
2015年1月9日
本來(lái)我都忘記了,結(jié)果有網(wǎng)友提醒我要寫(xiě),我就來(lái)寫(xiě)一寫(xiě)。
現(xiàn)在的年終總結(jié)已經(jīng)沒(méi)什么內(nèi)容了,主要是GacUI (www.gaclib.net)的開(kāi)發(fā)實(shí)在太漫長(zhǎng)。我現(xiàn)在在做拖控件程序GacStudio,希望在做完之后可以有Blend編輯WPF的效果,在xml里面寫(xiě)data binding的時(shí)候不同的地方會(huì)有不同的intellisense。這當(dāng)然是很難的,所以才想做。因此今年就把GacUI做到可以有Control Template、Item Template、Data Binding、XML Resource和加載,于是終于可以開(kāi)始做GacStudio了。GacStudio整個(gè)會(huì)使用GacUI推薦的Data Binding來(lái)寫(xiě)。這有三個(gè)好處:1、檢驗(yàn)Data Binding是否設(shè)計(jì)的好順便抓bug;2、檢驗(yàn)性能;3、證明GacUI是屌的,大家都可以用。
我還在github開(kāi)了一個(gè)數(shù)據(jù)庫(kù)項(xiàng)目,在https://github.com/vczh/herodb,不過(guò)因?yàn)楝F(xiàn)在沒(méi)有臺(tái)式機(jī),筆記本太爛裝不了Ubuntu的虛擬機(jī),所以暫停開(kāi)發(fā),等到我設(shè)備到了我再繼續(xù)寫(xiě)。這個(gè)東西寫(xiě)完之后會(huì)合并進(jìn)GacUI作為擴(kuò)展的一部分,可以開(kāi)很多腦洞,這個(gè)我就不講了。
我覺(jué)得2014年最偉大的成就就是,我終于搬去西雅圖了,啊哈哈哈哈。
posted @
2015-01-08 14:58 陳梓瀚(vczh) 閱讀(17822) |
評(píng)論 (14) |
編輯 收藏
2014年7月15日
上次有人來(lái)要求我寫(xiě)一篇文章談?wù)勈裁创a才是好代碼,是誰(shuí)我已經(jīng)忘記了,好像是AutoHotkey還是啥的專(zhuān)欄的作者。撇開(kāi)那些奇怪的條款不談,靠譜的 代碼有一個(gè)共同的特點(diǎn),就是DRY。DRY就是Don't Repeat Yourself,其實(shí)已經(jīng)被人談了好多年了,但是幾乎所有人都會(huì)忘記。
什么是DRY(Don't Repeat Yourself)
DRY 并不是指你不能復(fù)制代碼這么簡(jiǎn)單的。不能repeat的其實(shí)是信息,不是代碼。要分析一段代碼里面的什么東西時(shí)信息,就跟給物理題做受力分析一樣,想每次 都做對(duì)其實(shí)不太容易。但是一份代碼總是要不斷的修補(bǔ)的,所以在這之前大家要先做好TDD,也就是Test Driven Development。這里我對(duì)自己的要求是覆蓋率要高達(dá)95%,不管用什么手段,總之95%的代碼的輸出都要受到檢驗(yàn)。當(dāng)有了足夠多的測(cè)試做后盾的時(shí) 候,不管你以后發(fā)生了什么,譬如說(shuō)你發(fā)現(xiàn)你Repeat了什么東西要改,你才能放心大膽的去改。而且從長(zhǎng)遠(yuǎn)的角度來(lái)看,做好TDD可以將開(kāi)發(fā)出相同質(zhì)量的代碼的時(shí)間縮短到30%左右(這是我自己的經(jīng)驗(yàn)值) 。
什么是信息
信息這個(gè)詞不太好用語(yǔ)言下定義,不過(guò)我可以舉個(gè)例子。譬如說(shuō)你要把一個(gè)配置文件里面的字符串按照分隔符分解成幾個(gè)字符串,你大概就會(huì)寫(xiě)出這樣的代碼:
// name;parent;description
void ReadConfig(const wchar_t* config)
{
auto p = wcschr(config, L';'); // 1
if(!p) throw ArgumentException(L"Illegal config string"); // 2
DoName(wstring(config, p)); // 3
auto q = wcschr(p + 1, L';'); // 4
if(!q) throw ArgumentException(L"Illegal config string"); // 5
DoParent(wstring(p + 1, q); // 6
auto r = wcschr(q + 1, L';'); // 7
if(r) throw ArgumentException(L"Illegal config string"); // 8
DoDescription(q + 1); // 9
}
這段短短的代碼重復(fù)了多少信息?
- 分隔符用的是分號(hào)(1、4、7)
- 第二/三個(gè)片段的第一個(gè)字符位于第一/二個(gè)分號(hào)的后面(4、6、7、9)
- 格式檢查(2、5、8)
- 異常內(nèi)容(2、5、8)
除了DRY以外還有一個(gè)問(wèn)題,就是處理description的方法跟name和parent不一樣,因?yàn)樗竺嬖僖矝](méi)有分號(hào)了。
那這段代碼要怎么改呢?有些人可能會(huì)想到,那把重復(fù)的代碼抽取出一個(gè)函數(shù)就好了:
wstring Parse(const wchar_t& config, bool end)
{
auto next = wcschr(config, L';');
ArgumentException up(L"Illegal config string");
if (next)
{
if (end) throw up;
wstring result(config, next);
config = next + 1;
return result;
}
else
{
if (!end) throw up;
wstring result(config);
config += result.size();
return result;
}
}
// name;parent;description
void ReadConfig(const wchar_t* config)
{
DoName(Parse(config, false));
DoParent(Parse(config, false));
DoDescription(Parse(config, true));
}
是不是看起來(lái)還很別扭,好像把代碼修改了之后只把事情搞得更亂了,而且就算config對(duì)了我們也會(huì)創(chuàng)建那個(gè)up變量,就僅僅是為了不 重復(fù)代碼。而且這份代碼還散發(fā)出了一些不好的味道,因?yàn)閷?duì)于Name、Parent和Description的處理方法還是不能統(tǒng)一,Parse里面針對(duì) end變量的處理看起來(lái)也是很重復(fù),但實(shí)際上這是無(wú)法在這樣設(shè)計(jì)的前提下消除的。所以這個(gè)代碼也是不好的,充其量只是比第一份代碼強(qiáng)一點(diǎn)點(diǎn)。
實(shí) 際上,代碼之所以要寫(xiě)的好,之所以不能repeat東西,是因?yàn)楫a(chǎn)品狗總是要改需求,不改代碼你就要死,改代碼你就要加班,所以為了減少修改代碼的痛苦, 我們不能repeat任何信息。舉個(gè)例子,有一天產(chǎn)品狗說(shuō),要把分隔符從分號(hào)改成空格!一下子就要改兩個(gè)地方了。description后面要加tag! 這樣你處理description的方法又要改了因?yàn)樗且钥崭窠Y(jié)尾不是0結(jié)尾。
因此針對(duì)這個(gè)片段,我們需要把它改成這樣:
vector<wstring> SplitString(const wchar_t* config, wchar_t delimiter)
{
vector<wstring> fragments;
while(auto next = wcschr(config, delimiter))
{
fragments.push_back(wstring(config, next));
config = next + 1;
}
fragments.push_back(wstring(config));
return fragments; // C++11就是好!
}
void ReadConfig(const wchar_t* config)
{
auto fragments = SplitString(config, L';');
if(fragments.size() != 3)
{
throw ArgumentException(L"Illegal config string");
}
DoName(fragments[0]);
DoParent(fragments[1]);
DoDescription(fragments[2]);
}
我們可以發(fā)現(xiàn),分號(hào)(L';')在這里只出現(xiàn)了一次,異常內(nèi)容也只出現(xiàn)了一次,而且處理name、parent和 description的代碼也沒(méi)有什么區(qū)別了,檢查錯(cuò)誤也更簡(jiǎn)單了。你在這里還給你的Library增加了一個(gè)SplitString函數(shù),說(shuō)不定在以 后什么地方就用上了,比Parse這種專(zhuān)門(mén)的函數(shù)要強(qiáng)很多倍。
大家可以發(fā)現(xiàn),在這里重復(fù)的東西并不僅僅是復(fù)制了代碼,而是由于你把 同一個(gè)信息散播在了代碼的各個(gè)部分導(dǎo)致了有很多相近的代碼也散播在各個(gè)地方,而且還不是那么好通過(guò)抽成函數(shù)的方法來(lái)解決。因?yàn)樵谶@種情況下,就算你把重復(fù) 的代碼抽成了Parse函數(shù),你把函數(shù)調(diào)用了幾次實(shí)際上也等于重復(fù)了信息。因此正確的方法就是把做事情的方法變一下,寫(xiě)成SplitString。這個(gè) SplitString函數(shù)并不是通過(guò)把重復(fù)的代碼簡(jiǎn)單的抽取成函數(shù)而做出來(lái)的。去掉重復(fù)的信息會(huì)讓你的代碼的結(jié)構(gòu)發(fā)生本質(zhì)的變化。
這個(gè)問(wèn)題其實(shí)也有很多變體:
- 不能有Magic Number。L';'出現(xiàn)了很多遍,其實(shí)就是個(gè)Magic Number。所以我們要給他個(gè)名字,譬如說(shuō)delimiter。
- 不要復(fù)制代碼。這個(gè)應(yīng)該不用我講了。
- 解耦要做成正交的。SplitString雖然不是直接沖著讀config來(lái)寫(xiě)的,但是它反映了一個(gè)在其它地方也會(huì)遇到的常見(jiàn)的問(wèn)題。如果用Parse的那個(gè)版本,顯然只是看起來(lái)解決了問(wèn)題而已,并沒(méi)有給你帶來(lái)任何額外的效益。
信息一旦被你repeat了,你的代碼就會(huì)不同程度的出現(xiàn)各種腐爛或者破窗,上面那三條其實(shí)只是我能想到的比較常見(jiàn)的表現(xiàn)形式。這件事情也告訴我們,當(dāng)高手告訴你什么什么不能做的時(shí)候,得想一想背后的原因,不然跟封建迷信有什么區(qū)別。
posted @
2014-07-15 06:44 陳梓瀚(vczh) 閱讀(15794) |
評(píng)論 (9) |
編輯 收藏
2014年3月23日
文章中引用的代碼均來(lái)自https://github.com/vczh/tinymoe。
?
看了前面的三篇文章,大家應(yīng)該基本對(duì)Tinymoe的代碼有一個(gè)初步的感覺(jué)了。在正確分析"print sum from 1 to 100"之前,我們首先得分析"phrase sum from (lower bound) to (upper bound)"這樣的聲明。Tinymoe的函數(shù)聲明又很多關(guān)于block和sentence的配置,不過(guò)這里并不打算將所有細(xì)節(jié),我會(huì)將重點(diǎn)放在如何寫(xiě)一個(gè)針對(duì)無(wú)歧義語(yǔ)法的遞歸下降語(yǔ)法分析器上。所以我們這里不會(huì)涉及sentence和block的什么category和cps的配置。
?
雖然"print sum from 1 to 100"無(wú)法用無(wú)歧義的語(yǔ)法分析的方法做出來(lái),但是我們可以借用對(duì)"phrase sum from (lower bound) to (upper bound)"的語(yǔ)法分析的結(jié)果,動(dòng)態(tài)構(gòu)造能夠分析"print sum from 1 to 100"的語(yǔ)法分析器。這種說(shuō)法看起來(lái)好像很高大上,但是其實(shí)并沒(méi)有什么特別難的技巧。關(guān)于"構(gòu)造"的問(wèn)題我將在下一篇文章《跟vczh看實(shí)例學(xué)編譯原理——三:Tinymoe與有歧義語(yǔ)法分析》詳細(xì)介紹。
?
在我之前的博客里我曾經(jīng)寫(xiě)過(guò)《如何手寫(xiě)語(yǔ)法分析器》,這篇文章講了一些簡(jiǎn)單的寫(xiě)遞歸下降語(yǔ)法分析器的規(guī)則,盡管很多人來(lái)信說(shuō)這篇文章幫他們解決了很多問(wèn)題,但實(shí)際上細(xì)節(jié)還不夠豐富,用來(lái)對(duì)編程語(yǔ)言做語(yǔ)法分析的話,還是會(huì)覺(jué)得復(fù)雜性太高。這篇文章也同時(shí)作為《如何手寫(xiě)語(yǔ)法分析器》的補(bǔ)充。好了,我們開(kāi)始進(jìn)入無(wú)歧義語(yǔ)法分析的主題吧。
?
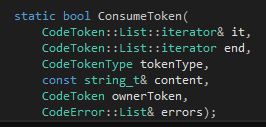
我們需要的第一個(gè)函數(shù)是用來(lái)讀token并判斷其內(nèi)容是不是我們希望看到的東西。這個(gè)函數(shù)比較特別,所以單獨(dú)拿出來(lái)講。在詞法分析里面我們已經(jīng)把文件分行,每一行一個(gè)CodeToken的列表。但是由于一個(gè)函數(shù)聲明獨(dú)占一行,因此在這里我們只需要對(duì)每一行進(jìn)行分析。我們判斷這一行是否以cps、category、symbol、type、phrase、sentence或block開(kāi)頭,如果是那Tinymoe就認(rèn)為這一定是一個(gè)聲明,否則就是普通的代碼。所以這里假設(shè)我們找到了一行代碼以上面的這些token作為開(kāi)頭,于是我們就要進(jìn)入語(yǔ)法分析的環(huán)節(jié)。作為整個(gè)分析器的基礎(chǔ),我們需要一個(gè)ConsumeToken的函數(shù):
?
?
