#
author : Kevin Lynx
需求
受WOW的影響,LUA越來越多地被應用于游戲中。腳本被用于游戲中主要用于策劃編寫游戲規則相關。實際運用中,
我們會將很多宿主語言函數綁定到LUA腳本中,使腳本可以更多地控制程序運行。例如我們可以綁定NPCDialog之類的函數
到LUA中,然后策劃便可以在腳本里控制游戲中彈出的NPC對話框。
我們現在面臨這樣的需求:對于宿主程序而言,某些功能是不能阻塞程序邏輯的(對于游戲程序尤其如此),但是為
了方便策劃,我們又需要讓腳本看起來被阻塞了。用NPCDialog舉個例子,在腳本中有如下代碼 :
 ret = NPCDialog( "Hello bitch" )
ret = NPCDialog( "Hello bitch" )
if ret == OK then print("OK") end
對于策劃而言,NPCDialog應該是阻塞的,除非玩家操作此對話框,點擊OK或者關閉,不然該函數不會返回。而對于
宿主程序C++而言,我們如何實現這個函數呢:
static int do_npc_dialog( lua_State *L )


 {
{
 const char *content = lua_tostring( L, -1 );
const char *content = lua_tostring( L, -1 );
lua_pushnumber( ret );
return 1;
 }
}
顯然,該函數不能阻塞,否則它會阻塞整個游戲線程,這對于服務器而言是不可行的。但是如果該函數立即返回,那
么它并沒有收集到玩家對于那個對話框的操作。
綜上,我們要做的是,讓腳本感覺某個操作阻塞,但事實上宿主程序并沒有阻塞。
事件機制
一個最簡單的實現(對于C程序員而言也許也是優美的),就是使用事件機制。我們將對話框的操作結果作為一個事件。
腳本里事實上沒有哪個函數是阻塞的。為了處理一些“阻塞”函數的處理結果,腳本向宿主程序注冊事件處理器(同GUI事件
處理其實是一樣的),例如腳本可以這樣:
function onEvent( ret )
if ret == OK then print("OK") end
end
-- register event handler
SetEventHandler( "onEvent" )
NPCDialog("Hello bitch")
宿主程序保存事件處理器onEvent函數名,當玩家操作了對話框后,宿主程序回調腳本中的onEvent,完成操作。
事實上我相信有很多人確實是這么做的。這樣做其實就是把一個順序執行的代碼流,分成了很多塊。但是對于sleep
這樣的腳本調用呢?例如:
--do job A
sleep(10)
--do job B
sleep(10)
--do job C
那么采用事件機制將可能會把代碼分解為:
function onJobA
--do job A
SetEventHandlerB("onJobB")
sleep(10)
end
function onJobB
--do job B
SetEventHandlerC("onJobC")
end
function onJobC
--do job C
end
-- script starts here
SetEventHandlerA( "onJobA" )
sleep(10)
代碼看起來似乎有點難看了,最重要的是它不易編寫,策劃估計會抓狂的。我想,對于非專業程序員而言,程序的
順序執行可能理解起來更為容易。
SOLVE IT
我們的解決方案,其實只有一句話:當腳本執行到阻塞操作時(如NPCDialog),掛起腳本,當宿主程序某個操作完
成時,讓腳本從之前的掛起點繼續執行。
這不是一種假想的功能。我在剛開始實現這個功能之前,以為LUA不支持這個功能。我臆想著如下的操作:
腳本:
ret = NPCDialog("Hello bitch")
if ret == 0 then print("OK") end
宿主程序:
static int do_npc_dialog( lua_State *L )
{
lua_suspend_script( L );
}
某個地方某個操作完成了:
lua_resume_script( L );
當我實現了這個功能后,我猛然發現,實際情況和我這里想的差不多(有點汗顏)。
認識Coroutine
coroutine是LUA中類似線程的東西,但是它其實和fiber更相似。也就是說,它是一種非搶占式的線程,它的切換取決
于任務本身,也就是取決你,你決定它們什么時候發生切換。建議你閱讀lua manual了解更多。
coroutine支持的典型操作有:lua_yield, lua_resume,也就是我們需要的掛起和繼續執行。
lua_State似乎就是一個coroutine,或者按照LUA文檔中的另一種說法,就是一個thread。我這里之所以用’似乎‘是
因為我自己也無法確定,我只能說,lua_State看起來就是一個coroutine。
LUA提供lua_newthread用于手工創建一個coroutine,然后將新創建的coroutine放置于堆棧頂,如同其他new出來的
對象一樣。網上有帖子說lua_newthread創建的東西與腳本里調用coroutine.create創建出來的東西不一樣,但是根據我
的觀察來看,他們是一樣的。lua_newthread返回一個lua_State對象,所以從這里可以看出,“lua_State看起來就是一個
coroutine”。另外,網上也有人說創建新的coroutine代價很大,但是,一個lua_State的代價能有多大?當然,我沒做過
測試,不敢多言。
lua_yield用于掛起一個coroutine,不過該函數只能用于coroutine內部,看看它的參數就知道了。
lua_resume用于啟動一個coroutine,它可以用于coroutine沒有運行時啟動之,也可以用于coroutine掛起時重新啟動
之。lua_resume在兩種情況下返回:coroutine掛起或者執行完畢,否則lua_resume不返回。
lua_yield和lua_resume對應于腳本函數:coroutine.yield和coroutine.resume,建議你寫寫腳本程序感受下coroutine,
例如:
function main()
print("main start")
coroutine.yield()
print("main end")
end
co=coroutine.create( main );
coroutine.resume(co)
REALLY SOLVE IT
你可能會想到,我們為腳本定義一個main,然后在宿主程序里lua_newthread創建一個coroutine,然后將main放進去,
當腳本調用宿主程序的某個’阻塞‘操作時,宿主程序獲取到之前創建的coroutine,然后yield之。當操作完成時,再resume
之。
事實上方法是對的,但是沒有必要再創建一個coroutine。如之前所說,一個lua_State看上去就是一個coroutine,
而恰好,我們始終都會有一個lua_State。感覺上,這個lua_State就像是main coroutine。(就像你的主線程)
思路就是這樣,因為具體實現時,還是有些問題,所以我羅列每個步驟的代碼。
初始lua_State時如你平時所做:
lua_State *L = lua_open();
luaopen_base( L );
注冊腳本需要的宿主程序函數到L里:
lua_pushcfunction( L, sleep );
lua_setglobal( L, "my_sleep" );
載入腳本文件并執行時稍微有點不同:
luaL_loadfile( L, "test.lua" );
lua_resume( L, 0 ); /**//* 調用resume */
在你的’阻塞‘函數里需要掛起coroutine:
return lua_yield( L, 0 );
注意,lua_yield函數非常特別,它必須作為return語句被調用,否則會調用失敗,具體原因我也不清楚。而在這里,
它作為lua_CFunction的返回值,會不會引發錯誤?因為lua_CFunction約定返回值為該函數對于腳本而言的返回值個數。
實際情況是,我看到的一些例子里都這樣安排lua_yield,所以i do what they do。
在這個操作完成后(如玩家操作了那個對話框),宿主程序需要喚醒coroutine:
lua_resume( L, 0 );
大致步驟就這些。如果你要單獨創建新的lua_State,反而會搞得很麻煩,我開始就是那樣的做的,總是實現不了自己
預想中的效果。
相關下載:
例子程序中,我給了一個sleep實現。腳本程序調用sleep時將被掛起,宿主程序不斷檢查當前時間,當時間到時,resume
掛起的coroutine。下載例子
8.13補充
可能有時候,我們提供給腳本的函數需要返回一些值給腳本,例如NPCDialog返回操作結果,我們只需要在宿主程序里lua_resume
之前push返回值即可,當然,需要設置lua_resume第二個參數為返回值個數。
2.9.2010
lua_yield( L, nResults )第二個參數指定返回給lua_resume的值個數。如下:
lua_pushnumber( L, 3 );
return lua_yield( L, 1 );
..
