位圖這個概念對于計算機圖形學來說是個至關重要的概念��,我們在屏幕上看到的任何東西�,對計算機來說,其實都是位圖�,簡單地說��,無論你是想顯示文字,還是線條�,抑或bmp�,png��,jpg和gif等圖像文件�,最終都是要直接或間接轉變為計算機顯示設備所認識的位圖����,才能顯示在屏幕上��。
我最近接手了一個項目����,是Windows Mobile平臺的��,主要做UI美化��,貼圖是其中的一大塊,我遇到的最大的問題就是貼圖的效率問題��,如何將一張內存里的圖片高效繪制出來��,實現平滑流暢的UI動畫效果�。我嘗試了許多辦法��,甚至DirectDraw����,但我發覺在硬件不支持的情況下�,DirectDraw除了讓代碼變得更復雜之外,沒有任何優點��。好����,接下去我們來分析一下如何盡量發揮GDI的威力。
跟貼圖相關的函數有幾個:
BitBlt:最基本的塊傳輸函數����。
StretchBlt:比同BitBlt����,它支持圖像的拉伸和壓縮�,當不需要拉伸和壓縮時候����,它的效果和BitBlt并無二致。
TransparentBlt:比同StretchBlt,它多了個“摳色”(Color Keying)功能,能把某種顏色或者某個范圍的顏色摳去而不作塊傳輸處理,以此來繪制不規則圖像。
AlphaBlend:比同StretchBlt����,它支持Alpha混合�,即“半透明”效果�,效果比簡單的“摳色”更好。
這幾個函數是一個比一個強,但也意味著效率一個比一個低�,總體上看差不多是這樣的��,運算量越大,當然就越慢,但測試下來發覺這其實并不絕對����,后面會提到����。
了解了這幾個函數之后�,我們開始加載一張圖片來觀察效果,我準備的是一張320*320的png圖片,利用Windows Mobile 6.0提供的IImage接口來加載它��,并把它轉變為位圖����,獲得HBITMAP。加載png的代碼可以通過搜索引擎搜索“IImage用法”等關鍵詞來獲取,此處略過�。
加載好圖片后��,創建一個和設備顯示設備兼容的DC(Device Context),選入上面加載的位圖�,用BitBlt繪制��,代碼如下(為簡潔起見�,只貼出關鍵代碼�,并且不考慮資源釋放):
HDC hWndDC = GetDC(hWnd);
HDC hMemDC = CreateCompatibleDC(hWndDC);
SelectObject(hMemDC, hBitmap); //hBitmap是前面加載的圖片
BitBlt(hWndDC, 0, 0, iWidth, iHeight, hMemDC, 0, 0, SRCCOPY);
我們通過添加一些debug代碼來觀察BitBlt的執行時間,在我的模擬器上大約是50 - 60ms�,我發覺這個速度并不快,按道理說,BitBlt應該可以在極短的時間之內完成的(1 - 2ms),也只有這樣才能實現“流暢”的UI動畫效果�,否則圖一旦多起來�,豈不是更慢��。
我嘗試修改BitBlt的最后一個參數�,我發覺換成NOTSRCCOPY�,速度更慢,變成了70多ms,說明運算量更大了,這不是簡單的內存拷貝����;而當我把最后一個參數換成BLACKNESS或者WHITENESS的時候�,速度則很快����,1ms-2ms即可完成,很顯然,對BitBlt來說��,把目標全部置為黑色或者白色��,運算量遠少于像素傳送����。在實驗的時候把BitBlt替換為另外的幾個函數��,效果和預期的相差不大�,如果圖像需要拉伸�,則執行得更慢一些,但如果圖像不是拉伸�,而是壓縮�,即縮小顯示��,執行速度居然比較快��,有些意外,這是因為壓縮后圖像變小�,需要傳輸的像素變少的緣故��。
我考慮如何提高繪圖效率,經過很多次嘗試,終于有所突破��,我最后發現:如果先把位圖存放在一個和DC兼容的位圖中�,再用這個位圖對目標設備進行像素傳輸,速度十分理想。代碼:
HDC hWndDC = GetDC(hWnd);
HDC hMemDC = CreateCompatibleDC(hWndDC);
HDC hMemDCToLoad = CreateCompatibleDC(hWndDC);
HBITMAP hMemBmp = CreateCompatibleBitmap(hWndDC, iWidth, iHeight); // The compatible bitmap
HGDIOBJ hOldBmp = SelectObject(hMemDC, hMemBmp);
SelectObject(hMemDCToLoad, hBitmap);
BitBlt(hMemDC, 0, 0, iWidth, iHeight, hMemDCToLoad, 0, 0, SRCCOPY); //Do this in initialization
BitBlt(hWndDC, 0, 0, iWidth, iHeight, hMemDC, 0, 0, SRCCOPY); //This BitBlt's speed is very fast
第一次調用BitBlt����,可以看作是初始化,我們計算第二個BitBlt的耗時����,只有1 - 2ms�,非常不錯��,經過分析�,我認為原因應該是這樣(不一定全對�,如有不妥請讀者指出):
只有在位圖格式完全一致的情況下,BitBlt才能執行真正的內存拷貝��,否則是要經過轉換的����,轉換是需要消耗CPU時間的,所以慢��。
那如何知道位圖的格式呢��?用GetObject可以看出來:
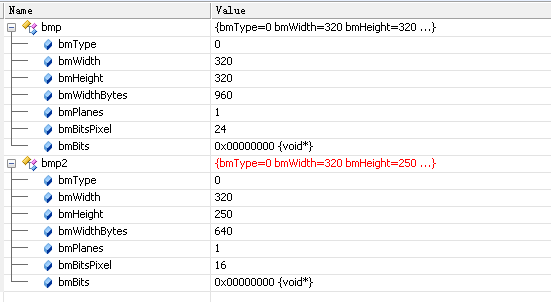
如上圖所示��,bmp是從png文件加載進來的位圖的信息,而bmp2是用CreateCompatibleBitmap創建的位圖的信息����,從這我們能看到����,前者是24bit位圖�,即一個像素用3個字節表示,而后者是16bit位圖��,一個像素用兩個字節來表示�,這個BitBlt執行過程中,就需要轉換了����,因此耗時��。而實際上位圖的差別可能比這個還要復雜些,如果再討論設備無關位圖����,那就說不完了……
總而言之����,為了提高效率��,我們要想方設法把加載進來的位圖轉變為設備兼容位圖�,繪制的時候直接BitBlt這些設備兼容位圖��,來實現位圖的高效繪制��。
前面討論的主要是BitBlt,那對于別的幾個Blt函數呢�?我都嘗試過了��,除了AlphaBlend之外,兼容位圖到設備的Blt速度上都有顯著的提高����,而AlphaBlend則無法正常工作�,因為兼容位圖不帶Alpha通道��,而AlphaBlend貌似需要32bit的ARGB格式的位圖方可正常工作�,這個問題我思考了好久都無解����,如果哪位讀者對提高AlphaBlend的工作效率有心得,不妨跟我聯系下�,我正急需這方面的技術資料����。
因此��,我給出這樣的結論,階段性結論:從文件(或資源)加載位圖后,把位圖轉為設備兼容位圖����,這樣使得BitBlt在執行SRCCOPY的時候直接使用內存拷貝�,速度很快��,即便需要拉伸壓縮或者摳色等運算����,使用兼容位圖的速度也是相當不錯的�,而使用AlphaBlend的時候,如果需要較高的效率,就應從設計上避免繪制大幅位圖��,改用小幅位圖����,在不必要對每一幀都執行Alpha混合的時候,就避免執行��,以免影響畫面的流暢性��。