000045d162 <_Z13GetStackTracePPvii+50>: test %rax,%rax # while (sp ?
0x000000000045d165 <_Z13GetStackTracePPvii+53>: jne 0x45d140 <_Z13GetStackTracePPvii+16>
0x000000000045d167 <_Z13GetStackTracePPvii+55>: pop %rbx
0x000000000045d168 <_Z13GetStackTracePPvii+56>: leaveq
0x000000000045d169 <_Z13GetStackTracePPvii+57>: mov %r8d,%eax # r8 存储了返回��|��r8=n
0x000000000045d16c <_Z13GetStackTracePPvii+60>: retq # return n
0x000000000045d16d <_Z13GetStackTracePPvii+61>: nopl (%rax)
0x000000000045d170 <_Z13GetStackTracePPvii+64>: mov %rcx,%rbx
0x000000000045d173 <_Z13GetStackTracePPvii+67>: sub %rax,%rbx # offset = new_sp - old_sp
0x000000000045d176 <_Z13GetStackTracePPvii+70>: cmp $0x186a0,%rbx # offset > 100000 ?
0x000000000045d17d <_Z13GetStackTracePPvii+77>: ja 0x45d156 <_Z13GetStackTracePPvii+38> # return NULL
0x000000000045d17f <_Z13GetStackTracePPvii+79>: test $0x7,%cl # new_sp & (sizeof(void*) - 1)
0x000000000045d182 <_Z13GetStackTracePPvii+82>: je 0x45d158 <_Z13GetStackTracePPvii+40>
0x000000000045d184 <_Z13GetStackTracePPvii+84>: jmp 0x45d156 <_Z13GetStackTracePPvii+38>
0x000000000045d186 <_Z13GetStackTracePPvii+86>: movslq %r8d,%rax # rax = n
0x000000000045d189 <_Z13GetStackTracePPvii+89>: add $0x1,%r8d # n++
0x000000000045d18d <_Z13GetStackTracePPvii+93>: mov %r9,(%rdi,%rax,8)# 关键位置�Q�result[n] = *(sp+1)
0x000000000045d191 <_Z13GetStackTracePPvii+97>: jmp 0x45d15f <_Z13GetStackTracePPvii+47>
分析�q�程比较耗时�Q�同时还可以分析�?code>GetStackTrace函数的实现原理,其实���是利用RBP寄存器不断回溯,从而得到整个调用堆栈各个函数的地址�Q�严格来说是�q�回地址�Q�。简单示意下函数调用中RBP的情况:
...
saved registers # i.e push rbx
local variabes # i.e sub 0x10, rsp
return address # call xxx
last func RBP # push rbp; mov rsp, rbp
saved registers
local variables
return address
last func RBP
... # rsp
��M���Q?strong>一般情况下�Q��Q何一个函��C���Q�RBP寄存器指向了当前函数的栈基址�Q�该栈基址中又存储了调用者的栈基址�Q�同时该栈基址前面�q�存储了调用者的�q�回地址。所以,GetStackTrace的实玎ͼ����单来说大概就是:
sp = rbp // 取得当前函数GetStackTrace的栈基址
while (n < max_depth) {
new_sp = *sp
result[n] = *(new_sp+1)
n++
}以上�Q�最�l�就知道了以下关键信息:
- r8 对应变量 n�Q�表�C�当前取到第几个栈���?/li>
- rax 对应变量 sp�Q�代码core�?*(sp+1)
- rdi 对应变量 result�Q�用于存储取得的各个地址
然后可以看看现场是怎样的:
(gdb) x/10a $rdi
0x1ffc9b98: 0x45a088 <_ZN8tcmalloc15CentralFreeList18FetchFromSpansSafeEv+40> 0x45a10a <_ZN8tcmalloc15CentralFreeList11RemoveRangeEPPvS2_i+106>
0x1ffc9ba8: 0x45c282 <_ZN8tcmalloc11ThreadCache21FetchFromCentralCacheEmm+114> 0x470766 <tc_malloc+790>
0x1ffc9bb8: 0x7f75532cd4c2 <__conhash_get_rbnode+34> 0x0
0x1ffc9bc8: 0x0 0x0
0x1ffc9bd8: 0x0 0x0
(gdb) p/x $r8
$3 = 0x5
(gdb) p/x $rax
$4 = 0x4e73aa58
���结�Q?/strong>
GetStackTrace在取调用__conhash_get_rbnode的函数时出错�Q�取得了5个函数地址。当前��用的RBP�?code>0x4e73aa58�?/p>
错误的RBP
RBP也是从堆栈中取出来的�Q�既然这个地址有问题,首先惛_��的就是有代码局部变�?数组写越界。例�?code>sprintf的��用。而且�Q?strong>一般写���界破坏堆栈�Q�都可能是把调用者的堆栈破坏�?/strong>�Q�例如:
char s[32];
memcpy(s, p, 1024);
因�ؓ写入都是从低地址往高地址写,而调用者的堆栈在高地址。当�Ӟ��也会遇到写坏调用者的调用者的堆栈�Q�也���是跨栈帧越界写�Q�例如以前遇到的�Q?/p>
len = vsnprintf(buf, sizeof(buf), fmt, wtf-long-string);
buf[len] = 0;
__conhash_get_rbnode的RBP是在tcmalloc的堆栈中取的�Q?/p>
(gdb) f 7
#7 0x0000000000470766 in tc_malloc ()
(gdb) x/10a $rsp
0x4e738b80: 0x4e73aa58 0x22c86870
0x4e738b90: 0x4e738bd0 0x85
0x4e738ba0: 0x4e73aa58 0x7f75532cd4c2 <__conhash_get_rbnode+34> # 0x4e73aa58
所以这里就会怀疑是tcmalloc�q�个函数里有把堆栈破坏,�q�个时候就是读代码�Q�看看有没有疑似危险的地方,未果。这里就陷入了僵局�Q�怀疑又遇到了跨栈��破坏的情况,�q�个时候就只能__conhash_get_rbnode调用栈中周围的函数翻���,例如调用__conhash_get_rbnode的函�?code>__conhash_add_replicas中恰好有字符串操作:
void __conhash_add_replicas(conhash_t *conhash, int32_t iden)
{
node_t* node = __conhash_create_node(iden, conhash->replica);
...