int ret = lua_resume( L, 0 );
if( ret == LUA_YIELD )
{
lua_Number r = luaL_checknumber( L, -1 );
}
Implement CGI in your httpd
author : Kevin Lynx
Purpose
為我們的http server加入CGI的功能,并不是要讓其成為真正響應CGI query功能的web server。正如klhttpd的開發初衷一樣,
更多的時候我們需要的是一個嵌入式(embeded)的web server。
而加入CGI功能(也許它算不上真正的CGI),則是為了讓我們與client擁有更多的交互能力。我們也許需要為我們的應用程序
加入一個具有網頁外觀的界面,也許這才是我的目的。
Brief
CGI,common gateway interface,在我看來它就是一個公共約定。客戶端瀏覽器提交表單(form)操作結果給服務器,服務器
解析這些操作,完成這些操作,然后創建返回信息(例如一個靜態網頁),返回給瀏覽器。
因為瀏覽器遵循了CGI發送請求的標準,那么我們所要做的就是解析收到的請求,處理我們自己的邏輯,返回信息給客戶端即可。
Detail...
如果你要獲取CGI的更多信息,你可以在網上查閱相關信息。如果你要獲取web server對CGI標準的處理方式,我無法提供給你
這些信息。不過我愿意提供我的臆測:
處理CGI請求通常都是由腳本去完成(當然也可以用任何可執行程序完成)。就我所獲取的資料來看,只要一門語言具備基本的
輸入輸出功能,它就可以被用作CGI腳本。瀏覽器以key-value的形式提交query string,一個典型的以GET方式提交query string的
URL類似于:http://host/cgi-bin/some-script.cgi?name=kevin+lynx&age=22。不必拘泥于我上句話中出現的一些讓你產生問號的
名詞。我可以告訴你,這里舉出的URL(也許更準確的說法是URI)中問號后面的字符串即為一個query string。
我希望你看過我的上一篇草文<實現自己的http server>,你應該知道一個典型的GET請求時怎樣的格式,應該知道什么是initial
line,應該知道HTTP請求有很多method,例如GET、POST、HEAD等。
一個CGI請求通常使用GET或POST作為其request method。對于一個GET類型的CGI請求,一個典型的request類似于:
GET /cgi-bin/some-script.cgi?name=kevin+lynx&age=22 HTTP/1.1
other headers...
...
我上面舉例的那個URL則可能出現在你的瀏覽器的地址欄中,它對我們不重要。
而對于POST類型的CGI請求呢?query string只是被放到了optional body里,如:
POST /cgi-bin/some-script.cgi HTTP/1.1
other heads...
...
name=kevin+lynx&age=22
不管我說到什么,我希望你不要陷入概念的泥潭,我希望你能明確我在brief里提到的what can we do and how to do。
How about the web browser ?
我總是想引領你走在實踐的路上(on the practice way)。作為一個程序員,你有理由自負,但是你沒任何理由小覷任何一個
編程問題。打開你的編譯器,現在就敲下main。
so,我們需要知道如何利用我們的瀏覽器,讓我們更為順手地實踐我們的想法。
你也許會寫:<html><head><title>HTML test</title></head><body>it's a html</body></html>這樣的HTML標記語言。但是
這沒有利用上CGI。check out the url in the reference section and learn how to write FORMs.
這個時候你應該明白:
<html>
<head>
<title>CGI test</title>
</head>
<body>
<FORM ACTION="./cgi-bin/test.cgi">
<INPUT TYPE="text" NAME="name" SIZE=20 VALUE="Your name">
</FORM>
</body>
</html>
加入<FORM>來添加表單,加入<INPUT TYPE="text"加一個edit box控件。那么當你在里面輸入名字按下回車鍵時,瀏覽器將整理
出一個CGI query string發給服務器。
我希望你能在瀏覽器里看到以問號打頭的key-value形式的字符串。
So here we go...
在你自己已有的http server的代碼基礎上,讓瀏覽器來請求一個包含FORM的網頁,例如以上我舉例的html。當瀏覽器將請求發
給服務器的時候,看看服務器這邊收到的request。即使你猜到了什么,我也建議你看看,這樣你將看到一個真正的CGI query是怎么
樣的。
so you know,CGI請求本質上也就是一連串的key-value字符串。真正的http server會將這些字符串傳給CGI腳本。腳本只需要
輸出處理結果信息到標準輸出,服務器就會收集這些輸出然后發給客戶端。
你也許在揣摩,我們的httpd如何地exec一個外部程序或腳本,如何等待腳本執行完(需不需要異步?),然后如何收集標準輸
出上的信息,然后是否需要同步地將這些信息送往客戶端。
這很沒必要。如果我們的http server真的只是被embeded到其他程序的。我們只需要將query的邏輯處理交給上層模塊即可。
What's the next..
