轉(zhuǎn)自:https://my.oschina.net/caicloud/blog/829365
著作權(quán)歸作者所有,轉(zhuǎn)載請自覺標(biāo)明出處,以示尊重!
大家好,我是徐超,從事 Kubernetes 開發(fā)已經(jīng)兩年多了。
今天,我從一個開發(fā)者的角度來講一講 client-go repository,以及怎么用 client-go 搭建 Controller。同時,也給大家講一講開發(fā)過程中遇到的坑,希望大家在開發(fā)的時候可以繞坑而行。
另外,我還會講一下 Kubernetes 的 API,讓 controller 功能變的更加強(qiáng)大。

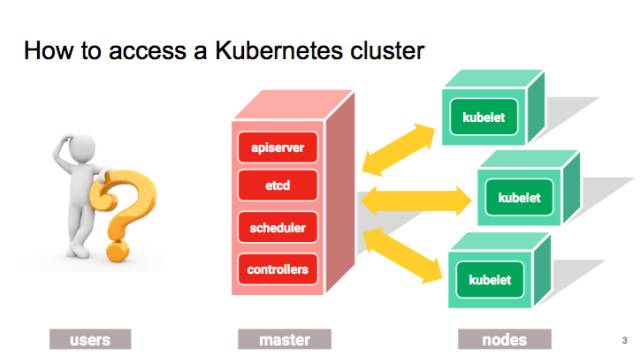
那我們現(xiàn)在先來講,有哪些方法可以跟 APIserver 進(jìn)行通訊。最常用的,可能就是 kubectl,以及官方支持的 UI,Kube Dashboard,這是 google 最近投入很多的一個項目。
開發(fā)過程中 debug 的時候可以直接去調(diào)用 k8s 的 Restful API,通過寫腳本去實現(xiàn) Controller。
但是,這些做法無論從效率還是可編程性來說都是不太令人滿意的。
這也就是為什么我們要創(chuàng)建 client-go,我們其實就是把寫 controller 所需的 clients,utilities 等都放到了 client-go 這個 repository 里面。大家如果需要寫 controller 的話,可以在這里面找到所需要的工具。client-go 是 go 語言的 client,除了 go 語言之外,我們現(xiàn)在還支持 python 的 client,目前是 beta 版本。但是這個 python client 是我們直接從 open API spec 生成的,之后我們會繼續(xù)生成 client Java 或者一些其它的語言。

我們先看一下 client library 的內(nèi)容。它主要包括各種 clients:clientset、DynamicClient 和 RESTClient。還有幫助你寫 Controller 時用到的 utilities:Workqueue 和 Informer。
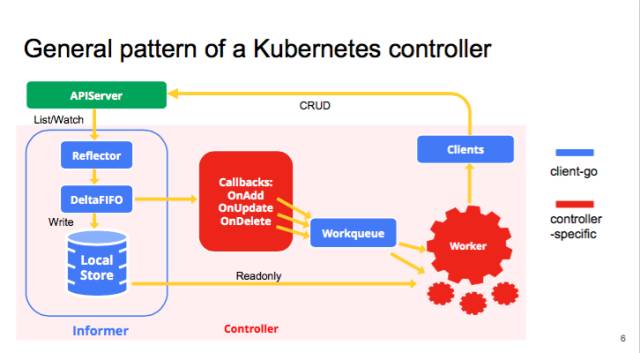
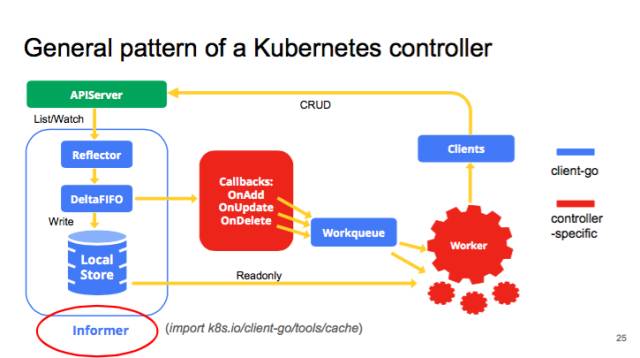
我們先看一下 kube-controller 的大致結(jié)構(gòu),典型的 controller 一般會有 1 個或者多個 informer,來跟蹤某一個 resource,跟 APIserver 保持通訊,把最新的狀態(tài)反映到本地的 cache 中。只要這些資源有變化,informal 會調(diào)用 callback。這些 callbacks 只是做一些非常簡單的預(yù)處理,把不關(guān)心的的變化過濾掉,然后把關(guān)心的變更的 Object 放到 workqueue 里面。其實真正的 business logic 都是在 worker 里面, 一般 1 個 Controller 會啟動很多 goroutines 跑 Workers,處理 workqueue 里的 items。它會計算用戶想要達(dá)到的狀態(tài)和當(dāng)前的狀態(tài)有多大的區(qū)別,然后通過 clients 向 APIserver 發(fā)送請求,來驅(qū)動這個集群向用戶要求的狀態(tài)演化。圖里面藍(lán)色的是 client-go 的原件,紅色是自己寫 controller 時填的代碼。