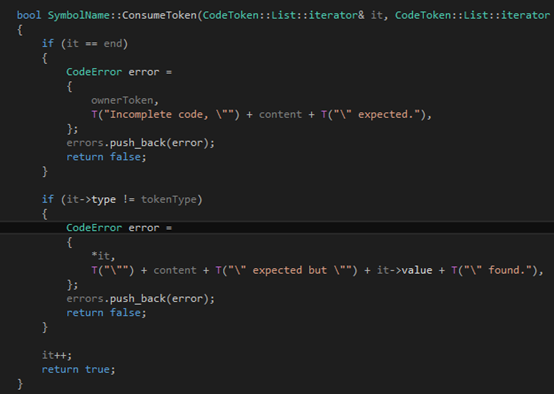
作為一個(gè)純粹的C++11的項(xiàng)目,我們應(yīng)該使用STL的迭代器。其實(shí)在寫(xiě)語(yǔ)法分析器的時(shí)候,基于迭代器的代碼也比基于"token在數(shù)組里的下表"的代碼要簡(jiǎn)單得多。這個(gè)函數(shù)所做的內(nèi)容是這樣的,它查看it指向的那個(gè)token,如果token的類(lèi)型跟tokenType描述的一樣,他就it++然后返回true;否則就是用content和ownerToken來(lái)產(chǎn)生一個(gè)錯(cuò)誤信息加入errors列表里,然后返回false。當(dāng)然,如果傳進(jìn)去的參數(shù)it本身就等于end,那自然要產(chǎn)生一個(gè)錯(cuò)誤。自然,函數(shù)體也十分簡(jiǎn)單:
?
那對(duì)于標(biāo)識(shí)符和數(shù)字怎么辦呢?明眼人肯定一眼就看出來(lái),這是給檢查符號(hào)用的,譬如左括號(hào)、右括號(hào)、冒號(hào)和關(guān)鍵字等。在聲明里面我們是不需要太復(fù)雜的東西的,因此我們還需要兩外一個(gè)函數(shù)來(lái)輸入標(biāo)識(shí)符。Tinymoe事實(shí)上有兩個(gè)針對(duì)標(biāo)識(shí)符的語(yǔ)法分析函數(shù),第一個(gè)是讀入標(biāo)識(shí)符,第二個(gè)不僅要讀入標(biāo)識(shí)符還要判斷是否到了行末否則報(bào)錯(cuò):
?
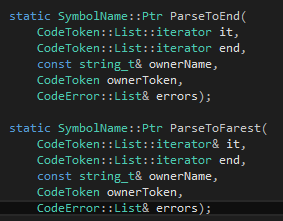
在這里我需要強(qiáng)調(diào)一個(gè)重點(diǎn),在寫(xiě)語(yǔ)法分析器的時(shí)候,函數(shù)的各式一定要整齊劃一。Tinymoe的語(yǔ)法分析函數(shù)有兩個(gè)格式,分別是針對(duì)parse一行的一個(gè)部分,和parse一個(gè)文件的一些行的。ParseToEnd和ParseToFarest就屬于parse一行的一個(gè)部分的函數(shù)。這種函數(shù)的格式如下:
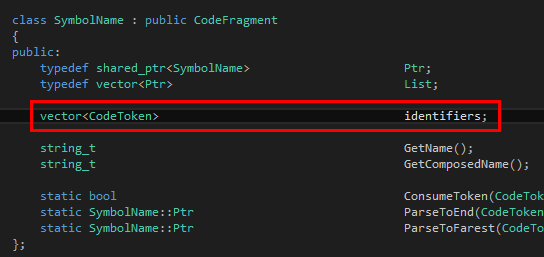
返回值一定是語(yǔ)法樹(shù)的一個(gè)節(jié)點(diǎn)。在這里我們以share_ptr<SymbolName>作為標(biāo)識(shí)符的節(jié)點(diǎn)。一個(gè)標(biāo)識(shí)符可以含有多個(gè)標(biāo)識(shí)符token,譬如說(shuō)the Chinese people、the real Tinymoe programmer什么的。因此我們可以簡(jiǎn)單地推測(cè)SymbolName里面有一個(gè)vector<CodeToken>。這個(gè)定義可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前兩個(gè)參數(shù)分別是iterator&和指向末尾的iterator。末尾通常指"從這里開(kāi)始我們不希望這個(gè)parser函數(shù)來(lái)讀",當(dāng)然這通常就意味著行末。我們把"末尾"這個(gè)概念抽取出來(lái),在某些情況下可以得到極大的好處。
最后一個(gè)token一定是vector<CodeError>&,用來(lái)存放過(guò)程中遇到的錯(cuò)誤。
?
除了函數(shù)格式以外,我們還需要所有的函數(shù)都遵循某些前置條件和后置條件。在語(yǔ)法分析里,如果你試圖分析一個(gè)結(jié)構(gòu)但是不幸出現(xiàn)了錯(cuò)誤,這個(gè)時(shí)候,你有可能可以返回一個(gè)語(yǔ)法樹(shù)的節(jié)點(diǎn),你也有可能什么都返回不了。于是這里就有兩種情況:
你可以返回,那就證明雖然輸入的代碼有錯(cuò)誤,但是你成功的進(jìn)行了錯(cuò)誤恢復(fù)——實(shí)際上就是說(shuō),你覺(jué)得你自己可以猜測(cè)這份代碼的作者實(shí)際是要表達(dá)什么意思——于是你要移動(dòng)第一個(gè)iterator,讓他指向你第一個(gè)還沒(méi)讀到的token,以便后續(xù)的語(yǔ)法分析過(guò)程繼續(xù)進(jìn)行下去。
你不能返回,那就證明你恢復(fù)不了,因此第一個(gè)iterator不能動(dòng)。因?yàn)檫@個(gè)函數(shù)有可能只是為了測(cè)試一下當(dāng)前的輸入是否滿(mǎn)足一個(gè)什么結(jié)構(gòu)。既然他不是,而且你恢復(fù)不出來(lái)——也就是你猜測(cè)作者本來(lái)也不打算在這里寫(xiě)某個(gè)結(jié)構(gòu)——因此iterator不能動(dòng),表示你什么都沒(méi)有讀。
?
當(dāng)你根據(jù)這樣的格式寫(xiě)了很多語(yǔ)法分析函數(shù)之后,你會(huì)發(fā)現(xiàn)你可以很容易用簡(jiǎn)單結(jié)構(gòu)的語(yǔ)法分析函數(shù),拼湊出一個(gè)復(fù)雜的語(yǔ)法分析函數(shù)。但是由于Tinymoe的聲明并沒(méi)有一個(gè)編程語(yǔ)言那么復(fù)雜,所以這種嵌套結(jié)構(gòu)出現(xiàn)的次數(shù)并不多,于是我們這里先跳過(guò)關(guān)于嵌套的討論,等到后面具體分析"函數(shù)指針類(lèi)型的參數(shù)"的時(shí)候自然會(huì)涉及到。
?
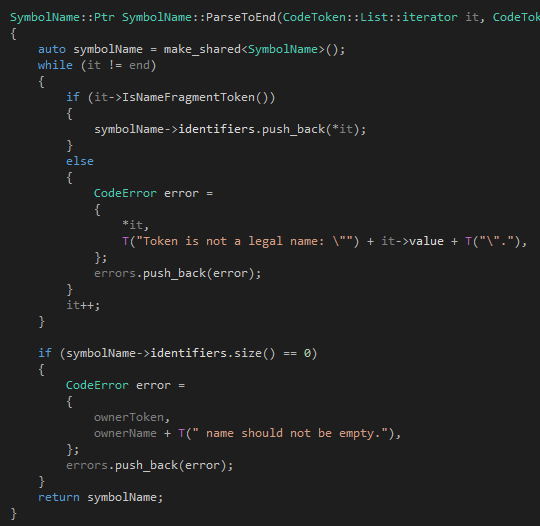
說(shuō)了這么多,我覺(jué)得也應(yīng)該上ParseToEnd和ParseToFarest的代碼了。首先是ParseToEnd:
?
我們很快就可以發(fā)現(xiàn),其實(shí)語(yǔ)法分析器里面絕大多數(shù)篇幅的代碼都是關(guān)于錯(cuò)誤處理的,真正處理正確代碼的部分其實(shí)很少。ParseToEnd做的事情不多,他就是從it開(kāi)始一直讀到end的位置,把所有不是標(biāo)識(shí)符的token都扔掉,然后把所有遇到的標(biāo)識(shí)符token都連起來(lái)作為一個(gè)完整的標(biāo)識(shí)符。也就是說(shuō),ParseToEnd遇到類(lèi)似"the real 100 Tinymoe programmer"的時(shí)候,他會(huì)返回"the real Tinymoe programmer",然后在"100"的地方報(bào)一個(gè)錯(cuò)誤。
?
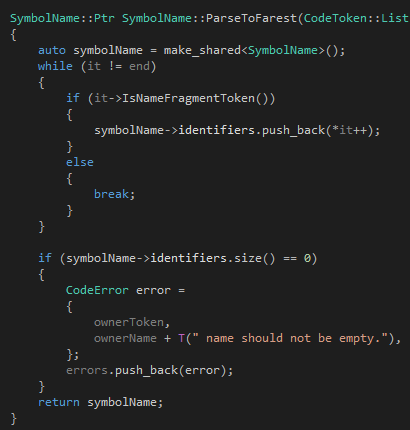
ParseToFarest的邏輯差不多:
?
只是當(dāng)這個(gè)函數(shù)遇到"the real 100 Tinymoe programmer"的時(shí)候,會(huì)返回"the real",然后把光標(biāo)移動(dòng)到"100",但是沒(méi)有報(bào)錯(cuò)。
?
看了這幾個(gè)基本的函數(shù)之后,我們可以進(jìn)入正題了。做語(yǔ)法分析器,當(dāng)然還是從文法開(kāi)始。跟上一篇文章一樣,我們來(lái)嘗試直接構(gòu)造一下文法。但是語(yǔ)法分析器跟詞法分析器的文法的區(qū)別是,詞法分析其的文法可以 "定義函數(shù)"和"調(diào)用函數(shù)"。
?
首先,我們來(lái)看symbol的文法:
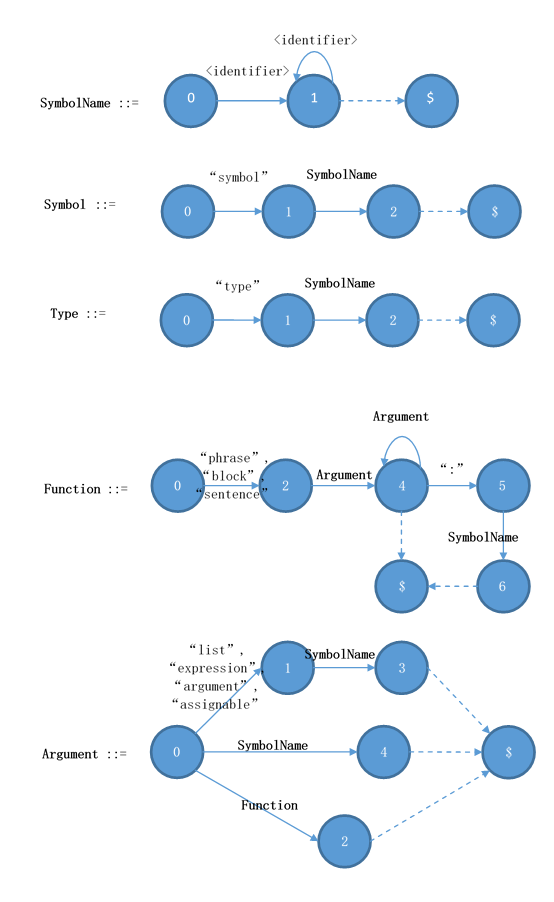
SymbolName ::= <identifier> { <identifier> }
Symbol ::= "symbol" SymbolName
?
其次,就是type的聲明。type是多行的,不過(guò)我們這里只關(guān)心開(kāi)頭的一樣:
Type ::= "type" SymbolName [ ":" SymbolName ]
?
在這里,中括號(hào)代表可有可無(wú),大括號(hào)代表重復(fù)0次或以上。現(xiàn)在讓我們來(lái)看函數(shù)的聲明。函數(shù)的生命略為復(fù)雜:
?
Function ::= ("phrase" | "sentence" | "block") { SymbolName | "(" Argument ")" } [ ":" SymbolName ]
Argument ::= ["list" | "expression" | "argument" | "assignable"] SymbolName
Argument ::= SymbolName
Argument ::= Function
?
Declaration ::= Symbol | Type | Function
?
在這里我們看到Function遞歸了自己,這是因?yàn)楹瘮?shù)的參數(shù)可以是另一個(gè)函數(shù)。為了讓這個(gè)參數(shù)調(diào)用起來(lái)更加漂亮一點(diǎn),你可以把參數(shù)寫(xiě)成函數(shù)的形式,譬如說(shuō):
pharse (the number) is odd : odd numbers
????return the number % 2 == 1
end
?
print all (phrase (the number) is wanted) in (numbers)
????repeat with the number in all numbers
????????if the number is wanted
????????????print the number
????????end
????end
end
?
print main
????print all odd numbers in array of (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
end
?
我們給"(the number) is odd"這個(gè)判斷一個(gè)數(shù)字是不是奇數(shù)的函數(shù),起了一個(gè)別名叫"odd numbers",這個(gè)別名不能被調(diào)用,但是他等價(jià)于一個(gè)只讀的變量保存著奇數(shù)函數(shù)的函數(shù)指針。于是我們就可以把它傳遞給"print all (…) in (…)"這個(gè)函數(shù)的第一個(gè)參數(shù)了。第一個(gè)參數(shù)聲明成函數(shù),所以我們可以在print函數(shù)內(nèi)直接調(diào)用這個(gè)參數(shù)指向的odd numbers函數(shù)。
?
事實(shí)上Tinymoe的SymbolName是可以包含關(guān)鍵字的,但是我為了不讓它寫(xiě)的太長(zhǎng),于是我就簡(jiǎn)單的寫(xiě)成了上面的那條式子。那Argument是否可以包含關(guān)鍵字呢?答案當(dāng)然是可以的,只是當(dāng)它以list、expression、argument、assignable、phrase、sentence、block開(kāi)始的時(shí)候,我們強(qiáng)行認(rèn)為他有額外的意義。
?
