Dynamo 是 Amazon 公司的一個分布式存儲引擎。 那么這個什么引擎又是什么?
首先�����,假設一個場景�����,你的網站要存儲用戶登陸的IP�����。這個問題怎么解決呢?傳統的方法是用數據庫。數據庫提供了方便的操作接口�����,復雜的查詢能力以及事物的保證�����。
好,現在假設大家都很喜歡你的網站�����,訪問的人越來越多�����。一個數據庫已經處理不過來了�����。于是你安裝了3臺數據庫主機,把用戶分成了三類(男人�����,女人�����,IT人;總是有某種方法把用戶分成數目大致差不多的幾個部分吧)�����。
每次訪問的時候�����,先看用戶屬于哪一類,然后直接訪問存儲那類用戶數據的數據庫。于是處理能力增加了三倍�����。這個時候你已經實現了一個分布式的存儲引 擎�����,Dynamo 就是一個類似的東西。只是它的可靠性�����,可用性等方面更好一點而已�����。下面我們看看那個簡單的分布式存儲系統有什么不方便的地方�����,而Dynamo是如何解決 的。
簡單分布式系統實現云存儲可能存在的問題先列舉一下簡單的分布式系統可能存在的問題吧:
1 很難擴容 :如果現在業務發展迅速�����,3臺主機撐不住了�����,需要加到5臺主機�����,那要如何處理呢?首先要更改分類方法,把用戶分成5類�����,然后重新遷移已經存在的數據�����。你要在網站上貼個條子,“系統維護中”,然后開始偉大的遷移工程�����,等到終于遷移完成�����,發現其實3臺也不用了�����,用戶都走光了。
2 數據可靠性 無法保證:有一天�����,發現有一臺數據庫服務器的硬盤壞了�����,這下麻煩就來了�����,本來網站就不賺錢,沒用什么高檔機器,只有一個定期的增量備份而已�����。經過一天復雜的恢復工作�����,你還要對部分用戶說�����,麻煩你們把做過的事情再做一遍啊。
3 單點問題 :負責把用戶分類�����,然后決定使用哪個數據服務器的那臺主機是網站的命根子啊�����,它如果宕機�����,所有的數據都不能訪問了,它如果滿負荷了,增加數據服務器也不會對整體性能有幫助。我好像看到一臺貼滿著驅邪保平安符咒的pc server。
這幾個問題,看似不大,解決起來還真的不容易呢�����。尤其是想到自己的網站也許有一天也會和google有一樣多的用戶(可能因為你是天才或者google快倒閉了)?����,F在我們看看 Dynnamo 是怎么解決的吧。
http://hi.baidu.com/beibeiboo/blog/item/71654029e81001f498250a0f.html Dynamo虛節點思想解決擴容問題
Dynamo虛節點思想解決擴容問題�����,這個問題實際上是數據分布方式的問題(怎么分組)�����。最簡單最容易想到的就是根據資源數目對數據進行哈希分布�����,比如算 出一個哈希值,然后對資源數取模�����。這種簡單處理的結果就是當資源數變化的時候�����,每個數據重新取模后�����,其分布方式都可能變化,從而需要遷移大量的數據�����。
舉個簡單的例子來說明一下�����,假設我的數據是自然數(1-20),資源現在是三臺主機(A�����,B,C)�����,采用取模分配方式�����,那么分配后A主機的數據為 (1�����,4,7�����,10�����,13�����,16,19)�����,B為(2�����,5,8�����,11�����,14�����,17,20) C(3,6,9�,12,15����,18) 現在增加一臺主機D�,重新分布后的結果是A(1,5,9,13����,17) B(2���,6�����,10�����,14���,18) C(3�,7,11,15,19) D(4,8����,12����,15�,20) 。
可以看到,有大量的數據需要從一臺主機遷移到另外一臺主機�����。這個遷移過程是很消耗性能的��。需要找到一種方式來盡可能減少對現存數據的影響(沒有影響當然也不可能�,那說明新添加的主機沒有數據)���。
