十四、排序(Sort)
這可能是最有趣的一節。排序的考題,在各大公司的筆試里最喜歡出了,但我看多數考得都很簡單,通常懂得冒泡排序就差不多了,確實,我在剛學數據機構時候,覺得冒泡排序真的很“精妙”,我怎么就想不出呢?呵呵,其實冒泡通常是效率最差的排序算法,差多少?請看本文,你一定不會后悔的。
1、冒泡排序(Bubbler Sort)
前面剛說了冒泡排序的壞話,但冒泡排序也有其優點,那就是好理解,穩定,再就是空間復雜度低,不需要額外開辟數組元素的臨時保存控件,當然了,編寫起來也容易。
其算法很簡單,就是比較數組相鄰的兩個值,把大的像泡泡一樣“冒”到數組后面去,一共要執行N的平方除以2這么多次的比較和交換的操作(N為數組元素),其復雜度為Ο(n²),如圖:

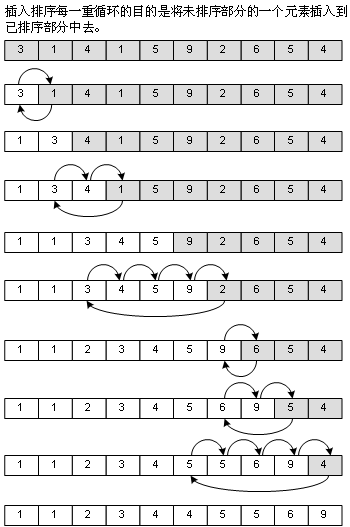
2、直接插入排序(Straight Insertion Sort)
冒泡法對于已經排好序的部分(上圖中,數組顯示為白色底色的部分)是不再訪問的,插入排序卻要,因為它的方法就是從未排序的部分中取出一個元素,插入到已經排好序的部分去,插入的位置我是從后往前找的,這樣可以使得如果數組本身是有序(順序)的話,速度會非常之快,不過反過來,數組本身是逆序的話,速度也就非常之慢了,如圖:
3、二分插入排序(Binary Insertion Sort)
這是對直接插入排序的改進,由于已排好序的部分是有序的,所以我們就能使用二分查找法確定我們的插入位置,而不是一個個找,除了這點,它跟插入排序沒什么區別,至于二分查找法見我前面的文章(本系列文章的第四篇)。圖跟上圖沒什么差別,差別在于插入位置的確定而已,性能卻能因此得到不少改善。(性能分析后面會提到)
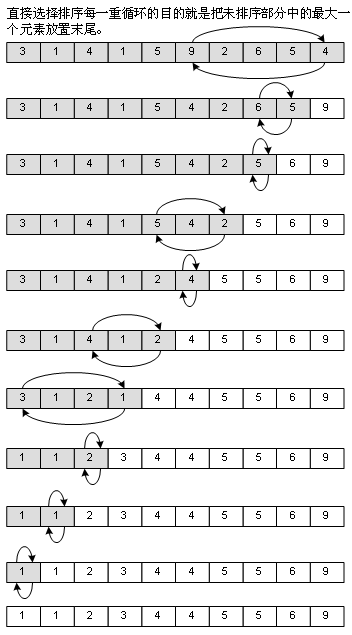
4、直接選擇排序(Straight Selection Sort)
這是我在學數據結構前,自己能夠想得出來的排序法,思路很簡單,用打擂臺的方式,找出最大的一個元素,和末尾的元素交換,然后再從頭開始,查找第1個到第N-1個元素中最大的一個,和第N-1個元素交換……其實差不多就是冒泡法的思想,但整個過程中需要移動的元素比冒泡法要少,因此性能是比冒泡法優秀的。看圖:
5、快速排序(Quick Sort)
快速排序是非常優秀的排序算法,初學者可能覺得有點難理解,其實它是一種“分而治之”的思想,把大的拆分為小的,小的再拆分為更小的,所以你一會兒從代碼中就能很清楚地看到,用了遞歸。如圖:
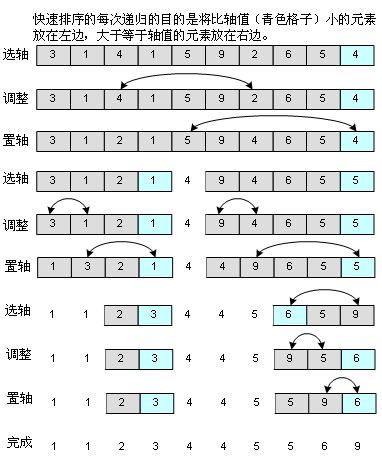
其中要選擇一個軸值,這個軸值在理想的情況下就是中軸,中軸起的作用就是讓其左邊的元素比它小,它右邊的元素不小于它。(我用了“不小于”而不是“大于”是考慮到元素數值會有重復的情況,在代碼中也能看出來,如果把“>=”運算符換成“>”,將會出問題)當然,如果中軸選得不好,選了個最大元素或者最小元素,那情況就比較糟糕,我選軸值的辦法是取出第一個元素,中間的元素和最后一個元素,然后從這三個元素中選中間值,這已經可以應付絕大多數情況。
6、改進型快速排序(Improved Quick Sort)
快速排序的缺點是使用了遞歸,如果數據量很大,大量的遞歸調用會不會導致性能下降呢?我想應該會的,所以我打算作這么種優化,考慮到數據量很小的情況下,直接選擇排序和快速排序的性能相差無幾,那當遞歸到子數組元素數目小于30的時候,我就是用直接選擇排序,這樣會不會提高一點性能呢?我后面分析。排序過程可以參考前面兩個圖,我就不另外畫了。
7、桶排序(Bucket Sort)
這是迄今為止最快的一種排序法,其時間復雜度僅為Ο(n),也就是線性復雜度!不可思議吧?但它是有條件的。舉個例子:一年的全國高考考生人數為500萬,分數使用標準分,最低100,最高900,沒有小數,你把這500萬元素的數組排個序。我們抓住了這么個非常特殊的條件,就能在毫秒級內完成這500萬的排序,那就是:最低100,最高900,沒有小數,那一共可出現的分數可能有多少種呢?一共有900-100+1=801,那么多種,想想看,有沒有什么“投機取巧”的辦法?方法就是創建801個“桶”,從頭到尾遍歷一次數組,對不同的分數給不同的“桶”加料,比如有個考生考了500分,那么就給500分的那個桶(下標為500-100)加1,完成后遍歷一下這個桶數組,按照桶值,填充原數組,100分的有1000人,于是從0填到999,都填1000,101分的有1200人,于是從1000到2019,都填入101……如圖:
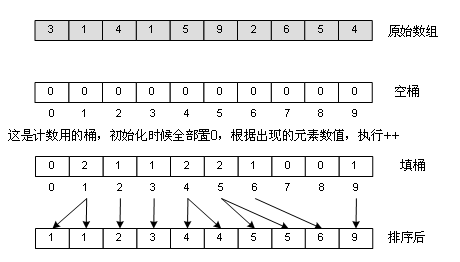
很顯然,如果分數不是從100到900的整數,而是從0到2億,那就要分配2億個桶了,這是不可能的,所以桶排序有其局限性,適合元素值集合并不大的情況。
8、基數排序(Radix Sort)
基數排序是對桶排序的一種改進,這種改進是讓“桶排序”適合于更大的元素值集合的情況,而不是提高性能。它的思想是這樣的,比如數值的集合是8位整數,我們很難創建一億個桶,于是我們先對這些數的個位進行類似桶排序的排序(下文且稱作“類桶排序”吧),然后再對這些數的十位進行類桶排序,再就是百位……一共做8次,當然,我說的是思路,實際上我們通常并不這么干,因為C++的位移運算速度是比較快,所以我們通常以“字節”為單位進行桶排序。但下圖為了畫圖方便,我是以半字節(4 bit)為單位進行類桶排序的,因為字節為單位進行桶排得畫256個桶,有點難畫,如圖:
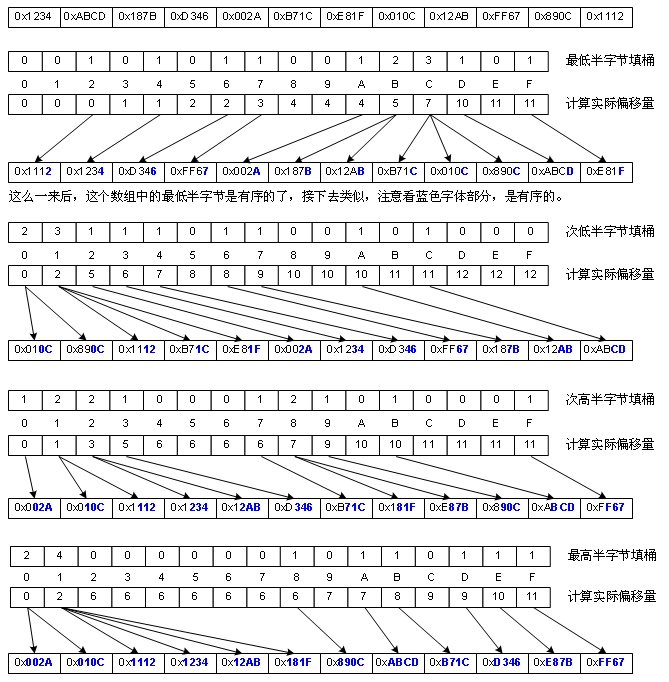
基數排序適合數值分布較廣的情況,但由于需要額外分配一個跟原始數組一樣大的暫存空間,它的處理也是有局限性的,對于元素數量巨大的原始數組而言,空間開銷較大。性能上由于要多次“類桶排序”,所以不如桶排序。但它的復雜度跟桶排序一樣,也是Ο(n),雖然它用了多次循環,但卻沒有循環嵌套。
9、性能分析和總結
先不分析復雜度為Ο(n)的算法,因為速度太快,而且有些條件限制,我們先分析前六種算法,即:冒泡,直接插入,二分插入,直接選擇,快速排序和改進型快速排序。
我的分析過程并不復雜,嘗試產生一個隨機數數組,數值范圍是0到7FFF,這正好可以用C++的隨機函數rand()產生隨機數來填充數組,然后嘗試不同長度的數組,同一種長度的數組嘗試10次,以此得出平均值,避免過多波動,最后用Excel對結果進行分析,OK,上圖了。
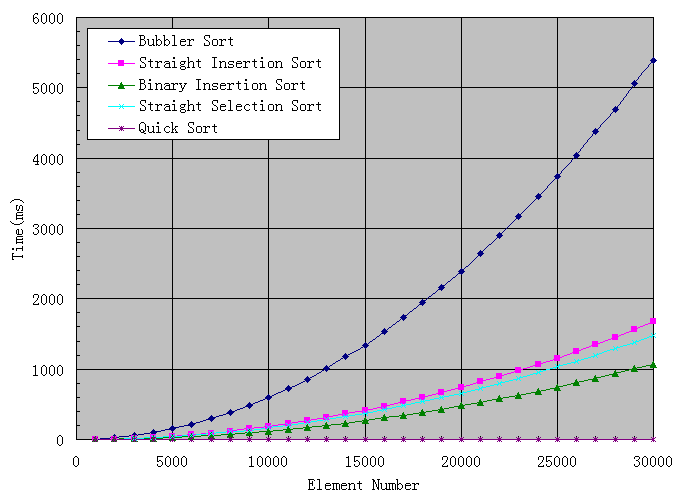
最差的一眼就看出來了,是冒泡,直接插入和直接選擇旗鼓相當,但我更偏向于使用直接選擇,因為思路簡單,需要移動的元素相對較少,況且速度還稍微快一點呢,從圖中看,二分插入的速度比直接插入有了較大的提升,但代碼稍微長了一點點。