char buf[buf_len]; // buf_len = 64
...
snprintf(buf, buf_len, VIRT_NODE_HASH_FMT, node->iden, i);
uint32_t hash = conhash->cb_hashfunc(buf);
if(util_rbtree_search(&(conhash->vnode_tree), hash) == NULL)
{
util_rbtree_node_t* rbnode = __conhash_get_rbnode(node, hash);
...�q�段代码最�l�发现是没有问题的,�q�里又耗费了不���时间。后来发现若�q�个函数里的RBP都有点奇怪,�q�个调用栈比较正常的范围是:0x4e738c90
(gdb) f 8
#8 0x00007f75532cd4c2 in __conhash_get_rbnode (node=0x22c86870, hash=30)
(gdb) p/x $rbp
$6 = 0x4e73aa58 # �q�个�q�不���特别可�?
(gdb) f 9
#9 0x00007f75532cd76e in __conhash_add_replicas (conhash=0x24fbc7e0, iden=<value optimized out>)
(gdb) p/x $rbp
$7 = 0x4e738c60 # �q�个也不���特别可�?
(gdb) f 10
#10 0x00007f75532cd1fa in conhash_add_node (conhash=0x24fbc7e0, iden=0) at build/release64/cm_sub/conhash/conhash.c:72
(gdb) p/x $rbp # 可疑
$8 = 0x0
(gdb) f 11
#11 0x00007f75532c651b in cm_sub::TopoCluster::initLBPolicyInfo (this=0x2593a400)
(gdb) p/x $rbp # 可疑
$9 = 0x2598fef0
��Z��么很多函��C��RBP都看��h��不正常? 想了想真要是代码里把堆栈破坏了,�q�错误得发生得多巧妙�Q?/p>
错误RBP的来�?/h2>
然后转机来了�Q�脑���中�H�然闪出-fomit-frame-pointer。编译器生成的代码中是可以不需要栈基址指针的,也就是RBP寄存器不作�ؓ栈基址寄存器。大部分函数或者说开启了frame-pointer的函敎ͼ�其函数头都会有以下指令:
push %rbp
mov %rsp,%rbp
...
表示保存调用者的栈基址到栈中,以及讄���自己的栈基址。看�?code>__conhash�p�d��函数�Q?/p>
Dump of assembler code for function __conhash_get_rbnode:
0x00007f75532cd4a0 <__conhash_get_rbnode+0>: mov %rbx,-0x18(%rsp)
0x00007f75532cd4a5 <__conhash_get_rbnode+5>: mov %rbp,-0x10(%rsp)
...
�q�个库是单独�~�译的,没有昄���指定-fno-omit-frame-pointer�Q�查�?a >gcc手册�Q�o2优化是开启了omit-frame-pinter 的�?/p>
在没有RBP的情况下�Q�tcmalloc�?code>GetStackTrace���试读RBP取获取调用返回地址�Q�自然是有问题的。但是,如果整个调用栈中的函敎ͼ�要么有RBP�Q�要么没有RBP�Q�那�?code>GetStackTrace取出的结果最多就是蟩�q�一些栈帧,不会出错�?/strong> 除非�Q�这中间的某个函数把RBP寄存器另作他用(�~�译器省�����个寄存器肯定是要另作他用的)。所以这里���l�追查这个错误地址 来源已经比较明显�Q�肯定是 �q�里打印RSI寄存器的值可能会被误��|��因�ؓ��M��时候打印寄存器的值可能都是错的,除非它有被显�C�Z��存。不�q�这里可以看出RSI的值来源于参数(RSI对应�W�二个参�?�Q?/p>
�q�到 扑ֈ��?code>0x4e73aa58的来源。这个地址值竟然是一个字�W�串哈希���法���出来的�Q�这里还可以看看�q�个字符串的内容�Q?/p>
�q�个���堡的哈希函数是 以上�Q�既然只要某个库 有了以上条�g�Q�才使得�q�个core几率变得很低�?/p>
最后,如果你很熟悉tcmalloc�Q�整个问题估计就被秒解了�Q?a >tcmalloc INSTALL 另外附上另一个有意思的东西�?/p>
在分�?code>__conhash_add_replicas�Ӟ��其内定义了一�?4字节的字�W�数�l�,查看其堆栈: 最开始我觉得0x4e73aa58的来源�?/p>
__conhash_get_rbnode中设�|�的�Q�因�����个函数的RBP是在被调用�?code>tcmalloc中保存的�?/p>
Dump of assembler code for function __conhash_get_rbnode:
0x00007f75532cd4a0 <__conhash_get_rbnode+0>: mov %rbx,-0x18(%rsp)
0x00007f75532cd4a5 <__conhash_get_rbnode+5>: mov %rbp,-0x10(%rsp)
0x00007f75532cd4aa <__conhash_get_rbnode+10>: mov %esi,%ebp # 改写了RBP
0x00007f75532cd4ac <__conhash_get_rbnode+12>: mov %r12,-0x8(%rsp)
0x00007f75532cd4b1 <__conhash_get_rbnode+17>: sub $0x18,%rsp
0x00007f75532cd4b5 <__conhash_get_rbnode+21>: mov %rdi,%r12
0x00007f75532cd4b8 <__conhash_get_rbnode+24>: mov $0x30,%edi
0x00007f75532cd4bd <__conhash_get_rbnode+29>: callq 0x7f75532b98c8 <malloc@plt> # 调用tcmalloc�Q�汇�~�到�q�里卛_��
void __conhash_add_replicas(conhash_t *conhash, int32_t iden)
{
node_t* node = __conhash_create_node(iden, conhash->replica);
...
