轉載自:http://blog.csdn.net/ahyswang/article/details/7691541
1.1混響的作用與基本原理
混響器即是人為地給聲音加上混響的效果。這樣通過改變場景的混響時間,可以對比較“干”的信號進行再加工,增加空間感,提高聲音的豐滿度,同時可以制造一些特殊的聲音效果,如回聲等,通過改變混響聲和直達聲的比例,還可以體現聲音的遠近感和空間感。
下圖一直觀的解釋了混響的簡單原理。為了研究的方便,聲學上把混響分為幾個部份,規定了一些習慣用語。混響的第一個聲音也就是直達聲(Direct sound),也就是源聲音,在效果器里叫做 dry out (干聲輸出),隨后的幾個明顯的相隔比較開的聲音叫做“早反射聲”(Early reflectedsounds),它們都是只經過幾次反射就到達了的聲音,聲音比較大,比較明顯,它們特別能夠反映空間中的源聲音、耳朵及墻壁之間的距離關系。后面的一堆連綿不絕的聲音叫做 reverberation。圖五中,老師在講臺上講課,學生在座位上聽到的聲音除了直接到達的聲音(DIRETO)外,還有R1.R2.R3.R4等等這些反射聲。可以看見不同的反射聲達到人耳的時間有著不同的延遲。所有這些聲音的疊加才是人耳聽到的最終聲音。然而實際上,這些反射聲是無窮盡的,這樣我們似乎就沒辦法得到混響聲了。
然而如果我們假定源聲音是一個脈沖,得到結果如圖二。


圖一

圖二
得到的是一串簡單的脈沖序列。這個混響特征是用脈沖得到的,聲學上我們叫做Impulse Response脈沖反應,簡稱IR。經過混響的聲音即可看作源聲音與IR的卷積得到的結果。
依據IR的來源不同,混響效果器,象合成器一樣分為三種類型:采樣混響、“算法”混響、模擬合成混響。
1.2 混響分類
(一)采樣 IR 混響
Sony ,Yamaha 都出過采樣混響,價格不菲。軟件的采樣混響效果器有著名的 SonicFoundry 的 Acoustic Mirror ,還有Samplitude 的 Room Simulator 。 采樣混響的 IR ,全部是真實采樣得來的 wave 文件。可以存放于任何存儲器,例如硬盤、光盤、軟盤等等。Sony ,Yamaha 的硬件采樣混響器,里面也帶有容量較大的存儲器。 采樣混響的 IR 都是錄音采樣得來的,最簡單的獲取 IR 的方式是:在圖一教師的位置放置一個音箱,學生的位置放置一個話筒。音箱播放一個脈沖,話筒進行錄音。錄到的聲音就是 IR ,也就是這個房間的從講臺到學生座位的混響特征曲線。目前 Sony 、Samplitude 等所采用的具體方式是: 在想要獲得混響特征的地方,例如音樂廳,舞臺上安置音箱(當然會是極好的音箱),座位席中安置立體聲話筒(極好的話筒)。然后播放一系列測試信號,這些信號以脈沖為主,各種速度的全頻段正弦波連續掃描為輔,錄得聲音,然后經過一些計算得到 IR 。用這種采樣方法得到的 IR ,極為真實。 采樣混響的 IR ,不但廠家可以預置給你,你自己也可以根據廠家提供的工具進行制作。因此從數量上來說是無限的。下圖三就是一個真實的采樣混響IR。
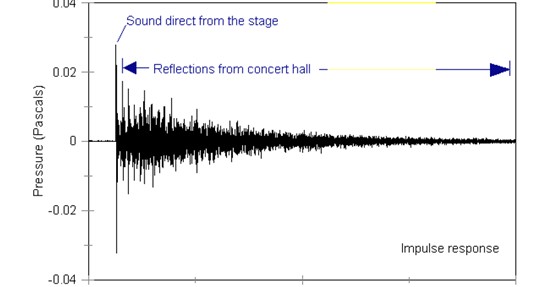
圖三
(二)“算法”混響
這是最常見的混響效果器。目前大多數的數字混響效果器以及軟件混響都是此類。這類效果器的本質是跟采樣混響一樣的,只是采樣混響的 IR 可以自由更換,而“算法”混響其實也帶有 IR ,但這些個 IR是廠家固定好的,是一組組簡易的脈沖序列,通過對這些脈沖序列進行調制和編輯控制,從而得到最終的混響效果。例如Waves 的 Renaissance Reberberator 帶有幾十個簡易的脈沖序列 ,這些脈沖序列都產品自帶的,不能更改。很多廠家把這些的脈沖序列稱之為“算法”,它們其實可以算作一種簡化過后的IR 。 