令人感到比較意外的是快速排序,3萬點以內的快速排序所消耗的時間幾乎可以忽略不計,速度之快,令人振奮,而改進型快速排序的線跟快速排序重合,因此不畫出來。看來要對快速排序進行單獨分析,我加大了數組元素的數目,從5萬到150萬,畫出下圖:
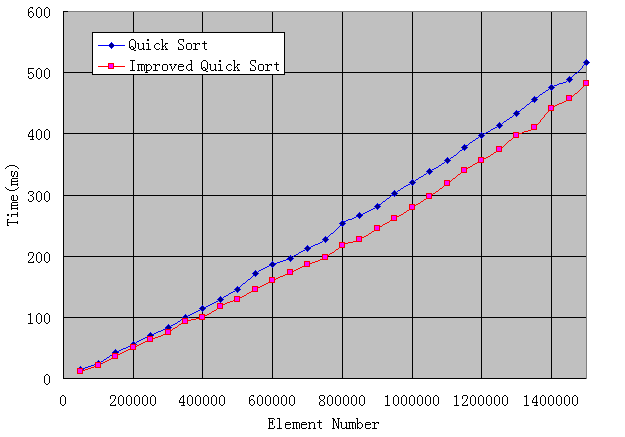
可以看到,即便到了150萬點,兩種快速排序也僅需差不多半秒鐘就完成了,實在快,改進型快速排序性能確實有微略提高,但并不明顯,從圖中也能看出來,是不是我設置的最小快速排序元素數目不太合適?但我嘗試了好幾個值都相差無幾。
最后看線性復雜度的排序,速度非常驚人,我從40萬測試到1200萬,結果如圖:
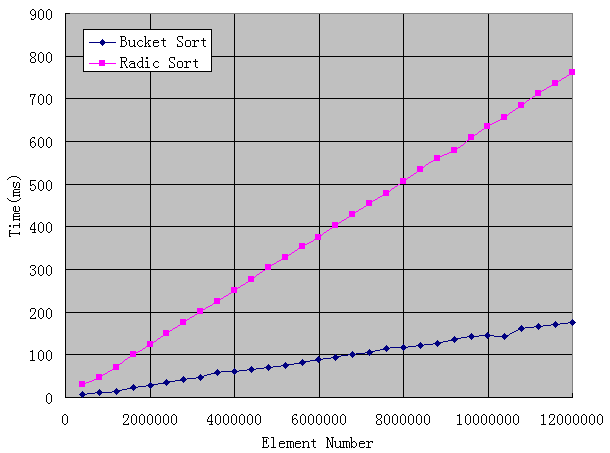
可見稍微調整下算法,速度可以得到質的飛升,而不是我們以前所認為的那樣:再快也不會比冒泡法快多少啊?
我最后制作一張表,比較一下這些排序法:
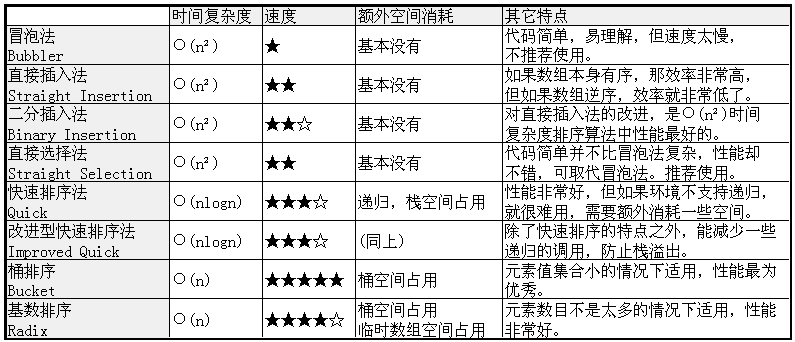
還有一個最后:附上我的代碼。
#include "stdio.h"
#include "stdlib.h"
#include "time.h"
#include "string.h"
void BubblerSort(int *pArray, int iElementNum);
void StraightInsertionSort(int *pArray, int iElementNum);
void BinaryInsertionSort(int *pArray, int iElementNum);
void StraightSelectionSort(int *pArray, int iElementNum);
void QuickSort(int *pArray, int iElementNum);
void ImprovedQuickSort(int *pArray, int iElementNum);
void BucketSort(int *pArray, int iElementNum);
void RadixSort(int *pArray, int iElementNum);
//Tool functions.
