http://www.guokr.com/article/436974/
編輯的話:2013年“韓國(guó)小姐”選美大賽開(kāi)始之后,最先曝光出的20位佳麗面容之酷似,讓人們驚嘆不已。我們?cè)邳S嘉斌的個(gè)人博客上看到了這篇有趣的 分析文章(英文)。在得到翻譯授權(quán)后,死理性派將本文編譯發(fā)布,以饗讀者。
(原作者/黃嘉斌 譯/小行蹤)前一陣,一張集合了20 位“韓國(guó)小姐”選美大賽大邱區(qū)選手的GIF圖(見(jiàn)下)廣為流傳,世人紛紛震驚于韓國(guó)整容技術(shù)的高度一致性。有網(wǎng)友稱“韓國(guó)整容界的混亂終于在這一張臉上體現(xiàn)出來(lái)了”。那么,這20位韓國(guó)小姐的臉到底有多相似?讓我們用科學(xué)的方法來(lái)揭開(kāi)謎底。

首先,放出20位佳麗集合圖,并對(duì)她們進(jìn)行編號(hào)(第一列從上往下依次為1-4號(hào),第二列為5-8號(hào),以此類推)。
通過(guò)簡(jiǎn)單的計(jì)算攝影學(xué)方法,可以將20張圖片的特征集合到一張圖片上,得出這20位佳麗的“平均臉”。結(jié)果如下:

然后,通過(guò)一個(gè)視頻來(lái)觀察一下這20張臉的漸變情況,看看每張圖片之間的變化幅度。
到目前為止,只能借助上面這些可視化對(duì)象進(jìn)行定性分析,通過(guò)主觀評(píng)價(jià)得出結(jié)論(結(jié)論是像呢還是像呢還是像呢?)。接下來(lái),還需要進(jìn)行定量分析。
第一步,要構(gòu)建這些選手面部的“特征空間”。不過(guò),由于選手在拍照時(shí)的姿勢(shì)差異和不同的發(fā)型干擾,我們不能用標(biāo)準(zhǔn)的“主成分分析法”(Principle Component Analysis,簡(jiǎn)稱PCA)構(gòu)建特征空間。因此,需要用一種魯棒性更強(qiáng)的PCA,來(lái)進(jìn)行臉部圖像的低秩部分(low rank part)分解和稀疏誤差(sparse errors)分解,如下圖中的三個(gè)例子所示:

第二步,通過(guò)奇異值分解法(singular value decomposition),可以得到這 20 張臉的“特征臉”以及對(duì)應(yīng)的特征值,從下面這張曲線圖中可以看到,沒(méi)有特征臉的特征值大于等于 7,因此這些圖像數(shù)據(jù)的秩為 6。
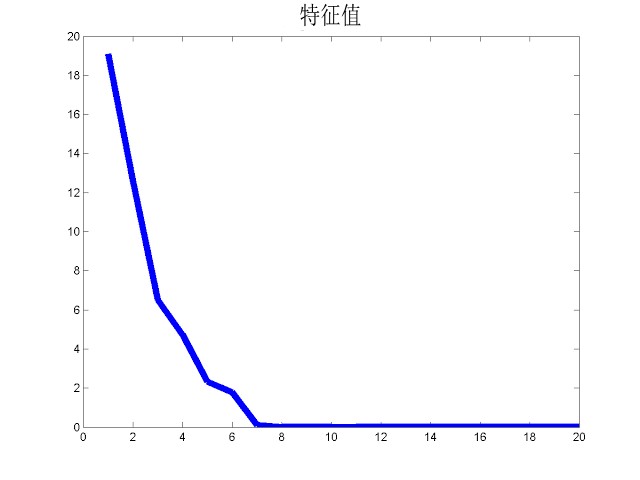
將 6 張?zhí)卣髂槇D像化如下,其中包含了20張臉部圖像的主要變化。

第三步,將每張臉投影到特征臉上,分析出這些臉部圖像在特征空間中是怎樣分布的。下圖是 20 張臉的特征系數(shù)曲線,可以看到,大部分特征差異都集中在前兩個(gè)特征值上。

再將每張臉對(duì)應(yīng)前兩個(gè)特征值的系數(shù)繪制成圖,就可以看出這 20 位選手的外貌特征有多相似(分布越近的點(diǎn)代表相似程度越高)。

第四步,通過(guò)兩兩對(duì)比來(lái)比較這些參賽選手互相之間的外貌相似程度。下圖中,方塊顏色越藍(lán)表示兩者越相似,越紅表示越不相似。
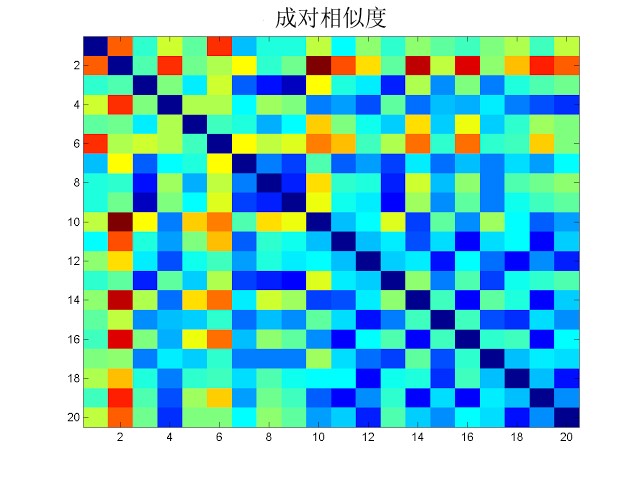
通過(guò)對(duì)上圖的統(tǒng)計(jì),可以得出下面這張橫向?qū)Ρ葓D,橫軸代表選手編號(hào),縱軸代表差異程度高低。

最后,我們可以看到,這20位“韓國(guó)小姐”參賽選手之中,與“平均臉”最接近,也就是與其他人長(zhǎng)得最像的三位分別是7號(hào)、12號(hào)和15號(hào)選手。

而與其他人外貌相似程度最低的三位分別是 1 號(hào)、2 號(hào)和 6 號(hào)選手。恭喜她們!

5月3日,“韓國(guó)小姐”大邱賽區(qū)的大眾投票結(jié)果出爐。前五名分別是5號(hào)、 1號(hào)、 15號(hào)、20號(hào)與19號(hào)佳麗。其中位列二三名的1號(hào)與15號(hào)佳麗分別在“最相似”與“最不相似”三人組中。這似乎與那個(gè)著名的觀點(diǎn)“大眾臉很吸引人,但最吸引人的卻不是大眾臉”有所巧合。

當(dāng)我們?cè)谇皟蓚€(gè)特征值系數(shù)圖中找到前五名佳麗(紅點(diǎn)標(biāo)記),可以發(fā)現(xiàn),大眾在投票過(guò)程中似乎避開(kāi)了選擇互相之間外貌非常近似的佳麗。

友情提醒:整容結(jié)果可能跟你的預(yù)期不一樣,進(jìn)行韓式整容需謹(jǐn)慎哦。