http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650325637&idx=1&sn=e3b66513e2ad39513d3637443e91995a&chksm=f235a58fc5422c99b2000599486858d0cc46af88eea1015b536205c995927a282490e92b3e60&mpshare=1&scene=1&srcid=1104m9Edzx1ubd7UlBlGBPaX#rd
國際人工智能聯合會議( International Joint Conference on Artificial Intelligence,IJCAI )是聚集人工智能領域研究者和從業者的盛會,也是人工智能領域中最主要的學術會議之一。1969 年到 2015 年,該大會在每個奇數年舉辦,現已舉辦了 24 屆。隨著近幾年來人工智能領域的研究和應用的持續升溫,從 2016 年開始,IJCAI 大會將變成每年舉辦一次的年度盛會;今年是該大會第一次在偶數年舉辦。第 25 屆 IJCAI 大會于 7 月 9 日- 15 日在紐約舉辦。本屆會議的舉辦地在繁華喧囂的紐約時代廣場附近,正映襯了人工智能領域幾年來的火熱氛圍。此次大會包括7場特邀演講、4場獲獎演講、551篇同行評議論文的presentation,41場workshop、37堂tutorial、22個demo等。深度學習成為了IJCAI 2016的關鍵詞之一,以深度學習為主題的論文報告session共計有3個。本期我們從中選擇了兩篇深度學習領域的相關論文進行選讀,組織了相關領域的博士研究生,介紹論文的主要思想,并對論文的貢獻進行點評。Makeup Like a Superstar Deep Localized Makeup Transfer Network在人臉分割的應用中,美妝是一個受眾較廣的問題。給出一張素顏正面照,如果能夠給出其最適合的化妝風格并將其渲染到這張素顏臉上,可以讓女孩子們更方便地找到適合的風格。中科院信工所劉偲博士等人的論文所解決的問題就是完成一個功能更完善的人臉自動美妝應用,不僅能夠給素顏的圖片上妝,而且可以為用戶推薦最適合的妝容,達到更高的用戶滿意度。文章采用端到端的方法完成風格推薦、五官提取、妝容遷移這三個步驟,同時在損失函數中還考慮平滑性與臉部對稱性的約束,最終達到了state-of-the-art效果,本文方法的整體框架如下:核心方法:首先風格推薦,是從已上妝人臉數據庫中挑選與當前素顏人臉最相近的圖片。具體方法是選取與當前人臉特征的歐氏距離最小者作為推薦結果,該特征即網絡輸出的feature map。然后是五官提取。五官提取是采用全卷積網絡做圖像分割實現face parsing,而已上妝數據庫還要多一個眼影的部分,對于素顏圖片則沒有眼影部分的問題,因此要根據眉眼特征點定位給出眼影區域。由于妝容分割的部分相對于背景更重要,網絡輸出loss選擇的是加權交叉熵,權重為使驗證集上F1 score最大的權重值。另一方面,數據庫中的臉都為正面,具有對稱性,因此加上了對稱性的先驗約束,具體方法為在輸出每個像素點的類別概率預測值后,將這個值與它的對稱點再取均值作為最終輸出:最后是妝容遷移。本文中的妝容包括粉底(對應面部),唇彩(對應雙唇),眼影(對應雙眼)。眼影的遷移比較特殊,因為它不是直接改變雙眼的部分,文章針對此設計了一個loss意指給需要的人臉上妝后眼影部分與推薦的帶妝人臉眼影的特征的L2 Norm (該特征為從五官提取部分用到的FCN第一層卷積特征conv1-1)。類似的,對面部、上唇與下唇的loss: 不同的是它計算了conv1-1,conv2-1, conv3-1, conv4-1, conv5-1層特征的相似度。最后給出的使這個loss最小的A(即最終給出的妝后人臉)滿足以下條件:其中Rl、Rr表示左眼右眼眼影的loss,Rf表示臉部粉底的loss,Rup、Rlow表示上唇下唇唇彩的loss,Rs表示結構的loss(計算公式與眼影loss相同,但Sb、Sr中元素值都為1)。