在看下面這篇文章之前,先介紹幾個理論知識,有助于理解A*算法。
啟發式搜索:啟發式搜索就是在狀態空間中的搜索對每一個搜索的位置進行評估,得到最好的位置,再從這個位置進行搜索直到目標。這樣可以省略大量無畏的搜索路徑,提到了效率。在啟發式搜索中,對位置的估價是十分重要的。采用了不同的估價可以有不同的效果。
估價函數:從當前節點移動到目標節點的預估費用;這個估計就是啟發式的。在尋路問題和迷宮問題中,我們通常用曼哈頓(manhattan)估價函數(下文有介紹)預估費用。
A*算法與BFS:可以這樣說,BFS是A*算法的一個特例。對于一個BFS算法,從當前節點擴展出來的每一個節點(如果沒有被訪問過的話)都要放進隊列進行進一步擴展。也就是說BFS的估計函數h永遠等于0,沒有一點啟發式的信息,可以認為BFS是“最爛的”A*算法。
選取最小估價:如果學過數據結構的話,應該可以知道,對于每次都要選取最小估價的節點,應該用到最小優先級隊列(也叫最小二叉堆)。在C++的STL里有現成的數據結構priority_queue,可以直接使用。當然不要忘了重載自定義節點的比較操作符。
A*算法的特點:A*算法在理論上是時間最優的,但是也有缺點:它的空間增長是指數級別的。
IDA*算法:這種算法被稱為迭代加深A*算法,可以有效的解決A*空間增長帶來的問題,甚至可以不用到優先級隊列。如果要知道詳細:google一下。
A*尋路初探(轉載)
作者:Patrick Lester
譯者:Panic2005年
譯者序:很久以前就知道了A*算法,但是從未認真讀過相關的文章,也沒有看過代碼,只是腦子里有個模糊的概念。這次決定從頭開始,研究一下這個被人推崇備至的簡單方法,作為學習人工智能的開始。
這篇文章非常知名,國內應該有不少人翻譯過它,我沒有查找,覺得翻譯本身也是對自身英文水平的鍛煉。經過努力,終于完成了文檔,也明白的A*算法的原理。毫無疑問,作者用形象的描述,簡潔詼諧的語言由淺入深的講述了這一神奇的算法,相信每個讀過的人都會對此有所認識(如果沒有,那就是偶的翻譯太差了--b)。
現在是年月日的版本,應原作者要求,對文中的某些算法細節做了修改。
原文鏈接:http://www.gamedev.net/reference/articles/article2003.asp
原作者文章鏈接:http://www.policyalmanac.org/games/aStarTutorial.htm
以下是翻譯的正文
會者不難,A*(念作A星)算法對初學者來說的確有些難度。這篇文章并不試圖對這個話題作權威的陳述。取而代之的是,它只是描述算法的原理,使你可以在進一步的閱讀中理解其他相關的資料。最后,這篇文章沒有程序細節。你盡可以用任意的計算機程序語言實現它。如你所愿,我在文章的末尾包含了一個指向例子程序的鏈接。壓縮包包括C++和Blitz Basic兩個語言的版本,如果你只是想看看它的運行效果,里面還包含了可執行文件。我們正在提高自己。讓我們從頭開始。。。
序:搜索區域
假設有人想從A點移動到一墻之隔的B點,如下圖,綠色的是起點A,紅色是終點B,藍色方塊是中間的墻。

[圖-1]
你首先注意到,搜索區域被我們劃分成了方形網格。像這樣,簡化搜索區域,是尋路的第一步。這一方法把搜索區域簡化成了一個二維數組。數組的每一個元素是網格的一個方塊,方塊被標記為可通過的和不可通過的。路徑被描述為從A到B我們經過的方塊的集合。一旦路徑被找到,我們的人就從一個方格的中心走向另一個,直到到達目的地。
這些中點被稱為“節點”。當你閱讀其他的尋路資料時,你將經常會看到人們討論節點。為什么不把他們描述為方格呢?因為有可能你的路徑被分割成其他不是方格的結構。他們完全可以是矩形,六角形,或者其他任意形狀。節點能夠被放置在形狀的任意位置-可以在中心,或者沿著邊界,或其他什么地方。我們使用這種系統,無論如何,因為它是最簡單的。