現在你知道什么是CGI query string,你也許稍微思考下就知道接下來你該如何去做(if you smart enough)。記住我們的目標,
只是解析CGI query string,然后處理相關邏輯,返回處理結果信息給客戶端。
所以接下來,呃,接下來,everything is up to you:分析那些惱人的字符串,將其從&的間隔中整理出來,得到一個key-value
的表,將這個表給你的上層模塊,上層模塊根據query scritp決定執行什么邏輯,根據這個表獲取需要的參數,處理,將結果格式
化為HTML之類的東西,then response。
就這么簡單。
Example...
同樣,我提供了源碼,從而證明我不是紙上談兵夸夸其談。我希望我公開源碼的習慣能受到你的贊同。
下載帶CGI的http server.
Reference:
http://hoohoo.ncsa.uiuc.edu/cgi/ (獲取服務器需要做的)
http://www.ietf.org/rfc/rfc3875 (rfc cgi)
http://www.cmis.brighton.ac.uk/~mas/mas/courses/html/html2.html (學會寫帶FORM的HTML)
Write your own http server
author : Kevin Lynx
Why write your own?
看這個問題的人證明你知道什么是http server,世界上有很多各種規模的http server,為什么要自己實現一個?其實沒什么
理由。我自己問自己,感覺就是在自己娛樂自己,或者說只是練習下網絡編程,或者是因為某日我看到某個庫宣稱自己附帶一個小
型的http server時,我不知道是什么東西,于是就想自己去實現一個。
What's httpd ?
httpd就是http daemon,這個是類unix系統上的名稱,也就是http server。httpd遵循HTTP協議,響應HTTP客戶端的request,
然后返回response。
那么,什么是HTTP協議?最簡單的例子,就是你的瀏覽器與網頁服務器之間使用的應用層協議。雖然官方文檔說HTTP協議可以
建立在任何可靠傳輸的協議之上,但是就我們所見到的,HTTP還是建立在TCP之上的。
httpd最簡單的response是返回靜態的HTML頁面。在這里我們的目標也只是一個響應靜態網頁的httpd而已(也許你愿意加入CGI
特性)。
More details about HTTP protocol
在這里有必要講解HTTP協議的更多細節,因為我們的httpd就是要去解析這個協議。
關于HTTP協議的詳細文檔,可以參看rfc2616。但事實上對于實現一個簡單的響應靜態網頁的httpd來說,完全沒必要讀這么一
分冗長的文檔。在這里我推薦<HTTP Made Really Easy>,以下內容基本取自于本文檔。
- HTTP協議結構
HTTP協議無論是請求報文(request message)還是回應報文(response message)都分為四部分:
* 報文頭 (initial line )
* 0個或多個header line
* 空行(作為header lines的結束)
* 可選body
HTTP協議是基于行的協議,每一行以\r\n作為分隔符。報文頭通常表明報文的類型(例如請求類型),報文頭只占一行;header line
附帶一些特殊信息,每一個header line占一行,其格式為name:value,即以分號作為分隔;空行也就是一個\r\n;可選body通常
包含數據,例如服務器返回的某個靜態HTML文件的內容。舉個例子,以下是一個很常見的請求報文,你可以截獲瀏覽器發送的數據
包而獲得:
1 GET /index.html HTTP/1.1
2 Accept-Language: zh-cn
3 Accept-Encoding: gzip, deflate
4 User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; MAXTHON 2.0)
5 Host: localhost
6 Connection: Keep-Alive
7
我為每一行都添加了行號,第1行就是initial line,2-6行是header lines,7行是一個header line的結束符,沒有顯示出來。
以下是一個回應報文:
1 HTTP/1.1 200 OK
2 Server: klhttpd/0.1.0
3 Content-Type: text/html
4 Content-Length: 67
5
6 <head><head><title>index.html</title></head><body>index.html</body>
第6行就是可選的body,這里是index.html這個文件的內容。
- HTTP request method
因為我們做的事服務器端,所以我們重點對請求報文做說明。首先看initial line,該行包含幾個字段,每個字段用空格分開,例
如以上的GET /index.html HTTP/1.1就可以分為三部分:GET、/index.html、HTTP/1.1。其中第一個字段GET就是所謂的request
method。它表明請求類型,HTTP有很多method,例如:GET、POST、HEAD等。
就我們的目標而言,我們只需要實現對GET和HEAD做響應即可。
GET是最普遍的method,表示請求一個資源。什么是資源?諸如HTML網頁、圖片、聲音文件等都是資源。順便提一句,HTTP協議
中為每一個資源設置一個唯一的標識符,就是所謂的URI(更寬泛的URL)。
HEAD與GET一樣,不過它不請求資源內容,而是請求資源信息,例如文件長度等信息。
- More detail
繼續說說initial line后面的內容:
對應于GET和HEAD兩個method,緊接著的字段就是資源名,其實從這里可以看出,也就是文件名(相對于你服務器的資源目錄),例
如這里的/index.html;最后一個字段表明HTTP協議版本號。目前我們只需要支持HTTP1.1和1.0,沒有多大的技術差別。
然后是header line。我們并不需要關注每一個header line。我只羅列有用的header line :
- Host : 對于HTTP1.1而言,請求報文中必須包含此header,如果沒有包含,服務器需要返回bad request錯誤信息。
- Date : 用于回應報文,用于客戶端緩存數據用。
- Content-Type : 用于回應報文,表示回應資源的文件類型,以MIME形式給出。什么是MIME?它們都有自己的格式,例如:
text/html, image/jpg, image/gif等。
- Content-Length : 用于回應報文,表示回應資源的文件長度。
body域很簡單,你只需要將一個文件全部讀入內存,然后附加到回應報文段后發送即可,即使是二進制數據。
- 回應報文
之前提到的一個回應報文例子很典型,我們以其為例講解。首先是initial line,第一個字段表明HTTP協議版本,可以直接以請求
報文為準(即請求報文版本是多少這里就是多少);第二個字段是一個status code,也就是回應狀態,相當于請求結果,請求結果
被HTTP官方事先定義,例如200表示成功、404表示資源不存在等;最后一個字段為status code的可讀字符串,你隨便給吧。
回應報文中最好跟上Content-Type、Content-Length等header。
具體實現
正式寫代碼之前我希望你能明白HTTP協議的這種請求/回應模式,即客戶端發出一個請求,然后服務器端回應該請求。然后繼續
這個過程(HTTP1.1是長連接模式,而HTTP1.0是短連接,當服務器端返回第一個請求時,連接就斷開了)。