現(xiàn)在一個(gè)Tinymoe的聲明的第一行都由Declaration來(lái)定義。當(dāng)我們識(shí)別出一個(gè)正確的Declaration之后,我們就可以根據(jù)分析的結(jié)果來(lái)對(duì)后面的行進(jìn)行分析。譬如說(shuō)symbol后面沒(méi)有東西,于是就這么完了。type后面都是成員函數(shù),所以我們一直找到"end"為止。函數(shù)的函數(shù)體就更復(fù)雜了,所以我們會(huì)直接跳到下一個(gè)看起來(lái)像Declaration的東西——也就是以symbol、type、phrase、sentence、block、cps、category開(kāi)始的行。這些步驟都很簡(jiǎn)單,所以問(wèn)題的重點(diǎn)就是,如何根據(jù)Declaration的文法來(lái)處理輸入的字符串。
?
為了讓文法可以真正的運(yùn)行,我們需要把它做成狀態(tài)機(jī)。根據(jù)之前的描述,這個(gè)狀態(tài)及仍然需要有"定義函數(shù)"和"執(zhí)行函數(shù)"的能力。我們可以先假裝他們是正則表達(dá)式,然后把整個(gè)狀態(tài)機(jī)畫(huà)出來(lái)。這個(gè)時(shí)候,"函數(shù)"本身我們把它看成是一個(gè)跟標(biāo)識(shí)符無(wú)關(guān)的輸入,然后就可以得到下面的狀態(tài)機(jī):
?
?
這樣我們的狀態(tài)機(jī)就暫時(shí)完成了。但是現(xiàn)在還不能直接把它轉(zhuǎn)換成代碼,因?yàn)楫?dāng)我們遇到一個(gè)輸入,而我們可以選擇調(diào)用函數(shù),而且可以用的函數(shù)還不止一個(gè)的時(shí)候,那應(yīng)該怎么辦呢?答案就是要檢查我們的文法是不是有歧義。
?
文法的歧義是一個(gè)很有意思的問(wèn)題。在我們真的實(shí)踐一個(gè)編譯器的時(shí)候,我們會(huì)遇到三種歧義:
文法本身就是有歧義的,譬如說(shuō)C++著名的A* B;的問(wèn)題。當(dāng)A是一個(gè)變量的時(shí)候,這是一個(gè)乘法表達(dá)式。當(dāng)A是一個(gè)類(lèi)型的時(shí)候,這是一個(gè)變量聲明語(yǔ)句。如果我們?cè)谡Z(yǔ)法分析的時(shí)候不知道A到底指向的是什么東西,那我們根本無(wú)從得知這一句話到底要取什么意思,于是要么返回錯(cuò)誤,要么兩個(gè)結(jié)果一起返回。這就是問(wèn)法本身固有的歧義。
文法本身沒(méi)有歧義,但是在分析的過(guò)程中卻無(wú)法在走每一步的時(shí)候都能夠算出唯一的"下一個(gè)狀態(tài)"。譬如說(shuō)C#著名的A<B>C;問(wèn)題。當(dāng)A是一個(gè)變量的時(shí)候,這個(gè)語(yǔ)句是不成立的,因?yàn)镃#的一個(gè)語(yǔ)句的根節(jié)點(diǎn)不能是一個(gè)操作符(這里是">")。當(dāng)A是一個(gè)類(lèi)型的時(shí)候,這是一個(gè)變量聲明語(yǔ)句。從結(jié)果來(lái)看,這并沒(méi)有歧義,但是當(dāng)我們讀完A<B>的時(shí)候仍然不知道這個(gè)語(yǔ)句的結(jié)構(gòu)到底是取哪一種。實(shí)際上B作為類(lèi)型參數(shù),他也可以有B<C>這樣的結(jié)構(gòu),因此這個(gè)B可以是任意長(zhǎng)的。也就是說(shuō)我們只有在">"結(jié)束之后再多讀幾個(gè)字符才能得到正確的判斷。譬如說(shuō)C是"(1)",那我們知道A應(yīng)該是一個(gè)模板函數(shù)。如果C是一個(gè)名字,A多半應(yīng)該是一個(gè)類(lèi)型。因此我們?cè)谧稣Z(yǔ)法分析的時(shí)候,只能兩種情況一起考慮,并行處理。最后如果哪一個(gè)情況分析不下去了,就簡(jiǎn)單的扔掉,剩下的就是我們所需要的。
文法本身沒(méi)有歧義,而且分析的過(guò)程中只要你每一步都往后多看最多N個(gè)token,酒可以算出唯一的"下一個(gè)狀態(tài)"到底是什么。這個(gè)想必大家都很熟悉,因?yàn)檫@個(gè)N就是LookAhead。所謂的LL(1)、SLR(1)、LR(1)、LALR(1)什么的,這個(gè)1其實(shí)就是N=1的情況。N當(dāng)然不一定是1,他也可以是一個(gè)很大的數(shù)字,譬如說(shuō)8。一個(gè)文法的LookAhead是多少,這是文法本身固有的屬性。一個(gè)LR(2)的狀態(tài)機(jī)你非要在語(yǔ)法分析的時(shí)候只LookAhead一個(gè)token,那也會(huì)遇到第二種歧義的情況。如果C語(yǔ)言沒(méi)有typedef的話,那他就是一個(gè)帶有LookAhead的沒(méi)有歧義的語(yǔ)言了。
?
看一眼我們剛才寫(xiě)出來(lái)的文法,明顯就是LookAhead=0的情況,而且連左遞歸都沒(méi)有,寫(xiě)起來(lái)肯定很容易。那接下來(lái)我們要做的就是給"函數(shù)"算first set。一個(gè)函數(shù)的first set,顧名思義就是,他的第一個(gè)token都可以是什么。SymbolName、Symbol、Type、Function都不用看了,因?yàn)樗麄兊奈姆ǖ谝粋€(gè)輸入都是token,那就是他們的first set。最后就剩下Argument。Argument的第一個(gè)token除了list、expression、argument和assignable以外,還有Function。因此Argument的first set就是這些token加上Function的first set。如果文法有左遞歸的話,也可以用類(lèi)似的方法做,只要我們?cè)诤瘮?shù)A->B->C->…->A的時(shí)候,知道A正在計(jì)算于是返回空集就可以了。當(dāng)然,只有左遞歸才會(huì)遇到這種情況。
?
然后我們檢查一下每一個(gè)狀態(tài),可以發(fā)現(xiàn),任何一個(gè)狀態(tài)出去的所有邊,他接受的token或者函數(shù)的first set都是沒(méi)有交集的。譬如Argument的0狀態(tài),第一條邊接受的token、第二條邊接受的SymbolName的first set,和第三條邊接受的Function的first set,是沒(méi)有交集的,所以我們就可以斷定,這個(gè)文法一定沒(méi)有歧義。按照上次狀態(tài)機(jī)到代碼的寫(xiě)法,我們可以機(jī)械的寫(xiě)出代碼了。寫(xiě)代碼的時(shí)候,我們把每一個(gè)文法的函數(shù),都寫(xiě)成一個(gè)C++的函數(shù)。每到一個(gè)狀態(tài)的時(shí)候,我們看一下當(dāng)前的token是什么,然后再?zèng)Q定走哪條邊。如果選中的邊是token邊,那我們就跳過(guò)一個(gè)token。如果選中的邊是函數(shù)邊,那我們不跳過(guò)token,轉(zhuǎn)而調(diào)用那個(gè)函數(shù),讓函數(shù)自己去跳token。《如何手寫(xiě)語(yǔ)法分析器》用的也是一樣的方法,如果對(duì)這個(gè)過(guò)程不清楚的,可以再看一遍這個(gè)文章。
?
于是我們到了定義語(yǔ)法樹(shù)的時(shí)候了。幸運(yùn)的是,我們可以直接從文法上看到語(yǔ)法樹(shù)的形狀,然后稍微做一點(diǎn)微調(diào)就可以了。我們把每一個(gè)函數(shù)都看成一個(gè)類(lèi),然后使用下面的規(guī)則:
對(duì)于A、A B、A B C等的情況,我們轉(zhuǎn)換成class里面有若干個(gè)成員變量。
對(duì)于A | B的情況,我們把它做成繼承,A的語(yǔ)法樹(shù)和B的語(yǔ)法樹(shù)繼承自一個(gè)基類(lèi),然后這個(gè)基類(lèi)的指針就放在class里面做成員變量。
對(duì)于{ A },或者A { A }的情況,那個(gè)成員變量就是一個(gè)vector。
對(duì)于[ A ]的情況,我們就當(dāng)A看,區(qū)別只是,這個(gè)成員變量可以填nullptr。
?
對(duì)于每一個(gè)函數(shù),要不要用shared_ptr來(lái)裝則見(jiàn)仁見(jiàn)智。于是我們可以直接通過(guò)上面的文法得到我們所需要的語(yǔ)法樹(shù):
?
首先是SymbolName:
?
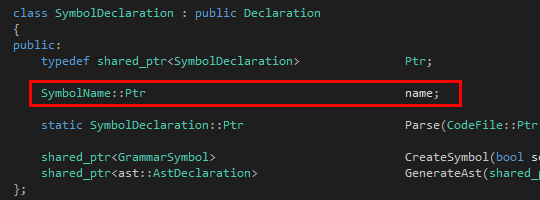
其次是Symbol:
?
然后是Type:
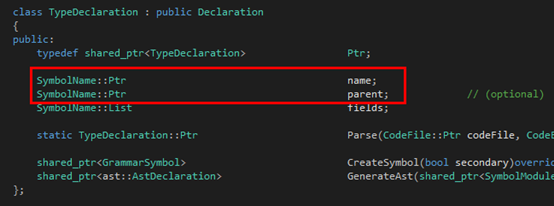
?
接下來(lái)是Argument:
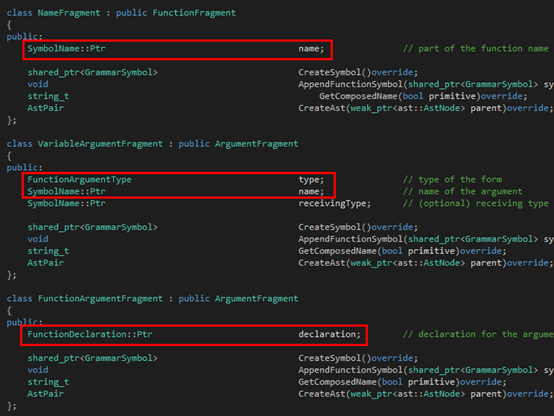
?
最后是Function:
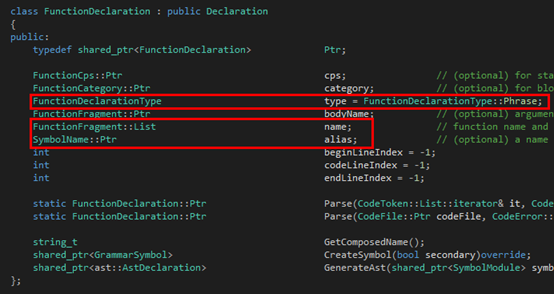
?
大家可以看到,在Argument那里,同時(shí)出去的三條邊就組成了三個(gè)子類(lèi),都繼承自FunctionFragment。圖中紅色的部分就是Tinymoe源代碼里在上述的文法里出現(xiàn)的那部分。至于為什么還有多出來(lái)的部分,其實(shí)是因?yàn)檫@里的文法是為了敘述方便簡(jiǎn)化過(guò)的。至于Tinymoe關(guān)于函數(shù)聲明的所有語(yǔ)法可以分別看下面的四個(gè)github的wiki page:
https://github.com/vczh/tinymoe/wiki/Phrases,-Sentences-and-Blocks
https://github.com/vczh/tinymoe/wiki/Manipulating-Functions
https://github.com/vczh/tinymoe/wiki/Category
https://github.com/vczh/tinymoe/wiki/State-and-Continuation
?
在本章的末尾,我將向大家展示Tinymoe關(guān)于函數(shù)聲明的那一個(gè)Parse函數(shù)。文章已經(jīng)把所有關(guān)鍵的知識(shí)點(diǎn)都講了,具體怎么做大家可以上https://github.com/vczh/tinymoe 閱讀源代碼來(lái)學(xué)習(xí)。
?
首先是我們的函數(shù)頭:
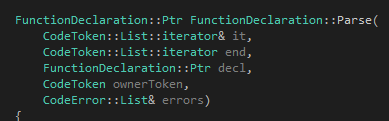
?
回想一下我們之前講到的關(guān)于語(yǔ)法分析函數(shù)的格式:
返回值一定是語(yǔ)法樹(shù)的一個(gè)節(jié)點(diǎn)。在這里我們以share_ptr<SymbolName>作為標(biāo)識(shí)符的節(jié)點(diǎn)。一個(gè)標(biāo)識(shí)符可以含有多個(gè)標(biāo)識(shí)符token,譬如說(shuō)the Chinese people、the real Tinymoe programmer什么的。因此我們可以簡(jiǎn)單地推測(cè)SymbolName里面有一個(gè)vector<CodeToken>。這個(gè)定義可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前兩個(gè)參數(shù)分別是iterator&和指向末尾的iterator。末尾通常指"從這里開(kāi)始我們不希望這個(gè)parser函數(shù)來(lái)讀",當(dāng)然這通常就意味著行末。我們把"末尾"這個(gè)概念抽取出來(lái),在某些情況下可以得到極大的好處。
最后一個(gè)token一定是vector<CodeError>&,用來(lái)存放過(guò)程中遇到的錯(cuò)誤。
?
我們可以清楚地看到這個(gè)函數(shù)滿(mǎn)足上文提出來(lái)的三個(gè)要求。剩下來(lái)的參數(shù)有兩個(gè),第一個(gè)是decl,如果不為空那代表調(diào)用函數(shù)的人已經(jīng)幫你吧語(yǔ)法樹(shù)給new出來(lái)了,你應(yīng)該直接使用它。領(lǐng)一個(gè)參數(shù)ownerToken則是為了產(chǎn)生語(yǔ)法錯(cuò)誤使用的。然后我們看代碼:
?
第一步,我們判斷輸入是否為空,然后根據(jù)需要報(bào)錯(cuò):
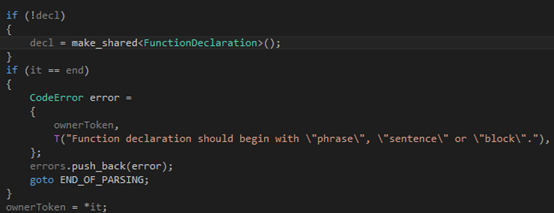
?