char buf[buf_len]; // buf_len = 64
...
snprintf(buf, buf_len, VIRT_NODE_HASH_FMT, node->iden, i);
uint32_t hash = conhash->cb_hashfunc(buf); // hash值由一个字�W�串哈希函数计算
if(util_rbtree_search(&(conhash->vnode_tree), hash) == NULL)
{
util_rbtree_node_t* rbnode = __conhash_get_rbnode(node, hash); // hash�?/span>
...__conhash_add_replicas�Q?/p>
0x00007f75532cd764 <__conhash_add_replicas+164>: mov %ebx,%esi # 来源于rbx
0x00007f75532cd766 <__conhash_add_replicas+166>: mov %r15,%rdi
0x00007f75532cd769 <__conhash_add_replicas+169>: callq 0x7f75532b9e48 <__conhash_get_rbnode@plt>
(gdb) p/x $rbx
$11 = 0x4e73aa58
(gdb) p/x hash
$12 = 0x4e73aa58 # 0x4e73aa58
(gdb) x/1s $rsp
0x4e738bd0: "conhash-00000-00133"
conhash_hash_def�?/p>
coredump的条�?/h2>
omit-frame-pointer�Q�那tcmalloc���可能出错,��Z��么发生的频率�q�不高呢�Q�这个可以回�?code>GetStackTrace���其�?code>NextStackFrame的实玎ͼ�其中包含了几个合法RBP的判定:if (new_sp <= old_sp) return NULL; // 上一个栈帧的RBP肯定比当前的�?/span>
if ((uintptr_t)new_sp - (uintptr_t)old_sp > 100000) return NULL; // 指针��D��围还必须�?00000�?/span>
...
if ((uintptr_t)new_sp & (sizeof(void *) - 1)) return NULL; // �׃��本��n保存的是指针�Q�所以还必须是sizeof(void*)的整数倍,寚w���ȝ��
�?/h2>
(gdb) x/20a $rsp
0x4e738bd0: 0x2d687361686e6f63 0x30302d3030303030 # �q�些是字�W�串conhash-00000-00133
0x4e738be0: 0x333331 0x0
0x4e738bf0: 0x0 0x7f75532cd69e <__conhash_create_node+78>
0x4e738c00: 0x24fbc7e0 0x4e738c60
0x4e738c10: 0x24fbc7e0 0x7f75532cd6e3 <__conhash_add_replicas+35>
0x4e738c20: 0x0 0x24fbc7e8
0x4e738c30: 0x4e738c20 0x24fbc7e0
0x4e738c40: 0x22324360 0x246632c0
0x4e738c50: 0x0 0x0
0x4e738c60: 0x0 0x7f75532cd1fa <conhash_add_node+74>
buf�?4字节�Q�也���是整个[0x4e738bd0, 0x4e738c10)内存�Q�但是这块内存里居然有函数地址�Q�这一度��我怀疑这里有问题。后来醒悟这些地址是定�?code>buf前调�?code>__conhash_create_node产生的,调用�q�程中写到堆栈里�Q�调用完后栈指针改变�Q�但�q�不需要清�I�栈中的内容�?/p>
有时候在�U�上使用gdb调试�E�序core问题�Ӟ��可能没有�W�号文�g�Q�拿到的仅是一个内存地址�Q�如果这个指向的是一个STL对象�Q�那么如何查看这个对象的内容呢?
只需要知道STL各个容器的数据结构实玎ͼ����可以查看其内容。本文描�q�C��SGI STL实现中常用容器的数据�l�构�Q�以及如何在gdb中查看其内容�?/p>
string
string�Q�即basic_string bits/basic_string.h�Q?/p>
mutable _Alloc_hider _M_dataplus;
...
const _CharT*
c_str() const
{ return _M_data(); }
...