開始搜索
正如我們處理上圖網格的方法,一旦搜索區域被轉化為容易處理的節點,下一步就是去引導一次找到最短路徑的搜索。在A*尋路算法中,我們通過從點A開始,檢查相鄰方格的方式,向外擴展直到找到目標。
我們做如下操作開始搜索:
1,從點A開始,并且把它作為待處理點存入一個“開啟列表”。開啟列表就像一張購物清單。盡管現在列表里只有一個元素,但以后就會多起來。你的路徑可能會通過它包含的方格,也可能不會。基本上,這是一個待檢查方格的列表。
2,尋找起點周圍所有可到達或者可通過的方格,跳過有墻,水,或其他無法通過地形的方格。也把他們加入開啟列表。為所有這些方格保存點A作為“父方格”。當我們想描述路徑的時候,父方格的資料是十分重要的。后面會解釋它的具體用途。
3,從開啟列表中刪除點A,把它加入到一個“關閉列表”,列表中保存所有不需要再次檢查的方格。在這一點,你應該形成如圖的結構。在圖中,暗綠色方格是你起始方格的中心。它被用淺藍色描邊,以表示它被加入到關閉列表中了。所有的相鄰格現在都在開啟列表中,它們被用淺綠色描邊。每個方格都有一個灰色指針反指他們的父方格,也就是開始的方格。

[圖-2]
接著,我們選擇開啟列表中的臨近方格,大致重復前面的過程,如下。但是,哪個方格是我們要選擇的呢?是那個F值最低的。
路徑評分
選擇路徑中經過哪個方格的關鍵是下面這個等式:F = G + H
這里:
* G = 從起點A,沿著產生的路徑,移動到網格上指定方格的移動耗費。
* H = 從網格上那個方格移動到終點B的預估移動耗費。這經常被稱為啟發式的,可能會讓你有點迷惑。這樣叫的原因是因為它只是個猜測。我們沒辦法事先知道路徑的長度,因為路上可能存在各種障礙(墻,水,等等)。雖然本文只提供了一種計算H的方法,但是你可以在網上找到很多其他的方法。
我們的路徑是通過反復遍歷開啟列表并且選擇具有最低F值的方格來生成的。文章將對這個過程做更詳細的描述。首先,我們更深入的看看如何計算這個方程。
正如上面所說,G表示沿路徑從起點到當前點的移動耗費。在這個例子里,我們令水平或者垂直移動的耗費為,對角線方向耗費為。我們取這些值是因為沿對角線的距離是沿水平或垂直移動耗費的的根號(別怕),或者約.414倍。為了簡化,我們用和近似。比例基本正確,同時我們避免了求根運算和小數。這不是只因為我們怕麻煩或者不喜歡數學。使用這樣的整數對計算機來說也更快捷。你不就就會發現,如果你不使用這些簡化方法,尋路會變得很慢。
既然我們在計算沿特定路徑通往某個方格的G值,求值的方法就是取它父節點的G值,然后依照它相對父節點是對角線方向或者直角方向(非對角線),分別增加和。例子中這個方法的需求會變得更多,因為我們從起點方格以外獲取了不止一個方格。
H值可以用不同的方法估算。我們這里使用的方法被稱為曼哈頓方法,它計算從當前格到目的格之間水平和垂直的方格的數量總和,忽略對角線方向,然后把結果乘以10。這被稱為曼哈頓方法是因為它看起來像計算城市中從一個地方到另外一個地方的街區數,在那里你不能沿對角線方向穿過街區。很重要的一點,我們忽略了一切障礙物。這是對剩余距離的一個估算,而非實際值,這也是這一方法被稱為啟發式的原因。想知道更多?你可以在這里找到方程和額外的注解。
F的值是G和H的和。第一步搜索的結果可以在下面的圖表中看到。F,G和H的評分被寫在每個方格里。正如在緊挨起始格右側的方格所表示的,F被打印在左上角,G在左下角,H則在右下角。
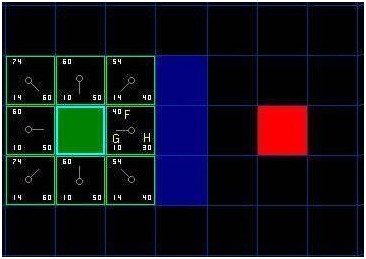
[圖-3]