Dynamo 采用的是 consistent hashing 來解決這個問題的�。 那么我們先來了解一下什么是consistent hashing。先想象一個圓����,或者你自己的手表表面��,把它看成是一個首尾相接的數軸,現在我們的數據,自然數����,已經分布到這個圓上了,我們可以把我們的資源采用某種方式�����,隨機的分布到這個圓上(圖1-1)�。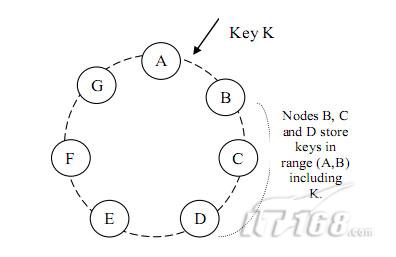 【虎.無名:和使用memcached技術類似,在節點變更時提高命中率 ���。】
【虎.無名:和使用memcached技術類似,在節點變更時提高命中率 ���。】
現在我們讓每一個資源負責它和上一個資源之間的數據��,就是說A來負責區間(C�����,A]��,B來負責區間(A,B]�,C負責區間(B�,C]�。采用這種策略,當我 們增加一個資源主機的時候�����,比如D����,那么我們只需要影響新節點相鄰的節點A所負責的范圍(只需要將A中(C,D]這個區間的數據遷移到D上)就可以了��。
因為資源節點是隨機分布到數據圓上的��,所以當資源節點的數量足夠多的時候�����,可以認為每個節點的負載基本是均衡的����。這是原始的consistent hashing 。
Dynamo并沒有采用這個模型����。這個理想的理論模型跟現實之間有一個問題�����,在這個理論模型上,每個資源節點的能力是一樣的。 我的意思是,他們有相同的cpu,內存,硬盤等�����,也就是有相同的處理能力?���?涩F實世界�����,我們使用的資源卻各有不同,新買的n核機器和老的奔騰主機一起為了節約成本而合作���。如果只是這么簡單的把機器直接分布上去,性能高的機器得不到充分利用����,性能低的機器處理不過來��。
這個問題怎么解決呢?Dynamo 使用的方法是虛節點 。把上面的A B C等都想象成一個邏輯上的節點�����。一臺真實的物理節點可能會包含幾個虛節點(邏輯節點)��,也可能只包含一個,看機器的性能而定 。
等等�,好像我們的網站還沒發展成 google 呢����,我們能使用的硬件資源還不多��,比如就4臺主機���。這個時候采用上面的方式�,把資源隨機分布上去��,幾乎一定會不均衡��。這要怎么辦呢?我們可以把那個數據圓分成Q等份(每一個等份就是一個虛節點),這個Q要遠大于我們的資源數 ����。
現在假設我們有S個資源�����,那么每個資源就承擔Q/S個等份。 當一個資源節點離開系統的時候����,它所負責的等份要重新均分到其他資源節點上���,一個新節點加入的時候�,要從其他的節點”偷”到一定數額的等份���。
這個策略下��,當一個節點離開系統的時候,雖然需要影響到很多節點�,但是注意�����,遷移的數據總量只是離開那個節點的數據量。 同樣�����,一個新節點的加入��,遷移的數據總量也只是一個新節點的數據量��。 之所以有這個效果是因為Q的存在,使得增加和減少機器的時候不需要對已有的數據做重新哈希 。這個策略的要求是Q>>S (其實還有存儲備份的問題��,現在還沒介紹到�����,假設每個數據存儲N個備份 則要滿足Q>>S*N )����。如果業務快速發展,使得不斷的增加主機,從而導致Q不再滿足Q>>S��,那么這個策略將不斷的退化�����。
http://hi.baidu.com/beibeiboo/blog/item/c04eed0ad4aac41594ca6b0e.html Dynamo的三點備份模型
第二個問題是數據可靠性��,因為我們使用的是廉價的pc機,硬盤損毀或者是其他原因導致的主機不可用是很經常的事情。
做這樣一個估算,假設一臺pc機平均三年就會有一次失效,不可用���。那么當一個一千臺機器的集群�����,基本上每天都有機器壞掉�����,所以某主機不可用是常態,系統必須可以在這樣的情況下繼續提供服務 (哦 雖然你的網站現在剛剛只需要4臺主機����,可是別忘了�,它要成長成為google的)���。
當然�����,廉價pc的好處就是便宜��。所以我們可以增加系統中數據的備份來使得系統在某臺機器掛掉的時候仍舊可用。大家最先想到的方案可能就是對每個節點�����,建立一個備份節點��,如果主節點壞掉了�����,備份節點可以立刻頂上去(雙機熱備)�。
但是仔細想一下,這個方案是讓人不放心的。因為當一主一備中的某一臺機器壞掉�����,另外一臺就成了一個單點運行的節點����。這個時候另外一個節點一旦發生錯誤,服務就變得不可用����,數據也有可能丟失��。在一個要求高可靠性的系統上,這是不可忍受的���。
