BLENDER架構
原文:http://www.blender.org/development/architecture/
此文并非嚴格的學術翻譯,有錯誤的地方請指出,一些非技術性的東西可能被刪節(jié)了。交流學習聯系方式:
Kuafu:augustus4400(at)gmail(dot)com
Blog:http://www.shnenglu.com/flyindark/
簡介
在過去的8年Blender的代碼庫一直在發(fā)生變化,并且擴大了很多。(刪除了本段后續(xù)部分)
在這份文檔中我將目標集中在回顧當初原始的設計理念上,例如這一部分是如何實現的,或這部分實現對應代碼樹里哪一處。既然下面即將介紹的原始設計理念可以很好的工作到現在,那么這個信息對當前所有的開發(fā)工作都會有益處。
本文檔的第二個目的是提供Hooks,以方便我們可以更深入的使用'模塊化的BLENDER。
BLENDER的設計的好壞是另外一個話題!特別是(角色)動畫系統的知識沒有出現在最初的設計階段,這也是為什么Armatures、約束和NLA在現在仍然有問題的原因。另一個方面是當初為趕時間,游戲引擎和邏輯編輯在后來才加入,這些地方與BLEDER也沒有很完美的協調工作。
雖然這兩個方面都可以在當前的設計中進行改進,但我們最好還是承認BLENDER存在一些短處。在現在這個框架上改進功能和優(yōu)化結構仍然是可能的,其中最有可能的是最終的代碼可以集中在完全重構的Blender3的框架和模塊化中完成改進。同樣這也是另外一個話題。讓我們先試圖將這個瘋狂的野獸控制住.:)
所見即所想;所做即所得
Blender最初是在動畫工作室中開發(fā)的,符合它自己的用戶所需求,作為一個商業(yè)軟件按照工作進度和截止日期完成開發(fā)。(意譯)
它有一個嚴格的面向數據的設計方式,幾乎像一個數據庫,但也有一些面向對象的思想。它完全由純C編寫。為了設計Blender,有一種嘗試是建立一個盡可能統一的數據結構,來實現3D展現的所有可能性和所有通用的工具。
這個結構是為了讓用戶和程序員能夠迅速和靈活,這是一個非常適合開發(fā)室內3D和動畫包的工作方式。
雖然有些戲稱Blender為'結構可視化',但是這個名字其實是相當準確的。在第一個月的Blender的開發(fā)中,我們除了設計框架和編寫包含文件確實做的不多。在隨后的幾年里,主要的工具和可視化的方法逐步完成。
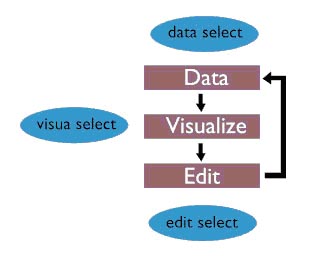
此圖描述了Blender最基本的結構。“數據---可視化---編輯”這個循環(huán)周期是它的核心,并被GUI(圖中藍色處)分隔開來,GUI在3個不同的層次工作。
Data Select
一個用戶選擇'數據'。這意味著用戶指定他希望工作的那部分三維數據庫。這是一樹狀結構的組織。Blender的基本數據系統存在于文件上,這個數據系統直接和它加載到內存中的映射是一致的。Blender數據可以包含多個'scenes',每個場景輪流的由3D Objects,materials,動畫和渲染設置組成。
Visua Select(visua or visual?)
指定的數據可以在Windows作為三維線框通過Zbuffer渲染來顯示,如按鈕或一個示意圖。Blender有一個柔性的windows系統實現這個目標,這個窗口系統允許任何非重疊和非阻塞型的窗口布局體系。
Edit Select
根據可視化的選擇,用戶可以使用很多工具。編輯操作總是直接作用于數據,而不是數據的可視化。這似乎是合乎邏輯的,但這是很多軟件的交互性和視覺方面的失敗。一方面它是一個速度問題,在三維可視化時,它需要一定的時間后用戶才看能到一個編輯命令的作用。這也是一個'反矯正的問題:用戶只是了解可視化,而不是實際描述的數據結構。這可能非常痛苦,如果你試圖做一些事情,結果最終被證明所做的與你想要的正好相反。
UI design decisions (本節(jié)未翻譯,覺得原文更好理解)
With a 3D creation suite requiring many different but conceivable methods to make the complexity available for artists, most programs ended up with providing multiple modules, separating the workflow for artists based on tasks like 'animating' or 'material editing' or 'modeling'.
