之前在公司里維護了一個名字服務����,這個名字服務日常管理了近4000臺機器���,有4000個左右的客戶端連接上來獲取機器信息����,由于其基本是一個單點服務,所以某些模塊接近瓶頸����。后來倒是有重構計劃����,詳細設計做了����,代碼都寫了一部分,結果由于某些原因重構就被終止了���。
JCM是我業余時間用Java重寫的一個版本,功能上目前只實現了基礎功能�。由于它是個完全分布式的架構�,所以理論上可以橫向擴展���,大大增強系統的服務能力�。
名字服務
在分布式系統中,某個服務為了提升整體服務能力�,通常部署了很多實例���。這里我把這些提供相同服務的實例統稱為集群(cluster),每個實例稱為一個節點(Node)。一個應用可能會使用很多cluster����,每次訪問一個cluster時�,就通過名字服務獲取該cluster下一個可用的node�。那么,名字服務至少需要包含的功能:
- 根據cluster名字獲取可用的node
- 對管理的所有cluster下的所有node進行健康度的檢測,以保證始終返回可用的node
有些名字服務僅對node管理,不參與應用與node間的通信�,而有些則可能作為應用與node間的通信轉發器�。雖然名字服務功能簡單�,但是要做一個分布式的名字服務還是比較復雜的,因為數據一旦分布式了����,就會存在同步�、一致性問題的考慮等���。
What’s JCM
JCM圍繞前面說的名字服務基礎功能實現����。包含的功能:
- 管理cluster到node的映射
- 分布式架構,可水平擴展以實現管理10,000個node的能力�,足以管理一般公司的后臺服務集群
- 對每個node進行健康檢查����,健康檢查可基于HTTP協議層的檢測或TCP連接檢測
- 持久化cluster/node數據,通過zookeeper保證數據一致性
- 提供JSON HTTP API管理cluster/node數據����,后續可提供Web管理系統
- 以庫的形式提供與server的交互�,庫本身提供各種負載均衡策略����,保證對一個cluster下node的訪問達到負載均衡
項目地址git jcm
JCM主要包含兩部分:
- jcm.server,JCM名字服務���,需要連接zookeeper以持久化數據
- jcm.subscriber�,客戶端庫,負責與jcm.server交互,提供包裝了負載均衡的API給應用使用
架構
基于JCM的系統整體架構如下:
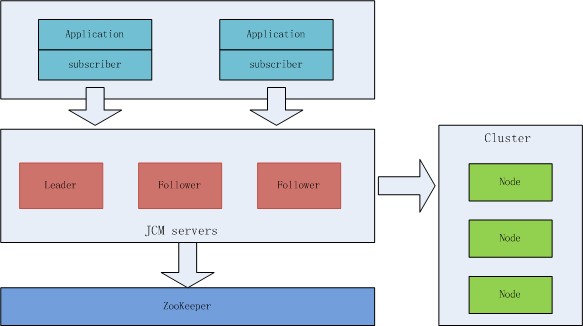
cluster本身是不需要依賴JCM的���,要通過JCM使用這些cluster,只需要通過JCM HTTP API注冊這些cluster到jcm.server上。要通過jcm.server使用這些cluster�,則是通過jcm.subscriber來完成�。
使用
可參考git READMe.md
需要jre1.7+
- 啟動zookeeper
- 下載jcm.server git jcm.server-0.1.0.jar
- 在
jcm.server-0.1.0.jar目錄下建立config/application.properties文件進行配置����,參考config/application.properties
-
啟動jcm.server
java -jar jcm.server-0.1.0.jar
-
注冊需要管理的集群,參考cluster描述:doc/cluster_sample.json���,通過HTTP API注冊:
curl -i -X POST http://10.181.97.106:8080/c -H "Content-Type:application/json" --data-binary @./doc/cluster_sample.json
部署好了jcm.server,并注冊了cluster后,就可以通過jcm.subscriber使用:
// 傳入需要使用的集群名hello9/hello�,以及傳入jcm.server地址���,可以多個:127.0.0.1:8080
Subscriber subscriber = new Subscriber( Arrays.asList("127.0.0.1:8080"), Arrays.asList("hello9", "hello"));
// 使用輪詢負載均衡策略
RRAllocator rr = new RRAllocator();
subscriber.addListener(rr);
subscriber.startup();
for (int i = 0; i < 2; ++i) {