第二步,根據(jù)第一個(gè)token來(lái)確定函數(shù)的形式是phrase、sentence還是block,并記錄在成員變量type里:
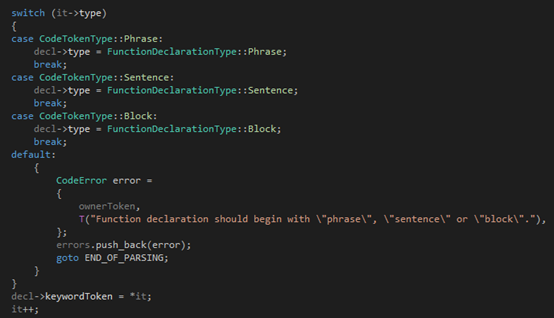
?
第三步是一個(gè)循環(huán),我們根據(jù)當(dāng)前的token(還記不記得之前說(shuō)過(guò),要先看一下token是什么,然后再?zèng)Q定走哪條邊?)來(lái)決定我們接下來(lái)要分析的,是ArgumentFragment的兩個(gè)子類(lèi)(分別是VariableArgumentFragment和FunctionArgumentFragment),還是普通的函數(shù)名的一部分,還是說(shuō)函數(shù)已經(jīng)結(jié)束了,遇到了一個(gè)冒號(hào),因此開(kāi)始分析別名:
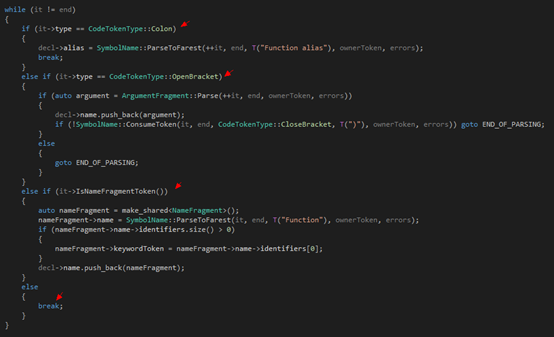
?
最后就不貼了,是檢查格式是否滿(mǎn)足語(yǔ)義的一些代碼,譬如說(shuō)block的函數(shù)名必須由參數(shù)開(kāi)始啦,或者phrase的參數(shù)不能是argument和assignable等。
?
這篇文章就到此結(jié)束了,希望大家在看了這片文章之后,配合wiki關(guān)于語(yǔ)法的全面描述,已經(jīng)知道如何對(duì)Tinymoe的聲明部分進(jìn)行語(yǔ)法分析。緊接著就是下一篇文章——Tinymoe與帶歧義語(yǔ)法分析了,會(huì)讓大家明白,想對(duì)諸如"print sum from 1 to 100"這樣的代碼做語(yǔ)法分析,也不需要多復(fù)雜的手段就可以做出來(lái)。
posted @
2014-03-23 00:51 陳梓瀚(vczh) 閱讀(8383) |
評(píng)論 (2) |
編輯 收藏
2014年3月2日
文章中引用的代碼均來(lái)自https://github.com/vczh/tinymoe。
?
實(shí)現(xiàn)Tinymoe的第一步自然是一個(gè)詞法分析器。詞法分析其所作的事情很簡(jiǎn)單,就是把一份代碼分割成若干個(gè)token,記錄下他們所在文件的位置,以及丟掉不必要的信息。但是Tinymoe是一個(gè)按行分割的語(yǔ)言,自然token列表也就是二維的,第一維是行,第二維是每一行的token。在繼續(xù)講詞法分析器之前,先看看Tinymoe包含多少token:
符號(hào):(、)、,、:、&、+、-、*、/、\、%、<、>、<=、>=、=、<>
關(guān)鍵字:module、using、phrase、sentence、block、symbol、type、cps、category、expression、argument、assignable、list、end、and、or、not
數(shù)字:123、456.789
字符串:"abc\r\ndef"
標(biāo)識(shí)符:tinymoe
注釋?zhuān)?- this is a comment
?
Tinymoe對(duì)于token有一個(gè)特殊的規(guī)定,就是字符串和注釋都是單行的。因此如果一個(gè)字符串在沒(méi)有結(jié)束之前就遇到了換行,那么這種寫(xiě)法定義為你遇到了一個(gè)沒(méi)有右雙引號(hào)的字符串,需要報(bào)個(gè)錯(cuò),然后下一行就不是這個(gè)字符串的內(nèi)容了。
?
一個(gè)詞法分析器所需要做的事情,就是把一個(gè)字符串分解成描述此法的數(shù)據(jù)結(jié)構(gòu)。既然上面已經(jīng)說(shuō)到Tinymoe的token列表是二維的,因此數(shù)據(jù)結(jié)構(gòu)肯定會(huì)體現(xiàn)這個(gè)觀點(diǎn)。Tinymoe的詞法分析器代碼可以在這里找到:https://github.com/vczh/tinymoe/blob/master/Development/Source/Compiler/TinymoeLexicalAnalyzer.h。
?
首先是token:
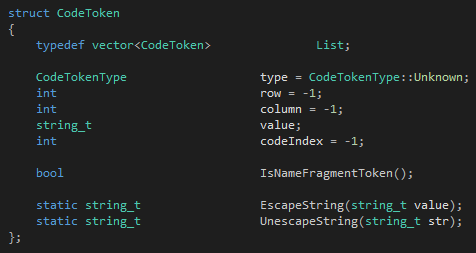
CodeTokenType是一個(gè)枚舉類(lèi)型,標(biāo)記一個(gè)token的類(lèi)型。這個(gè)類(lèi)型比較細(xì)化,每一個(gè)關(guān)鍵字有自己的類(lèi)型,每一個(gè)符號(hào)也有自己的類(lèi)型,剩下的按種類(lèi)來(lái)分。我們可以看到token需要記錄的最關(guān)鍵的東西只有三個(gè):類(lèi)型、內(nèi)容和代碼位置。在token記錄代碼位置是十分重要的,正確地記錄代碼位置可以讓你能夠報(bào)告帶位置的錯(cuò)誤、從語(yǔ)法樹(shù)的節(jié)點(diǎn)還原成代碼位置、甚至在調(diào)試的時(shí)候可以把指令也換成位置。
?
這里需要提到的是,string_t是一個(gè)typedef,具體的聲明可以在這里看到:https://github.com/vczh/tinymoe/blob/master/Development/Source/TinymoeSTL.h。Tinymoe是完全由標(biāo)準(zhǔn)的C++11和STL寫(xiě)成的,但是為了適應(yīng)不同情況的需要,Tinymoe分為依賴(lài)code page的版本和Unicode版本。如果編譯Tinymoe代碼的時(shí)候聲明了全局的宏UNICODE_TINYMOE的話,那Tinymoe所有的字符處理將使用wchar_t,否則使用char。char的類(lèi)型和Tinymoe編譯器在運(yùn)行的時(shí)候操作系統(tǒng)當(dāng)前的code page是綁定的。所以這里會(huì)有類(lèi)似string_t啊、ifstream_t啊、char_t等類(lèi)型,會(huì)在不同的編譯選項(xiàng)的影響下指向不同的STL類(lèi)型或者原生的C++類(lèi)型。github上的VC++2013工程使用的是wchar_t的版本,所以string_t就是std::wstring。
?
Tinymoe的詞法分析器除了token的類(lèi)型以外,肯定還需要定義整個(gè)文件結(jié)構(gòu)在詞法分析后的結(jié)果:
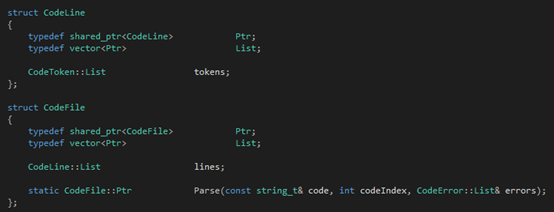
這個(gè)數(shù)據(jù)結(jié)構(gòu)體現(xiàn)了"Tinymoe的token列表是二維的"的這個(gè)觀點(diǎn)。一個(gè)文件會(huì)被詞法分析器處理成一個(gè)shared_ptr<CodeFIle>對(duì)象,CodeFile::lines記錄了所有非空的行,CodeLine::tokens記錄了該行的所有token。
?
現(xiàn)在讓我們來(lái)看詞法分析的具體過(guò)程。關(guān)于如何從正則表達(dá)式構(gòu)造詞法分析器可以在這里(http://www.shnenglu.com/vczh/archive/2008/05/22/50763.html)看到,不過(guò)我們今天要講一講如何人肉構(gòu)造詞法分析器。方法其實(shí)是一樣的,首先人肉構(gòu)造狀態(tài)機(jī),然后把用狀態(tài)機(jī)分析輸入的字符串的代碼抄過(guò)來(lái)就可以了。但是很少有人會(huì)解耦得那么開(kāi),因?yàn)檫@樣寫(xiě)很容易看不懂,其次有可能會(huì)遇到一些極端情況是你無(wú)法用純粹的正則表達(dá)式來(lái)分詞的,譬如說(shuō)C++的raw string literal:R"tinymoe(這里的字符串沒(méi)有轉(zhuǎn)義)tinymoe"。一個(gè)用【R"<一些字符>(】開(kāi)始的字符串只能由【)<同樣的字符>"】來(lái)結(jié)束,要順利分析這種情況,只能通過(guò)在狀態(tài)機(jī)里面做hack才能解決。這就是為什么我們?nèi)巳鈽?gòu)造詞法分析器的時(shí)候,會(huì)把狀態(tài)和動(dòng)作都混在一起寫(xiě),因?yàn)檫@樣便于處理特殊情況。
?
不過(guò)幸好的是,Tinymoe并沒(méi)有這種情況發(fā)生。所以我們可以直接從狀態(tài)機(jī)入手。為了簡(jiǎn)單起見(jiàn),我在下面的狀態(tài)機(jī)中去掉所有不是+和-的符號(hào)。首先,我們需要一個(gè)起始狀態(tài)和一個(gè)結(jié)束狀態(tài):

?
首先我們添加整數(shù)和標(biāo)識(shí)符進(jìn)去:
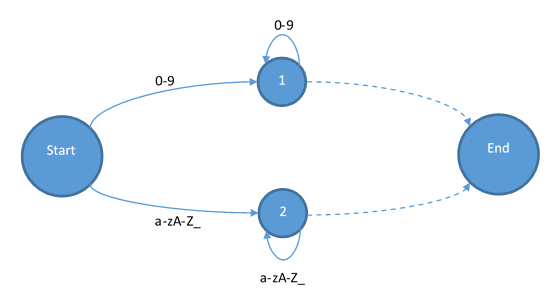
?
其次是加減和浮點(diǎn):
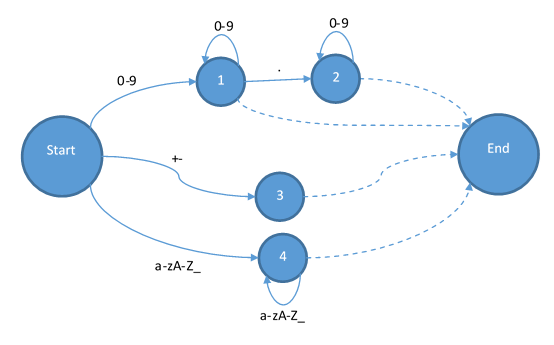
?
最后把字符串和注釋補(bǔ)全:
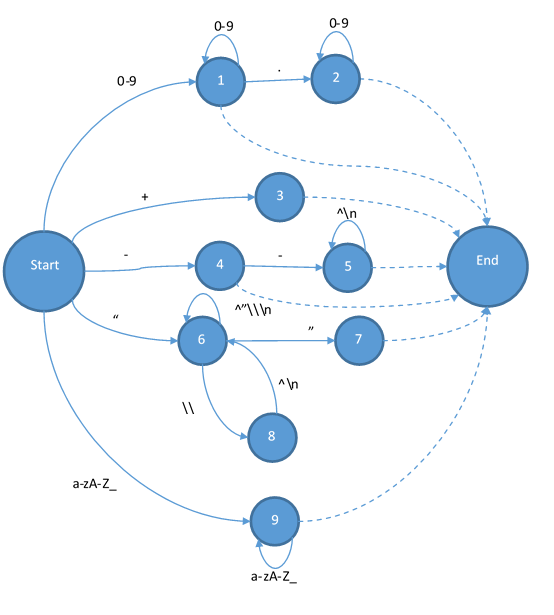
?
這樣狀態(tài)機(jī)就已經(jīng)完成了。讀過(guò)編譯原理的可能會(huì)問(wèn),為什么終結(jié)狀態(tài)都是由虛線而不是帶有輸入的實(shí)現(xiàn)指向的?因?yàn)樘摼€在這里有特殊的意義,也就是說(shuō)它不能移動(dòng)輸入的字符串的指針,而且他還要負(fù)責(zé)添加一個(gè)token。當(dāng)狀態(tài)跳到End之后,那他就會(huì)變成Start,所以實(shí)際上Start和End是同一個(gè)狀態(tài)。這個(gè)狀態(tài)機(jī)也不是輸入什么字符都能跳轉(zhuǎn)到下一個(gè)狀態(tài)的。所以當(dāng)你發(fā)現(xiàn)輸入的字符讓你無(wú)路可走的時(shí)候,你就是遇到了一個(gè)詞法錯(cuò)誤。
?
這樣我們的設(shè)計(jì)就算完成了,接下來(lái)就是如何用C++來(lái)實(shí)現(xiàn)它了。為了讓代碼更容易閱讀,我們應(yīng)該給Start和1-9這么多狀態(tài)起名字,做法如下:
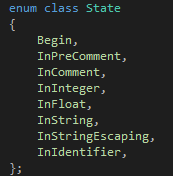
在這里類(lèi)似狀態(tài)3這樣的狀態(tài)被我省略掉了,因?yàn)檫@個(gè)狀態(tài)唯一的出路就是虛線,所以跳到這個(gè)狀態(tài)意味著你要立刻執(zhí)行虛線,也就是說(shuō)你不需要做"跳到這個(gè)狀態(tài)"這個(gè)動(dòng)作。因此它不需要有一個(gè)名字。
?
