這一節(jié)關(guān)注TC中的hash數(shù)據(jù)庫(kù)如何根據(jù)一個(gè)key查找到該key所在的record,因?yàn)楹罄m(xù)的刪除,插入記錄都是以查找為基礎(chǔ)的,所以首先描述這部分內(nèi)容.
從上一節(jié)的
概述中,可以看到record結(jié)構(gòu)體中有兩個(gè)成員left,right:
typedef struct { // type of structure for a record
uint64_t off; // offset of the record
uint32_t rsiz; // size of the whole record
uint8_t magic; // magic number
uint8_t hash; // second hash value
uint64_t left; // offset of the left child record
uint64_t right; // offset of the right child record
uint32_t ksiz; // size of the key
uint32_t vsiz; // size of the value
uint16_t psiz; // size of the padding
const char *kbuf; // pointer to the key
const char *vbuf; // pointer to the value
uint64_t boff; // offset of the body
char *bbuf; // buffer of the body
} TCHREC;
說(shuō)明,每個(gè)record是存放在一個(gè)類二叉樹(shù)的結(jié)構(gòu)中的.
實(shí)際上,TC會(huì)首先根據(jù)一個(gè)record的key去算出該key所在的bucket index以及hash index,代碼如下:
/* Get the bucket index of a record.
`hdb' specifies the hash database object.
`kbuf' specifies the pointer to the region of the key.
`ksiz' specifies the size of the region of the key.
`hp' specifies the pointer to the variable into which the second hash value is assigned.
The return value is the bucket index. */
static uint64_t tchdbbidx(TCHDB *hdb, const char *kbuf, int ksiz, uint8_t *hp){
assert(hdb && kbuf && ksiz >= 0 && hp);
uint64_t idx = 19780211;
uint32_t hash = 751;
const char *rp = kbuf + ksiz;
while(ksiz--){
idx = idx * 37 + *(uint8_t *)kbuf++;
hash = (hash * 31) ^ *(uint8_t *)--rp;
}
*hp = hash;
return idx % hdb->bnum;
}
需要特別提醒的一點(diǎn)是,上面的算法中,根據(jù)key算出所在的bucket index,是經(jīng)過(guò)模TCHDB->bnum之后的結(jié)果,也就是說(shuō),這個(gè)值是有限制的---最大不能超過(guò)TCHDB初始化時(shí)得到的bucket最大數(shù)量;而算出的二級(jí)hash值,我是沒(méi)有看出來(lái)有數(shù)值上的限制的,為什么?看了后面的內(nèi)容就明白了.
因此,所有根據(jù)記錄的key算出bucket index相同的記錄全都以二叉樹(shù)的形式組織起來(lái),而每個(gè)bucket array元素存放的整型值就是該bucket樹(shù)根所在記錄的offset.
到此,相關(guān)的結(jié)構(gòu)體聯(lián)系都清楚了,下面的流程圖給出了查找一個(gè)key的記錄是否存在的流程:
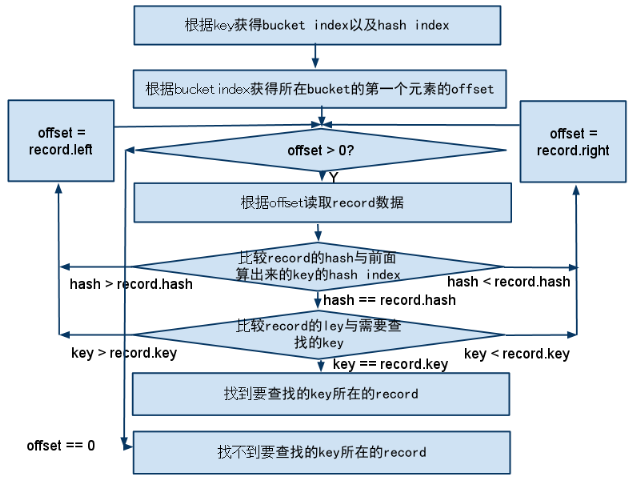
簡(jiǎn)單的解釋一下,這個(gè)查找的流程就是首先根據(jù)查找的key算出所在的bucket,然后在這個(gè)bucket的二叉樹(shù)中按照條件遍歷的過(guò)程.