Based on our experience, as an animation studio, we didn't think this was natural nor followed the actual workflow of an art project.
Following the flow diagram as mentioned above, decided was to:
1. Base the UI on a non-overlapping non-blocking subdivision window system
2. Allow each subdivided 'window' in Blender to be hooked up with any 'editor' (= vizualization method), displaying any choosen type of data.
3. Implement a uniform usage of hotkey and mouse commands, that don't change meaning within different contexts.
4. Since it's an in-house tool, speed of usage had preference over ease of learning
The implementation of the UI was first tried with existing tools (libraries), but that failed completely because of lack of speed. The choice to create an entire new window manager, and base it all on IrisGL (predecessor of OpenGL), was one of the happy coincidences that made Blender as portable and slim as still is today.
數據結構
Blender設計的大部分時間用于決定哪些類型的數據類型要定義在一起,以及如何定義數據之間的關系。在時刻記住“'實現遵循設計”的理念的前提下,任何設計決策既有效又盡可能功能約束是很好理解的。
根據我們如何需要3D來實現我們的項目,做出了數據設計的決策,實現了一個高度抽象的數據層:
- 允許多人協同工作
- 讓復雜的動畫項目建立在1個項目(或文件)的基礎上
- 允許高效的重復使用的數據
- 允許模板(或背景)
這導致設計一個非標'數據庫',不像傳統的'場景圖'(這在當時基于的概念/顯示),而是基于創(chuàng)建通用的3D的數據世界,在那里你可以創(chuàng)建你想要的足夠多的場景圖(顯示,圖像,動畫等)。
順便說一句:認識這個數據結構的概念一直是新用戶進入Blender的瓶頸:)
在Blender數據塊是用戶的積木:它們可以隨心所欲的被復制,修改和與另一塊建立鏈接。
創(chuàng)建一個鏈接實際上和指明關系是一樣的。這會導致一個塊'被使用'。這可能會產生一個塊的實例,或者得到一個特定的特征(類似C++中特化的概率?)。

For example, the block type 'Object' makes a 'Mesh' block appear in the 3d scene. The Object here determines the exact location, rotation and size of the Mesh. The Mesh then only stores information on vertex locations and faces. Also, more than one Object can have a link to the same Mesh (use, create an instance). Other block types, e.g. Materials, can be linked to Meshes to obtain the block type's features.
在Blender中每一個這樣的塊都帶有一個ID結構,其中包含塊的唯一名稱,并在某些情況下,包含一個指明該塊來自何處的庫。ID結構允許Blender的數據被一個統一的方式操縱,而不需要了解實際的數據類型。
這些ID也讓Blender來內部組織文件作為一個文件結構,仿佛它是一個包含文件的目錄的集合。
這樣的組織方式對當需要組合blender文件或將他們作為一個庫使用的情形也很重要。
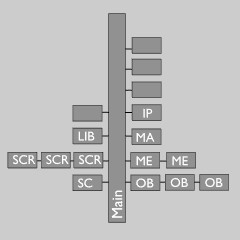
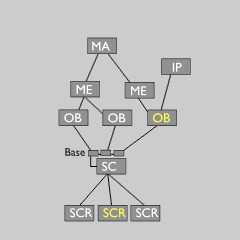
Data tree as in memory and file Scene graph