然后你只要按照下面的做法翻譯這個(gè)狀態(tài)機(jī)就可以了:
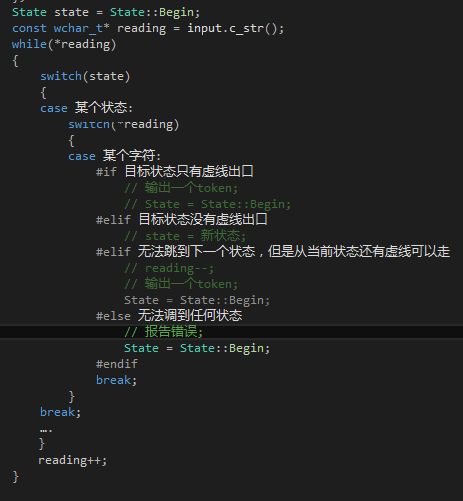
?
只要寫(xiě)到這里,那么我們就初步完成了詞法分析器了。其實(shí)任何系統(tǒng)的主要功能都是相對(duì)容易實(shí)現(xiàn)的,往往是次要的功能才需要花費(fèi)大量的精力來(lái)完成,而且還很容易出錯(cuò)。在這里"次要的功能"就是——記錄token的行列號(hào),還有維護(hù)CodeFile::lines避免空行的出現(xiàn)!
?
盡管我已經(jīng)做過(guò)了那么多次詞法分析器,但是我仍然無(wú)法一氣呵成寫(xiě)對(duì),仍然會(huì)出一些bug。面對(duì)編譯器這種純計(jì)算程序,debug的最好方法就是寫(xiě)單元測(cè)試。不過(guò)對(duì)于不熟悉單元測(cè)試的人來(lái)講可能很難一下子想到要做什么測(cè)試,在這里我可以把我給Tinymoe謝的一部分單元測(cè)試在這里貼一下。
?
第一個(gè),當(dāng)然是傳說(shuō)中的"Hello, world!"測(cè)試了:
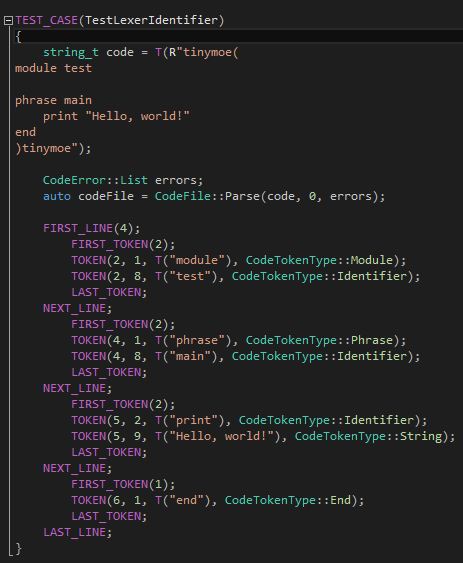
?
TEST_CASE和TEST_ASSERT(這里暫時(shí)沒(méi)有直接用到TEST_ASSERT)是我為了開(kāi)發(fā)Tinymoe隨手?jǐn)]的一個(gè)宏,可以在Tinymoe的代碼里看到。為了檢查我們有沒(méi)有粗心大意,我們有必要檢查詞法分析器的任何一個(gè)輸出的數(shù)據(jù),譬如每一行有多少token,譬如每一個(gè)token的行號(hào)列好內(nèi)容和類(lèi)型。我為了讓這些枯燥的測(cè)試用例容易看懂,在這個(gè)文件(
?
第二個(gè)測(cè)試用例針對(duì)的是整數(shù)和浮點(diǎn)的輸出和報(bào)錯(cuò)上,重點(diǎn)在于檢查每一個(gè)token的列號(hào)是不是正確的計(jì)算了出來(lái):
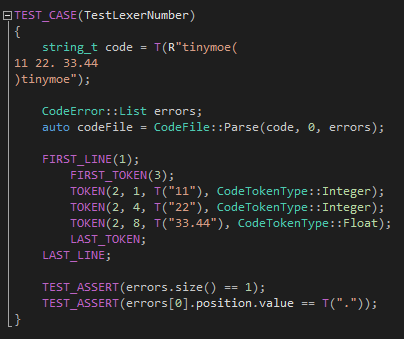
?
第三個(gè)測(cè)試用例的重點(diǎn)主要是-符號(hào)和—注釋的分析:
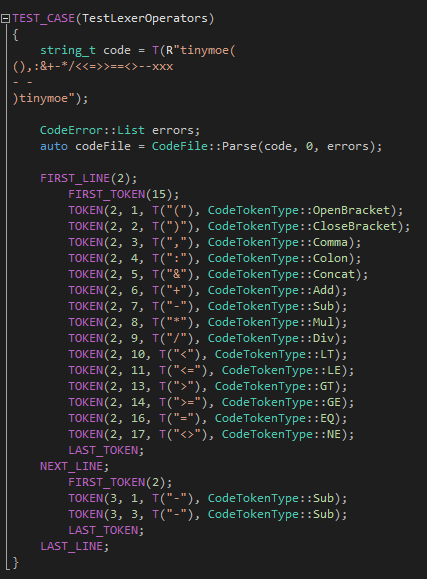
?
第四個(gè)測(cè)試用例則是測(cè)試字符串的escaping和在面對(duì)換行的時(shí)候是否正確的處理(之前提到字符串不能換行,遇到一個(gè)突然的換行將會(huì)被看成缺少雙引號(hào)):
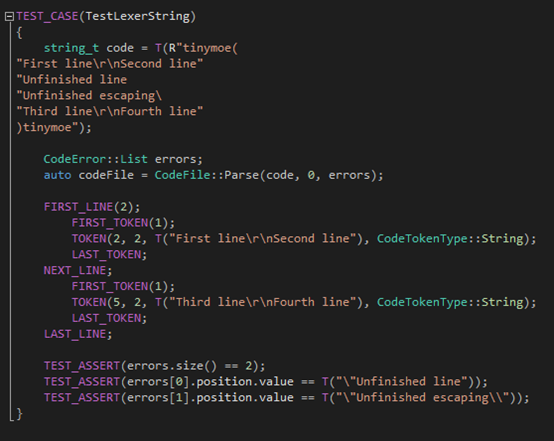
?
鑒于詞法分析本來(lái)內(nèi)容也不多,所以這篇文章也不會(huì)太長(zhǎng)。相信有前途的程序員也會(huì)在這里得到一些編譯原理以外的知識(shí)。下一篇文章將會(huì)描述Tinymoe的函數(shù)頭的語(yǔ)法分析部分,將會(huì)描述一個(gè)編譯器的不帶歧義的語(yǔ)法分析是如何人肉出來(lái)的。敬請(qǐng)期待。
posted @
2014-03-02 07:44 陳梓瀚(vczh) 閱讀(12968) |
評(píng)論 (10) |
編輯 收藏
2014年3月1日
最近學(xué)習(xí)C++11的variadic template argument,終于可以擺脫用fpmacro模板來(lái)復(fù)制一大堆代碼的做法了,好開(kāi)心。這個(gè)例子的main函數(shù)用lambda寫(xiě)了一個(gè)斐波那契數(shù)列的遞歸計(jì)算函數(shù)。跟以往不同的是,在Y函數(shù)的幫助下,這個(gè)lambda表達(dá)是可以成功看到自己,然后遞歸調(diào)用。當(dāng)然這仍然需要用普通的C++遞歸來(lái)實(shí)現(xiàn),并不是λ-calculus那個(gè)高大上的Y Combinator。
?
#include
<functional>
#include
<memory>
#include
<iostream>
#include
<string>
?
using
namespace std;
?
template<typename
TResult, typename ...TArgs>
class
YBuilder
{
private:
????function<TResult(function<TResult(TArgs...)>, TArgs...)> partialLambda;
?
public:
????YBuilder(function<TResult(function<TResult(TArgs...)>, TArgs...)> _partialLambda)
????????:partialLambda(_partialLambda)
????{
????}
?
????TResult operator()(TArgs ...args)const
????{
????????return partialLambda(
????????????[this](TArgs ...args)
????????????{
????????????????return
this->operator()(args...);
????????????}, args...);
????}
};
?
template<typename
TMethod>
struct
PartialLambdaTypeRetriver
{
????typedef
void
FunctionType;
????typedef
void
LambdaType;
????typedef
void
YBuilderType;
};
?
template<typename
TClass, typename
TResult, typename ...TArgs>
struct
PartialLambdaTypeRetriver<TResult(__thiscall
TClass::*)(function<TResult(TArgs...)>, TArgs...)>
{
????typedef
TResult
FunctionType(TArgs...);
????typedef
TResult
LambdaType(function<TResult(TArgs...)>, TArgs...);
????typedef
YBuilder<TResult, TArgs...> YBuilderType;
};
?
template<typename
TClass, typename
TResult, typename ...TArgs>
struct
PartialLambdaTypeRetriver<TResult(__thiscall
TClass::*)(function<TResult(TArgs...)>, TArgs...)const>
{
????typedef
TResult
FunctionType(TArgs...);
????typedef
TResult
LambdaType(function<TResult(TArgs...)>, TArgs...);
????typedef
YBuilder<TResult, TArgs...> YBuilderType;
};
?
template<typename
TLambda>
function<typename
PartialLambdaTypeRetriver<decltype(&TLambda::operator())>::FunctionType> Y(TLambda
partialLambda)
{
????return
typename
PartialLambdaTypeRetriver<decltype(&TLambda::operator())>::YBuilderType(partialLambda);
}
?
int
_tmain(int
argc, _TCHAR* argv[])
{
????auto fib = Y([](function<int(int)> self, int
index)
????{
????????return
index<2
?????????????1
????????????:self(index-1)+self(index-2);
????});
?
????for (int i = 0; i < 10; i++)
????{
????????cout << fib(i) << " ";
????}
????cout << endl;
}
posted @
2014-02-28 08:34 陳梓瀚(vczh) 閱讀(11103) |
評(píng)論 (3) |
編輯 收藏
2014年2月11日
自從《序》胡扯了快一個(gè)月之后,終于迎來(lái)了正片。之所以系列文章叫《看實(shí)例學(xué)編譯原理》,是因?yàn)檎麄€(gè)系列會(huì)通過(guò)帶大家一步一步實(shí)現(xiàn)Tinymoe的過(guò)程,來(lái)介紹編譯原理的一些知識(shí)點(diǎn)。
但是第一個(gè)系列還沒(méi)到開(kāi)始處理Tinymoe源代碼的時(shí)候,首先的跟大家講一講我設(shè)計(jì)Tinymoe的故事。為什么這種東西要等到現(xiàn)在才講呢,因?yàn)橹皼](méi)有文檔,將了也是白講啊。Tinymoe在github的wiki分為兩部分,一部分是介紹語(yǔ)法的,另一部分是介紹一個(gè)最小的標(biāo)準(zhǔn)庫(kù)是如何實(shí)現(xiàn)出來(lái)的,地址在 https://github.com/vczh/tinymoe/wiki 不帶問(wèn)號(hào)的那些都是寫(xiě)完了的。
系列文章的目標(biāo)
在介紹Tinymoe之前,先說(shuō)一下這個(gè)系列文章的目標(biāo)。Ideally,只要一個(gè)人看完了這個(gè)系列,他就可以在下面這些地方得到入門(mén):
當(dāng)然,這并不能讓你成為一個(gè)大牛,但是至少自己做做實(shí)驗(yàn),搞一點(diǎn)高大上的東西騙師妹們是沒(méi)有問(wèn)題了。
Tinymoe設(shè)計(jì)的目標(biāo)
雖然想法很多年前就已經(jīng)有了,但是這次我想把它實(shí)現(xiàn)出來(lái),是為了完成《如何設(shè)計(jì)一門(mén)語(yǔ)言》的后續(xù)。光講大道理是沒(méi)有意義的,至少得有一個(gè)例子,讓大家知道這些事情到底是什么樣子的。因此Tinymoe有一點(diǎn)教學(xué)的意義,不管是使用它還是實(shí)現(xiàn)它。
首先,處理Tinymoe需要的知識(shí)點(diǎn)多,用于編譯原理教學(xué)。既然是為了展示編譯原理的基礎(chǔ)知識(shí),因此語(yǔ)言本身不可能是那種爛大街的C系列的東西。當(dāng)然除了知識(shí)點(diǎn)以外,還會(huì)讓大家深刻的理解到,難實(shí)現(xiàn)和難用,是完全沒(méi)有關(guān)系的!Tinymoe用起來(lái)可爽了,啊哈哈哈哈哈。
其次,Tinymoe容易嵌入其他語(yǔ)言的程序,作為DSL使用,可以調(diào)用宿主程序提供的功能。這嚴(yán)格的來(lái)講不算語(yǔ)言本身的功能,而是實(shí)現(xiàn)本身的功能。就算是C++也可以設(shè)計(jì)為嵌入式,lua也可以被設(shè)計(jì)為編譯成exe的。一個(gè)語(yǔ)言本身的設(shè)計(jì)并不會(huì)對(duì)如何使用它有多大的限制。為了讓大家看了這個(gè)系列之后,可以寫(xiě)出至少可用的東西,而不僅僅是寫(xiě)玩具,因此這也是設(shè)計(jì)的目標(biāo)之一。
第三,Tinymoe語(yǔ)法優(yōu)化于描述復(fù)雜的邏輯,而不是優(yōu)化與復(fù)雜的數(shù)據(jù)結(jié)構(gòu)和算法(雖然也可以)。Tinymoe本身是不存在任何細(xì)粒度控制內(nèi)存的能力的,而且雖然可以實(shí)現(xiàn)復(fù)雜的數(shù)據(jù)結(jié)構(gòu)和算法,但是本身描述這些東西最多也就跟JavaScript一樣容易——其實(shí)就是不容易。但是Tinymoe設(shè)計(jì)的時(shí)候,是為了讓大家把Tinymoe當(dāng)成是一門(mén)可以設(shè)計(jì)DSL的語(yǔ)言,因此對(duì)復(fù)雜邏輯的描述能力特別強(qiáng)。唯一的前提就是,你懂得如何給Tinymoe寫(xiě)庫(kù)。很好的使用和很好地實(shí)現(xiàn)一個(gè)東西是相輔相成的。我在設(shè)計(jì)Tinymoe之初,很多pattern我也不知道,只是因?yàn)樵O(shè)計(jì)Tinymoe遵循了科學(xué)的方法,因此最后我發(fā)現(xiàn)Tinymoe竟然具有如此強(qiáng)大的描述能力。當(dāng)然對(duì)于讀者們本身,也會(huì)在閱讀系列文章的有類(lèi)似的感覺(jué)。
最后,Tinymoe是一個(gè)動(dòng)態(tài)類(lèi)型語(yǔ)言。這純粹是我的個(gè)人愛(ài)好了。對(duì)一門(mén)動(dòng)態(tài)類(lèi)型語(yǔ)言做靜態(tài)分析那該多有趣啊,啊哈哈哈哈哈哈。
Tinymoe的設(shè)計(jì)哲學(xué)
當(dāng)然我并不會(huì)為了寫(xiě)文章就無(wú)線提高Tinymoe的實(shí)現(xiàn)難度的。為了把他控制在一個(gè)正常水平,因此設(shè)計(jì)Tinymoe的第一條就是:
一、小規(guī)模的語(yǔ)言核心+大規(guī)模的標(biāo)準(zhǔn)庫(kù)
其實(shí)這跟C++差不多。但是C++由于想做的事情實(shí)在是太多了,譬如說(shuō)視圖包涵所有范式等等,因此就算這么做,仍然讓C++本身包含的東西過(guò)于巨大(其實(shí)我還是覺(jué)得C++不難怎么辦)。
語(yǔ)言核心小,實(shí)現(xiàn)起來(lái)當(dāng)然容易。但是你并不能為了讓語(yǔ)言核心小就犧牲什么功能。因此精心設(shè)計(jì)一個(gè)核心是必須的,因?yàn)樗心阆胍遣幌爰尤胝Z(yǔ)言的功能,從此就可以用庫(kù)來(lái)實(shí)現(xiàn)了。