我們來仔細(xì)看一下各種 clients。
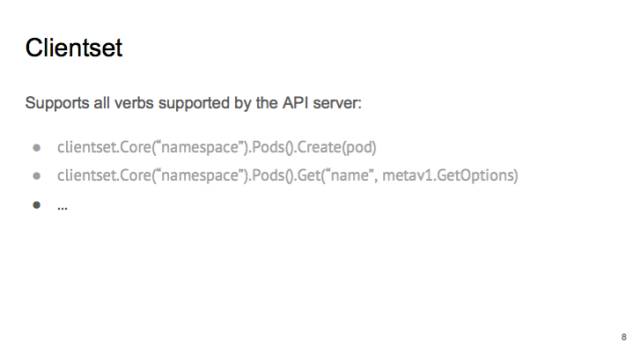
先講最常見的 Clientset,它是 k8s 中出鏡率最高的 client,用法比較簡單。先選 group,比如 core,再選具體的 resource,比如 pod 或者 job,最后在把動詞(create、get)填上。
clientset 的使用分兩種情況:集群內(nèi)和集群外。
集群內(nèi):將 controller 容器化后以 pod 的形式在集群里跑,只需調(diào)用 rest.InClusterConfig(),默認(rèn)的 service accoutns 就可以訪問 apiserver 的所有資源。
集群外,比如在本地,可以使用與 kubectl 一樣的 kube-config 來配置 clients。如果是在云上,比如 gke,還需要 import Auth Plugin。
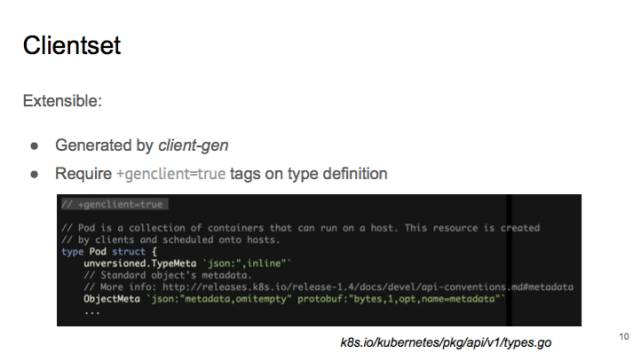
clientset 是用 client-gen 生成的。如果你打開 pkg/api/v1/tyeps.go,在 pod 的定義上有一行注釋,叫做“+genclient=true”,這句話的意思是,需要為這個 type 生成一個 client,如果之后要做自己的 API type 拓展,也可以通過這樣的方式來生成對應(yīng)的 clients。