這里,我們無論客戶端,例如瀏覽器,發出什么樣的請求,請求什么資源,我們都回應相同的數據:
/**//* 阻塞地接受一個客戶端連接 */
SOCKET con = accept( s, 0, 0 );
/**//* recv request */
char request[1024] = { 0 };
ret = recv( con, request, sizeof( request ), 0 );
printf( request );
/**//* whatever we recv, we send 200 response */
{
char content[] = "<head><head><title>index.html</title></head><body>index.html</body>";
char response[512];
sprintf( response, "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\nContent-Length: %d\r\n\r\n%s", strlen( content ), content );
ret = send( con, response, strlen( response ), 0 );
}
closesocket( con );
程序以最簡單的阻塞模式運行,我們可以將重點放在協議的分析上。運行程序,在瀏覽器里輸入http://localhost:8080/index.html
,然后就可以看到瀏覽器正常顯示content中描述的HTML文件。假設程序在8080端口監聽。
現在你基本上明白了整個工作過程,我們可以把代碼寫得更全面一點,例如根據GET的URI來載入對應的文件然后回應給客戶端。
其實這個很簡單,只需要從initial line里解析出(很一般的字符串解析)URI字段,然后載入對應的文件即可。例如以下函數:
void http_response( SOCKET con, const char *request )
{

 /**//* get the method */
/**//* get the method */
char *token = strtok( request, " " );
char *uri = strtok( 0, " " );
char file[64];
sprintf( file, ".%s", uri );
{
/**//* load the file content */
FILE *fp = fopen( file, "rb" );
if( fp == 0 )
{
/**//* response 404 status code */
char response[] = "HTTP/1.1 404 NOT FOUND\r\n\r\n";
send( con, response, strlen( response ), 0 );
 }
}
else
{
/**//* response the resource */
/**//* first, load the file */
int file_size ;
char *content;
char response[1024];
fseek( fp, 0, SEEK_END );
file_size = ftell( fp );
fseek( fp, 0, SEEK_SET );
content = (char*)malloc( file_size + 1 );
fread( content, file_size, 1, fp );
content[file_size] = 0;
sprintf( response, "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\nContent-Length: %d\r\n\r\n%s", file_size, content );
send( con, response, strlen( response ), 0 );
free( content );
}
}
}
其他
要將這個簡易的httpd做完善,我們還需要注意很多細節。包括:對不支持的method返回501錯誤;對于HTTP1.1要求有Host這個
header;為了支持客戶端cache,需要添加Date header;支持HEAD請求等。
相關下載中我提供了一個完整的httpd library,純C的代碼,在其上加上一層資源載入即可實現一個簡單的httpd。在這里我將
對代碼做簡要的說明:
evbuffer.h/buffer.c : 取自libevent的buffer,用于緩存數據;
klhttp-internal.h/klhttp-internal.c :主要用于處理/解析HTTP請求,以及創建回應報文;
klhttp-netbase.h/klhttp-netbase.c :對socket api的一個簡要封裝,使用select模型;
klhttp.h/klhttp.c :庫的最上層,應用層主要與該層交互,這一層主要集合internal和netbase。
test_klhttp.c :一個測試例子。
相關下載:
klhttpd
文中相關代碼
參考資料:
http://www.w3.org/Protocols/rfc2616/rfc2616.html
http://jmarshall.com/easy/http/
http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html
Kevin Lynx
7.21.2008
What's memcached ?
memcached是一個以key-value的形式緩存數據的緩存系統。通過將數據緩存到內存中,從而提高數據的獲取速度。
memcached以key-value的形式來保存數據,你可以為你每一段數據關聯一個key,然后以后可以通過這個key獲取
這段數據。
memcached是一個庫還是什么?memcached其實是一個單獨的網絡服務器程序。它的網絡底層基于libevent,你可以
將其運行在網絡中的一臺服務器上,通過網絡,在遵循memcached的協議的基礎上與memcached服務器進行通信。
What do we want to wrap ?
我們需要做什么?我們只需要遵循memcached的協議(參見該文檔),封裝網絡層的通信,讓上層可以通過調用諸如
add/get之類的接口即可實現往memcached服務器緩存數據,以及取數據。上層程序員根本不知道這些數據在網絡
上存在過。
這個東西,也就是memcached官方所謂的client apis。你可以使用現成的客戶端庫,但是你也可以將這種重造輪子
的工作當作一次網絡編程的練習。it's up to you.:D
Where to start ?
很遺憾,對于windows用戶而言,memcached官方沒有給出一個可以執行或者可以直接F7即可得到可執行文件的下載
(如果你是vc用戶)。幸運的是,已經有人做了這個轉換工作。
你可以從http://jehiah.cz/projects/memcached-win32/這里下載到memcached的windows版本,包括可執行程序和
源代碼。
我們直接可以運行memcached.exe來安裝/開啟memcached服務器,具體步驟在以上頁面有所提及:
安裝:memcached.exe -d install,這會在windows服務里添加一個memcached服務
運行:memcached.exe -d start,你也可以通過windows的服務管理運行。
然后,你可以在任務管理器里看到一個'memcached'的進程,很占內存,因為這是memcached。
So, here we go ...