_CharT*
_M_data() const
{ return _M_dataplus._M_p; }
...
struct _Alloc_hider : _Alloc
{
_Alloc_hider(_CharT* __dat, const _Alloc& __a)
: _Alloc(__a), _M_p(__dat) { }
_CharT* _M_p; // The actual data.
};
size_type
length() const
{ return _M_rep()->_M_length; }
_Rep*
_M_rep() const
{ return &((reinterpret_cast<_Rep*> (_M_data()))[-1]); }
...
struct _Rep_base
{
size_type _M_length;
size_type _M_capacity;
_Atomic_word _M_refcount;
};
struct _Rep : _Rep_base卻I��string内有一个指针,指向实际的字�W�串位置�Q�这个位�|�前面有一�?code>_Rep�l�构�Q�其内保存了字符串的长度、可用内存以及引用计数。当我们拿到一个string对象的地址�Ӟ��可以通过以下代码获取相关��|��
void ds_str_i(void *p) {
char **raw = (char**)p;
char *s = *raw;
size_t len = *(size_t*)(s - sizeof(size_t) * 3);
printf("str: %s (%zd)\n", s, len);
}
size_t ds_str() {
std::string s = "hello";
ds_str_i(&s);
return s.size();
}在gdb中拿��C��个string的地址�Ӟ��可以以下打印�����字符串及长度�Q?/p>
(gdb) x/1a p
0x7fffffffe3a0: 0x606028
(gdb) p (char*)0x606028
$2 = 0x606028 "hello"
(gdb) x/1dg 0x606028-24
0x606010: 5
vector
众所周知vector实现���是一块连�l�的内存�Q?code>bits/stl_vector.h�?/p>
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >
class vector : protected _Vector_base<_Tp, _Alloc>
...
template<typename _Tp, typename _Alloc>
struct _Vector_base
{
typedef typename _Alloc::template rebind<_Tp>::other _Tp_alloc_type;
struct _Vector_impl
: public _Tp_alloc_type
{
_Tp* _M_start;
_Tp* _M_finish;
_Tp* _M_end_of_storage;
_Vector_impl(_Tp_alloc_type const& __a)
: _Tp_alloc_type(__a), _M_start(0), _M_finish(0), _M_end_of_storage(0)
{ }
};
_Vector_impl _M_impl;可以看出sizeof(vector<xxx>)=24�Q�其内也���是3个指针,_M_start指向首元素地址�Q?code>_M_finish指向最后一个节�?1�Q?code>_M_end_of_storage是可用空间最后的位置�?/p>
iterator
end()
{ return iterator (this->_M_impl._M_finish); }
const_iterator
...
begin() const
{ return const_iterator (this->_M_impl._M_start); }
...
size_type
capacity() const
{ return size_type(const_iterator(this->_M_impl._M_end_of_storage)
- begin()); }可以通过代码从一个vector对象地址输出其信息:
template <typename T>
void ds_vec_i(void *p) {
T *start = *(T**)p;
T *finish = *(T**)((char*)p + sizeof(void*));
T *end_storage = *(T**)((char*)p + 2 * sizeof(void*));
printf("vec size: %ld, avaiable size: %ld\n", finish - start, end_storage - start);
}
size_t ds_vec() {
std::vector<int> vec;
vec.push_back(0x11);
vec.push_back(0x22);
vec.push_back(0x33);
ds_vec_i<int>(&vec);
return vec.size();
}使用gdb输出一个vector中的内容�Q?/p>
(gdb) p p
$3 = (void *) 0x7fffffffe380
(gdb) x/1a p
0x7fffffffe380: 0x606080
(gdb) x/3xw 0x606080
0x606080: 0x00000011 0x00000022 0x00000033
list
众所周知list被实��Cؓ一个链表。准���来说是一个双向链表。list本��n是一个特�D�节点,其代表end�Q�其指向的下一个元素才是list真正的第一个节点:
bits/stl_list.h
bool
empty() const
{ return this->_M_impl._M_node._M_next == &this->_M_impl._M_node; }
const_iterator
begin() const
{ return const_iterator(this->_M_impl._M_node._M_next); }
iterator
end()
{ return iterator(&this->_M_impl._M_node); }
...
struct _List_node_base
{
_List_node_base* _M_next; ///< Self-explanatory
_List_node_base* _M_prev; ///< Self-explanatory
...
};
template<typename _Tp>
struct _List_node : public _List_node_base
{
_Tp _M_data; ///< User's data.
};
template<typename _Tp, typename _Alloc>
class _List_base
{
...
struct _List_impl
: public _Node_alloc_type
{
_List_node_base _M_node;
...