現在我們來看看這些方格。寫字母的方格里,G = 10。這是因為它只在水平方向偏離起始格一個格距。緊鄰起始格的上方,下方和左邊的方格的G值都等于。對角線方向的G值是。
H值通過求解到紅色目標格的曼哈頓距離得到,其中只在水平和垂直方向移動,并且忽略中間的墻。用這種方法,起點右側緊鄰的方格離紅色方格有格距離,H值就是。這塊方格上方的方格有格距離(記住,只能在水平和垂直方向移動),H值是。你大致應該知道如何計算其他方格的H值了~。每個格子的F值,還是簡單的由G和H相加得到
繼續搜索
為了繼續搜索,我們簡單的從開啟列表中選擇F值最低的方格。然后,對選中的方格做如下處理:
4,把它從開啟列表中刪除,然后添加到關閉列表中。
5,檢查所有相鄰格子。跳過那些已經在關閉列表中的或者不可通過的(有墻,水的地形,或者其他無法通過的地形),把他們添加進開啟列表,如果他們還不在里面的話。把選中的方格作為新的方格的父節點。
6,如果某個相鄰格已經在開啟列表里了,檢查現在的這條路徑是否更好。換句話說,檢查如果我們用新的路徑到達它的話,G值是否會更低一些。如果不是,那就什么都不做。
另一方面,如果新的G值更低,那就把相鄰方格的父節點改為目前選中的方格(在上面的圖表中,把箭頭的方向改為指向這個方格)。最后,重新計算F和G的值。如果這看起來不夠清晰,你可以看下面的圖示。
好了,讓我們看看它是怎么運作的。我們最初的格方格中,在起點被切換到關閉列表中后,還剩格留在開啟列表中。這里面,F值最低的那個是起始格右側緊鄰的格子,它的F值是。因此我們選擇這一格作為下一個要處理的方格。在緊隨的圖中,它被用藍色突出顯示。
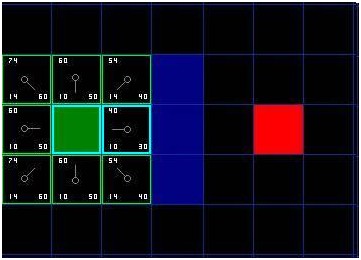
[圖-4]
首先,我們把它從開啟列表中取出,放入關閉列表(這就是他被藍色突出顯示的原因)。然后我們檢查相鄰的格子。哦,右側的格子是墻,所以我們略過。左側的格子是起始格。它在關閉列表里,所以我們也跳過它。
其他格已經在開啟列表里了,于是我們檢查G值來判定,如果通過這一格到達那里,路徑是否更好。我們來看選中格子下面的方格。它的G值是。如果我們從當前格移動到那里,G值就會等于(到達當前格的G值是,移動到上面的格子將使得G值增加)。因為G值大于,所以這不是更好的路徑。如果你看圖,就能理解。與其通過先水平移動一格,再垂直移動一格,還不如直接沿對角線方向移動一格來得簡單。
當我們對已經存在于開啟列表中的個臨近格重復這一過程的時候,我們發現沒有一條路徑可以通過使用當前格子得到改善,所以我們不做任何改變。既然我們已經檢查過了所有鄰近格,那么就可以移動到下一格了。
于是我們檢索開啟列表,現在里面只有7格了,我們仍然選擇其中F值最低的。有趣的是,這次,有兩個格子的數值都是。我們如何選擇?這并不麻煩。從速度上考慮,選擇最后添加進列表的格子會更快捷。這種導致了尋路過程中,在靠近目標的時候,優先使用新找到的格子的偏好。但這無關緊要。(對相同數值的不同對待,導致不同版本的A*算法找到等長的不同路徑)那我們就選擇起始格右下方的格子,如圖:
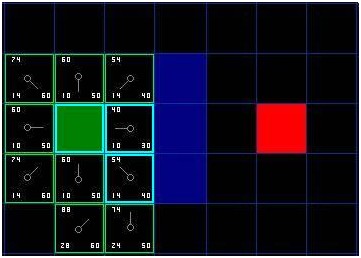
[圖-5]
這次,當我們檢查相鄰格的時候,發現右側是墻,于是略過。上面一格也被略過。我們也略過了墻下面的格子。為什么呢?因為你不能在不穿越墻角的情況下直接到達那個格子。你的確需要先往下走然后到達那一格,按部就班的走過那個拐角。(注解:穿越拐角的規則是可選的。它取決于你的節點是如何放置的。)
這樣一來,就剩下了其他格。當前格下面的另外兩個格子目前不在開啟列表中,于是我們添加他們,并且把當前格指定為他們的父節點。其余格,兩個已經在關閉列表中(起始格,和當前格上方的格子,在表格中藍色高亮顯示),于是我們略過它們。最后一格,在當前格的左側,將被檢查通過這條路徑,G值是否更低。不必擔心,我們已經準備好檢查開啟列表中的下一格了。