通過以上步驟運行的memcached,默認在11211端口監聽(是個TCP連接,可以通過netstat查看)。接下來,我們就可
以connect到該端口上,然后send/recv數據了。發送/接收數據只要遵循memcached的協議格式,一切都很簡單。
使用最簡單的阻塞socket連接memcached服務器:
SOCKET s = socket( AF_INET, SOCK_STREAM, 0 );
struct sockaddr_in addr;
memset( &addr, 0, sizeof( addr ) );
addr.sin_family = AF_INET;
addr.sin_port = htons( 11211 );
addr.sin_addr.s_addr = inet_addr( "127.0.0.1" );
ret = connect( s, (struct sockaddr*) &addr, sizeof( addr ) );
if( ret == 0 )
{
printf( "connect ok\n" );
}
About the protocol
簡單地提一下memcached的協議。
可以說,memcached的協議是基于行的協議,因為無論是客戶端請求還是服務器端應答,都是以"\r\n"作為結束符。
memcached的協議將數據(send/recv操作的數據)分為兩種類型:命令和用戶數據。
命令用于服務器和客戶端進行交互;而用戶數據,很顯然,就是用戶想要緩存的數據。
關于用戶數據,你只需要將其編碼成字節流(說白了,只要send函數允許即可),并附帶數據結束標志"\r\n"發送即可。
關于命令,memcached分為如下幾種命令:存儲數據、刪除數據、取出數據、其他一些獲取信息的命令。其實你換個角度
想想,memcached主要就是將數據存儲到內存里,所以命令也多不了哪去,基本就停留在add/get/del上。
關于key,memcached用key來標識數據,每一個key都是一個不超過255個字符的字符串。
到這里,你可以發現memcached對于數據的存儲方式(暴露給上層)多少有點像std::map,如果你愿意,你可以將客戶端
API封裝成map形式。= =#
具體實現
接下來可以看看具體的實現了。
首先看看存儲數據命令,存儲數據命令有:add/set/replace/append/prepend/cas。存儲命令的格式為:
<command name> <key> <flags> <exptime> <bytes> [noreply]\r\n
具體字段的含義參看protocol.txt文件,這里我對set舉例,如下代碼,阻塞發送即可:
char cmd[256] ;
char data[] = "test data";
sprintf( cmd, "set TestKey 0 0 %d\r\n", strlen( data ) );
ret = send( s, cmd, strlen( cmd ), 0 );
注意:noreply選項對于有些memcached版本并不被支持,例如我們使用的1.2.2版本。注意官方的changelog即可。
當你發送了存儲命令后,memcached會等待客戶端發送數據塊。所以我們繼續發送數據塊:
ret = send( s, data, strlen( data ), 0 );
ret = send( s, "\r\n", 2, 0 ); // 數據結束符
然后,正常的話,memcached服務器會返回應答信息給客戶端。
char reply[256];
ret = recv( s, reply, sizeof( reply ) - 1, 0 );
reply[ret] = 0;
printf( "server reply : %s\n", reply );
如果存儲成功,服務器會返回STORED字符串。memcached所有應答信息都是以字符串的形式給出的。所以可以直接printf出來。
關于其他的操作,我就不在這里列舉例子了。我提供了我封裝的memcached客戶端庫的完整代碼下載,使用的是阻塞socket,
對應著memcached的協議看,很容易看懂的。
It's a story about a programmer...
最近發覺自己有點極端,要么寫純C的代碼,要么寫滿是template的泛型代碼。
相關代碼下載
author : Kevin Lynx
什么是min heap ?
首先看什么是heap,heap是這樣一種數據結構:1.它首先是一棵完成二叉樹;2.父親節點始終大于(或其他邏輯關系
)其孩子節點。根據父親節點與孩子節點的這種邏輯關系,我們將heap分類,如果父親節點小于孩子節點,那么這個heap
就是min heap。
就我目前所看到的實現代碼來看,heap基本上都是用數組(或者其他的連續存儲空間)作為其存儲結構的。這可以保證
數組第一個元素就是heap的根節點。這是一個非常重要的特性,它可以保證我們在取heap的最小元素時,其算法復雜度為
O(1)。
原諒我的教科書式說教,文章后我會提供我所查閱的比較有用的關于heap有用的資料。
What Can It Do?
libevent中的min_heap其實不算做真正的MIN heap。它的節點值其實是一個時間值。libevent總是保證時間最晚的節
點為根節點。
libevent用這個數據結構來實現IO事件的超時控制。當某個事件(libevent中的struct event)被添加時(event_add),
libevent將此事件按照其超時時間(由用戶設置)保存在min_heap里。然后libevent會定期地去檢查這個min_heap,從而實現
了超時機制。
實現
min_heap相關源碼主要集中在min_heap.h以及超時相關的event.c中。
首先看下min_heap的結構體定義:
typedef struct min_heap
{
struct event** p;
unsigned n, a;
} min_heap_t;
p指向了一個動態分配的數組(隨便你怎么說,反正它是一個由realloc分配的連續內存空間),數組元素為event*,這也是
heap中的節點類型。這里libevent使用連續空間去保存heap,也就是保存一棵樹。因為heap是完成樹,所以可以保證其元素在
數組中是連續的。n表示目前保存了多少個元素,a表示p指向的內存的尺寸。
struct event這個結構體定義了很多東西,但是我們只關注兩個成員:min_heap_idx:表示該event保存在min_heap數組中
的索引,初始為-1;ev_timeout:該event的超時時間,將被用于heap操作中的節點值比較。
接下來看幾個與堆操作不大相關的函數:
min_heap_elem_greater:比較兩個event的超時值大小。
min_heap_size:返回heap元素值數量。
min_heap_reserve:調整內存空間大小,也就是調整p指向的內存區域大小。凡是涉及到內存大小調整的,都有一個策略問
題,這里采用的是初始大小為8,每次增大空間時以2倍的速度增加。
看幾個核心的:真正涉及到heap數據結構操作的函數:往堆里插入元素、從堆里取出元素:
相關函數為:min_heap_push、min_heap_pop、min_heap_erase、min_heap_shift_up_、min_heap_shift_down_。
heap的核心操作:
- 往堆里插入元素:
往堆里插入元素相對而言比較簡單,如圖所示,每一次插入時都從樹的最右最下(也就是葉子節點)開始。然后比較即將插入
的節點值與該節點的父親節點的值,如果小于父親節點的話(不用在意這里的比較規則,上下文一致即可),那么交換兩個節點,
將新的父親節點與其新的父親節點繼續比較。重復這個過程,直到比較到根節點。
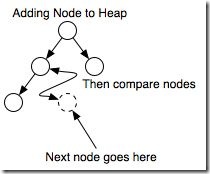
libevent實現這個過程的函數主要是min_heap_shift_up_。每一次min_heap_push時,首先檢查存儲空間是否足夠,然后直接
調用min_heap_shift_up_插入。主要代碼如下:
void min_heap_shift_up_(min_heap_t* s, unsigned hole_index, struct event* e)
{
/**//* 獲取父節點 */
unsigned parent = (hole_index - 1) / 2;
/**//* 只要父節點還大于子節點就循環 */