譬如說(shuō),Tinymoe通過(guò)有條件地暴露continuation,要求編譯器在編譯Tinymoe的時(shí)候做一次全文CPS變換。這個(gè)東西說(shuō)容易也不是那么容易,但是至少比你做分支循環(huán)異常處理什么的全部加起來(lái)要簡(jiǎn)單多了吧。所以我只提供continuation,剩下的控制流全部用庫(kù)來(lái)做。這樣有三個(gè)好處:
語(yǔ)言簡(jiǎn)單,實(shí)現(xiàn)難度降低。
為了讓庫(kù)可以發(fā)揮應(yīng)有的作用,語(yǔ)言的功能的選擇十分的正交化。不過(guò)這仍然在一定的程度上提高了學(xué)習(xí)的難度。但是并不是所有人都需要寫(xiě)庫(kù)對(duì)吧,很多人只需要會(huì)用庫(kù)就夠了。通過(guò)一點(diǎn)點(diǎn)的犧牲,正交化可以充分發(fā)揮程序員的想象能力。這對(duì)于以DSL為目的的語(yǔ)言來(lái)說(shuō)是不可或缺的。
標(biāo)準(zhǔn)庫(kù)本身可以作為編譯器的測(cè)試用例。你只需要準(zhǔn)備足夠多的測(cè)試用例來(lái)運(yùn)行標(biāo)準(zhǔn)庫(kù),那么你只要用C++(假設(shè)你用C++來(lái)實(shí)現(xiàn)Tinymoe)來(lái)跑他們,那所有的標(biāo)準(zhǔn)庫(kù)都會(huì)得到運(yùn)行。運(yùn)行結(jié)果如果對(duì),那你對(duì)編譯器的實(shí)現(xiàn)也就有信心了。為什么呢,因?yàn)闃?biāo)準(zhǔn)庫(kù)大量的使用了語(yǔ)言的各種功能,而且是無(wú)節(jié)操的使用。如果這樣都能過(guò),那普通的程序就更能過(guò)了。
說(shuō)了這么多,那到底什么是小規(guī)模的語(yǔ)言核心呢?這在Tinymoe上有兩點(diǎn)體現(xiàn)。
第一點(diǎn),就是Tinymoe的語(yǔ)法元素少。一個(gè)Tinymoe表達(dá)式無(wú)非就只有三類(lèi):函數(shù)調(diào)用、字面量和變量、操作符。字面量就是那些數(shù)字字符串什么的。當(dāng)Tinymoe的函數(shù)的某一個(gè)參數(shù)指定為不定個(gè)數(shù)的時(shí)候你還得提供一個(gè)tuple。委托(在這里是函數(shù)指針和閉包的統(tǒng)稱(chēng))和數(shù)組雖然也是Tinymoe的原生功能之一,但是對(duì)他們的操作都是通過(guò)函數(shù)調(diào)用來(lái)實(shí)現(xiàn)的,沒(méi)有特殊的語(yǔ)法。
簡(jiǎn)單地講,就是除了下面這些東西以外你不會(huì)見(jiàn)到別的種類(lèi)的表達(dá)式了:
1
"text"
sum from 1 to 100
sum of (1, 2, 3, 4, 5)
(1+2)*(3+4)
true
一個(gè)Tinymoe語(yǔ)句的種類(lèi)就更少了,要么是一個(gè)函數(shù)調(diào)用,要么是block,要么是連在一起的幾個(gè)block:
do something bad
repeat with x from 1 to 100
do something bad with x
end
try
do something bad
catch exception
do something worse
end
有人可能會(huì)說(shuō),那repeat和try-catch就不是語(yǔ)法元素嗎?這個(gè)真不是,他們是標(biāo)準(zhǔn)庫(kù)定義好的函數(shù),跟你自己聲明的函數(shù)沒(méi)有任何特殊的地方。
這里其實(shí)還有一個(gè)有意思的地方:"repeat with x from 1 to 100"的x其實(shí)是循環(huán)體的參數(shù)。Tinymoe是如何給你自定義的block開(kāi)洞的呢?不僅如此,Tinymoe的函數(shù)還可以聲明"引用參數(shù)",也就是說(shuō)調(diào)用這個(gè)函數(shù)的時(shí)候你只能把一個(gè)變量放進(jìn)去,函數(shù)里面可以讀寫(xiě)這個(gè)變量。這些都是怎么實(shí)現(xiàn)的呢?學(xué)下去就知道了,啊哈哈哈哈。
Tinymoe的聲明也只有兩種,第一種是函數(shù),第二種是符號(hào)。函數(shù)的聲明可能會(huì)略微復(fù)雜一點(diǎn),不過(guò)除了函數(shù)頭以外,其他的都是類(lèi)似配置一樣的東西,幾乎都是用來(lái)定義"catch函數(shù)在使用的時(shí)候必須是連在try函數(shù)后面"啊,"break只能在repeat里面用"啊,諸如此類(lèi)的信息。
Tinymoe的符號(hào)十分簡(jiǎn)單,譬如說(shuō)你要定義一年四季的符號(hào),只需要這么寫(xiě):
symbol spring
symbol summer
symbol autumn
symbol winter
symbol是一個(gè)"與眾不同的值",也就是說(shuō)你在兩個(gè)module下面定義同名的symbol他們也是不一樣的。所有symbol之間都是不一樣的,可以用=和<>來(lái)判斷。symbol就是靠"不一樣"來(lái)定義其自身的。
至于說(shuō),那為什么不用enum呢?因?yàn)門(mén)inymoe是動(dòng)態(tài)類(lèi)型語(yǔ)言,enum的類(lèi)型本身是根本沒(méi)有用武之地的,所以干脆就設(shè)計(jì)成了symbol。
第二點(diǎn),Tinymoe除了continuation和select-case以外,沒(méi)有其他原生的控制流支持。
這基本上歸功于先輩發(fā)明continuation passing style transformation的功勞,細(xì)節(jié)在以后的系列里面會(huì)講。心急的人可以先看 https://github.com/vczh/tinymoe/blob/master/Development/Library/StandardLibrary.txt 。這個(gè)文件暫時(shí)包含了Tinymoe的整個(gè)標(biāo)準(zhǔn)庫(kù),里面定義了很多if-else/repeat/try-catch-finally等控制流,甚至連coroutine都可以用continuation、select-case和遞歸來(lái)做。
這也是小規(guī)模的語(yǔ)言核心+大規(guī)模的標(biāo)準(zhǔn)庫(kù)所要表達(dá)的意思。如果可以提供一個(gè)feature A,通過(guò)他來(lái)完成其他必要的feature B0, B1, B2…的同時(shí),將來(lái)說(shuō)不定還有人可以出于自己的需求,開(kāi)發(fā)DSL的時(shí)候定義feature C,那么只有A需要保留下來(lái),所有的B和C都將使用庫(kù)的方法來(lái)實(shí)現(xiàn)。
這么做并不是完全有益無(wú)害的,只是壞處很小,在"Tinymoe的實(shí)現(xiàn)難點(diǎn)"里面會(huì)詳細(xì)說(shuō)明。
二、擴(kuò)展后的東西跟原生的東西外觀一致
這是很重要的。如果擴(kuò)展出來(lái)的東西跟原生的東西長(zhǎng)得不一樣,用起來(lái)就覺(jué)得很傻逼。Java的string不能用==來(lái)判斷內(nèi)容就是這樣的一個(gè)例子。雖然他們有的是理由證明==的反直覺(jué)設(shè)計(jì)是對(duì)的——但是反直覺(jué)就是反直覺(jué),就是一個(gè)大坑。
這種例子還有很多,譬如說(shuō)go的數(shù)組和表的類(lèi)型啦,go本身如果不要數(shù)組和表的話,是寫(xiě)不出長(zhǎng)得跟原生數(shù)組和表一樣的數(shù)組和表的。其實(shí)這也不是一個(gè)大問(wèn)題,問(wèn)題是go給數(shù)組和表的樣子搞特殊化,還有那個(gè)反直覺(jué)的slice的賦值問(wèn)題(會(huì)合法溢出!),類(lèi)似的東西實(shí)在是太多了。一個(gè)東西特例太多,坑就無(wú)法避免。所以其實(shí)在我看來(lái),go還不如給C語(yǔ)言加上erlang的actor功能了事。
反而C++在這件事情上就做得很好。如果你對(duì)C++不熟悉的話,有時(shí)候根本分不清什么是編譯器干的,什么是標(biāo)準(zhǔn)庫(kù)干的。譬如說(shuō)static_cast和dynamic_cast長(zhǎng)得像一個(gè)模板函數(shù),因此boost就可以用類(lèi)似的手法加入lexical_cast和針對(duì)shared_ptr的static_pointer_cast和dynamic_pointer_cast,整個(gè)標(biāo)準(zhǔn)庫(kù)和語(yǔ)言本身渾然一體。這樣子做的好處是,當(dāng)你在培養(yǎng)對(duì)語(yǔ)言本身的直覺(jué)的時(shí)候,你也在培養(yǎng)對(duì)標(biāo)準(zhǔn)庫(kù)的直覺(jué),培養(yǎng)直覺(jué)這件事情你不用做兩次。你對(duì)一個(gè)東西的直覺(jué)越準(zhǔn),學(xué)習(xí)新東西的速度就越快。所以C++的設(shè)計(jì)剛好可以讓你在熬過(guò)第一個(gè)階段的學(xué)習(xí)之后,后面都覺(jué)得無(wú)比的輕松。
不過(guò)具體到Tinymoe,因?yàn)門(mén)inymoe本身的語(yǔ)法元素太少了,所以這個(gè)做法在Tinymoe身上體現(xiàn)得不明顯。
Tinymoe的實(shí)現(xiàn)難點(diǎn)
首先,語(yǔ)法分析需要對(duì)Tinymoe程序處理三遍。Tinymoe對(duì)于語(yǔ)句設(shè)計(jì)使得對(duì)一個(gè)Tinymoe程序做語(yǔ)法分析不是那么直接(雖然比C++什么的還是容易多了)。舉個(gè)例子:
module hello world
phrase sum from (lower bound) to (upper bound)
…
end
sentence print (message)
…
end
phrase main
print sum from 1 to 100
end
第一遍分析是詞法分析,這個(gè)時(shí)候得把每一個(gè)token的行號(hào)記住。第二遍分析是不帶歧義的語(yǔ)法分析,目標(biāo)是把所有的函數(shù)頭抽取出來(lái),然后組成一個(gè)全局符號(hào)表。第三遍分析就是對(duì)函數(shù)體里面的語(yǔ)句做帶歧義的語(yǔ)法分析了。因?yàn)門(mén)inymoe允許你定義變量,所以符號(hào)表肯定是一邊分析一邊修改的。于是對(duì)于"print sum from 1 to 100"這一句,如果你沒(méi)有發(fā)現(xiàn)"phrase sum from (lower bound) to (upper bound)"和"sentence print (message)",那根本無(wú)從下手。
還有另一個(gè)例子:
module exception handling
…
phrase main
try
do something bad
catch
print "bad thing happened"
end
end
當(dāng)語(yǔ)法分析做到"try"的時(shí)候,因?yàn)榘l(fā)現(xiàn)存在try函數(shù)的定義,所以Tinymoe知道接下來(lái)的"do something bad"屬于調(diào)用try這個(gè)塊函數(shù)所需提供的代碼塊里面的代碼。接下來(lái)是"catch",Tinymoe怎么知道catch是接在try后面,而不是放在try里面的呢?這仍然是由于catch函數(shù)的定義告訴我們的。關(guān)于這方面的語(yǔ)法知識(shí)可以點(diǎn)擊這里查看。
正因?yàn)槿绱耍覀冃枰紫戎篮瘮?shù)的定義,然后才能分析函數(shù)體里面的代碼。雖然這在一定程度上造成了Tinymoe的語(yǔ)法分析復(fù)雜度的提升,但是其復(fù)雜度本身并不高。比C++簡(jiǎn)單就不說(shuō)了,就算是C、C#和Java,由于其語(yǔ)法元素太多,導(dǎo)致不需要多次分析所降低的復(fù)雜度被完全的抵消,結(jié)果跟實(shí)現(xiàn)Tinymoe的語(yǔ)法分析器的難度不相上下。
其次,CPS變換后的代碼需要特殊處理,否則直接執(zhí)行容易導(dǎo)致call stack積累的沒(méi)用的東西過(guò)多。因?yàn)門(mén)inymoe可以自定義操作符,所以操作符跟C++一樣在編譯的時(shí)候被轉(zhuǎn)換成了函數(shù)調(diào)用。每一個(gè)函數(shù)調(diào)用都是會(huì)被CPS變換的。盡管每一行的函數(shù)調(diào)用次數(shù)不多,但是如果你的程序油循環(huán),循環(huán)是通過(guò)遞歸來(lái)描述(而不是實(shí)現(xiàn),由于CPS變換后Tinymoe做了優(yōu)化,所以不存在實(shí)際上的遞歸)的,如果直接執(zhí)行CPS變換后的代碼,算一個(gè)1加到1000都會(huì)導(dǎo)致stack overflow。可見(jiàn)其call stack里面堆積的closure數(shù)量之巨大。
我在做Tinymoe代碼生成的實(shí)驗(yàn)的時(shí)候,為了簡(jiǎn)單我在單元測(cè)試?yán)锩嬷苯赢a(chǎn)生了對(duì)應(yīng)的C#代碼。一開(kāi)始沒(méi)有處理CPS而直接調(diào)用,程序不僅慢,而且容易stack overflow。但是我們知道(其實(shí)你們以后才會(huì)知道),CPS變換后的代碼里面幾乎所有的call stack項(xiàng)都是浪費(fèi)的,因此我把整個(gè)在生成C#代碼的時(shí)候修改成,如果需要調(diào)用continuation,就返回調(diào)用continuation的語(yǔ)句組成的lambda表達(dá)式,在最外層用一個(gè)循環(huán)去驅(qū)動(dòng)他直到返回null為止。這樣做了之后,就算Tinymoe的代碼有遞歸,call stack里面也不會(huì)因?yàn)檫f歸而積累call stack item了。于是生成的C#代碼執(zhí)行飛快,而且無(wú)論你怎么遞歸也永遠(yuǎn)不會(huì)造成stack overflow了。這個(gè)美妙的特性幾乎所有語(yǔ)言都做不到,啊哈哈哈哈哈。