我們剛剛估算了一個大的集群每天都有機器掛掉。而這種錯誤���,一定要人工介入才能解決。想想系統管理員每天在機房里更換主機的情景以及其他不可預料情況(系統管理員休假或者新買的主機沒按時到貨等)�����,再想想系統每天都有節點在單點運行�,真的是很可怕的事情。
事實上,一般工業界認為比較安全的備份數應該是3份����。 好��,那么我們看看做這個備份的時候需要注意的問題�����。首先,如何選擇備份節點��。我們可以簡單的選擇順序上的后兩個節點為備份節點��,比如存在節點A的數據,備份到節點B和C。但是當我們前面引入了虛節點的概念的時候就要注意了,有可能C節點和A節點在同一臺物理機器上,這個時候就不能選擇C做為A的備份了 �。
下一個問題���,當一個節點離開系統的時候��,比如宕機,這個節點上存儲的信息需要繼續備份到其它節點上�����。雖然節點離開了系統�,但是因為備份的存在,我們通過其他節點可以恢復出本節點的所有信息�,因為該節點的離開�,這部分信息的備份數會比要求的備份數少一�����,所以需要把這部分數據做再備份 ����。同樣����,當一個節點加入系統,從其他節點偷了數據后,其他節點也需要相應減少備份數。而一個節點如果只是暫時性的不可達���,也就是失效一個很短的時間(這種情況是最常發生的),那么需要其他節點暫時接管這個節點的工作,在其可用的時候����,把數據增量傳送回該節點 ��。
http://hi.baidu.com/beibeiboo/blog/item/c3dda333d0713049ac4b5f0d.html 2009-12-02 22:38 NWR模型與同步和異步備份
在設計上述需求的解決方案的時候�����,還要考慮一個問題��,各個節點間數據備份是同步還是異步。 假設我們要求寫請求總是盡可能的成功����,那么我們的策略是寫任何一個節點成功就認為成功�����。節點之間的數據通過異步形式達成一致,這個時候讀請求可能讀不到最新寫進去的信息��。
比如我們一個數據在A B C 三個節點各存一份(系統中有三個備份的時候����,下面的討論都是基于這個假設的),那么當寫A成功后�����,另外一個進程從節點C讀數據�����,這個時候C還沒收到最新的數據�����,只能給讀請求一個較老的版本�。這個可能會帶來大問題;同樣����,如果我們希望讀請求總能讀到正確的數據���,那我們的策略是寫的時候要等A B C三個節點都寫成功了才認為寫成功 �。這個時候寫請求可能要耗較多的時間,甚至根本不能完成(如果有節點不可達)也就是說���,系統的一致性,可靠性�����,原子性�,隔離性的問題(ACID)是無法同時達到的。只能在其中做出取舍 ���。
Dynamo 的處理方式是把這個選擇權交給用戶,這就是它的N W R模型�����。N代表N個備份����,W代表要寫入至少W份才認為成功,R表示至少讀取R個備份�����。配置的時候要求W+R > N���。 因為W+R > N�, 所以 R > N-W 這個是什么意思呢?就是讀取的份數一定要比總備份數減去確保寫成功的倍數的差值要大 。也就是說�����,每次讀取����,都至少讀取到一個最新的版本�。從而不會讀到一份舊數據。 當我們需要高可寫的環境的時候(例如����,amazon的購物車的添加請求應該是永遠不被拒絕的)我們可以配置W = 1 如果N=3 那么R = 3�����。 這個時候只要寫任何節點成功就認為成功,但是讀的時候必須從所有的節點都讀出數據。 如果我們要求讀的高效率,我們可以配置 W=N R=1。這個時候任何一個節點讀成功就認為成功���,但是寫的時候必須寫所有三個節點成功才認為成功 。
大家注意,一個操作的耗時是幾個并行操作中最慢一個的耗時�。比如R=3的時候���,實際上是向三個節點同時發了讀請求���,要三個節點都返回結果才能認為成功��。 假設某個節點的響應很慢,它就會嚴重拖累一個讀操作的響應速度�。
http://hi.baidu.com/beibeiboo/blog/item/94b44cd35dd8570a3bf3cf03.html 2009-12-02 22:33 vector clock算法保證版本信息
解決數據版本問題