};
_List_impl _M_impl;
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >
class list : protected _List_base<_Tp, _Alloc>所�?code>sizeof(list<xx>)=16�Q�两个指针。每一个真正的节点首先是包含两个指针,然后是元素内�?_List_node)�?/p>
通过代码输出list的内容:
#define NEXT(ptr, T) do { \
void *n = *(char**)ptr; \
T val = *(T*)((char**)ptr + 2); \
printf("list item %p val: 0x%x\n", ptr, val); \
ptr = n; \
} while (0)
template <typename T>
void ds_list_i(void *p) {
void *ptr = *(char**)p;
NEXT(ptr, T);
NEXT(ptr, T);
NEXT(ptr, T);
}
size_t ds_list() {
std::list<int> lst;
lst.push_back(0x11);
lst.push_back(0x22);
lst.push_back(0x33);
ds_list_i<int>(&lst);
return lst.size();
}在gdb中可以以下方式遍历该list�Q?/p>
(gdb) p p
$4 = (void *) 0x7fffffffe390
(gdb) x/1a p
0x7fffffffe390: 0x606080
(gdb) x/1xw 0x606080+16 # 元素1
0x606090: 0x00000011
(gdb) x/1a 0x606080
0x606080: 0x6060a0
(gdb) x/1xw 0x6060a0+16 # 元素2
0x6060b0: 0x00000022
map
map使用的是�U�黑树实玎ͼ�实际使用的是stl_tree.h实现�Q?/p>
bits/stl_map.h
typedef _Rb_tree<key_type, value_type, _Select1st<value_type>,
key_compare, _Pair_alloc_type> _Rep_type;
...
_Rep_type _M_t;
...
iterator
begin()
{ return _M_t.begin(); }bits/stl_tree.h
struct _Rb_tree_node_base
{
typedef _Rb_tree_node_base* _Base_ptr;
typedef const _Rb_tree_node_base* _Const_Base_ptr;
_Rb_tree_color _M_color;
_Base_ptr _M_parent;
_Base_ptr _M_left;
_Base_ptr _M_right;
...
};
template<typename _Val>
struct _Rb_tree_node : public _Rb_tree_node_base
{
typedef _Rb_tree_node<_Val>* _Link_type;
_Val _M_value_field;
};
template<typename _Key_compare,
bool _Is_pod_comparator = std::__is_pod<_Key_compare>::__value>
struct _Rb_tree_impl : public _Node_allocator
{
_Key_compare _M_key_compare;
_Rb_tree_node_base _M_header;
size_type _M_node_count; // Keeps track of size of tree.
...
}
_Rb_tree_impl<_Compare> _M_impl;
...
iterator
begin()
{
return iterator(static_cast<_Link_type>
(this->_M_impl._M_header._M_left));
}所以可以看出,大部分时�?取决�?code>_M_key_compare) sizeof(map<xx>)=48�Q�主要的元素是:
_Rb_tree_color _M_color; // 节点颜色
_Base_ptr _M_parent; // 父节�?/span>
_Base_ptr _M_left; // 左节�?/span>
_Base_ptr _M_right; // 双����?/span>
_Val _M_value_field // 同list中节�Ҏ��巧一��_��后面是实际的元素同list中的实现一��_��map本��n作�ؓ一个节点,其不是一个存储数据的节点�Q?/p>
_Rb_tree::end
iterator
end()
{ return iterator(static_cast<_Link_type>(&this->_M_impl._M_header)); }�׃��节点值在_Rb_tree_node_base后,所以�Q意时候拿到节点就可以偏移�q�个�l�构体拿到节点��|��节点的值是一个pair�Q�包含了key和value�?/p>
在gdb中打��C��下map的内容:
size_t ds_map() {
std::map<std::string, int> imap;
imap["abc"] = 0xbbb;
return imap.size();
}(gdb) p/x &imap
$7 = 0x7fffffffe370
(gdb) x/1a (char*)&imap+24 # _M_left 真正的节�?
0x7fffffffe388: 0x606040
(gdb) x/1xw 0x606040+32+8 # 偏移32字节是节点值的地址�Q�再偏移8则是value的地址
0x606068: 0x00000bbb
(gdb) p *(char**)(0x606040+32) # 偏移32字节是string的地址
$8 = 0x606028 "abc"
或者很多时候没有必要这么装�?蛋疼�Q?/p>
(gdb) p *(char**)(imap._M_t._M_impl._M_header._M_left+1)
$9 = 0x606028 "abc"
(gdb) x/1xw (char*)(imap._M_t._M_impl._M_header._M_left+1)+8
0x606068: 0x00000bbb
�?/em>
zookeeper配置为集���模式时�Q�在启动或异常情冉|��会选�D��Z��个实例作为Leader。其默认选�D���法�?code>FastLeaderElection�?/p>
不知道zookeeper的可以考虑�q�样一个问题:某个服务可以配置为多个实例共同构成一个集���对外提供服务。其每一个实例本地都存有冗余数据�Q�每一个实例都可以直接对外提供��d��服务。在�q�个集群中�ؓ了保证数据的一致性,需要有一个Leader来协调一些事务。那么问题来了:如何���定哪一个实例是Leader呢?