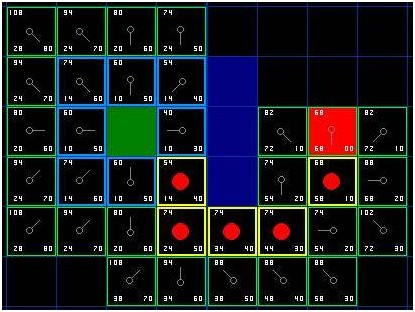
我們重復這個過程,直到目標格被添加進關閉列表(注解),就如在下面的圖中所看到的。
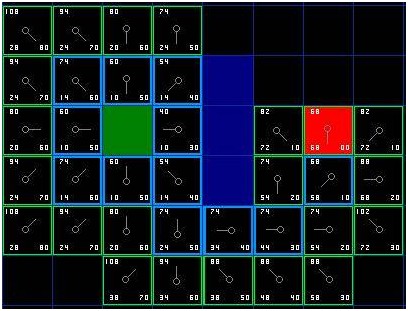
[圖-6]
注意,起始格下方格子的父節點已經和前面不同的。之前它的G值是,并且指向右上方的格子。現在它的G值是,指向它上方的格子。這在尋路過程中的某處發生,當應用新路徑時,G值經過檢查變得低了-于是父節點被重新指定,G和F值被重新計算。盡管這一變化在這個例子中并不重要,在很多場合,這種變化會導致尋路結果的巨大變化。
那么,我們怎么確定這條路徑呢?很簡單,從紅色的目標格開始,按箭頭的方向朝父節點移動。這最終會引導你回到起始格,這就是你的路徑!看起來應該像圖中那樣。從起始格A移動到目標格B只是簡單的從每個格子(節點)的中點沿路徑移動到下一個,直到你到達目標點。就這么簡單。
[圖-7]
A*方法總結
好,現在你已經看完了整個說明,讓我們把每一步的操作寫在一起:
1,把起始格添加到開啟列表。
2,重復如下的工作:
a) 尋找開啟列表中F值最低的格子。我們稱它為當前格。
b) 把它切換到關閉列表。
c) 對相鄰的格中的每一個?
* 如果它不可通過或者已經在關閉列表中,略過它。反之如下。
* 如果它不在開啟列表中,把它添加進去。把當前格作為這一格的父節點。記錄這一格的F,G,和H值。
* 如果它已經在開啟列表中,用G值為參考檢查新的路徑是否更好。更低的G值意味著更好的路徑。如果是這樣,就把這一格的父節點改成當前格,并且重新計算這一格的G和F值。如果你保持你的開啟列表按F值排序,改變之后你可能需要重新對開啟列表排序。
d) 停止,當你
* 把目標格添加進了關閉列表(注解),這時候路徑被找到,或者
* 沒有找到目標格,開啟列表已經空了。這時候,路徑不存在。
3.保存路徑。從目標格開始,沿著每一格的父節點移動直到回到起始格。這就是你的路徑。
(注解:在這篇文章的較早版本中,建議的做法是當目標格(或節點)被加入到開啟列表,而不是關閉列表的時候停止尋路。這么做會更迅速,而且幾乎總是能找到最短的路徑,但不是絕對的。當從倒數第二個節點到最后一個(目標節點)之間的移動耗費懸殊很大時-例如剛好有一條河穿越兩個節點中間,這時候舊的做法和新的做法就會有顯著不同。)
題外話
離題一下,見諒,值得一提的是,當你在網上或者相關論壇看到關于A*的不同的探討,你有時會看到一些被當作A*算法的代碼而實際上他們不是。要使用A*,你必須包含上面討論的所有元素--特定的開啟和關閉列表,用F,G和H作路徑評價。有很多其他的尋路算法,但他們并不是A*,A*被認為是他們當中最好的。Bryan Stout在這篇文章后面的參考文檔中論述了一部分,包括他們的一些優點和缺點。有時候特定的場合其他算法會更好,但你必須很明確你在作什么。好了,夠多的了。回到文章。
實現的注解
現在你已經明白了基本原理,寫你的程序的時候還得考慮一些額外的東西。下面這些材料中的一些引用了我用C++和Blitz Basic寫的程序,但對其他語言寫的代碼同樣有效。
1.其他單位(避免碰撞):如果你恰好看了我的例子代碼,你會發現它完全忽略了其他單位。我的尋路者事實上可以相互穿越。取決于具體的游戲,這也許可以,也許不行。如果你打算考慮其他單位,希望他們能互相繞過,我建議你只考慮靜止或那些在計算路徑時臨近當前單位的單位,把它們當前的位置標志為可通過的。對于臨近的運動著的單位,你可以通過懲罰它們各自路徑上的節點,來鼓勵這些尋路者找到不同的路徑(更多的描述見#2).
