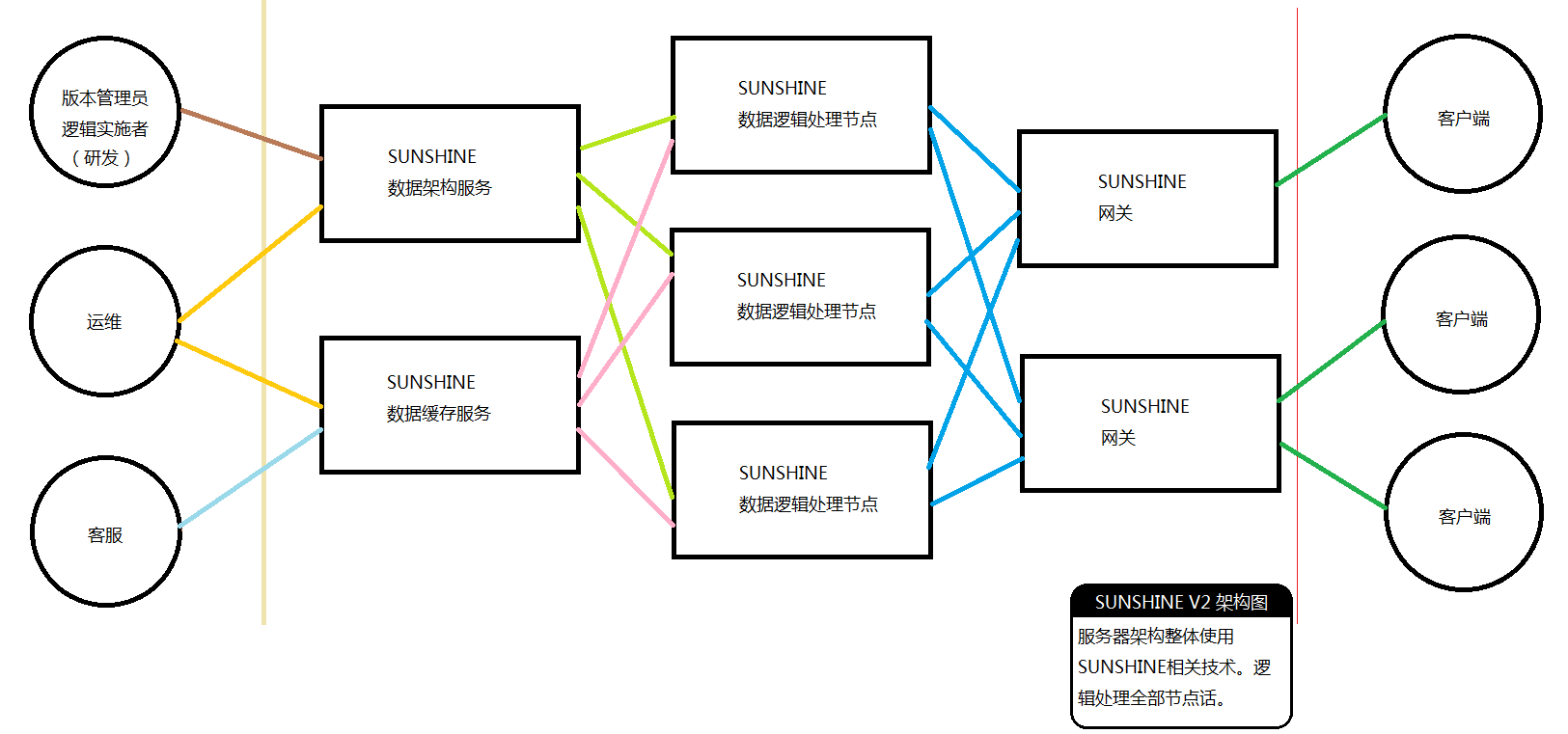
PROJECT SUNSHINE(日光)
數據字段類型:
有/無符號整數(32/64)
單精度浮點數
雙精度浮點數
【數據協議】引用
字符串
容器(可用于所有以上類型)
鍵索引容器
線性數組
ID分配與索引容器
ID分配與索引以及鍵值互斥和索引容器
概念:
【數據協議】
用于描述一個抽象的數據聚合,這個聚合里包含各種屬性,以及屬性的類型、名字、唯一ID和缺省值。
【數據類】
用于描述一個具體的數據聚合體,確定了該聚合體將實現那些數據協議中的字段(字段集),并覆蓋哪些字段的缺省值(覆蓋集)。
它的數據描述依賴于【數據協議】。
【數據對象】
從數據類生成的一個擁有數據類描述的字段的一個內存塊。實際用于數據聚合體在內存中的實例存在。
內存塊初始化時為一頁,可以容納整個數據類描述的字段。
在新加入數據字段時,實時分配最小可容納的頁,作為增長需要。如一頁超過初始頁面大小,則生成新的頁面。
【數據字段存儲管理器】
幫助數據對象規劃內存塊中的字段分布,以適應數據類和數據協議的改動。
每次進行數據類和數據協議的改動時,將生成擁有如下指令的更改腳本:
1- 斷開某字段與其內存塊位置的連接
2- 連接新的字段與原有的斷開連接的內存塊位置,或者分配新的內存塊位置。
3- 檢查數據對象的內存塊的某一頁,如果全部被斷開連接,則該頁從數據對象中回收。
【數據處理器】
用于描述一個具體的數據處理方法。
它以【數據協議】作為它的輸入輸出參數表。
它會對其中的字段做附加的描述,如缺省值覆蓋,輸入、輸出、輸入輸出或者不使用(不使用默認輸出缺省值)
而且,它其中包含有一系列的邏輯操作和計算操作,用于通過輸入內容生成輸出內容。
【統一對象模型】
通過【數據協議】來進行處理方法和對象描述的統一,就稱為在Sunshine中的【同一對象模型】。
數據處理器中的部分術語:
【元素】
一個【數據協議】的實現者,用于在處理流程圖中進行流程描述,以及輸入輸出。
【協議展開】
將【數據協議】中的【數據協議引用】字段展開成【數據協議】的元素,以供輸入輸出。
【執行域】
在進行邏輯判斷時,需要改變方法的執行方向時,采用的一種將區域的元素著色,以生成一個執行方向的方法。
【數據轉換】
在處理流程圖中,為了流程圖的整體性全局性,在連接不同類型的輸入輸出時,將進行數據轉換。
當遇到不兼容的數據轉換,將會產生一個轉換警告,并使用目標輸入上的缺省值,以期望處理流程可以繼續執行。
【全局對象引用】
用于將預定義的全局對象引用,導入到流程圖中使用。(置于流程圖的TOP位置,輸入置于流程圖的LEFT位置,輸出置于流程圖的RIGHT位置)
數據協議可能出現的實現者:
1- 數據類
2- 數據處理器
3- 底層組件(用C\C++\C#實現的底層組件,用于SUNSHINE和底層的交互)
A- 數據庫映射
B- 網絡封包
C- 數據源(XML)
D- 復雜算法的計算密集型處理
E- 除以上列出外的其他暫未預料到的處理
SUNSHINE的入口點
1- 初始化的入口點,SUNSHINE將執行一個全局的初始化。
2- 事件入口點,SUNSHINE所有的日常數據處理的執行都源于事件入口點。
事件入口點由SUNSHINE使用者和底層提供者預先商定一個【數據協議】
然后由SUNSHINE使用者通過【數據協議】創建預定名字的【數據處理器】
底層提供者在事件發生時,依照【數據協議】調用預定名字的【數據處理器】
3- 結束入口點,SUNSHINE將執行全局的對象回收。