// rr.alloc 根據cluster名字獲取可用的node
System.out.println(rr.alloc("hello9", ProtoType.HTTP));
}
subscriber.shutdown();
JCM實現
JCM目前的實現比較簡單�,參考模塊圖:
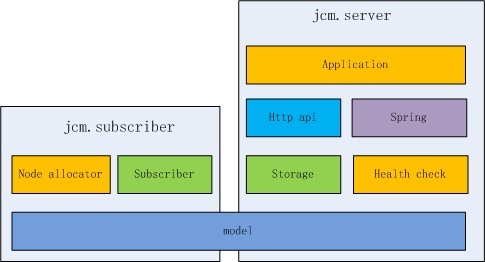
- model����,即cluster/node這些數據結構的描述,同時被jcm.server和jcm.subscriber依賴
- storage,持久化數據到zookeeper,同時包含jcm.server實例之間的數據同步
- health check,健康檢查模塊����,對各個node進行健康檢查
以上模塊都不依賴Spring���,基于以上模塊又有:
- http api�,使用spring-mvc����,包裝了一些JSON HTTP API
- Application,基于spring-boot,將各個基礎模塊組裝起來,提供standalone的模式啟動���,不用部署到tomcat之類的servlet容器中
jcm.subscriber的實現更簡單,主要是負責與jcm.server進行通信,以更新自己當前的model層數據����,同時提供各種負載均衡策略接口:
- subscriber,與jcm.server通信����,定期增量拉取數據
- node allocator���,通過listener方式從subscriber中獲取數據���,同時實現各種負載均衡策略�,對外統一提供
alloc node的接口
接下來看看關鍵功能的實現
數據同步
既然jcm.server是分布式的�,每一個jcm.server instance(實例)都是支持數據讀和寫的,那么當jcm.server管理著一堆cluster上萬個node時�,每一個instance是如何進行數據同步的�?jcm.server中的數據主要有兩類:
- cluster本身的數據�,包括cluster/node的描述,例如cluster name���、node IP、及其他附屬數據
- node健康檢查的數據
對于cluster數據���,因為cluster對node的管理是一個兩層的樹狀結構,而對cluster有增刪node的操作���,所以并不能在每一個instance上都提供真正的數據寫入,這樣會導致數據丟失����。假設同一時刻在instance A和instance B上同時對cluster c1添加節點N1和N2���,那么instance A寫入c1(N1)�,而instance B還沒等到數據同步就寫入c1(N2),那么c1(N1)就被覆蓋為c1(N2)���,從而導致添加的節點N1丟失。
所以,jcm.server instance是分為leader和follower的����,真正的寫入操作只有leader進行,follower收到寫操作請求時轉發給leader�。leader寫數據優先更新內存中的數據再寫入zookeeper����,內存中的數據更新當然是需要加鎖互斥的���,從而保證數據的正確性���。
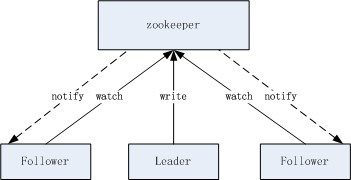
leader和follower是如何確定角色的�?這個很簡單,標準的利用zookeeper來進行主從選舉的實現�。
jcm.server instance數據間的同步是基于zookeeper watch機制的�。這個可以算做是一個JCM的一個瓶頸�,每一個instance都會作為一個watch,使得實際上jcm.server并不能無限水平擴展�,擴展到一定程度后�,watch的效率就可能不足以滿足性能了�,參考zookeeper節點數與watch的性能測試 (那個時候我就在考慮對我們系統的重構了) 。
jcm.server中對node健康檢查的數據采用同樣的同步機制����,但node健康檢查數據是每一個instance都會寫入的���,下面看看jcm.server是如何通過分布式架構來分擔壓力的���。
健康檢查
jcm.server的另一個主要功能的是對node的健康檢查����,jcm.server集群可以管理幾萬的node�,既然已經是分布式了,那么顯然是要把node均分到多個instance的���。這里我是以cluster來分配的�,方法就是簡單的使用一致性哈希。通過一致性哈希����,決定一個cluster是否屬于某個instance負責�。每個instance都有一個server spec����,也就是該instance對外提供服務的地址(IP+port),這樣在任何一個instance上,它看到的所有instance server spec都是相同的���,從而保證在每一個instance上計算cluster的分配得到的結果都是一致的。