void PrintArray(int *pArray, int iElementNum);
void StuffArray(int *pArray, int iElementNum);
inline void Swap(int& a, int& b);
#define SINGLE_TEST
int main(int argc, char* argv[])
{
srand(time(NULL));
#ifndef SINGLE_TEST
int i, j, iTenTimesAvg;
for(i=50000; i<=1500000; i+=50000)
{
iTenTimesAvg = 0;
for(j=0; j<10; j++)
{
int iElementNum = i;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
ImprovedQuickSort(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctEnd = clock();
delete[] pArr;
iTenTimesAvg += ctEnd-ctBegin;
}
printf("%d\t%d\n", i, iTenTimesAvg/10);
}
#else
//Single test
int iElementNum = 100;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
QuickSort(pArr, iElementNum);
clock_t ctEnd = clock();
PrintArray(pArr, iElementNum);
delete[] pArr;
int iTenTimesAvg = ctEnd-ctBegin;
printf("%d\t%d\n", iElementNum, iTenTimesAvg);
#endif
return 0;
}
void BubblerSort(int *pArray, int iElementNum)
{
int i, j, x;
for(i=0; i<iElementNum-1; i++)
{
for(j=0; j<iElementNum-1-i; j++)
{
if(pArray[j]>pArray[j+1])
{
//Frequent swap calling may lower performance.
//Swap(pArray[j], pArray[j+1]);
//Do you think bit operation is better? No! Please have a try.
//pArray[j] ^= pArray[j+1];
//pArray[j+1] ^= pArray[j];
//pArray[j] ^= pArray[j+1];
//This kind of traditional swap is the best.
x = pArray[j];
pArray[j] = pArray[j+1];
pArray[j+1] = x;
}
}
}
}
void StraightInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
for(j=i; j>0; j--)
{
if(iHandling>=pArray[j-1])
break;
}
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void BinaryInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
int iLeft = 0;
int iRight = i-1;
while(iLeft<=iRight)
{
int iMiddle = (iLeft+iRight)/2;
if(iHandling < pArray[iMiddle])
{
iRight = iMiddle-1;
}
else if(iHandling > pArray[iMiddle])
{
iLeft = iMiddle+1;
}
else
{
j = iMiddle + 1;
break;
}
}
if(iLeft>iRight)
j = iLeft;
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void StraightSelectionSort(int *pArray, int iElementNum)
{
int iEndIndex, i, iMaxIndex, x;
for(iEndIndex=iElementNum-1; iEndIndex>0; iEndIndex--)
{
for(i=0, iMaxIndex=0; i<iEndIndex; i++)
{
if(pArray[i]>=pArray[iMaxIndex])
iMaxIndex = i;
}
x = pArray[iMaxIndex];
pArray[iMaxIndex] = pArray[iEndIndex];
pArray[iEndIndex] = x;
}
}
void BucketSort(int *pArray, int iElementNum)
{
//This is really buckets.
int buckets[RAND_MAX];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[pArray[i]-1];
}
int iAdded = 0;
for(i=0; i<RAND_MAX; i++)
{
while((buckets[i]--)>0)
{
pArray[iAdded++] = i;
}
}
}
void RadixSort(int *pArray, int iElementNum)
{
int *pTmpArray = new int[iElementNum];
int buckets[0x100];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[(pArray[i])&0xFF];
}
//Convert number to offset
int iPrevNum = buckets[0];
buckets[0] = 0;
int iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pTmpArray[buckets[(pArray[i])&0xFF]++] = pArray[i];
}
//////////////////////////////////////////////////////////////////////////
memset(buckets, 0, sizeof(buckets));
for(i=0; i<iElementNum; i++)
{
++buckets[(pTmpArray[i]>>8)&0xFF];
}
//Convert number to offset
iPrevNum = buckets[0];
buckets[0] = 0;
iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pArray[buckets[((pTmpArray[i]>>8)&0xFF)]++] = pTmpArray[i];
}
delete[] pTmpArray;
}
void QuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>1)
QuickSort(pArray, iLeft);
if(iElementNum-iLeft-1>=1)
QuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void ImprovedQuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>30)
ImprovedQuickSort(pArray, iLeft);
else
StraightSelectionSort(pArray, iLeft);
if(iElementNum-iLeft-1>=30)
ImprovedQuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
else
StraightSelectionSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void StuffArray(int *pArray, int iElementNum)
{
int i;
for(i=0; i<iElementNum; i++)
{
pArray[i] = rand();
}
}
void PrintArray(int *pArray, int iElementNum)
{
int i;
for(i=0; i<iElementNum; i++)
{
printf("%d ", pArray[i]);
}
printf("\n\n");
}
void Swap(int& a, int& b)
{
int c = a;
a = b;
b = c;
}