許多硬件混響器也是如此,例如 Lexicon 和TC 的,原理都一樣。而采樣混響內帶有可擦寫存儲器,可以自由更換 IR 。 這類混響器雖然不帶有真實 IR ,但是卻提供了很多方法可以讓你對它自帶的原始的脈沖序列進行修改,例如可以讓你拉長或者縮短這組脈沖序列(也就是拉大或者縮短脈沖之間的距離),這樣可以模擬墻壁漫反射的效果,還提供了濾波器和 EQ ,前反射時間,等等,很多控制。這些實際上都是對原始 IR 進行修改,以達到控制混響效果的目的。因此雖然它不帶有真實 IR ,但通過對 IR 進行編輯,可以獲得無數種混響效果。 為了容量上的考慮,“算法”混響所帶有的原始脈沖序列都作了很大的簡化,不會象采樣混響的 IR 里那樣無數個脈沖有如滔滔江水連綿不絕。下圖四是“算法”混響經過調節后最終得到的 IR 。將之與上面采樣 IR 對比一下就可以知道區別了。
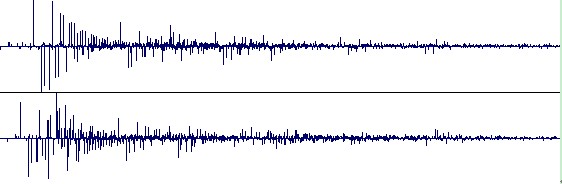
圖四
(三)模擬合成 IR 混響
這類混響效果器并不帶有IR 曲線,而是用模擬合成方法“臨時”生成 IR 。 幾乎所有的非數字混響器都是這一類(包括所有的傳統電子管混響效果器、調音臺上的非數字混響等),還有少數軟件混響效果器也是,例如 Spin Audio 的 RoomVerb M2 ,Samplitude 的 Track Reverb 等等。 它會根據你提出的要求,比如空間大小,墻壁的吸音程度,等等,用它自己的計算方法(例如 Spin Audio 的“虛擬房間聲學建模技術”),生成一個 IR ,并且有許多方法對IR 進行編輯控制,例如濾波,EQ 等。因此雖然 SpinAudio 的 RoomVerb M2 不帶有任何 IR ,卻也能模擬出無數種混響效果。
1.3混響的特征參數
下面以Waves的“文藝復興混響器”來說明混響器的特征參數,如圖五所示:
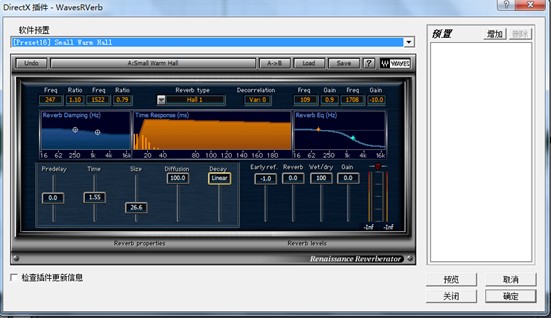
圖五
大多數的混響效果器會有一些參數選項給你調節,現在就來講講這些參數具體是什么意思。
(1)衰減時間(Decay time)
也就是整個混響的總長度。不同的環境會有不同的長度,有以下幾個特點:空間越大,decay 越長;反之越短。空間越空曠,decay 越長;反之越短。空間中家具或別的物體(比如柱子之類)越少,decay 越長;反之越短。空間表面越光滑平整,decay 越長,反之越短。因此,大廳的混響比辦公室的混響長;無家具的房間的混響比有家具的房間長;荒山山谷的混響比森林山谷的混響長;水泥墻壁的空間的混響比布制墻壁的空間的混響長 …… 一般很多人喜歡把混響時間設得很長。其實真正的一些劇院、音樂廳的混響時間并沒有我們想象得那么長。例如波士頓音樂廳的混響時間是 1.8 秒,紐約卡內基音樂廳是 1.7 秒,維也納音樂廳是 2.05 秒。
(2)前反射的延遲時間(Predelay)
就是直達聲與前反射聲的時間距離。有以下幾個特點: 空間越大,Predelay 越長;反之越短。空間越寬廣,Predelay 越長;反之越短。因此,大廳的 Predelay 比辦公室的長;而隧道的空間雖然大,但是它很窄,所以 Predelay就很短。 想要表現很寬大空曠的空間,就把 Predelay 設大一點。
(3)wet out
也就是混響效果聲的大小。有以下幾個特點: wet out 與空間大小無關,而只與空間內雜物的多少以及墻壁及物體的材質有關。 墻壁及室內物體的表面材質越松軟,wet out 越小;反之越大 空間內物體越多,wet out 越小;反之越大墻壁越不光滑,wet out 越小,反之越大 墻壁上越多坑坑凹凹,wetout 越小,反之越大 因此,擠滿了人的車廂的混響就比空車要小得多;放滿了家具的房間的混響就比空房間要小;有地毯的房間的混響比無地毯的小;森林山谷的混響比荒山山谷的混響要小。