while(hole_index && min_heap_elem_greater(s->p[parent], e))
{
/**//* 交換位置 */
(s->p[hole_index] = s->p[parent])->min_heap_idx = hole_index;
hole_index = parent;
parent = (hole_index - 1) / 2;
}
(s->p[hole_index] = e)->min_heap_idx = hole_index;
- 從堆里取元素:
大部分時候,從堆里取元素只局限于取根節點,因為這個節點是最有用的。對于數組存儲結構而言,數組第一個元素即為根
節點。取完元素后,我們還需要重新調整整棵樹以使其依然為一個heap。
這需要保證兩點:1.依然是完成樹;2.父親節點依然小于孩子節點。
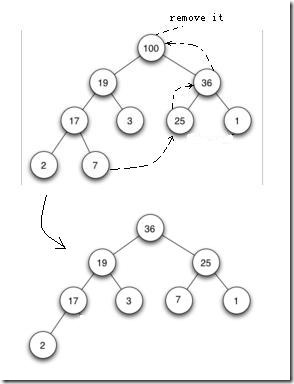
在具體實現heap的取元素操作時,具體到代碼層次,方法都是有那么點微小差別的。libvent里的操作過程大致如圖所示(實際上libevent中父節點的時間值小于子節點的時間值,時間值的比較通過evutil_timercmp實現):
主要過程分為兩步:
1.比較左右孩子節點,選擇最大的節點,移到父親節點上;按照這種方式處理被選擇的孩子節點,直到沒有孩子節點為止。例如,
當移除了100這個節點后,我們在100的孩子節點19和36兩個節點里選擇較大節點,即36,將36放置到100處;然后選擇原來的36的
左右孩子25和1,選25放置于原來的36處;
2.按照以上方式處理后,樹會出現一個空缺,例如原先的25節點,因為被移動到原先的36處,25處就空缺了。因此,為了保證完
成性,就將最右最下的葉子節點(也就是連續存儲結構中最后一個元素),例如這里的7,移動到空缺處,然后按照插入元素的方式處理
新插入的節點7。
完成整個過程。
libevent完成這個過程的函數主要是min_heap_shift_down_:
/**//* hole_index 為取出的元素的位置,e為最右最下的元素值 */
void min_heap_shift_down_(min_heap_t* s, unsigned hole_index, struct event* e)
{
/**//* 取得hole_index的右孩子節點索引 */
unsigned min_child = 2 * (hole_index + 1);
while(min_child <= s->n)
{
/**//* 有點惡心的一個表達式,目的就是取兩個孩子節點中較大的那個孩子索引 */
min_child -= min_child == s->n || min_heap_elem_greater(s->p[min_child], s->p[min_child - 1]);
/**//* 找到了位置,這里似乎是個優化技巧,不知道具體原理 */
if(!(min_heap_elem_greater(e, s->p[min_child])))
break;
/**//* 換位置 */
(s->p[hole_index] = s->p[min_child])->min_heap_idx = hole_index;
/**//* 重復這個過程 */
hole_index = min_child;
min_child = 2 * (hole_index + 1);
}
/**//* 執行第二步過程,將最右最下的節點插到空缺處 */
min_heap_shift_up_(s, hole_index, e);
}
STL中的heap
值得一提的是,STL中提供了heap的相關操作算法,借助于模板的泛化特性,其適用范圍非常廣泛。相關函數為:
make_heap, pop_heap, sort_heap, is_heap, sort 。其實現原理同以上算法差不多,相關代碼在algorithm里。SGI的
STL在stl_heap.h里。
參考資料:
What is a heap?
Heap_(data_structure)
Heap Remove
Author : Kevin Lynx
前言
可以說對于任何網絡庫(模塊)而言,一個緩沖模塊都是必不可少的。緩沖模塊主要用于緩沖從網絡接收到的數據,以及
用戶提交的數據(用于發送)。很多時候,我們還需要將網絡模塊層(非TCP層)的這些緩沖數據拷貝到用戶層,而這些內存拷貝
都會消耗時間。
在這里,我簡要分析下libevent的相關代碼(event.h和buffer.c)。
結構
關于libevent的緩沖模塊,主要就是圍繞evbuffer結構體展開。先看下evbuffer的定義:
/**//*event.h*/
struct evbuffer {
u_char *buffer;
u_char *orig_buffer;
size_t misalign;
size_t totallen;
size_t off;
void (*cb)(struct evbuffer *, size_t, size_t, void *);
void *cbarg;
};
libevent的緩沖是一個連續的內存區域,其處理數據的方式(寫數據和讀數據)更像一個隊列操作方式:從后寫入,從前
讀出。evbuffer分別設置相關指針(一個指標)用于指示讀出位置和寫入位置。其大致結構如圖:
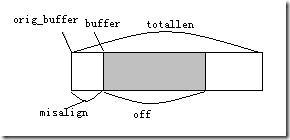
orig_buffer指向由realloc分配的連續內存區域,buffer指向有效數據的內存區域,totallen表示orig_buffer指向的內存
區域的大小,misalign表示buffer相對于orig_buffer的偏移,off表示有效數據的長度。
實際運作
這里我將結合具體的代碼分析libevent是如何操作上面那個隊列式的evbuffer的,先看一些輔助函數:
evbuffer_drain:
該函數主要操作一些指標,當每次從evbuffer里讀取數據時,libevent便會將buffer指針后移,同時增大misalign,減小off,
而該函數正是做這件事的。說白了,該函數就是用于調整緩沖隊列的前向指標。
evbuffer_expand:
該函數用于擴充evbuffer的容量。每次向evbuffer寫數據時,都是將數據寫到buffer+off后,buffer到buffer+off之間已被
使用,保存的是有效數據,而orig_buffer和buffer之間則是因為讀取數據移動指標而形成的無效區域。
evbuffer_expand的擴充策略在于,首先判斷如果讓出orig_buffer和buffer之間的空閑區域是否可以容納添加的數據,如果
可以,則移動buffer和buffer+off之間的數據到orig_buffer和orig_buffer+off之間(有可能發生內存重疊,所以這里移動調用的
是memmove),然后把新的數據拷貝到orig_buffer+off之后;如果不可以容納,那么重新分配更大的空間(realloc),同樣會移動
數據。
擴充內存的策略為:確保新的內存區域最小尺寸為256,且以乘以2的方式逐步擴大(256、512、1024、...)。
了解了以上兩個函數,看其他函數就比較簡單了。可以看看具體的讀數據和寫數據:
evbuffer_add:
該函數用于添加一段用戶數據到evbuffer中。很簡單,就是先判斷是否有足夠的空閑內存,如果沒有則調用evbuffer_expand
擴充之,然后直接memcpy,更新off指標。
evbuffer_remove:
該函數用于將evbuffer中的數據復制給用戶空間(讀數據)。簡單地將數據memcpy,然后調用evbuffer_drain移動相關指標。
其他
回過頭看看libevent的evbuffer其實是非常簡單的(跟我那個kl_net里的buffer一樣),不知道其他人有沒有更優的緩沖管理
方案。evbuffer還提供了兩個函數:evbuffer_write和evbuffer_read,用于直接在套接字(其他文件描述符)上寫/讀數據。
另外,關于libevent,因為官方提供的VC工程文件有問題,很多人在windows下編譯不過。金慶曾提供過一種方法。其實主要
就是修改event-config.h文件,修改編譯相關配置。這里我也提供一個解決步驟,順便提供完整包下載:
1. vs2005打開libevent.dsw,轉換四個工程(event_test, libevent, signal_test, time_test)
2. 刪除libevent項目中所有的文件,重新添加文件,文件列表如下:
buffer.c