這里我們需要討論一下數據版本問題�,這個問題不僅僅存在于分布式系統�,只是分布式系統的一些要求使得這個問題更復雜。 先 看個簡單的例子��,用戶x對key1做了一次寫入操作���,我們設值是數字3����。然后用戶y讀取了key1����,這個時候用戶y知道的值是3�����。然后用戶x對值做了一 個+1操作,將新值寫入,現在key1的值是4了�����。而用戶y也做了一次+1操作��,然后寫入�����,因為用戶y讀到的值是3,y不知道這個值現在已經變化了,結果 按照語義本應該是5的值,現在還是4。
解決這個問題常用的方法是設置一個版本值��。用戶x第一次寫入key1 值3的時候���,產生一個版本設為v1��。用戶y讀取的信息中包括版本編號v1����。當x做了加1把值4寫入的時候����,告訴server自己拿到的是版本v1,要在 v1的基礎上把值改成4。server發現自己保存的版本的確是v1所以就同意這個寫入����,并且把版本改成v2。 這個時候y也要寫入4�����,并且宣稱自己是在版本v1上做的修改���。
但是因為server發現自己手里已經是版本v2了���,所以server就拒絕y的寫入請求��,告訴y�����,版本錯誤。 這個算法在版本沖突的時候經常被使用����。但是剛才我們描述的分布式系統不能簡單采用這個方式來實現�����。
假設我們設置了N=3 W=1。現在x寫入key1 值3����,這個請求被節點A處理����,生成了v1版本的數據��。然后x用戶又在版本v1上進行了一次key1值4的寫操作,這個請求這次是節點C處理的�����。但是節點C 還沒有收到上一個A接收的版本(數據備份是異步進行的)如果按照上面的算法���,他應該拒絕這個請求�����,因為他不了解版本v1的信息�。但是實際上是不可以拒絕的,因為如果C拒絕了寫請求����,實際上W=1這個配置�����,這個服務器向客戶做出的承諾將被打破,從而使得系統的行為退化成W=N的形式��。 那么C接收了這個請求�����,就可能產生前面提到的不一致性�����。如何解決這個問題呢?
Dynamo 的方法是保留所有這些版本,用vector clock記錄版本信息�����。當讀取操作發生的時候返回多個版本����,由客戶端的業務層來解決這個沖突合并各個版本�����。當然客戶端也可以選擇最簡單的策略�����,就是最近一次的寫覆蓋以前的寫。
vector clock算法保證版本信息
這里又引入了一個vector clock算法���,這里簡單介紹一下?����?梢园堰@個vector clock想象成每個節點都記錄自己的版本信息���,而一個數據���,包含所有這些版本信息����。來看一個例子:假設一個寫請求,第一次被節點A處理了。節點A會增加 一個版本信息(A,1)���。我們把這個時候的數據記做D1(A,1)。 然后另外一個對同樣key(這一段討論都是針對同樣的key的)的請求還是被A處理了于是有D2(A�����,2)����。
這個時候�����,D2是可以覆蓋D1的�,不會有沖突產生?���,F在我們假設D2傳播到了所有節點(B和C),B和C收到的數據不是從客戶產生的,而是別人復制給他們 的��,所以他們不產生新的版本信息���,所以現在B和C都持有數據D2(A,2)。好,繼續���,又一個請求,被B處理了,生成數據D3(A��,2;B����,1),因為這 是一個新版本的數據,被B處理�����,所以要增加B的版本信息����。
假設D3沒有傳播到C的時候又一個請求被C處理記做D4(A���,2;C���,1)�����。假設在這些版本沒有傳播開來以前��,有一個讀取操作,我們要記得�,我們的W=1 那么R=N=3����,所以R會從所有三個節點上讀�����,在這個例子中將讀到三個版本��。A上的D2(A,2);B上的D3(A��,2;B��,1);C上的D4(A����,2; C�����,1)這個時候可以判斷出�����,D2已經是舊版本��,可以舍棄��,但是D3和D4都是新版本,需要應用自己去合并�。