问题的难点在于:
- 没有一个仲裁者来选定Leader
- 每一个实例本地可能已�l�存在数据,不确定哪个实例上的数据是最新的
分布式选�D���法正是用来解决�q�个问题的�?/p>
本文��Z��zookeeper 3.4.6 的源码进行分析。FastLeaderElection���法的源码全部位�?code>FastLeaderElection.java文�g中,其对外接口�ؓFastLeaderElection.lookForLeader�Q�该接口是一个同步接口,直到选�D�l�束才会�q�回。同��L��于网上已有类似文章,所以我��׃��囄���的角度来阐述。阅��M��些其他文章有利于获得初步印象�Q?/p>
- 深入���出Zookeeper之五 Leader选�D�Q�代码导�?/li>
- zookeeper3.3.3源码分析(�?FastLeader选�D���法�Q�文字描�q�较�l?/li>
主要���程
阅读代码和以上推荐文章可以把整个���程梳理清楚。实��C���Q�包括了一个消息处理主循环�Q�也是选�D的主要逻辑�Q�以及一个消息发送队列处理线�E�和消息解码�U�程。主要流�E�可概括��Z��图:

推荐对照着推荐的文章及代码理解�Q�不赘述�?/p>
我们从感性上来理解这个算法�?/p>
每一个节点,相当于一个选民�Q�他们都有自��q��推荐人,最开始他们都推荐自己。谁更适合成�ؓLeader有一个简单的规则�Q�例如sid够大�Q�配�|�)、持有的数据够新(zxid够大)。每个选民都告诉其他选民自己目前的推荐�h是谁�Q�类��g��出去搞宣传拉拢其他选民。每一个选民发现有比自己更适合的�h时就转而推荐这个更适合的�h。最后,大部分�h意见一致时�Q�就可以�l�束选�D�?/p>
���p��么简单。��M��上有一�U�不断演化��D���l�果的感觉�?/p>
当然�Q�会有些�Ҏ��情况的处理。例如��d��3个选民�Q?�?已经���定3是Leader�Q�但3�q�不知情�Q�此时就走入LEADING/FOLLOWING的分支,选民3只是接收�l�果�?/p>
代码中不是所有逻辑都在�q�个大流�E�中完成的。在接收消息�U�程中,�q�可能单独地回应某个节点(WorkerReceiver.run)�Q?/p>

从这里可以看出,当某个节点已�l�确定选�D�l�果不再处于LOOKING状态时�Q�其收到LOOKING消息旉���会直接回应选�D的最�l�结果。结合上面那个比方,相当于某�ơ选�D�l�束了,�q�个时候来了选民4又发起一�ơ新的选�D�Q�那么其他选民���q��接告诉它当前的Leader情况。相当于�Q�在�q�个集群��M��已经���q�A的情况下�Q�又开启了一个实例,�q�个实例��׃��直接使用当前的选�D�l�果�?/p>
状态�{�?/h2>
每个节点上有一些关键的数据�l�构�Q?/p>
- 当前推荐人,初始推荐自己�Q�每�ơ收到其他更好的推荐人时���更�?/li>
- 其他人的投票集合�Q�用于确定何旉����D�l�束
每次推荐人更新时��׃���q�行�q�播�Q�正是这个不断地�q�播驱动整个���法���向于结果。假设有3个节点A/B/C�Q�其都还没有数据�Q�按照sid关系为C>B>A�Q�那么按照规则,C更可能成为Leader�Q�其各个节点的状态�{换�ؓ�Q?/p>

图中�Q�v(A)表示当前推荐��ZؓA�Q�r[]表示收到的投���集合�?/p>
可以看看当其他节点已�l�确定投���结果时�Q�即不再�?code>LOOKING时的状态:

代码中有一个特�D�的投票集合outofelection�Q�我理解为选�D已结束的那些投票�Q�这些投���仅用于表征选�D�l�果�?/p>
当一个新启动的节点加入集���时�Q�它寚w�����内其他节点发出投票��h���Q�而其他节点已不处�?code>LOOKING状态,此时其他节点回应选�D�l�果�Q�该节点攉����q�些�l�果�?code>outofelection中,最�l�在收到合法LEADER消息且这些选票也构成选�D�l�束条�g�Ӟ��该节点就�l�束自己的选�D行�ؓ�?em>注意��C��码中�?code>logicalclock = n.electionEpoch;更新选�D轮数
�?/em>
Paxos协议/���法是分布式�pȝ��中比较重要的协议�Q�它有多重要呢?
<分布式系�l�的事务处理>�Q?/p>
Google Chubby的作者Mike Burrows说过�q�个世界上只有一�U�一致性算法,那就是Paxos�Q�其它的���法都是�D�次品�?/p>
<大规模分布式存储�pȝ��>�Q?/p>
理解了这两个分布式协议之�?Paxos/2PC)�Q�学习其他分布式协议会变得相当容易�?/p>
学习Paxos���法有两部分�Q�a) ���法的原�?证明�Q�b) ���法的理�?�q�作�?/p>
理解�q�个���法的运作过�E�其实基本就可以用于工程实践。而且理解�q�个�q�程相对来说也容易得多�?/p>
�|�上我觉得讲Paxos讲的好的属于�q�篇�Q?a >paxos图解�?a >Paxos���法详解�Q�我�q�里���q���?a >wiki上的实例�q�一步阐�q�。一些paxos基础通过�q�里提到的两���文章,以及wiki上的内容基本可以理解�?/p>
���法内容
Paxos在原作者的《Paxos Made Simple》中内容是比较精���的:
Phase 1
(a) A proposer selects a proposal number n and sends a prepare request with number n to a majority of acceptors.
(b) If an acceptor receives a prepare request with number n greater than that of any prepare request to which it has already responded, then it responds to the request with a promise not to accept any more proposals numbered less than n and with the highest-numbered pro-posal (if any) that it has accepted.