evbuffer.c
evdns.c
evdns.h
event.c
event.h
event_tagging.c
event-config.h
event-internal.h
evhttp.h
evrpc.h
evrpc.c
evrpc-internal.h
evsignal.h
evutil.c
evutil.h
http.c
http-internal.h
log.c
log.h
min_heap.h
strlcpy.c
strlcpy-internal.h
tree.h
win32.c
config.h
signal.c
3. 替換event-config.h,使用libevent-iocp中的
4. 項目設置里添加HAVE_CONFIG_H預處理宏
5. 修改win32.c中win32_init函數,加入WSAStartup函數,類似于:
WSADATA wd;
int err;
struct win32op *winop;
size_t size;
if( ( err = WSAStartup( MAKEWORD( 2, 2 ), &wd ) ) != 0 )
event_err( 1, "winsock startup failed : %d", err );
6. 修改win32.c中win32_dealloc函數,在函數末尾加上WSACleanup的調用:
WSACleanup();
6. 至此libevent編譯成功;
7. 幾個例子程序,只需要加入HAVE_CONFIG_H預處理宏,以及連接ws2_32.lib即可;
(time_test需要修改time-test.c文件,即在包含event.h前包含windows.h)
libevent-1.4.5-stable-vs2005.zip下載
author : Kevin Lynx
什么是完成包?
完成包,即IO Completion Packet,是指異步IO操作完畢后OS提交給應用層的通知包。IOCP維護了一個IO操作結果隊列,里面
保存著各種完成包。應用層調用GQCS(也就是GetQueueCompletionStatus)函數獲取這些完成包。
最大并發線程數
在一個典型的IOCP程序里,會有一些線程調用GQCS去獲取IO操作結果。最大并發線程數指定在同一時刻處理完成包的線程數目。
該參數在調用CreateIoCompletionPort時由NumberOfConcurrentThreads指定。
工作者線程
工作者線程一般指的就是調用GQCS函數的線程。要注意的是,工作者線程數和最大并發線程數并不是同一回事(見下文)。工作者
線程由應用層顯示創建(_beginthreadex 之類)。工作者線程通常是一個循環,會不斷地GQCS到完成包,然后處理完成包。
調度過程
工作者線程以是否阻塞分為兩種狀態:運行狀態和等待狀態。當線程做一些阻塞操作時(線程同步,甚至GQCS空的完成隊列),線程
處于等待狀態;否則,線程處于運行狀態。
另一方面,OS會始終保持某一時刻處于運行狀態的線程數小于最大并發線程數。每一個調用GQCS函數的線程OS實際上都會進行記錄,
當完成隊列里有完成包時,OS會首先檢查當前處于運行狀態的工作線程數是否小于最大并發線程數,如果小于,OS會按照LIFO的順
序讓某個工作者線程從GQCS返回(此工作者線程轉換為運行狀態)。如何決定這個LIFO?這是簡單地通過調用GQCS函數的順序決定的。
從這里可以看出,這里涉及到線程喚醒和睡眠的操作。如果兩個線程被放置于同一個CPU上,就會有線程切換的開銷。因此,為了消
除這個開銷,最大并發線程數被建議為設置成CPU數量。
從以上調度過程還可以看出,如果某個處于運行狀態的工作者線程在處理完成包時阻塞了(例如線程同步、其他IO操作),那么就有
CPU資源處于空閑狀態。因此,我們也看到很多文檔里建議,工作者線程數為(CPU數*2+2)。
在一個等待線程轉換到運行狀態時,有可能會出現短暫的時間運行線程數超過最大并發線程數,這個時候OS會迅速地讓這個新轉換
的線程阻塞,從而減少這個數量。(關于這個觀點,MSDN上只說:by not allowing any new active threads,卻沒說明not allowing
what)
調度原理
這個知道了其實沒什么意義,都是內核做的事,大致上都是操作線程control block,直接摘錄<Inside IO Completion Ports>:
The list of threads hangs off the queue object. A thread's control block data structure has a pointer in it that
references the queue object of a queue that it is associated with; if the pointer is NULL then the thread is not
associated with a queue.
So how does NT keep track of threads that become inactive because they block on something other than the completion
port" The answer lies in the queue pointer in a thread's control block. The scheduler routines that are executed
in response to a thread blocking (KeWaitForSingleObject, KeDelayExecutionThread, etc.) check the thread's queue
pointer and if its not NULL they will call KiActivateWaiterQueue, a queue-related function. KiActivateWaiterQueue
decrements the count of active threads associated with the queue, and if the result is less than the maximum and
there is at least one completion packet in the queue then the thread at the front of the queue's thread list is
woken and given the oldest packet. Conversely, whenever a thread that is associated with a queue wakes up after
blocking the scheduler executes the function KiUnwaitThread, which increments the queue's active count.
參考資料
<Inside I/O Completion Ports>:
http://technet.microsoft.com/en-us/sysinternals/bb963891.aspx
<I/O Completion Ports>:
http://msdn.microsoft.com/en-us/library/aa365198(VS.85).aspx
<INFO: Design Issues When Using IOCP in a Winsock Server>:
http://support.microsoft.com/kb/192800/en-us/
6.6.2008
Kevin Lynx
Proactor和Reactor都是并發編程中的設計模式。在我看來,他們都是用于派發/分離IO操作事件的。這里所謂的
IO事件也就是諸如read/write的IO操作。"派發/分離"就是將單獨的IO事件通知到上層模塊。兩個模式不同的地方
在于,Proactor用于異步IO,而Reactor用于同步IO。
摘抄一些關鍵的東西:
"
Two patterns that involve event demultiplexors are called Reactor and Proactor [1]. The Reactor patterns
involve synchronous I/O, whereas the Proactor pattern involves asynchronous I/O.