當(dāng)然這也是有代價(jià)的,因?yàn)楸举|(zhì)上我只是把保存在stack上的context轉(zhuǎn)移到heap上。不過(guò)多虧了.net 4.0的強(qiáng)大的background GC,這樣做絲毫沒(méi)有多余的性能上的損耗。當(dāng)然這也意味著,一個(gè)高性能的Tinymoe虛擬機(jī),需要一個(gè)牛逼的垃圾收集器作為靠山。context產(chǎn)生的closure在函數(shù)體真的被執(zhí)行完之后就會(huì)被很快地收集,所以CPS加上這種做法并不會(huì)對(duì)GC產(chǎn)生額外的壓力,所有的壓力仍然來(lái)源于你自己所創(chuàng)建的數(shù)據(jù)結(jié)構(gòu)。
第三,Tinymoe需要?jiǎng)討B(tài)類(lèi)型語(yǔ)言的類(lèi)型推導(dǎo)。當(dāng)然你不這么做而把Tinymoe的程序當(dāng)JavaScript那樣的程序處理也沒(méi)有問(wèn)題。但是我們知道,正是因?yàn)閂8對(duì)JavaScript的代碼進(jìn)行了類(lèi)型推導(dǎo),才產(chǎn)生了那么優(yōu)異的性能。因此這算是一個(gè)優(yōu)化上的措施。
最后,Tinymoe還需要跨過(guò)程分析和對(duì)程序的控制流的化簡(jiǎn)(譬如continuation轉(zhuǎn)狀態(tài)機(jī)等)。目前具體怎么做我還在學(xué)習(xí)當(dāng)中。不過(guò)我們想,既然repeat函數(shù)是通過(guò)遞歸來(lái)描述的,那我們能不能通過(guò)對(duì)所有代碼進(jìn)行inter-procedural analyzing,從而發(fā)現(xiàn)諸如
repeat 3 times
do something good
end
就是一個(gè)循環(huán),從而生成用真正的循環(huán)指令(譬如說(shuō)goto)呢?這個(gè)問(wèn)題是個(gè)很有意思的問(wèn)題,我覺(jué)得我如果可以通過(guò)學(xué)習(xí)靜態(tài)分析從而解決它,不進(jìn)我的能力會(huì)得到提升,我對(duì)你們的科普也會(huì)做得更好。
后記
雖然還不到五千字,但是總覺(jué)得寫(xiě)了好多的樣子。總之我希望讀者在看完《零》和《一》之后,對(duì)接下來(lái)需要學(xué)習(xí)的東西有一個(gè)較為清晰的認(rèn)識(shí)。
posted @
2014-02-10 20:53 陳梓瀚(vczh) 閱讀(16299) |
評(píng)論 (11) |
編輯 收藏
2014年1月19日
在《如何設(shè)計(jì)一門(mén)語(yǔ)言》里面,我講了一些語(yǔ)言方面的東西,還有痛快的噴了一些XX粉什么的。不過(guò)單純講這個(gè)也是很無(wú)聊的,所以我開(kāi)了這個(gè)《跟vczh看實(shí)例學(xué)編譯原理》系列,意在科普一些編譯原理的知識(shí),盡量讓大家可以在創(chuàng)造語(yǔ)言之后,自己寫(xiě)一個(gè)原型。在這里我拿我創(chuàng)造的一門(mén)很有趣的語(yǔ)言 https://github.com/vczh/tinymoe/ 作為實(shí)例。
商業(yè)編譯器對(duì)功能和質(zhì)量的要求都是很高的,里面大量的東西其實(shí)都跟編譯原理沒(méi)關(guān)系。一個(gè)典型的編譯原理的原型有什么特征呢?
性能低
錯(cuò)誤信息難看
沒(méi)有檢查所有情況就生成代碼
優(yōu)化做得爛
幾乎沒(méi)有編譯選項(xiàng)
等等。Tinymoe就滿(mǎn)足了上面的5種情況,因?yàn)槲业哪繕?biāo)也只是想做一個(gè)原型,向大家介紹編譯原理的基礎(chǔ)知識(shí)。當(dāng)然,我對(duì)語(yǔ)法的設(shè)計(jì)還是盡量靠近工業(yè)質(zhì)量的,只是實(shí)現(xiàn)沒(méi)有花太多心思。
為什么我要用Tinymoe來(lái)作為實(shí)例呢?因?yàn)門(mén)inymoe是少有的一種用起來(lái)簡(jiǎn)單,而且?guī)炜梢杂卸鄰?fù)雜寫(xiě)多復(fù)雜的語(yǔ)言,就跟C++一樣。C++11額標(biāo)準(zhǔn)庫(kù)在一起用簡(jiǎn)直是愉快啊,Tinymoe的代碼也是這么寫(xiě)的。但是這并不妨礙你可以在寫(xiě)C++庫(kù)的時(shí)候發(fā)揮你的想象力。Tinymoe也是一樣的。為什么呢,我來(lái)舉個(gè)例子。
Hello, world!
Tinymoe的hello world程序是很簡(jiǎn)單的:
module hello world
using standard library
sentence print (message)
redirect to "printf"
end
phrase main
print "Hello, world!"
end
module指的是模塊的名字,普通的程序也是一個(gè)模塊。using指的是你要引用的模塊——standard library就是Tinymoe的STL了——當(dāng)然這個(gè)程序并沒(méi)有用到任何standard library的東西。說(shuō)到這里大家可能意識(shí)到了,Tinymoe的名字可以是不定長(zhǎng)的token組成的!沒(méi)錯(cuò),后面大家會(huì)慢慢意識(shí)到這種做法有多么的強(qiáng)大。
后面是print函數(shù)和main函數(shù)。Tinymoe是嚴(yán)格區(qū)分語(yǔ)句和表達(dá)式的,只有sentence和block開(kāi)頭的函數(shù)才能作為語(yǔ)句,而且同時(shí)只有phrase開(kāi)頭的函數(shù)才能作為表達(dá)式。所以下面的程序是不合法的:
phrase main
(print "Hello, world!") + 1
end
原因就是,print是sentence,不能作為表達(dá)式使用,因此他不能被+1。
Tinymoe的函數(shù)參數(shù)都被寫(xiě)在括號(hào)里面,一個(gè)參數(shù)需要一個(gè)括號(hào)。到了這里大家可能會(huì)覺(jué)得很奇怪,不過(guò)很快就會(huì)有解答了。為什么要這么做,下一個(gè)例子就會(huì)告訴我們。
print函數(shù)用的redirect to是Tinymoe聲明FFI(Foreign Function Interface)的方法,也就是說(shuō),當(dāng)你運(yùn)行了print,他就會(huì)去host里面找一個(gè)叫做printf的函數(shù)來(lái)運(yùn)行。不過(guò)大家不要誤會(huì),Tinymoe并沒(méi)有被設(shè)計(jì)成可以直接調(diào)用C函數(shù),所以這個(gè)名字其實(shí)是隨便寫(xiě)的,只要host提供了一個(gè)叫做printf的函數(shù)完成printf該做的事情就行了。main函數(shù)就不用解釋了,很直白。
1加到100等于5050
這個(gè)例子可以在Tinymoe的主頁(yè)(https://github.com/vczh/tinymoe/)上面看到:
module hello world
using standard library
sentence print (message)
redirect to "printf"
end
phrase sum from (start) to (end)
set the result to 0
repeat with the current number from start to end
add the current number to the result
end
end
phrase main
print "1+ ... +100 = " & sum from 1 to 100
end
為什么名字可以是多個(gè)token?為什么每一個(gè)參數(shù)都要一個(gè)括號(hào)?看加粗的部分就知道了!正是因?yàn)門(mén)inymoe想讓每一行代碼都可以被念出來(lái),所以才這么設(shè)計(jì)的。當(dāng)然,大家肯定都知道怎么算start + (start+1) + … + (end-1) + end了,所以應(yīng)該很容易就可以看懂這個(gè)函數(shù)里面的代碼具體是什么意思。
在這里可以稍微多做一下解釋。the result是一個(gè)預(yù)定義的變量,代表函數(shù)的返回值。只要你往the result里面寫(xiě)東西,只要函數(shù)一結(jié)束,他就變成函數(shù)的返回值了。Tinymoe的括號(hào)沒(méi)有什么特殊意思,就是改變優(yōu)先級(jí),所以那一句循環(huán)則可以通過(guò)添加括號(hào)的方法寫(xiě)成這樣:
repeat with (the current number) from (start) to (end)
大家可能會(huì)想,repeat with是不是關(guān)鍵字?當(dāng)然不是!repeat with是standard library里面定義的一個(gè)block函數(shù)。大家知道block函數(shù)的意思了吧,就是這個(gè)函數(shù)可以帶一個(gè)block。block有一些特性可以讓你寫(xiě)出類(lèi)似try-catch那樣的幾個(gè)block連在一起的大block,特別適合寫(xiě)庫(kù)。
到了這里大家心中可能會(huì)有疑問(wèn),循環(huán)為什么可以做成庫(kù)呢?還有更加令人震驚的是,break和continue也不是關(guān)鍵字,是sentence!因?yàn)閞epeat with是有代碼的:
category
start REPEAT
closable
block (sentence deal with (item)) repeat with (argument item) from (lower bound) to (upper bound)
set the current number to lower bound
repeat while the current number <= upper bound
deal with the current number
add 1 to the current number
end
end
前面的category是用來(lái)定義一些block的順序和包圍結(jié)構(gòu)什么的。repeat with是屬于REPEAT的,而break和continue聲明了自己只能直接或者間接方在REPEAT里面,因此如果你在一個(gè)沒(méi)有循環(huán)的地方調(diào)用break或者continue,編譯器就會(huì)報(bào)錯(cuò)了。這是一個(gè)花邊功能,用來(lái)防止手誤的。
大家可能會(huì)注意到一個(gè)新東西:(argument item)。argument的意思指的是,后面的item是block里面的代碼的一個(gè)參數(shù),對(duì)于repeat with函數(shù)本身他不是一個(gè)參數(shù)。這就通過(guò)一個(gè)很自然的方法給block添加參數(shù)了。如果你用ruby的話就得寫(xiě)成這個(gè)悲催的樣子:
repeat_with(1, 10) do |item|
xxxx
end
而用C++寫(xiě)起來(lái)就更悲催了:
repeat_with(1, 10, [](int item)
{
xxxx
});
block的第一個(gè)參數(shù)sentence deal with (item)就是一個(gè)引用了block中間的代碼的委托。所以你會(huì)看到代碼里面會(huì)調(diào)用它。
好了,那repeat while總是關(guān)鍵字了吧——不是!后面大家還會(huì)知道,就連
if xxx
yyy
else if zzz
www
else if aaa
bbb
else
ccc
end
也只是你調(diào)用了if、else if和else的一系列函數(shù)然后讓他們串起來(lái)而已。
那Tinymoe到底提供了什么基礎(chǔ)設(shè)施呢?其實(shí)只有select-case和遞歸。用這兩個(gè)東西,加上內(nèi)置的數(shù)組,就圖靈完備了。圖靈完備就是這么容易啊。
多重分派(Multiple Dispatch)
講到這里,我不得不說(shuō),Tinymoe也可以寫(xiě)類(lèi),也可以繼承,不過(guò)他跟傳統(tǒng)的語(yǔ)言不一樣的,類(lèi)是沒(méi)有構(gòu)造函數(shù)、析構(gòu)函數(shù)和其他成員函數(shù)的。Tinymoe所有的函數(shù)都是全局函數(shù),但是你可以使用多重分派來(lái)"挑選"類(lèi)型。這就需要第三個(gè)例子了(也可以在主頁(yè)上找到):
module geometry
using standard library
phrase square root of (number)
redirect to "Sqrt"
end
sentence print (message)
redirect to "Print"
end
type rectangle
width
height
end
type triangle
a
b
c
end
type circle
radius
end
phrase area of (shape)
raise "This is not a shape."