Phase 2
(a) If the proposer receives a response to its prepare requests (numbered n) from a majority of acceptors, then it sends an accept request to each of those acceptors for a proposal numbered n with a value v , where v is the value of the highest-numbered proposal among the responses, or is any value if the responses reported no proposals.
(b) If an acceptor receives an accept request for a proposal numbered n, it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
借用paxos图解文中的流�E�图可概括�ؓ�Q?/p>

实例及详�?/h2>
Paxos中有三类角色Proposer�?code>Acceptor�?code>Learner�Q�主要交互过�E�在Proposer�?code>Acceptor之间�?/p>
Proposer�?code>Acceptor之间的交互主要有4�c�L��息通信�Q�如下图�Q?/p>

�q?�c�L��息对应于paxos���法的两个阶�D?个过�E�:
- phase 1
- a) proposer向网�l�内���过半数的acceptor发送prepare消息
- b) acceptor正常情况下回复promise消息
- phase 2
- a) 在有���_��多acceptor回复promise消息�Ӟ��proposer发送accept消息
- b) 正常情况下acceptor回复accepted消息
因�ؓ在整个过�E�中可能有其他proposer针对同一件事情发��Z��上请求,所以在每个�q�程中都会有些特�D�情况处理,�q�也是�ؓ了达成一致性所做的事情。如果在整个�q�程中没有其他proposer来竞争,那么�q�个操作的结果就是确定无异议的。但是如果有其他proposer的话�Q�情况就不一样了�?/p>
�?a >paxos中文wiki上的例子��Z��。简单来说该例子以若�q�个议员提议�E�收�Q�确定最�l�通过的法案税收比例�?/p>
以下图中基本只画出proposer与一个acceptor的交互。时间标志T2��L��在T1后面。propose number����U�N�?/p>
情况之一如下图:

A3在T1发出accepted�l�A1�Q�然后在T2收到A5的prepare�Q�在T3的时候A1才通知A5最�l�结�?�E�率10%)。这里会有两�U�情况:
- A5发来的N5���于A1发出�ȝ��N1�Q�那么A3直接拒绝(reject)A5
- A5发来的N5大于A1发出�ȝ��N1�Q�那么A3回复promise�Q�但带上A1�?N1, 10%)
�q�里可以与paxos���程囑֯�应�v来,更好理解�?strong>acceptor会记�?MaxN, AcceptN, AcceptV)�?/p>
A5在收到promise后,后箋的流�E�可以顺利进行。但是发出accept�Ӟ��因�ؓ收到�?AcceptN, AcceptV)�Q�所以会取最大的AcceptN对应的AcceptV�Q�例子中也就是A1�?0%作�ؓAcceptV。如果在收到promise时没有发现有其他已记录的AcceptV�Q�则其值可以由自己军_���?/p>
针对以上A1和A5冲突的情况,最�l�A1和A5都会�q�播接受的��gؓ10%�?/p>
其实4个过�E�中对于acceptor而言�Q�在回复promise和accepted时由于都可能因�ؓ其他proposer的介入而导致特�D�处理。所以基本上看在�q�两个时间点收到其他proposer的请求时���可以了解整个算法了。例如在回复promise时则可能因�ؓproposer发来的N不够大而reject�Q?/p>

如果在发accepted消息�Ӟ��对其他更大N的proposer发出�q�promise�Q�那么也会reject该proposer发出的accept�Q�如图:

�q�个对应于Phase 2 b)�Q?/p>
it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
�ȝ��
Leslie Lamport没有用数学描�q�Paxos�Q�但是他用英文阐�q�得很清晰。将Paxos的两个Phase的内容理解清楚,整个���法�q�程�q�是不复杂的�?/p>
至于Paxos中一直提到的一个全局唯一且递增的proposer number�Q�其如何实现�Q�引用如下:
如何产生唯一的编号呢�Q�在《Paxos made simple》中提到的是让所有的Proposer都从不相交的数据集合中进行选择�Q�例如系�l�有5个Proposer�Q�则可�ؓ每一个Proposer分配一个标识j(0~4)�Q�则每一个proposer每次提出册���的编号可以�ؓ5*i + j(i可以用来表示提出议案的次�?