如果你選擇了把其他正在移動并且遠離當前尋路單位的那些單位考慮在內,你將需要實現一種方法及時預測在何時何地碰撞可能會發生,以便恰當的避免。否則你極有可能得到一條怪異的路徑,單位突然轉彎試圖避免和一個已經不存在的單位發生碰撞。
當然,你也需要寫一些碰撞檢測的代碼,因為無論計算的時候路徑有多完美,它也會因時間而改變。當碰撞發生時,一個單位必須尋找一條新路徑,或者,如果另一個單位正在移動并且不是正面碰撞,在繼續沿當前路徑移動之前,等待那個單位離開。
這些提示大概可以讓你開始了。如果你想了解更多,這里有些你可能會覺得有用的鏈接:
*自治角色的指導行為:Craig Reynold在指導能力上的工作和尋路有些不同,但是它可以和尋路整合從而形成更完整的移動和碰撞檢測系統。
*電腦游戲中的長短距指導:指導和尋路方面著作的一個有趣的考察。這是一個pdf文件。
*協同單位移動:一個兩部分系列文章的第一篇,內容是關于編隊和基于分組的移動,作者是帝國時代(Age of Empires)的設計者Dave Pottinger.
*實現協同移動:Dave Pottinger文章系列的第二篇。
2. 不同的地形損耗:在這個教程和我附帶的程序中,地形只能是二者之-可通過的和不可通過的。但是你可能會需要一些可通過的地形,但是移動耗費更高-沼澤,小山,地牢的樓梯,等等。這些都是可通過但是比平坦的開闊地移動耗費更高的地形。類似的,道路應該比自然地形移動耗費更低。
這個問題很容易解決,只要在計算任何地形的G值的時候增加地形損耗就可以了。簡單的給它增加一些額外的損耗就可以了。由于A*算法已經按照尋找最低耗費的路徑來設計,所以很容易處理這種情況。在我提供的這個簡單的例子里,地形只有可通過和不可通過兩種,A*會找到最短,最直接的路徑。但是在地形耗費不同的場合,耗費最低的路徑也許會包含很長的移動距離-就像沿著路繞過沼澤而不是直接穿過它。
一種需額外考慮的情況是被專家稱之為“influence mapping”的東西(暫譯為影響映射圖)。就像上面描述的不同地形耗費一樣,你可以創建一格額外的分數系統,并把它應用到尋路的AI中。假設你有一張有大批尋路者的地圖,他們都要通過某個山區。每次電腦生成一條通過那個關口的路徑,它就會變得更擁擠。如果你愿意,你可以創建一個影響映射圖對有大量屠殺事件的格子施以不利影響。這會讓計算機更傾向安全些的路徑,并且幫助它避免總是僅僅因為路徑短(但可能更危險)而持續把隊伍和尋路者送到某一特定路徑。
另一個可能得應用是懲罰周圍移動單位路徑上得節點。A*的一個底限是,當一群單位同時試圖尋路到接近的地點,這通常會導致路徑交疊。以為一個或者多個單位都試圖走相同或者近似的路徑到達目的地。對其他單位已經“認領”了的節點增加一些懲罰會有助于你在一定程度上分離路徑,降低碰撞的可能性。然而,如果有必要,不要把那些節點看成不可通過的,因為你仍然希望多個單位能夠一字縱隊通過擁擠的出口。同時,你只能懲罰那些臨近單位的路徑,而不是所有路徑,否則你就會得到奇怪的躲避行為例如單位躲避路徑上其他已經不在那里的單位。還有,你應該只懲罰路徑當前節點和隨后的節點,而不應處理已經走過并甩在身后的節點。
3. 處理未知區域:你是否玩過這樣的PC游戲,電腦總是知道哪條路是正確的,即使它還沒有偵察過地圖?對于游戲,尋路太好會顯得不真實。幸運的是,這是一格可以輕易解決的問題。
答案就是為每個不同的玩家和電腦(每個玩家,而不是每個單位--那樣的話會耗費大量的內存)創建一個獨立的“knownWalkability”數組,每個數組包含玩家已經探索過的區域,以及被當作可通過區域的其他區域,直到被證實。用這種方法,單位會在路的死端徘徊并且導致錯誤的選擇直到他們在周圍找到路。一旦地圖被探索了,尋路就像往常那樣進行。