"
關于兩個模式的大致模型,從以下文字基本可以明白:
"
An example will help you understand the difference between Reactor and Proactor. We will focus on the read
operation here, as the write implementation is similar. Here's a read in Reactor:
* An event handler declares interest in I/O events that indicate readiness for read on a particular socket ;
* The event demultiplexor waits for events ;
* An event comes in and wakes-up the demultiplexor, and the demultiplexor calls the appropriate handler;
* The event handler performs the actual read operation, handles the data read, declares renewed interest in
I/O events, and returns control to the dispatcher .
By comparison, here is a read operation in Proactor (true async):
* A handler initiates an asynchronous read operation (note: the OS must support asynchronous I/O). In this
case, the handler does not care about I/O readiness events, but is instead registers interest in receiving
completion events;
* The event demultiplexor waits until the operation is completed ;
* While the event demultiplexor waits, the OS executes the read operation in a parallel kernel thread, puts
data into a user-defined buffer, and notifies the event demultiplexor that the read is complete ;
* The event demultiplexor calls the appropriate handler;
* The event handler handles the data from user defined buffer, starts a new asynchronous operation, and returns
control to the event demultiplexor.
"
可以看出,兩個模式的相同點,都是對某個IO事件的事件通知(即告訴某個模塊,這個IO操作可以進行或已經完成)。在結構
上,兩者也有相同點:demultiplexor負責提交IO操作(異步)、查詢設備是否可操作(同步),然后當條件滿足時,就回調handler。
不同點在于,異步情況下(Proactor),當回調handler時,表示IO操作已經完成;同步情況下(Reactor),回調handler時,表示
IO設備可以進行某個操作(can read or can write),handler這個時候開始提交操作。
用select模型寫個簡單的reactor,大致為:
/**////class handler
{
public:
virtual void onRead() = 0;
virtual void onWrite() = 0;
virtual void onAccept() = 0;
};
class dispatch
{
public:
void poll()
{
// add fd in the set.
//
// poll every fd
int c = select( 0, &read_fd, &write_fd, 0, 0 );
if( c > 0 )
{
for each fd in the read_fd_set
{ if fd can read
_handler->onRead();
if fd can accept
_handler->onAccept();
}
for each fd in the write_fd_set
{
if fd can write
_handler->onWrite();
}
}
}
void setHandler( handler *_h )
{
_handler = _h;
}
private:
handler *_handler;
};
/**//// applicationclass MyHandler : public handler
{
public:
void onRead()
{
}
void onWrite()
{
}
void onAccept()
{
}
};
在網上找了份Proactor模式比較正式的文檔,其給出了一個總體的UML類圖,比較全面:
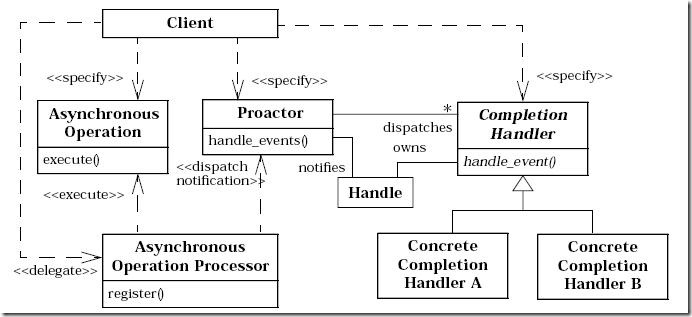
根據這份圖我隨便寫了個例子代碼:
class AsyIOProcessor
{
public:
void do_read()
{
//send read operation to OS
// read io finished.and dispatch notification
_proactor->dispatch_read();
}
private:
Proactor *_proactor;
};
class Proactor
{
public:
void dispatch_read()
{
_handlerMgr->onRead();
}
private:
HandlerManager *_handlerMgr;
};
class HandlerManager
{
public:
typedef std::list<Handler*> HandlerList;
public:
void onRead()
{
// notify all the handlers.
std::for_each( _handlers.begin(), _handlers.end(), onRead );
}
private:
HandlerList *_handlers;
};
class Handler
{
public:
virtual void onRead() = 0;
};
// application level handler.
class MyHandler : public Handler
{
public:
void onRead()
{
//
}
};
Reactor通過某種變形,可以將其改裝為Proactor,在某些不支持異步IO的系統上,也可以隱藏底層的實現,利于編寫跨平臺
代碼。我們只需要在dispatch(也就是demultiplexor)中封裝同步IO操作的代碼,在上層,用戶提交自己的緩沖區到這一層,
這一層檢查到設備可操作時,不像原來立即回調handler,而是開始IO操作,然后將操作結果放到用戶緩沖區(讀),然后再
回調handler。這樣,對于上層handler而言,就像是proactor一樣。詳細技法參見這篇文章。
其實就設計模式而言,我個人覺得某個模式其實是沒有完全固定的結構的。不能說某個模式里就肯定會有某個類,類之間的
關系就肯定是這樣。在實際寫程序過程中也很少去特別地實現某個模式,只能說模式會給你更多更好的架構方案。
最近在看spserver的代碼,看到別人提各種并發系統中的模式,有點眼紅,于是才來掃掃盲。知道什么是leader follower模式,
reactor, proactor,multiplexing,對于心中的那個網絡庫也越來越清晰。
最近還干了些離譜的事,寫了傳說中的字節流編碼,用模板的方式實現,不但保持了擴展性,還少寫很多代碼;處于效率考慮,
寫了個static array容器(其實就是template <typename _Tp, std::size_t size> class static_array { _Tp _con[size]),
加了iterator,遵循STL標準,可以結合進STL的各個generic algorithm用,自我感覺不錯。基礎模塊搭建完畢,解析了公司
服務器網絡模塊的消息,我是不是真的打算用自己的網絡模塊重寫我的驗證服務器?在另一個給公司寫的工具里,因為實在厭惡
越來越多的重復代碼,索性寫了幾個宏,還真的做到了代碼的自動生成:D。
對優雅代碼的追求真的成了種癖好. = =|