如果需要高可寫性�����,就要處理這種合并問題。好假設應用完成了沖入解決����,這里就是合并D3和D4版本����,然后重新做了寫入����,假設是B處理這個請求,于是有 D5(A,2;B,2;C,1);這個版本將可以覆蓋掉D1-D4那四個版本。這個例子只舉了一個客戶的請求在被不同節點處理時候的情況����, 而且每次寫更新都是可接受的���,大家可以自己更深入的演算一下幾個并發客戶的情況��,以及用一個舊版本做更新的情況�����。
上面問題看似好像可以通過在三個節點里選擇一個主節點來解決��,所有的讀取和寫入都從主節點來進行����。但是這樣就違背了W=1這個約定�,實際上還是退化到W=N的情況了。所以如果系統不需要很大的彈性����,W=N為所有應用都接受�,那么系統的設計上可以得到很大的簡化����。 Dynamo為了給出充分的彈性而被設計成完全的對等集群(peer to peer),網絡中的任何一個節點都不是特殊的 。
解決單點故障問題
最后還有一個單點故障的問題��,這個問題的解決要求系統構建的時候是完全分布式�����,不存在一個核心的 ���。 例如傳統的存儲系統里面往往存在一個中心節點�,這個單點的存在使得系統在這一點上變得很脆弱���。解決方法就是讓系統的每個節點都可以承擔起所有需要的功能�。 這個問題的解決涉及到事情比較多,以亞馬遜平臺的Dynamo分布式存儲引擎來說,有Seed節點的概念�����,不過本文我們暫時不做過多剖析��。
http://storage.it168.com/a2009/1013/757/000000757579_3.shtml 詳細解析Dynamo存儲引擎
NWR模型與同步和異步備份
在設計上述需求的解決方案的時候��,還要考慮一個問題���,各個節點間數據備份是同步還是異步��。假設我們要求寫請求總是盡可能的成功����,那么我們的策略是寫任何一個節點成功就認為成功����。節點之間的數據通過異步形式達成一致,這個時候讀請求可能讀不到最新寫進去的信息����。
比如我們一個數據在A B C 三個節點各存一份(系統中有三個備份的時候����,下面的討論都是基于這個假設的)����,那么當寫A成功后,另外一個進程從節點C讀數據�,這個時候C還沒收到最新的 數據��,只能給讀請求一個較老的版本。這個可能會帶來大問題;同樣�����,如果我們希望讀請求總能讀到正確的數據,那我們的策略是寫的時候要等A B C三個節點都寫成功了才認為寫成功。這個時候寫請求可能要耗較多的時間�����,甚至根本不能完成(如果有節點不可達)也就是說����,系統的一致性����,可靠性,原子性�,隔離性的問題(ACID)是無法同時達到的�����。只能在其中做出取舍 。
Dynamo 的處理方式是把這個選擇權交給用戶����,這就是它的N W R模型����。N代表N個備份�����,W代表要寫入至少W份才認為成功�����,R表示至少讀取R個備份。配置的時候要求W+R > N �����。 因為W+R > N��, 所以 R > N-W 這個是什么意思呢?就是讀取的份數一定要比總備份數減去確保寫成功的倍數的差值要大。
也就是說�����,每次讀取���,都至少讀取到一個最新的版本�。從而不會讀到一份舊數據。當我們需要高可寫的環境的時候(例如,amazon的購物車的添加請求應該是 永遠不被拒絕的)我們可以配置W = 1 如果N=3 那么R = 3�����。 這個時候只要寫任何節點成功就認為成功����,但是讀的時候必須從所有的節點都讀出數據。如果我們要求讀的高效率,我們可以配置 W=N R=1。這個時候任何一個節點讀成功就認為成功,但是寫的時候必須寫所有三個節點成功才認為成功��。
大家注意����,一個操作的耗時是幾個并行操作中最慢一個的耗時。比如R=3的時候,實際上是向三個節點同時發了讀請求,要三個節點都返回結果才能認為成功����。假設某個節點的響應很慢����,它就會嚴重拖累一個讀操作的響應速度���。
http://www.dbanotes.net/techmemo/amazon_dynamo.html Amazon 的 Dynamo 架構
作者: Fenng | 可以轉載, 但必須以超鏈接形式標明文章原始出處和作者信息及版權聲明.
http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html Amazon Dynamo 這個高可用����、可擴展存儲體系 支撐了Amazon 不少核心服務.