4. 平滑路徑:盡管A*提供了最短,最低代價的路徑,它無法自動提供看起來平滑的路徑。看一下我們的例子最終形成的路徑(在圖)。最初的一步是起始格的右下方,如果這一步是直接往下的話,路徑不是會更平滑一些嗎?有幾種方法來解決這個問題。當計算路徑的時候可以對改變方向的格子施加不利影響,對G值增加額外的數值。也可以換種方法,你可以在路徑計算完之后沿著它跑一遍,找那些用相鄰格替換會讓路徑看起來更平滑的地方。想知道完整的結果,查看Toward More Realistic Pathfinding,一篇(免費,但是需要注冊)Marco Pinter發表在Gamasutra.com的文章
5. 非方形搜索區域:在我們的例子里,我們使用簡單的D方形圖。你可以不使用這種方式。你可以使用不規則形狀的區域。想想冒險棋的游戲,和游戲中那些國家。你可以設計一個像那樣的尋路關卡。為此,你可能需要建立一個國家相鄰關系的表格,和從一個國家移動到另一個的G值。你也需要估算H值的方法。其他的事情就和例子中完全一樣了。當你需要向開啟列表中添加新元素的時候,不需使用相鄰的格子,取而代之的是從表格中尋找相鄰的國家。
類似的,你可以為一張確定的地形圖創建路徑點系統,路徑點一般是路上,或者地牢通道的轉折點。作為游戲設計者,你可以預設這些路徑點。兩個路徑點被認為是相鄰的如果他們之間的直線上沒有障礙的話。在冒險棋的例子里,你可以保存這些相鄰信息在某個表格里,當需要在開啟列表中添加元素的時候使用它。然后你就可以記錄關聯的G值(可能使用兩點間的直線距離),H值(可以使用到目標點的直線距離),其他都按原先的做就可以了。Amit Patel 寫了其他方法的摘要。另一個在非方形區域搜索RPG地圖的例子,查看我的文章Two-Tiered A* Pathfinding。(譯者注:譯文: A*分層尋路)
6. 一些速度方面的提示:當你開發你自己的A*程序,或者改寫我的,你會發現尋路占據了大量的CPU時間,尤其是在大地圖上有大量對象在尋路的時候。如果你閱讀過網上的其他材料,你會明白,即使是開發了星際爭霸或帝國時代的專家,這也無可奈何。如果你覺得尋路太過緩慢,這里有一些建議也許有效:
* 使用更小的地圖或者更少的尋路者。
* 不要同時給多個對象尋路。取而代之的是把他們加入一個隊列,把尋路過程分散在幾個游戲周期中。如果你的游戲以周期每秒的速度運行,沒人能察覺。但是當大量尋路者計算自己路徑的時候,他們會發覺游戲速度突然變慢。
* 盡量使用更大的地圖網格。這降低了尋路中搜索的總網格數。如果你有志氣,你可以設計兩個或者更多尋路系統以便使用在不同場合,取決于路徑的長度。這也正是專業人士的做法,用大的區域計算長的路徑,然后在接近目標的時候切換到使用小格子/區域的精細尋路。如果你對這個觀點感興趣,查閱我的文章Two-Tiered A* Pathfinding。(譯者注:譯文:A*分層尋路)
* 使用路徑點系統計算長路徑,或者預先計算好路徑并加入到游戲中。
* 預處理你的地圖,表明地圖中哪些區域是不可到達的。我把這些區域稱作“孤島”。事實上,他們可以是島嶼或其他被墻壁包圍等無法到達的任意區域。A*的下限是,當你告訴它要尋找通往那些區域的路徑時,它會搜索整個地圖,直到所有可到達的方格/節點都被通過開啟列表和關閉列表的計算。這會浪費大量的CPU時間。可以通過預先確定這些區域(比如通過flood-fill或類似的方法)來避免這種情況的發生,用某些種類的數組記錄這些信息,在開始尋路前檢查它。
* 在一個擁擠的類似迷宮的場合,把不能連通的節點看作死端。這些區域可以在地圖編輯器中預先手動指定,或者如果你有雄心壯志,開發一個自動識別這些區域的算法。給定死端的所有節點可以被賦予一個唯一的標志數字。然后你就可以在尋路過程中安全的忽略所有死端,只有當起點或者終點恰好在死端的某個節點的時候才需要考慮它們。
7. 維護開啟列表:這是A*尋路算法最重要的組成部分。每次你訪問開啟列表,你都需要尋找F值最低的方格。有幾種不同的方法實現這一點。你可以把路徑元素隨意保存,當需要尋找F值最低的元素的時候,遍歷開啟列表。這很簡單,但是太慢了,尤其是對長路徑來說。這可以通過維護一格排好序的列表來改善,每次尋找F值最低的方格只需要選取列表的首元素。當我自己實現的時候,這種方法是我的首選。