健康檢查按cluster劃分,可以簡化數據的寫沖突問題,在正常情況下,每個instance寫入的健康檢查結果都是不同的�。
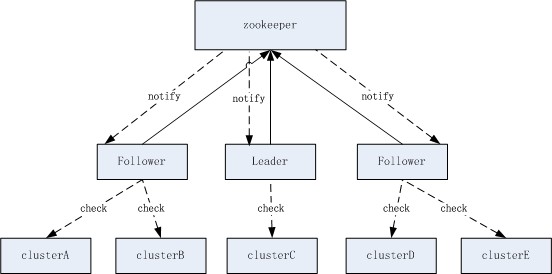
健康檢查一般以1秒的頻率進行�,jcm.server做了優化���,當檢查結果和上一次一樣時����,并不寫入zookeeper。寫入的數據包含了node的完整key (IP+Port+Spec),這樣可以簡化很多地方的數據同步問題���,但會增加寫入數據的大小���,寫入數據的大小是會影響zookeeper的性能的���,所以這里簡單地對數據進行了壓縮�。
健康檢查是可以支持多種檢查實現的���,目前只實現了HTTP協議層的檢查。健康檢查自身是單個線程����,在該線程中基于異步HTTP庫����,發起異步請求�,實際的請求在其他線程中發出。
jcm.subscriber通信
jcm.subscriber與jcm.server通信,主要是為了獲取最新的cluster數據。subscriber初始化時會拿到一個jcm.server instance的地址列表���,訪問時使用輪詢策略以平衡jcm.server在處理請求時的負載�。subscriber每秒都會請求一次數據�,請求中描述了本次請求想獲取哪些cluster數據�,同時攜帶一個cluster的version���。每次cluster在server變更時�,version就變更(時間戳)����。server回復請求時���,如果version已最新,只需要回復node的狀態。
subscriber可以拿到所有狀態的node,后面可以考慮只拿正常狀態的node�,進一步減少數據大小�。
壓力測試
目前只對健康檢查部分做了壓測,詳細參考test/benchmark.md。在A7服務器上測試�,發現寫zookeeper及zookeeper的watch足以滿足要求�,jcm.server發起的HTTP請求是主要的性能熱點,單jcm.server instance大概可以承載20000個node的健康監測。
網絡帶寬:
1
2
3
4
5
|
Time ---------------------traffic--------------------
Time bytin bytout pktin pktout pkterr pktdrp
01/07/15-21:30:48 3.2M 4.1M 33.5K 34.4K 0.00 0.00
01/07/15-21:30:50 3.3M 4.2M 33.7K 35.9K 0.00 0.00
01/07/15-21:30:52 2.8M 4.1M 32.6K 41.6K 0.00 0.00
|
CPU�,通過jstack查看主要的CPU消耗在HTTP庫實現層,以及健康檢查線程:
1
2
3
4
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13301 admin 20 0 13.1g 1.1g 12m R 76.6 2.3 2:40.74 java httpchecker
13300 admin 20 0 13.1g 1.1g 12m S 72.9 2.3 0:48.31 java
13275 admin 20 0 13.1g 1.1g 12m S 20.1 2.3 0:18.49 java
|
代碼中增加了些狀態監控:
1
|
checker HttpChecker stat count 20 avg check cost(ms) 542.05, avg flush cost(ms) 41.35
|
表示平均每次檢查耗時542毫秒,寫數據因為開啟了cache沒有參考價值�。
雖然還可以從我自己的代碼中做不少優化�,但既然單機可以承載20000個節點的檢測,一般的應用遠遠足夠了�。
總結
名字服務在分布式系統中雖然是基礎服務���,但往往承擔了非常重要的角色����,數據同步出現錯誤����、節點狀態出現瞬時的錯誤�,都可能對整套系統造成較大影響,業務上出現較大故障���。所以名字服務的健壯性�、可用性非常重要����。實現中需要考慮很多異常情況,包括網絡不穩定�、應用層的錯誤等�。為了提高足夠的可用性,一般還會加多層的數據cache�,例如subscriber端的本地cache����,server端的本地cache,以保證在任何情況下都不會影響應用層的服務���。