Blender中所有的數據都存儲在一個主樹上,這實際上只是一個塊的列表。這里的數據始終駐留,獨立于無論用戶如何將他們連接在一起。在圖片上面你可以看到一個'場景圖'是如何從主樹中可用的數據來構造出來的。
真實的數據仍然在主樹上,這是在場景塊(Scene block)中的進一步可視化。它內部有一個基本結構的清單,允許一個場景去連接許多對象而不從主結構中刪除他們。
(一個基礎還允許一些本地屬性,例如層和選擇集(selection),使一個對象可以被多個場景使用而且附帶這些不同的屬性。)
當使用Blender,Library blocks通常不解放自己(not freed themselves),而只是沒有被連接。他們留在主塊列表中。只有當用戶計數是零的時候,這樣的塊才不寫入文件中。
注意上圖中黃色處,這里有兩個主要的全局變量:當前屏幕(也表示活動場景)和活動對象。
數據塊類型(Data block types)
所有存儲在主樹中的塊都被稱為Library blocks(有時也稱為Libdata)。Library blocks啟始的ID結構:
1 <ccode>
2
3 typedef struct ID {
4
5 void *next, *prev; /* for inserting in lists */
6
7 struct ID *newid; /* temporal data for finding new links when copying */
8
9 struct Library *lib; /* pointer to the optional Library */
10
11 char name[24]; /* unique name, starting with 2 bytes identifier */
12
13 short us; /* amount of users of the block */
14
15 short flag; /* bitwise flags to indicate special types */
16
17 } ID;
18
19 </ccode>
20
21
讓我們來仔細看看Library blocks的其中之一,那個Mesh。當然,這樣一個塊其實是許多塊的集合,不論是在數組中還是在列表中。在這里我們存儲頂點,面,UV紋理坐標,等等(藍色圖片部分)。這些塊被稱為直接數據(Direct Data)。這些數據意味著是該網格的直接組成部分,并且總是和一個網格寫在一起或從文件中讀取回來。
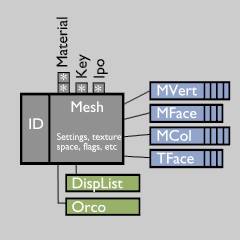
除了這些永久數據,另外還有一些臨時數據可能會被連接到這個網格,例如顯示列表,可以鏈接到網格。這些數據總是在匆忙中產生,不寫入文件,并且在從文件中讀回的時候被設置為清空。由于所有的庫和Direct Data都保留在文件中,所以將他們設計緊湊并將臨時數據分隔開來很重要。
我們現在得到了Blender設計的一個非常重要的規(guī)則:在Blender使用塊的指針的時候限于指向指向LibraryData的指針的使用。這意味在任何地方都允許使用指向對象或網格的指針(例如在一個頂點),但是指向特定定點的指針不能隨意存儲。
譯者注:不是很明確這里的“指針”的含義,暫且認為是之前ID STRUCT中的C++指針結構相關的東西。
這個規(guī)則確保了一個一致的和可預見的結構體,它可以被任何部分的Blender代碼(尤其是對于數據庫管理和文件)使用。它還明確了對一些東西是否應該成為Library Data該如何進行決定,當你想將它在Blender中到處進行交叉引用(crosslinked , re-used)時會碰到。
當文件被保存后,Direct Data總是緊隨Library Data。由于儲存的數據可以包含當他們需要讀回時的指針。這里的指針規(guī)則有助于迅速恢復所有指向Direct Data的指針,因為這些指針只在一個單一的和相對較小的情況下存在。只有指向Library Data的指針才會存儲在一個全局表中,并且所有恢復操作都會在一個調用中立即完成(lib_link_***).
(注:當給Blender加入游戲邏輯---傳感器,控制器,執(zhí)行器---最初的決策是將它作為Direct Data駐留在對象的上下文中。后來出現了對象傳感器需要在其他對象上觸發(fā)控制器,這個特性事實上因該在Library Data中完成,但是沒有這樣做。一個很丑陋的補丁就在急匆匆的就被添加到了文件讀取的代碼中。直到目前它仍然是一個有爭議的設計問題。潛在的可能是應該用消息執(zhí)行器和消息傳感器來代替。)
外部庫數據
以前的一個設計要求是能夠從其他文件中導入數據,或將作為一種動態(tài)鏈接的模板。評估當時其他3D程序(Alias,Softimage公司)時我注意到他們都使用的真實的操作系統文件系統;創(chuàng)建一個項目目錄包含一個目錄樹并在每一個目錄中包含一個數據塊對應的文件。除了它非常笨拙和復雜難于維護,我懷疑這種方式相當慢.:)
無論如何,Blender應該至少有這種做的好處。這些名為Blender數據的使用方式非常類似于文件系統的使用方式,Blender文件是一個包含所有單個文件的目錄組合。