Clientset 的動詞很多細(xì)微的地方比較燒腦,我來幫助大家理解一下。
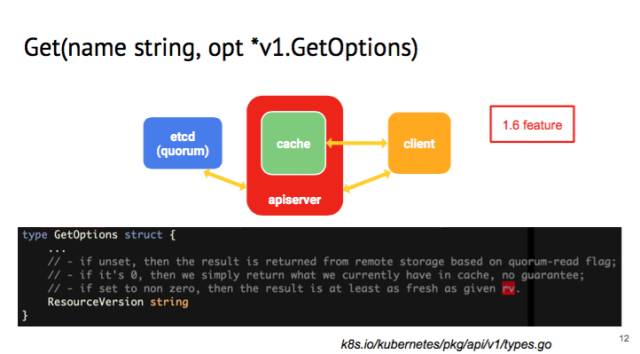
我們先來說 Get 的 GetOptions,這是 1.6 的 feature,如果在里面看 client 的 get 的話,有一個 field,叫做 resource version。
resourece version 是 kubernetes 里面一個 logical clock,用作 optimistic concurrency。如果沒有設(shè)置 resourceversion,api-server 收到請求后會從 etcd 讀出最新的值。但設(shè)為 0 的話,APIserver 就會從 local 的 cache 里面把值讀取出來,cache 的值可能會有一定的延遲。這樣可以減輕 APIserver 和 etcd 后端的壓力。現(xiàn)在是用得比較多的是 kubelet,經(jīng)常要 get node status,但是不需要最新的 node status,如果集群很大,就能夠省不少 cpu/memory 的開銷。如果 resource version 設(shè)成非常大的值,get request 會在 api-server 掛起,沒有響應(yīng)的話會 time-out。
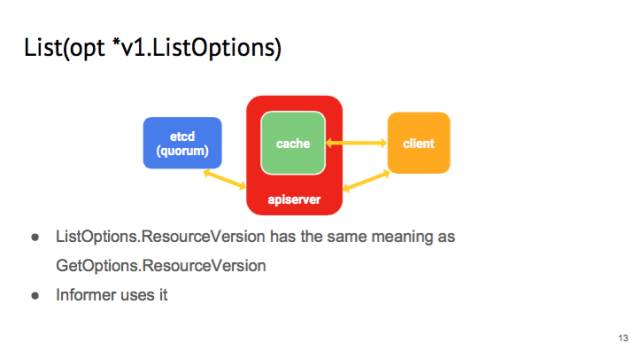
同樣的,在 list 這個操作的時候,你可以提供一個 listOption,這個 listOption 里面也有 resource version,和 get 里的意義一樣。我們在寫 informer 的時候會用到。因為每一個 controller 在啟動的時候,會向 api-server 發(fā)送 list 請求,如果每一個 request 都是從 etcd 里讀取過來的話,這個開銷非常大,所以 list 會從 api-server 的 cache 讀取。
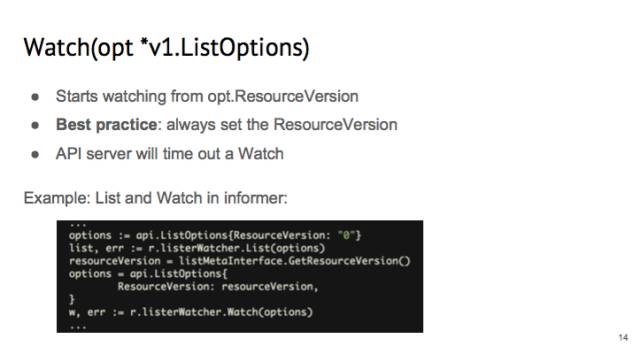
在 watch 里面也有一個 listOption,里面 resrouce version 的意義不一樣。在 watch 的時候,apiserver 會從這個 resuorce version 開始所有的變化。這里的 best practice 設(shè)置成:永遠(yuǎn)要設(shè)置 resource version。因為如果不設(shè)置,那么 APIserver 就會從 cache 里隨便的一個時間點開始推送,令 controller 的行為不好預(yù)測。
我們看 informer 是怎么使用 list 進(jìn)行 watch 的。在 informer 里面,我們一般都是先 list,把 resource version 設(shè)為 0,API Server 就可以從 cache 里面給我 list。List 完之后,把 list 的 resource version 取出來,并且設(shè)置為 watch 的 listOption,這樣就可以保證 informer 拿到的 events 是連續(xù)的。
另外要注意的是,watch 不是一勞永逸的,apiserver 會 timeout 一個 watchrequest 的,默認(rèn)值是 5~10 分鐘。這時你需要重新 watch。