人臉妝容的平滑性可以通過以下公式進行進一步約束:本文用end-to-end深度卷積神經網絡學習出妝前妝后面部特征部位的對應關系,并進行妝容的遷移,流程較為簡單,在考慮了人臉結構對稱性和平滑性約束后達到了理想的效果,部分實驗結果如下:Feature Learning based Deep Supervised Hashing with Pairwise Labels在信息檢索中,哈希學習算法將圖像/文本/視頻等復雜數據表示成一串緊致的二值編碼(只由0/1或者±1構成的特征向量),從而實現時間、空間高效的最近鄰搜索。在哈希學習算法中,給定一個訓練集,目標是學到一組映射函數,使得訓練集中的數據經過映射后,相似的樣本被映射到相似的二值編碼(二值編碼的相似性用Hamming距離度量)。南京大學李武軍組的這篇文章中,作者提出了一種使用pairwise label進行哈希學習的方法。通常的圖像標簽指示的可能是圖像中的物體屬于哪個類別,或者圖像所描繪的場景屬于哪個類別,而這里的pairwise label則是基于一對圖像定義的,指示的是這一對圖像是否相似(通常可以根據這一對圖像是否屬于同一類別定義它們是否相似)。具體來說,對于一個數據庫中的第i,j兩幅圖像,sij=1代表這兩個圖像相似,sij=0代表這兩個圖像不相似。具體到這篇文章,作者使用了上圖所示的網絡結構,網絡的輸入為成對的圖像,以及相應的pairwise label。該網絡結構中包含了共享權值的兩路子網絡(這種結構被稱為Siamese Network),每路子網絡處理一對圖像中的一張。在網絡的后端,根據得到的樣本的二值編碼和pairwise label,作者設計了損失函數來指導網絡的訓練。具體來說,理想情況下,網絡前端的輸出應該是只由±1構成的二值向量,在這種情況下,兩個樣本的二值編碼向量的內積事實上是等價于Hamming距離的。基于這個事實,作者提出了如下的損失函數,希望用樣本二值編碼之間的相似性(內積)去擬合pairwise label(logistic regression):
在實際中,如果想讓網絡前端輸出為只由±1構成的二值向量,則需要在網絡中插入量化操作(如sign函數)。但是,因為量化函數在定義域上要么導數為0,要么不可導,因此在訓練網絡的時候無法使用基于梯度的算法,因此作者提出將網絡前端的輸出進行松弛,不再要求輸出是二值的,轉而通過在損失函數中增加一個正則項的方法,對網絡輸出進行約束:
其中U表示松弛后的“二值編碼”,其余定義與J1相同。
在訓練的時候,J2中的第一項可以直接根據圖像對的標簽和Ui計算得到,第二項需要對Ui進行量化得到bi后再計算。利用上述損失函數訓練好網絡后,當查詢樣本出現時,只需要將圖像通過網絡,并對最后一個全連接層的輸出進行量化,即可得到樣本的二值編碼。
本文中的部分實驗結果如下,文章提出的方法取得了state-of-the-art的性能,即使和使用了CNN特征作為輸入的一些非深度哈希方法相比,在性能上也有比較顯著的優勢:
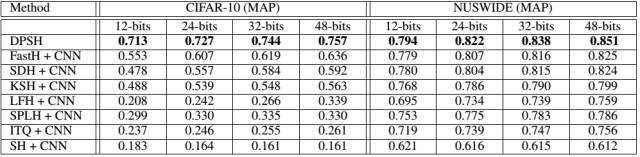
總體來說,本文提出的方法通過聯合學習圖像特征和哈希函數,在圖像檢索任務上取得了顯著的性能提升。但是由于文中使用的pairwise label在描述一對樣本的時候只有相似、不相似兩種可能,相對比較粗糙,因此不可避免地限制了本文方法的適用場合。作者在后續的工作中可能會考慮使用更加靈活的監督信息形式來擴展方法的通用性。
該文章屬于“深度學習大講堂”原創,如需要轉載,請聯系loveholicguoguo。朱鵬飛,天津大學機器學習與數據挖掘實驗室副教授,碩士生導師。分別于2009和2011年在哈爾濱工業大學能源科學與工程學院獲得學士和碩士學位,2015年于香港理工大學電子計算學系獲得博士學位。目前,在機器學習與計算機視覺國際頂級會議和期刊上發表論文20余篇,包括AAAI、IJCAI、ICCV、ECCV以及IEEE Transactions on Information Forensics and Security等。