這兩個數據結構在內核中隨處可見,不得不拿出來單獨講講.
這兩個數據結構都是為了方便內核開發者在使用到類似數據結構的時候不必自行開發(雖然不難),因此它們需要做到足夠的"通用性",也就是說,今天可以用它們做一個存放進程的鏈表,明天同樣可以做一個封裝定時器的鏈表.兩個數據結構的對外API封裝了針對它們的基本操作,也是最常見的操作,比如遍歷,查找等等.
一般的,如果我們需要寫一個鏈表,會這么寫:
struct node
{
struct node *next;
data_t data;
}
其中的data假設是鏈表中元素存放的數據.然后針對這個鏈表寫一些相關操作的API.
假設下一個需求,鏈表存放的元素變了,那么我們還需要定義一個新的數據結構,寫一些相關操作的API.
但是,其實我們需要做的事情都是類似:遍歷一個鏈表,按照某個條件定位到其中的一個元素,等等.有沒有辦法將操作比較特定數據的操作交給使用者,而封裝出一套滿足基本鏈表操作的API呢?
C++里面的做法是STL,使用的是范型技術,在運行時才直到容器所要存放的數據元素的類型.而通過C++中的重載,函數對象等技術可以平滑的實現操作不同數據元素.
C中沒有這些技術,用STL的方式恐怕是走不通了.
于是,內核采用了另一種方法解決這個問題.
內核中實現的鏈表數據結構是這樣的:
struct list_head {
struct list_head *next, *prev;
};
可見,這個鏈表中只有分別指向前一個和后一個元素的指針,而沒有特定的類型.也就是說,這個數據類型關注的僅僅是鏈表本身的東西,與具體的數據無關.
當需要使用鏈表的時候,可以這樣來:
struct node
{
struct list_head link;
data_t data;
}
那么,如何根據這個link定位到所需要管理的數據呢?
內核中定義了這么一個宏:
#define container_of(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
這個宏的作用是容器類型type中有一個名為member的list_head元素,要根據這個元素的指針(ptr)得到存放它的type類型的對象的地址.
一步一步看這個宏:
1) &
((type *)0)->member)
從C的角度出發, 假設結構體node中有一個成員data, 那么對于一個指向結構體node的指針p來說,p->data與p的地址相差為data這個域在結構體node中的偏移量.
于是,&
(p->member)就是type類型的指針p中的成員member的地址,而這個地址是p的地址+member成員在這個結構體中的偏移,
當這個p變成了0之后,自然就得出了member成員在結構體type中的偏移量.
所以,
&((type *)0)->member)獲得了結構體type中成員member的偏移量.
2)
(char *)(ptr)-(unsigned long)(&((type *)0)->member))
這里ptr是list_head的指針,也就是member成員的指針,因此兩者相減得到了存放member的type結構體的指針.
3)((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
最后在前面加上一個類型轉換,將前面得到的指針轉換成type類型.
這就是內核中根據list_head指針得到容納它的容器地址的魔法.
理解了這個,理解內核中的鏈表操作也就不再難.
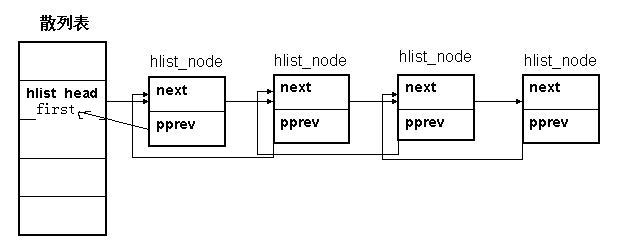
接著看hlist,首先看看內核中的定義:
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
這個數據結構與一般的hash-list數據結構定義有以下的區別:
1) 首先,hash的頭節點僅存放一個指針,也就是first指針,指向的是list的頭結點,沒有tail指針也就是指向list尾節點的指針,這樣的考慮是為了節省空間--尤其在hash bucket很大的情況下可以節省一半的指針空間.
2) list的節點有兩個指針,但是需要注意的是pprev是指針的指針,它指向的是前一個節點的next指針(見下圖).
現在疑問來了:為什么pprev不是prev也就是一個指針,用于簡單的指向list的前一個指針呢?這樣即使對于first而言,它可以將prev指針指向list的尾結點.
主要是基于以下幾個考慮:
1) hash-list中的list一般元素不多(如果太多了一般是設計出現了問題),即使遍歷也不需要太大的代價,同時需要得到尾結點的需求也不多.
2) 如果對于一般節點而言,prev指向的是前一個指針,而對于first也就是hash的第一個元素而言prev指向的是list的尾結點,那么在刪除一個元素的時候還需要判斷該節點是不是first節點進行處理.而在hlist提供的刪除節點的API中,并沒有帶上hlist_head這個參數,因此做這個判斷存在難度.
3) 以上兩點說明了為什么不使用prev,現在來說明為什么需要的是pprev,也就是一個指向指針的指針來保存前一個節點的next指針--因為這樣做即使在刪除的節點是first節點時也可以通過*pprev = next;直接修改指針的指向.來看刪除一個節點和修改list頭結點的兩個API:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first; //此時n是hash的first指針,因此它的pprev指向的是hash的first指針的地址
}
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next; // pprev指向的是前一個節點的next指針,而當該節點是first節點時指向自己,因此兩種情況下不論該節點是一般的節點還是頭結點都可以通過這個操作刪除掉所需刪除的節點
if (next)
next->pprev = pprev;
}
參考資料:
1)http://blog.chinaunix.net/u/12592/showart.php?id=451619
我對里面的示意圖做了一下修改,主要是將list頭結點的pprev指針指向hash的first指針地址.這樣看上去更明白一些.
2)http://linux.chinaunix.net/bbs/viewthread.php?tid=1032772