說一下這個 update,client 里面有兩種 update:Update 和 UpdateStatus。
他們的區(qū)別是,如果你 Update 一個 pod,那么你對 status 的修改會被 API server overwrite 掉。UptateStatus 則相反。
k8s 有 OptimisticConcurrency 機(jī)制,如果有兩個 client 都在 update 同一個,會 fail。所以寫代碼時一般會把 update 寫到 loop 里,直到 api-server 返回 200,ok 時才確定 update 成功。
另外,使用 get+update 有一個 bug:假設(shè) cluster 的 pod 有一個新的 field,如果你使用一個舊的 client,它不知道這個新的 field,那么 get 到的 pod 是沒有這個新的 field 的,再 update 的時候,這個新的 field 會被覆蓋掉。
可能會在 1.7 的時候把這個 bug 處理掉。
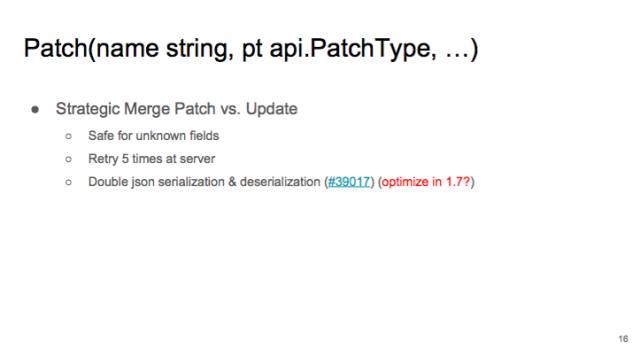
跟 update 相對應(yīng)的就是 patch。Update 像拆遷隊,只會把整個 object 推倒重做。Patch 則像手術(shù)刀,可以做精細(xì)操作,可以精確修改一個 object 的 field。
patch 如果有 conflicts,會在 apiserver 重試 5 次。除非有用戶 patch 同一個 field,否則一般 client 會一次 patch 成功。當(dāng)然 patch 有性能問題,因為要在 API serve 做 Json serialiation 和 deserialization。我們估計會在 1.7 的時候優(yōu)化。如果不關(guān)心性能,我們還是推薦用 patch。
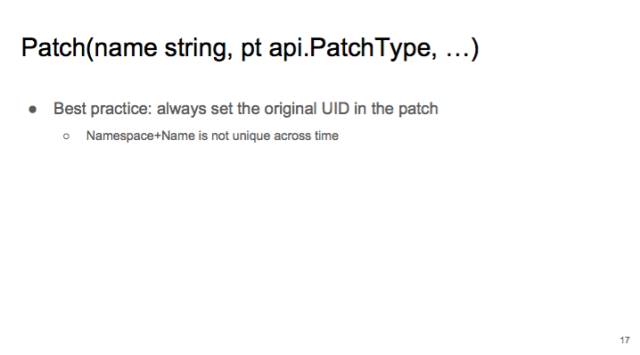
提醒一下:你在做 Patch 的時候,最佳實踐是把 original 的 UID 填在 patch 里。因為 API server 的 key-value store 是以“namespace + name”作為 key 的。在任意一個時間,這個組合都是唯一的。但是如果把時間這條軸加進(jìn)來的話,比如你有一個 pod,刪除后過了一會兒,又在同一個 namespace 下建了同名的 pod,但是把所有的 spec 都改掉了,那么 controller 舊的 patch 可能會被應(yīng)用到這個新建的 pod 上,這樣就會有 bug 了。如果在 patch 里加入 uid 的話,一旦發(fā)生剛才所說的情況,apiserver 會以為你是要修改 uid,這個是不允許的,所以這個 patch 就會 fail 掉,防止了 bug。
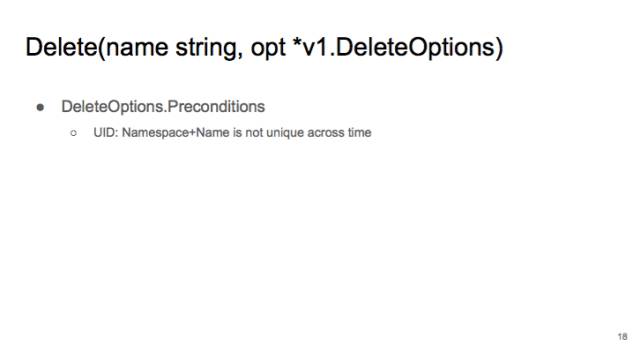
Delete Option,有一個選項叫 precondition,它有一個 uid 選項。也是為了防止 namespace+name 的組合在時間軸上不唯一。
當(dāng)時,我們發(fā)現(xiàn) K8S 的 CI tests 經(jīng)常會莫名其妙的 fail 掉。最后我發(fā)現(xiàn)是因為剛 create 的 pod 跟之前已經(jīng)被刪除的 pod 重名,但是 kubelet 不知道,就把新的 pod 給誤刪除了。所以我們 delete 的時候,這個 precondition 的 UID 請勿刪除。