先看一個示意圖:
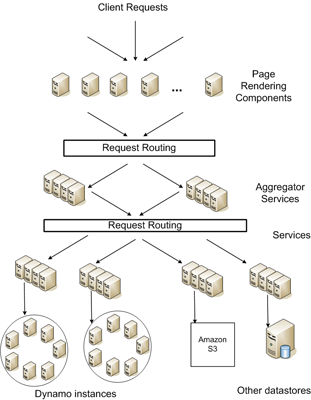
從上圖可以看出,Amazon 的架構是完全的分布式,去中心化����。存儲層也做到了分布式 �����。
Dynamo 概述
Dynamo 的可擴展性和可用性采用的都比較成熟的技術,數據分區 并用改進的一致性哈希(consistent hashing)方式進行復制,利用數據對象的版本化實現一致性����。復制時因為更新產生的一致性問題的維護采取類似 quorum 的機制以及去中心化的復制同步協議�。 Dynamo 是完全去中心化的系統�����,人工管理工作很小���。
強調一下 Dynamo 的”額外”特點:
1) 總是可寫
2) 可以根據應用類型優化
關鍵詞
Key : Key 唯一代表一個數據對象�����,對該數據對象的讀寫操通過 Key 來完成.
節點(node) :通常是一臺自帶硬盤的主機。每個節點有三個 Java 寫的組件:請求協調器(request coordination)、成員與失敗檢測����、本地持久引擎(local persistence engine)
實例(instance) �;每個實例由一組節點組成�����,從應用的角度看�,實例提供 IO 能力�����。一個實例上的節點可能位于不同的數據中心內, 這樣一個數據中心出問題也不會導致數據丟失。
上面提到的本地持久引擎支持不同的存儲引擎 ���。Dynamo 上最主要的引擎是 Berkeley Database Transactional Data Store(存儲處理數百K的對象更為適合),其他還有 BDB Java Edition�、MySQL 以及 一致性內存 Cache 等等��。
三個關鍵參數 (N,R,W)
第一個關鍵參數是 N,這個 N 指的是數據對象將被復制到 N 臺主機上����,N 在 Dynamo 實例級別配置��,協調器將負責把數據復制到 N-1 個節點上。N 的典型值設置為 3.
復制中的一致性���,采用類似于 Quorum 系統的一致性協議實現。這個協議有兩個關鍵值:R 與 W�。R 代表一次成功的讀取操作中最小參與節點數量��,W 代表一次成功的寫操作中最小參與節點數量。R + W>N ����,則會產生類似 quorum 的效果�����。該模型中的讀(寫)延遲由最慢的 R(W)復制決定,為得到比較小的延遲���,R 和 W 有的時候的和又設置比 N 小。
(N,R,W) 的值典型設置為 (3, 2 ,2),兼顧性能與可用性��。R 和 W 直接影響性能����、擴展性�、一致性,如果 W 設置 為 1��,則一個實例中只要有一個節點可用���,也不會影響寫操作���,如果 R 設置為 1 ,只要有一個節點可用�����,也不會影響讀請求�,R 和 W 值過小則影響一致性,過大也不好����,這兩個值要平衡�����。對于這套系統的典型的 SLA 要求 99.9% 的讀寫操作在 300ms 內完成。
–待續– 更多閱讀:Dynamo學習 — http://donghao.org/2008/10/dynamoni.html
http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html 論文:網頁版
4.System Architecture
The architecture of a storage system that needs to operate in a production setting is complex. In addition to the actual data persistence component, the system needs to have scalable and robust solutions for load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management. Describing the details of each of the solutions is not possible, so this paper focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling. Table 1 presents a summary of the list of techniques Dynamo uses and their respective advantages.
Table 1: Summary of techniques used in Dynamo and their advantages.
| Problem |
Technique |
Advantage |
| Partitioning |
Consistent Hashing |
Incremental Scalability |
| High Availability for writes |
Vector clocks with reconciliation during reads |
Version size is decoupled from update rates. |
| Handling temporary failures |
Sloppy Quorum and hinted handoff |
Provides high availability and durability guarantee when some of the replicas are not available. |
| Recovering from permanent failures |
Anti-entropy using Merkle trees |
Synchronizes divergent replicas in the background. |
| Membership and failure detection |
Gossip-based membership protocol and failure detection. |
Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information. |