参考文�?/h2>
- paxos图解, http://coderxy.com/archives/121
- Paxos���法详解, http://coderxy.com/archives/136
- Paxos���法 wiki, http://zh.wikipedia.org/zh-cn/Paxos%E7%AE%97%E6%B3%95#.E5.AE.9E.E4.BE.8B
在一个分布式环境中,同类型的服务往往会部�|�很多实例。这些实例��用了一些配�|�,��Z��更好地维护这些配�|�就产生了配�|�管理服务。通过�q�个服务可以��L��地管理这些应用服务的配置问题。应用场景可概括为:

zookeeper的一�U�应用就是分布式配置���理(��Z��ZooKeeper的配�|�信息存储方案的设计与实�?/a>)。百度也有类似的实现�Q?a >disconf�?/p>
Diamond则是淘宝开源的一�U�分布式配置���理服务的实现。Diamond本质上是一个Java写的Web应用�Q�其对外提供接口都是��Z��HTTP协议的,在阅��M��码时可以从实现各个接口的controller入手�?/p>
分布式配�|�管�?/h2>
分布式配�|�管理的本质基本上就是一�U?strong>推�?订阅模式的运用。配�|�的应用�Ҏ��订阅者,配置���理服务则是推送方。概括�ؓ下图�Q?/p>

其中�Q�客��L��包括���理人员publish数据到配�|�管理服务,可以理解为添�?更新数据�Q�配�|�管理服务notify数据到订阅者,可以理解为推送�?/p>
配置���理服务往往会封装一个客��L��库,应用方则是基于该库与配置���理服务�q�行交互。在实际实现�Ӟ��客户端库可能是主动拉�?pull)数据�Q�但对于应用方而言�Q�一般是一�U�事仉���知方式�?/p>
Diamond中的数据是简单的key-value�l�构。应用方订阅数据则是��Z��key来订阅,未订阅的数据当然不会被推送。数据从�c�d��上又划分�����合和非聚合。因为数据推送者可能很多,在整个分布式环境中,可能有多个推送者在推送相同key的数据,�q�些数据如果是聚合的�Q�那么所有这些推送者推送的数据会被合�ƈ在一��P��反之如果是非聚合的,则会出现覆盖�?/p>
数据的来源可能是人工通过���理端录入,也可能是其他服务通过配置���理服务的推送接口自动录入�?/p>
架构及实�?/h2>
Diamond服务是一个集���,是一个去除了单点的协作集���。如图:

图中可分��Z��下部分讲解:
服务之间同步
Diamond服务集群每一个实例都可以对外完整地提供服务,那么意味着每个实例上都有整个集���维护的数据。Diamond有两�U�方式保证这一点:
- ��M��一个实例都有其他实例的地址�Q��Q何一个实例上的数据变更时�Q�都会将改变的数据同步到mysql上,然后通知其他所有实例从mysql上进行一�ơ数据拉�?
DumpService::dump)�Q�这个过�E�只拉取改变了的数据 - ��M��一个实例启动后都会以较长的旉���间隔�Q�几���时�Q�,从mysql�q�行一�ơ全量的数据拉取(
DumpAllProcessor)
实现上�ؓ了一致性,通知其他实例实际上也包含自己。以服务器收到添加聚合数据�ؓ例,处理�q�程大致为:
DatumController::addDatum // /datum.do?method=addDatum
PersistService::addAggrConfigInfo
MergeDatumService::addMergeTask // ��d��一个MergeDataTask�Q�异步处�?
MergeTaskProcessor::process
PersistService::insertOrUpdate
EventDispatcher.fireEvent(new ConfigDataChangeEvent // �z�֏�一个ConfigDataChangeEvent事�g
NotifyService::onEvent // 接收事�g�q�处�?
TaskManager::addTask(..., new NotifyTask // 由此�Q�当数据发生变动�Q�则最�l�创��Z��一个NoticyTask
// NotifyTask同样异步处理
NotifyTaskProcessor::process
foreach server in serverList // 包含自己
notifyToDump // 调用 /notify.do?method=notifyConfigInfo 从mysql更新变动的数�?
虽然Diamond去除了单炚w��题,不过问题都下降到了mysql上。但�׃��其作为配�|�管理的定位�Q�其数据量就mysql的应用而言���小的了�Q�所以可以一定程度上保证整个服务的可用性�?/p>
数据一致�?/h3>
�׃��Diamond服务器没有master�Q��Q何一个实例都可以��d��数据�Q�那么针对同一个key的数据则可能面��冲突。这里应该是通过mysql来保证数据的一致性。每一�ơ客��L����h��写数据时�Q�Diamond都将写请求投递给mysql�Q�然后通知集群内所有Diamond实例�Q�包括自己)从mysql拉取数据。当�Ӟ��拉取数据则可能不是每一�ơ写入都能拉出来�Q�也���是最�l�一致性�?/p>
Diamond中没有把数据攑օ�内存�Q�但会放到本地文件。对于客��L��的读操作而言�Q�则是直接返回本地文仉���的数据�?/p>
服务实例列表
Diamond服务实例列表是一份静态数据,直接���每个实例的地址存放在一个web server上。无论是Diamond服务�q�是客户端都从该web server上取出实例列表�?/p>
对于客户端而言�Q�当其取��Z��该列表后�Q�则是随机选择一个节�?ServerListManager.java)�Q�以后的��h��都会发往该节炏V�?/p>
数据同步
客户端库中以固定旉���间隔从服务器拉取数据(ClientWorker::ClientWorker�Q?code>ClientWorker::checkServerConfigInfo)。只有应用方兛_��的数据才可能被拉取。另外,��Z��数据推送的及时�Q�Diamond�q���用了一�U�long polling的技术,其实也是��Z���H�破HTTP协议的局限性�?em>如果整个服务是基于TCP的自定义协议�Q�客��L��与服务器保持长连接则没有�q�些问题�?/p>
数据的变�?/h3>
Diamond中很多操作都会检查数据是否发生了变化。标识数据变化则是基于数据对应的MD5值来实现的�?/p>
容灾
在整个Diamond�pȝ��中,几个角色��Z��提高容灾性,都有自己的缓存,概括��Z��图:

每一个角色出问题�Ӟ��都可以尽量保证客��L��对应用层提供服务�?/p>