Delete 從 1.4 開始有一個 field 叫做 OrphanDependents。如果設(shè)為 true 或者 unset 的話,當(dāng) delete()返回的時候,這個 object 可能會在繼續(xù)存在一會兒,雖然最終還是會被刪掉。另外,這個時候,如果你把 OrphanDependents 設(shè)置成 true 或者不設(shè)置的話,要刪除的 Dependents 是不會被刪除的。如果設(shè)成 false,只要 delete()返回了,這個 object 就肯定已經(jīng)在 apiserver 上被刪掉了,除非你另外設(shè)置了 finalizer。并且 garbage collector 會在背景里面慢慢刪除 dependents。


現(xiàn)在講一下另外一種 client,叫做 dynamic client。
dynamic client 用法比較靈活。因為你可以任意設(shè)置要操作的 resource。它的 return value,不是一個 structure,而是 map[string]interface{}。如果一個 controller 需要控制所有 API,比如 namespace controller 或者 garbage collector,那就用 dynamic client。使用時可以先通過 discovery,發(fā)現(xiàn)有哪些 API,再通過使用 dynamic client access 所有的 api。dynamic client 也支持 third party resources。
dynamic client 的缺點是它只支持 JSON 一種序列化。而 JSON 的效率遠(yuǎn)遠(yuǎn)低于 proto buf。


現(xiàn)在我們講一下 rest client。
Rest Client 是 client 和 dynamic client 的基礎(chǔ)。屬于比較底層的,跟 dynamic client 一樣,你可以使用它操作各種 resource。支持 Do() 和 DoRaw。
相比 dynamic client,支持 protobuf 和 json。效率會比較高。
但是問題就是,如果你要 access third party resource,需要自己寫反序列化,不能直接 decode 到 type。在 demo 里會進(jìn)行演示。
現(xiàn)在我們講 informer,它的 input 其實就兩個,一是要 list function 和 watch function,二是你要給 informer 提供一些 callback。informer 跑起來后,它會維護(hù) localstore。你之后就可以直接訪問 localstore,而不用跟 APIserver 通訊。提高一些 performance。
使用 informer 的好處一個是性能比較好,還有一個是可靠性。如果有 network partition,informer 后會從斷點開始繼續(xù) watch,它不會錯過任何 event 的。
Informer 也有一些 best practice,第一點,在 controller run 之前,最好等這些 informer 都 sync 了(初始化)。這樣做,一是可以避免 controller 初始化時的 churn:比如 replica set controller 要 watch replica set 和 pod,如果不 sync 就開始 run,controller 會以為現(xiàn)在沒有任何 pod,會創(chuàng)建很多不必要的 pod,之后還要刪除。二來就是會避免很多很詭異的 bug。我在寫 garbage collector 的時候就遇到過不少。
另外 informer 提供的 localcache 是 read-only 的。如果要修改,先用 DeepCopy 拷貝出來,否則可能有 read-write race。并且你的 cache 可能是和其他 controller 共享的,修改 cache 會影響其他 controller。
第三個要注意的地方就是,informer 傳遞給 callbacks 的 object 不一定是你所期待的 type。比如 informer 追蹤所有 pod,返回的 Object 可能不是 pod,而是 DeletedFinalStateUnknown。所以在處理 delete 的時候,除了要處理原來跟蹤的 object,還要處理 DeletedFinalStateUnknown。
最后要講一下的就是,informer 的 resyncoption。它只是周期性地把所有的 local cache 的東西重新放到 FIFO 里。并不是說把 APIserver 上所有的最新狀態(tài)都重新 list 一遍。這個 option 大家一般都是不會用到的,可以放心大膽地把這個 resync period 設(shè)成 0。
最后再講一下這個 workqueue。
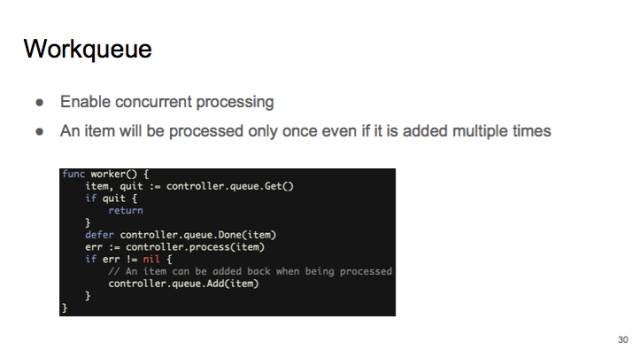
其實主要是為了可以 concurrent processing,可以并行地讓 Callbacks 把狀態(tài)加到 workqueue 里,然后起一大堆的 worker。
workqueue 提供的一個保障就是,如果是同一個object,比如同一個 pod,被多次加到 workqueue 里,在 dequeue 時,它只會出現(xiàn)一次。防止會有同一個 object 被多個 worker 同時處理。