(4)高低頻截止(low cut / high cut)
這個參數在有些效果器里是以 EQ 的形式來表現的,例如 Waves 的 RVerb 。這項內容實際上跟現實情況沒有太直接的聯系,它只是為了我們做混響處理時聲音好聽而設計的。不過它也能表現高頻聲音在傳播中損失比較厲害的現象。一般在做處理的時候,為了混響聲的清晰和溫暖,都會把低頻和高頻去掉一部份。只有在表現一些諸如“宇宙聲”等科幻環境時,才把高低頻保留。 另外有些效果器也把這個叫做“color”(色彩)。例如 TC 的效果器就是 color 。color 也就是“冷”和“暖”的感覺,高頻就是冷,低頻就是暖。所以這些效果器用顏色來表示高低頻截止,暖色(紅)表示混響聲偏向低頻,冷色(藍)表示混響聲偏向高頻。補充:高低頻截止實際上在現實中是不存在的,現實中的普遍現象是:低頻聲音的混響無論是聲音大小還是衰減時間,都要比高頻聲音大。這是因為不同頻率的聲音由于波長不同,因此繞過障礙的能力不同,高頻聲音波長短,不容易繞過障礙,低頻聲音波長長,容易繞過障礙。加上它們在空氣中傳播時的衰弱程度不同(頻率越高越容易衰弱),被墻壁吸收的程度不同(頻率越高越容易損失),所以不同頻率的聲音的混響時間和大小是不相同的。在真實世界中,在大多數中小空間里,越低的聲音具有越長的混響時間,越高的聲音具有越短的混響時間,而不可能做到反過來。如何做到降低低頻混響是任何一個錄音棚頭疼的難題。唯獨有一種情況,是低頻混響小于高頻混響的,那就是很大的空間,并且里面布滿了由硬質材料制成的障礙和表面,比如采用硬塑料凳子和水泥墻壁地板的室內體育館。
(5)衰減形狀(Decay Shape)
有的混響器里提供了這個參數,用來控制混響的衰減形狀。如下圖六所示是幾種常見衰減形狀:
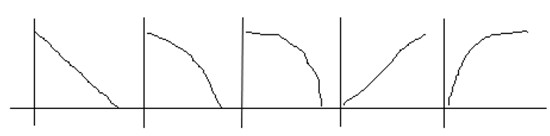
圖六
上圖中第一個是我們最常用的線性衰減,第二個和第三個是EXP型衰減,其中第三個可以成為門式混響(Gate Reverb),第四和第五個是Reverse型衰減,通常用來制造一些特殊聲音效果。
(6)散射度(Diffusion)
一般也稱作Early Reflections Diffusion(早反射的散射度)。這些早反射是比較明顯的反射聲,它們之間的相互接近程度就是散射度。一般來說,墻壁越不光滑,反射聲越多,相互之間越接近,散射度越大,混響聲連成一片;墻壁越不光滑,反射聲越小,相互之間分得越開,散射度越小,混響聲聽起來比較接近回聲,比較清晰。
然而對于用戶來講,這些參數既繁多又難以確定,調節得不好反而不如不加混響。這時最好的選擇是套用軟件中得預置參數,比如“Large Hall”就可以實現大廳的混響效果。對于UItrafunkfxReverbR3效果器,可以給出下面一組參數:Input 0.0 Low cut 145 Highcut 4.5 Predelay 160 Room size 100 Diffusiin 100 Bass Multiplier 2.6 Crossover116 Decay Time 1.8 High Damping 2.2 Dry 1.0 E.R. -3.5 Reverb -7
這里筆者認為在音效處理要求不高的時候Gold Wave軟件以其小巧玲瓏和調節簡便的特點,有著很大的借鑒意義。其做出的混響效果基本令人滿意,最重要的是它只有三個最重要的參數需要調節。然而其不足之處在于添加的可選場景混響效果較少。
1.4 混響算法
混響的算法實現通常通過聽覺逼近方式實現,這種方式產生與人耳聽覺無差異的混響效果,著重重建混響的重點部分。最著名的混響算法是由貝爾實驗室的Schroeder提出的,他提出的混響算法包含兩個IIR濾波器:梳狀濾波器和全通濾波器。其中梳狀濾波器是一個帶后向反饋的延時電路,而全通濾波器則是一個帶前向反饋支路的梳狀濾波器。原理圖如下:
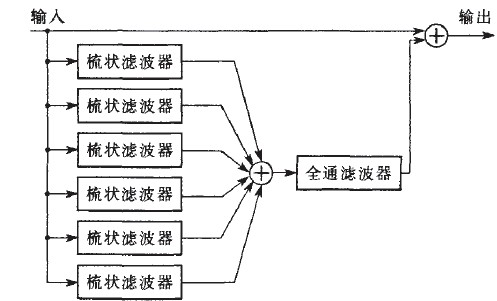
圖七
通過并聯的梳狀濾波器模擬延時較大的回聲,串聯的全通濾波器模擬延時較小的回聲。然而這種方法的缺點則是它模擬的混響中回聲密度不夠,對此可以通過增加濾波器個數等方法進行改進。
1.5混響的實現代碼
參考
- #define dsound_allpass_process(_allpass, _input) \
- { \
- dsound_real_t output; \
- dsound_real_t bufout; \
- bufout = _allpass.buffer[_allpass.bufidx]; \
- output = bufout-_input; \
- _allpass.buffer[_allpass.bufidx] = _input + (bufout * _allpass.feedback); \
- if (++_allpass.bufidx >= _allpass.bufsize) { \
- _allpass.bufidx = 0; \
- } \
- _input = output; \
- }
- #define dsound_comb_process(_comb, _input, _output) \
- { \
- dsound_real_t _tmp = _comb.buffer[_comb.bufidx]; \
- _comb.filterstore = (_tmp * _comb.damp2) + (_comb.filterstore * _comb.damp1); \
- _comb.buffer[_comb.bufidx] = _input + (_comb.filterstore * _comb.feedback); \
- if (++_comb.bufidx >= _comb.bufsize) { \
- _comb.bufidx = 0; \
- } \
- _output += _tmp; \
- }
- void dsound_revmodel_processreplace(dsound_revmodel_t * rev, dsound_real_t * in, dsound_real_t * left_out, dsound_real_t * right_out)
- {
- int i, k = 0;
- dsound_real_t outL, outR, input;
-
- for (k = 0; k < FLUID_BUFSIZE; ++k){
-
- outL = outR = 0;
-
-
-
-
-
- input = (2.0f * in[k] + DC_OFFSET) * rev->gain;
-
-
- for (i = 0; i < numcombs; i++) {
- dsound_comb_process(rev->combL[i], input, outL);
- dsound_comb_process(rev->combR[i], input, outR);
- }
-
- for (i = 0; i < numallpasses; i++) {
- dsound_allpass_process(rev->allpassL[i], outL);
- dsound_allpass_process(rev->allpassR[i], outR);
- }
-
-
- outL -= DC_OFFSET;
- outR -= DC_OFFSET;
-
-
- left_out[k] = outL * rev->wet1 + outR * rev->wet2;
- right_out[k] = outR * rev->wet1 + outL * rev->wet2;
- }
-
- }