前面提到過(guò),bucket array是整個(gè)被mmap映射到共享內(nèi)存中去的.我們來(lái)做一個(gè)估計(jì),假設(shè)存放bucket array的內(nèi)存使用了1G,而真正存放record的文件長(zhǎng)度有16G,也就是,bucket array的元素與記錄大概是1:16的關(guān)系,假設(shè)所選的hash算法足夠的好,以至于每個(gè)記錄的key可以較為平均的分布在不同的bucket index上,也就是每個(gè)bucket array的元素組成的二叉樹(shù)上平均有16個(gè)元素,那么也就最多需要O(4)次讀取文件I/O(每次去讀取記錄的數(shù)據(jù)都是一次讀磁盤操作) + O(1)次內(nèi)存讀操作(因?yàn)樾枰赽ucket array中得到樹(shù)根元素的offset).
但是等等,上面還有一些細(xì)節(jié)沒(méi)有交待清楚.
首先,上面的二叉樹(shù)不是類似AVL,紅黑樹(shù)這樣的平衡二叉查找樹(shù),也就是說(shuō),很可能在極端的情況下演變成一個(gè)鏈表---樹(shù)的一邊沒(méi)有元素,另一邊有全部的元素.
其次,上面的流程圖中還有一點(diǎn)就是每次比較首先比較的是hash值,這個(gè)值的奧秘就在于解決上面提到的那個(gè)問(wèn)題.既然只是一個(gè)普通的二叉樹(shù),無(wú)法保證平衡,那么就通過(guò)算出這個(gè)二級(jí)的hash值來(lái)保證平衡---當(dāng)然,前提依然是所選擇的hash算法足夠的好,可以保證key平均的分布.
前面提到過(guò),非平衡的二叉樹(shù)只會(huì)在極端的情況下才會(huì)演變?yōu)橐粋€(gè)極端不平衡的二叉樹(shù)--鏈表,而諸如AVL,紅黑樹(shù)之類的平衡二叉樹(shù),算法編碼都相對(duì)復(fù)雜,調(diào)試起來(lái)也麻煩,出錯(cuò)了要跟進(jìn)更麻煩,另外還別忘了,這些平衡二叉樹(shù)之所以能保持平衡,在刪除/增加元素時(shí)做的讓樹(shù)重新平衡的操作,比如旋轉(zhuǎn)等,都是要涉及到讀寫樹(shù)結(jié)點(diǎn)的,而這些,目前都是存放在磁盤上的---也就是這是相對(duì)較費(fèi)時(shí)的操作,所以問(wèn)題在于:是不是值得為這一個(gè)極端的情況去優(yōu)化?另外,引入二級(jí)hash就是為了部分解決這個(gè)極端不平衡問(wèn)題,它的思路簡(jiǎn)單也容易實(shí)現(xiàn),但是引入的另外一個(gè)問(wèn)題就是每次查找時(shí)根據(jù)key去算bucket index的時(shí)候,還要耗費(fèi)時(shí)間去算hash index了.
平衡點(diǎn),還是平衡點(diǎn).時(shí)間還是空間,這是一個(gè)問(wèn)題.
所以,經(jīng)過(guò)對(duì)TC的hash數(shù)據(jù)庫(kù)查找key流程的分析,最大的感受是:它沒(méi)有使用復(fù)雜的算法與數(shù)據(jù)結(jié)構(gòu),而是通過(guò)一些巧妙的優(yōu)化如二級(jí)hash的引入,達(dá)到了系統(tǒng)效率和編碼調(diào)試復(fù)雜度之間一個(gè)較好的平衡.學(xué)會(huì)"平衡"各種因素,是做項(xiàng)目做事情,都要掌握的一個(gè)技能,而這個(gè),只有多經(jīng)歷多想才能慢慢積累了.
好了,簡(jiǎn)單的回顧整個(gè)查找key的關(guān)鍵點(diǎn):
1) 所有的record是以二叉樹(shù)的形式組織在同一個(gè)bucket上面的.
2) 這個(gè)二叉樹(shù)不是平衡的二叉樹(shù)
3) 為了解決問(wèn)題二造成的極端不平衡問(wèn)題,TC引入了二級(jí)hash,以保證這個(gè)二叉樹(shù)盡可能的平衡.
以上,就是TC對(duì)記錄,bucket的組織情況,以及整個(gè)查找算法的流程.可以看到,算法,結(jié)構(gòu)體定義等等都不復(fù)雜,但是由于巧妙的構(gòu)思,既可以使用盡可能簡(jiǎn)單的算法/數(shù)據(jù)結(jié)構(gòu),又能規(guī)避可能出現(xiàn)的一些隱患,同時(shí)還能保證查找的高效率.
查找是key-value形式存儲(chǔ)的核心流程,能夠?qū)⑦@個(gè)流程優(yōu)化,對(duì)整個(gè)系統(tǒng)的性能也有很大的影響.