另外 workqueue 還有一些非常有用的 feature。比如說 rate limited: 如果你從 workqueue 里面拿出一個 object,處理時發(fā)生了錯誤,重新放回了 workqueue。這時,workqueue 保證這個 object 不會被立刻重新處理,防止 hot loop。
另外的一個 feature 就是提供 prometheus 監(jiān)控。你可以實時監(jiān)控 queue 的長度,延遲等。你可以監(jiān)控 queue 的處理速度是否跟得上。

現(xiàn)在我給大家做一個 demo(https://github.com/caesarxuchao/servicelookup)。通過 k8s 的 api 用戶是沒辦法很快通過 pod 的名字找到對應(yīng)的 service 的。當(dāng)然你可以找到這個 pod 的 label,然后去跟 selector 進(jìn)行比較而確定 service,但做這種逆向查詢是非常費時間的。
所以我這里就是寫了這樣一種 controller,watch 所有的 endpoints 和 pods,來做比對,找到 pod 服務(wù)的 service。

我先啟動兩個 informer,1 個 informer 是追蹤所有 pods 的變化,另一個追蹤所有 endpoints 變化。

給 informer 注冊 callback,來把 pod 和 endpoint 的變化放到 workqueue。

然后啟動許多 worker,從 workquue 里拿出 pod 和 endpoint 做比對。
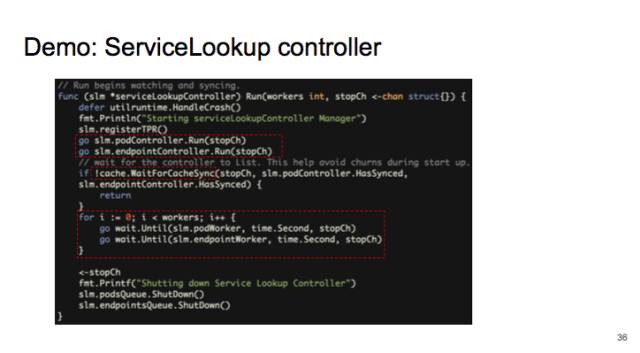
運行時,先啟動兩個 informer,等它們 sync,最后啟動 worker。
Demo 的代碼在 github 上,https://github.com/caesarxuchao/servicelookup。
視頻鏈接:http://v.qq.com/iframe/player.html?vid=c03641vzw2m&width=670&height=502.5&auto=0
posted on 2017-01-23 17:06
思月行云 閱讀(568)
評論(0) 編輯 收藏 引用 所屬分類:
Docker\K8s