在小地圖。這種方法工作的很好,但它并不是最快的解決方案。更苛求速度的A*程序員使用叫做二叉堆的方法,這也是我在代碼中使用的方法。憑我的經驗,這種方法在大多數場合會快~倍,并且在長路經上速度呈幾何級數提升(10倍以上速度)。如果你想了解更多關于二叉堆的內容,查閱我的文章,Using Binary Heaps in A* Pathfinding。(譯者注:譯文:在A*尋路中使用二叉堆)
另一個可能的瓶頸是你在多次尋路之間清除和保存你的數據結構的方法。我個人更傾向把所有東西都存儲在數組里面。雖然節點可以以面向對象的風格被動態的產生,記錄和保存,我發現創建和刪除對象所增加的大量時間,以及多余的管理層次減慢的整個過程的速度。但是,如果你使用數組,你需要在調用之間清理數據。這中情形你想做的最后一件事就是在尋路調用之后花點時間把一切歸零,尤其是你的地圖很大的時候。
我通過使用一個叫做whichList(x,y)的二維數組避免這種開銷,數組的每個元素表明了節點在開啟列表還是在關閉列表中。嘗試尋路之后,我沒有清零這個數組。取而代之的是,我在新的尋路中重置onClosedList和onOpenList的數值,每次尋路兩個都+5或者類似其他數值。這種方法,算法可以安全的跳過前面尋路留下的臟數據。我還在數組中儲存了諸如F,G和H的值。這樣一來,我只需簡單的重寫任何已經存在的值而無需被清除數組的操作干擾。將數據存儲在多維數組中需要更多內存,所以這里需要權衡利弊。最后,你應該使用你最得心應手的方法。
8. Dijkstra的算法:盡管A*被認為是通常最好的尋路算法(看前面的“題外話”),還是有一種另外的算法有它的可取之處-Dijkstra算法。Dijkstra算法和A*本質是相同的,只有一點不同,就是Dijkstra算法沒有啟發式(H值總是)。由于沒有啟發式,它在各個方向上平均搜索。正如你所預料,由于Dijkstra算法在找到目標前通常會探索更大的區域,所以一般會比A*更慢一些。
那么為什么要使用這種算法呢?因為有時候我們并不知道目標的位置。比如說你有一個資源采集單位,需要獲取某種類型的資源若干。它可能知道幾個資源區域,但是它想去最近的那個。這種情況,Dijkstra算法就比A*更適合,因為我們不知道哪個更近。用A*,我們唯一的選擇是依次對每個目標許路并計算距離,然后選擇最近的路徑。我們尋找的目標可能會有不計其數的位置,我們只想找其中最近的,而我們并不知道它在哪里,或者不知道哪個是最近的。
看完上面的介紹,再來看一個比較經典的題目:knight moves。貌似也叫漢密爾頓路徑,具體的我也不記得了。對這個問題我用A*算法來求解,正所謂光說不練是沒有用的
http://acm.pku.edu.cn/JudgeOnline/problem?id=2243
problem statement
A friend of you is doing research on the Traveling Knight Problem (TKP) where you are to find the shortest closed tour of knight moves that visits each square of a given set of n squares on a chessboard exactly once. He thinks that the most difficult part of the problem is determining the smallest number of knight moves between two given squares and that, once you have accomplished this, finding the tour would be easy.