end
phrase area of (shape : rectangle)
set the result to field width of shape * field height of shape
end
phrase area of (shape : triangle)
set a to field a of shape
set b to field b of shape
set c to field c of shape
set p to (a + b + c) / 2
set the result to square root of (p * (p - a) * (p - b) * (p - c))
end
phrase area of (shape : circle)
set r to field radius of shape
set the result to r * r * 3.14
end
phrase (a) and (b) are the same shape
set the result to false
end
phrase (a : rectangle) and (b : rectangle) are the same shape
set the result to true
end
phrase (a : triangle) and (b : triangle) are the same shape
set the result to true
end
phrase (a : circle) and (b : circle) are the same shape
set the result to true
end
phrase main
set shape one to new triangle of (2, 3, 4)
set shape two to new rectangle of (1, 2)
if shape one and shape two are the same shape
print "This world is mad!"
else
print "Triangle and rectangle are not the same shape!"
end
end
這個(gè)例子稍微長(zhǎng)了一點(diǎn)點(diǎn),不過(guò)大家可以很清楚的看到我是如何定義一個(gè)類(lèi)型、創(chuàng)建他們和訪問(wèn)成員變量的。area of函數(shù)可以計(jì)算一個(gè)平面幾何圖形的面積,而且會(huì)根據(jù)你傳給他的不同的幾何圖形而使用不同的公式。當(dāng)所有的類(lèi)型判斷都失敗的時(shí)候,就會(huì)掉進(jìn)那個(gè)沒(méi)有任何類(lèi)型聲明的函數(shù),從而引發(fā)一場(chǎng)。嗯,其實(shí)try/catch/finally/raise都是函數(shù)來(lái)的——Tinymoe對(duì)控制流的控制就是如此強(qiáng)大,啊哈哈哈哈。就連return都可以自己做,所以Tinymoe也不提供預(yù)定義的return。
那phrase (a) and (b) are the same shape怎么辦呢?沒(méi)問(wèn)題,Tinymoe可以同時(shí)指定多個(gè)參數(shù)的類(lèi)型。而且Tinymoe的實(shí)現(xiàn)具有跟C++虛函數(shù)一樣的性質(zhì)——無(wú)論你有多少個(gè)參數(shù)標(biāo)記了類(lèi)型,我都可以O(shè)(n)跳轉(zhuǎn)到一個(gè)你需要的函數(shù)。這里的n指的是標(biāo)記了類(lèi)型的參數(shù)的個(gè)數(shù),而不是函數(shù)實(shí)例的個(gè)數(shù),所以跟C++的情況是一樣的——因?yàn)閠his只能有一個(gè),所以就是O(1)。至于Tinymoe到底是怎么實(shí)現(xiàn)的,只需要看《如何設(shè)計(jì)一門(mén)語(yǔ)言》第五篇(http://www.shnenglu.com/vczh/archive/2013/05/25/200580.html)就有答案了。
Continuation Passing Style
為什么Tinymoe的控制流都可以自己做呢?因?yàn)門(mén)inymoe的函數(shù)都是寫(xiě)成了CPS這種風(fēng)格的。其實(shí)CPS大家都很熟悉,當(dāng)你用jquery做動(dòng)畫(huà),用node.js做IO的時(shí)候,那些嵌套的一個(gè)一個(gè)的lambda表達(dá)式,就有點(diǎn)CPS的味道。不過(guò)在這里我們并沒(méi)有看到嵌套的lambda,這是因?yàn)門(mén)inymoe提供的語(yǔ)法,讓Tinymoe的編譯器可以把同一個(gè)層次的代碼,轉(zhuǎn)成嵌套的lambda那樣的代碼。這個(gè)過(guò)程就叫CPS變換。Tinymoe雖然用了很多函數(shù)式編程的手段,但是他并不是一門(mén)函數(shù)是語(yǔ)言,只是一門(mén)普通的過(guò)程式語(yǔ)言。但是這跟C語(yǔ)言不一樣,因?yàn)樗BC#的yield return都可以寫(xiě)成函數(shù)!這個(gè)例子就更長(zhǎng)了,大家可以到Tinymoe的主頁(yè)上看。我這里只貼一小段代碼:
module enumerable
using standard library
symbol yielding return
symbol yielding break
type enumerable collection
body
end
type collection enumerator
current yielding result
body
continuation
end
略(這里實(shí)現(xiàn)了跟enumerable相關(guān)的函數(shù),包括yield return)
block (sentence deal with (item)) repeat with (argument item) in (items : enumerable collection)
set enumerator to new enumerator from items
repeat
move enumerator to the next
deal with current value of enumerator
end
end
sentence print (message)
redirect to "Print"
end
phrase main
create enumerable to numbers
repeat with i from 1 to 10
print "Enumerating " & i
yield return i
end
end
repeat with number in numbers
if number >= 5
break
end
print "Printing " & number
end
end
什么叫模擬C#的yield return呢?就是連惰性計(jì)算也一起模擬!在main函數(shù)的第一部分,我創(chuàng)建了一個(gè)enumerable(iterator),包含1到10十個(gè)數(shù)字,而且每產(chǎn)生一個(gè)數(shù)字還會(huì)打印出一句話。但是接下來(lái)我在循環(huán)里面只取前5個(gè),打印前4個(gè),因此執(zhí)行結(jié)果就是
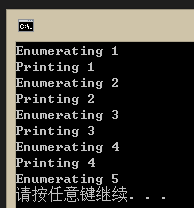
當(dāng)!
CPS風(fēng)格的函數(shù)的威力在于,每一個(gè)函數(shù)都可以控制他如何執(zhí)行函數(shù)結(jié)束之后寫(xiě)在后面的代碼。也就是說(shuō),你可以根據(jù)你的需要,干脆選擇保護(hù)現(xiàn)場(chǎng),然后以后再回復(fù)。是不是聽(tīng)起來(lái)很像lua的coroutine呢?在Tinymoe,coroutine也可以自己做!
雖然函數(shù)最后被轉(zhuǎn)換成了CPS風(fēng)格的ast,而且測(cè)試用的生成C#代碼的確也是原封不動(dòng)的輸出了出來(lái),所以運(yùn)行這個(gè)程序耗費(fèi)了大量的函數(shù)調(diào)用。但這并不意味著Tinymoe的虛擬機(jī)也要這么做。大家要記住,一個(gè)語(yǔ)言也好,類(lèi)庫(kù)也好,給你的接口的概念,跟實(shí)現(xiàn)的概念,有可能完全不同。yield return寫(xiě)出來(lái)的確要花費(fèi)點(diǎn)心思,所以《序言》我也不講這么多了,后續(xù)的文章會(huì)詳細(xì)介紹這方面的知識(shí),當(dāng)然了,還會(huì)告訴你怎么實(shí)現(xiàn)的。
尾聲
這里我挑選了四個(gè)例子來(lái)展示Tinymoe最重要的一些概念。一門(mén)語(yǔ)言,要應(yīng)用用起來(lái)簡(jiǎn)單,庫(kù)寫(xiě)起來(lái)可以發(fā)揮想象力,才是有前途的。yield return例子里面的main函數(shù)一樣,用的時(shí)候多清爽,清爽到讓你完全忘記yield return實(shí)現(xiàn)的時(shí)候里面的各種麻煩的細(xì)節(jié)。
所以為什么我要挑選Tinymoe作為實(shí)例來(lái)科普編譯原理呢?有兩個(gè)原因。第一個(gè)原因是,想要實(shí)現(xiàn)Tinymoe,需要大量的知識(shí)。所以既然這個(gè)系列想讓大家能夠看完實(shí)現(xiàn)一個(gè)Tinymoe的低質(zhì)量原型,當(dāng)然會(huì)講很多知識(shí)的。第二個(gè)原因是,我想通過(guò)這個(gè)例子向大家將一個(gè)道理,就是庫(kù)和應(yīng)用 、編譯器和語(yǔ)法、實(shí)現(xiàn)和接口,完全可以做到隔離復(fù)雜,只留給最終用戶(hù)簡(jiǎn)單的部分。你看到的復(fù)雜的接口,并不意味著他的實(shí)現(xiàn)是臃腫的。你看到的簡(jiǎn)單的接口,也不意味著他的實(shí)現(xiàn)就很簡(jiǎn)潔。
Tinymoe目前已經(jīng)可以輸出C#代碼來(lái)執(zhí)行了。后面我還會(huì)給Tinymoe加上靜態(tài)分析和類(lèi)型推導(dǎo)。對(duì)于這類(lèi)語(yǔ)言做靜態(tài)分析和類(lèi)型推導(dǎo)又很多麻煩,我現(xiàn)在還沒(méi)有完全搞明白。譬如說(shuō)這種可以自己控制continuation的函數(shù)要怎么編譯成狀態(tài)機(jī)才能避免掉大量的函數(shù)調(diào)用,就不是一個(gè)容易的問(wèn)題。所以在系列一邊做的時(shí)候,我還會(huì)一邊研究這個(gè)事情。如果到時(shí)候系列把編譯部分寫(xiě)完的同時(shí),這些問(wèn)題我也搞明白的話,那我就會(huì)讓這個(gè)系列擴(kuò)展到包含靜態(tài)分析和類(lèi)型推導(dǎo),繼續(xù)往下講。
posted @
2014-01-18 09:21 陳梓瀚(vczh) 閱讀(51210) |
評(píng)論 (4) |
編輯 收藏
2014年1月4日
2013年我就干了兩件事情。第一件是gaclib,第二件是tinymoe。
Gaclib終于做到安全的支持C++的反射、從XML加載窗口和控件了。現(xiàn)在在實(shí)現(xiàn)的東西則是一個(gè)給gaclib用的workflow小腳本,用來(lái)寫(xiě)一些簡(jiǎn)單的view的邏輯、定義viewmodel接口,還有跟WPF差不多的data binding。
Tinymoe是我大二的時(shí)候就設(shè)計(jì)出來(lái)的東西,無(wú)奈以前對(duì)計(jì)算機(jī)的理論基礎(chǔ)了解的太少,以至于沒(méi)法實(shí)現(xiàn),直到現(xiàn)在才能做出來(lái)。總的來(lái)說(shuō)tinymoe是一個(gè)模仿英語(yǔ)語(yǔ)法的嚴(yán)肅的編程語(yǔ)言——也就是說(shuō)它是不基于NLP的,語(yǔ)法是嚴(yán)格的,寫(xiě)錯(cuò)一個(gè)單詞也會(huì)編譯不過(guò)。因此所有的函數(shù)都要寫(xiě)成短語(yǔ),包括控制流語(yǔ)句也是。所以我就想了一想,能不能讓分支、循環(huán)、異常處理和異步處理等等其他語(yǔ)言的內(nèi)置的功能在我這里都變成庫(kù)?這當(dāng)然是可以的,只要做全文的cps變換,然后要求這些控制流函數(shù)也寫(xiě)成cps的風(fēng)格就可以了。
目前的第一個(gè)想法是,等搞好了之后先生成javascript或者C#的代碼,不太想寫(xiě)自己的VM了,然后就出一個(gè)系列文章叫做《看實(shí)例跟大牛學(xué)編譯原理》,就以這個(gè)tinymoe作為例子,來(lái)把《如何設(shè)計(jì)一門(mén)語(yǔ)言》延續(xù)下去,啊哈哈哈哈哈。
寫(xiě)博客是一件很難的事情。我大三開(kāi)始經(jīng)營(yíng)這個(gè)cppblog/cnblogs的博客的時(shí)候,一天都可以寫(xiě)一篇,基本上是在記錄我學(xué)到的東西和我造的輪子。現(xiàn)在都比較懶了,覺(jué)得整天說(shuō)自己在開(kāi)發(fā)什么也沒(méi)意思了,于是想寫(xiě)一些別的,竟然不知如何下手,于是就出了各種沒(méi)填完的系列。
我覺(jué)得我學(xué)編程這13年來(lái)也是學(xué)到了不少東西的,除了純粹的api和語(yǔ)言的知識(shí)以外,很多方法論都給我起到了十分重要的作用。一開(kāi)始是面向?qū)ο螅缓笫菙?shù)據(jù)結(jié)構(gòu)算法,然后是面向方面編程,然后是函數(shù)式編程,后來(lái)還接觸了各種跟函數(shù)式編程有關(guān)的概念,譬如說(shuō)reactive programming啊,actor啊,異步啊,continuation等等。腦子里充滿(mǎn)了各種各樣的方法論和模型之后,現(xiàn)在無(wú)論寫(xiě)什么程序,幾乎都可以拿這些東西往上套,然后做出一個(gè)維護(hù)也很容易(前提是有這些知識(shí)),代碼也很簡(jiǎn)潔的程序了。
工作的這四年半里,讓我學(xué)習(xí)到了文檔和自動(dòng)化測(cè)試的重要性,于是利用這幾年我把文檔和測(cè)試的能力也鍛煉的差不多了。現(xiàn)在我覺(jué)得,技術(shù)的話工作應(yīng)付起來(lái)是超級(jí)簡(jiǎn)單,但是自己對(duì)技術(shù)的熱情還是促使我不斷的研究下去。2014年應(yīng)該研究的技能就是嘴炮了。
posted @
2014-01-04 05:52 陳梓瀚(vczh) 閱讀(10166) |
評(píng)論 (9) |
編輯 收藏
2013年11月10日
摘要: 在思考怎么寫(xiě)這一篇文章的時(shí)候,我又想到了以前討論正交概念的事情。如果一個(gè)系統(tǒng)被設(shè)計(jì)成正交的,他的功能擴(kuò)展起來(lái)也可以很容易的保持質(zhì)量這是沒(méi)錯(cuò)的,但是對(duì)于每一個(gè)單獨(dú)給他擴(kuò)展功能的個(gè)體來(lái)說(shuō),這個(gè)系統(tǒng)一點(diǎn)都不好用。所以我覺(jué)得現(xiàn)在的語(yǔ)言被設(shè)計(jì)成這樣也是有那么點(diǎn)道理的。就算是設(shè)計(jì)Java的那誰(shuí),他也不是傻逼,那為什么Java會(huì)被設(shè)計(jì)成這樣?我覺(jué)得這跟他剛開(kāi)始想讓金字塔的底層程序員也可以順利使用Java是有關(guān)系...
閱讀全文
posted @
2013-11-10 01:06 陳梓瀚(vczh) 閱讀(10100) |
評(píng)論 (6) |
編輯 收藏