Of course you know that it is vice versa. So you offer him to write a program that solves the "difficult" part.
Your job is to write a program that takes two squares a and b as input and then determines the number of knight moves on a shortest route from a to b.
Input Specification
The input file will contain one or more test cases. Each test case consists of one line containing two squares separated by one space. A square is a string consisting of a letter (a-h) representing the column and a digit (1-8) representing the row on the chessboard.
Output Specification
For each test case, print one line saying "To get from xx to yy takes n knight moves.".
Sample Input
e2 e4
a1 b2
b2 c3
a1 h8
a1 h7
h8 a1
b1 c3
f6 f6
Sample Output
To get from e2 to e4 takes 2 knight moves.
To get from a1 to b2 takes 4 knight moves.
To get from b2 to c3 takes 2 knight moves.
To get from a1 to h8 takes 6 knight moves.
To get from a1 to h7 takes 5 knight moves.
To get from h8 to a1 takes 6 knight moves.
To get from b1 to c3 takes 1 knight moves.
To get from f6 to f6 takes 0 knight moves.
題目的意思大概是說:在國際象棋的棋盤上,一匹馬共有8個可能的跳躍方向,求從起點到目標點之間的最少跳躍次數。
A* code:
1 #include <iostream>
2 #include <queue>
3 using namespace std;
4
5 struct knight{
6 int x,y,step;
7 int g,h,f;
8 bool operator < (const knight & k) const{ //重載比較運算符
9 return f > k.f;
10 }
11 }k;
12 bool visited[8][8]; //已訪問標記(關閉列表)
13 int x1,y1,x2,y2,ans; //起點(x1,y1),終點(x2,y2),最少移動次數ans
14 int dirs[8][2]={{-2,-1},{-2,1},{2,-1},{2,1},{-1,-2},{-1,2},{1,-2},{1,2}};//8個移動方向
15 priority_queue<knight> que; //最小優先級隊列(開啟列表)
16
17 bool in(const knight & a){ //判斷knight是否在棋盤內
18 if(a.x<0 || a.y<0 || a.x>=8 || a.y>=8)
19 return false;
20 return true;
21 }
22 int Heuristic(const knight &a){ //manhattan估價函數
23 return (abs(a.x-x2)+abs(a.y-y2))*10;
24 }
25 void Astar(){ //A*算法
26 knight t,s;
27 while(!que.empty()){
28 t=que.top(),que.pop(),visited[t.x][t.y]=true;
29 if(t.x==x2 && t.y==y2){
30 ans=t.step;
31 break;
32 }
33 for(int i=0;i<8;i++){
34 s.x=t.x+dirs[i][0],s.y=t.y+dirs[i][1];
35 if(in(s) && !visited[s.x][s.y]){
36 s.g = t.g + 23; //23表示根號5乘以10再取其ceil
37 s.h = Heuristic(s);
38 s.f = s.g + s.h;
39 s.step = t.step + 1;
40 que.push(s);
41 }
42 }
43 }
44 }
45 int main(){
46 char line[5];
47 while(gets(line)){
48 x1=line[0]-'a',y1=line[1]-'1',x2=line[3]-'a',y2=line[4]-'1';
49 memset(visited,false,sizeof(visited));
50 k.x=x1,k.y=y1,k.g=k.step=0,k.h=Heuristic(k),k.f=k.g+k.h;
51 while(!que.empty()) que.pop();
52 que.push(k);
53 Astar();
54 printf("To get from %c%c to %c%c takes %d knight moves.\n",line[0],line[1],line[3],line[4],ans);
55 }
56 return 0;
57 }
58