當使用其他文件(動態(tài)鏈接的)中的數據,很明顯,只有LibraryData中的塊可以被鏈接到。Blender然后自動讀取其相關聯的Direct Data。不過,為了使從外部文件讀更有用,還需要展開其所有被連接的樹。例如,一個被鏈接的對象也將調用附加的讀取網格、材質和紋理。這種展開的數據被稱為“間接”。在接口處可以識別到一個紅色的庫圖標。當保存到一個文件,這些擴展的(間接)數據根本不會被寫入。這使得外部文件編輯器可以改變對象的鏈接,如添加一IPO或添加其他材質。
這個特性的一個典型的用法是從其他文件動態(tài)鏈接一個場景。無論如何這個場景永遠會被讀取。
當保存被連接的Library Data,僅僅它的ID組成部分被寫入文件。然后這個ID包含一個指向被使用的“庫”的指針,并且那些真正的IDs有一個統一的名字用于保證那些鏈接總是被正確的保存。
文件保存和載入
文件保存大概是通過整個主樹進行,并將所有用戶塊保存為原始二進制數據轉儲到磁盤上。每個保存的塊有一個頭(struct BHead)用于存儲附加信息,如在內存中這個塊的原始地址。
讀文件時先讀整個文件到內存中。 Blender的讀文件代碼接著遍歷所有BHeads,處理Library Data和Indirect Data,創(chuàng)建完整的副本。因此,在最后最初讀入的整個文件可以從內存中被釋放。(注:讀和寫大量的數據塊是為了防止磁盤和網絡開銷)。
寫入被動態(tài)鏈接的Library Data(Writing dynamic linked library data)
由于Blender的主樹僅僅是另外一個可以列表化的結構,它使用多個Main以能夠高效的保存和寫入被動態(tài)鏈接的數據。這是由函數split_main()完成的,它使用所有的數據創(chuàng)建主樹。
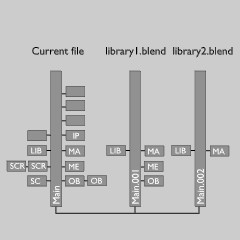
為了節(jié)省,當前的主樹可以正常處理。至于其他主樹則只保存所有IDs(例如類型ID_ID),以分隔來表示它源自哪個文件(通過保存結構庫來完成)。
然后,它調用join_main()來再一次合并所有到一個單一的主樹。
讀取被動態(tài)鏈接的庫數據(Reading dynamic linked library data)
這又有點復雜,也允許遞歸;
1.當從文件中讀取數據,Blender遇到庫結構,它創(chuàng)建一個新的主結構并記得儲存的所有后續(xù)ID_IDs到那里。這些ID得到標記LIB_READ。
2.它接著遍歷所有主樹(Main trees),檢查LIB_READ塊標記
3.如果一個LIB_READ塊發(fā)現:
3.1它檢查包含該數據的文件是否已經被讀取,如果沒有則加載這整個文件到內存中和并保存到Main。
3.2然后使用正常的讀取規(guī)則讀取塊,連接所有Direct Data到它上面。新的塊被鏈接到當前的Main tree,老的塊被清除。
3.3根據快的類型不同,它調用expand_doit()函數,它的像步驟3.2一樣讀取更多的塊,或者檢測這個塊數據是否已經被正確讀取。注:當這樣的擴展的數據再一次從另一個文件出現,它只是讀取ID部分,將它鏈接到正確的Main并且標記為LIB_READ。
4.只要LIB_READ標記的塊被發(fā)現,則返回到步驟2。
5.只有在最后,它才加入到Main,并恢復所有正確的Library Data的指針。
你可以想像得到,這個系統需要相當多的指針技巧,其中指針必須映射到新的指針,然后再一次映射到新的指針,只有用正確的結束方式將真實的數據分配完成才算數。
Struct-DNA (SDNA結構)
隨著選擇了將文件保存為二進制格式,并了解到Blender的結構總是在變化和擴展,我當初想設計一個系統,可以兼顧到所有的低版本變更。這就是Blender DNA在圖片得到的。
簡單來說,SDNA是一打包并用二進制預處理過的Blender包含文件的一個版本,其中包含可以保存到文件的數據。De SDNA系統然后可以得到結構的內容本身,包括它的大小,元素類型和名稱。
每個編譯的Blender都有類似的SDNA被編譯在其中,并在每個保存的.blennd文件中這個SDNA塊都被加進來。另外,對于每一個文件的BHead它保存了一個索引數字表示了結構類型。
當檢測和解析到變化時所有這一切都被允許。例如像一個short到int的轉換,一個char到float的轉換,或一個數組的元素變得越來越少或越來越多。新的變量總是很好的被清零,并且被刪除的變量只是簡單的被跳過。在移植到little endian系統(Blender誕生的時候使用big endian)的時候可以很好的進行自動轉換。即使移植到到64位系統(DEC Alpha)也成功的使用SDNA完成了。
此外,它允許向后和向上兼容性。從Blender 1997任何可以很好的讀取2004版的文件,反之亦然。
主要的限制是碰到要求對一個真實的版本進行改動。例如添加一個新的變量,它需要初始化一個特定的指。或者更糟的是,當一些變量的意義發(fā)生了變化(例如像物理屬性)。
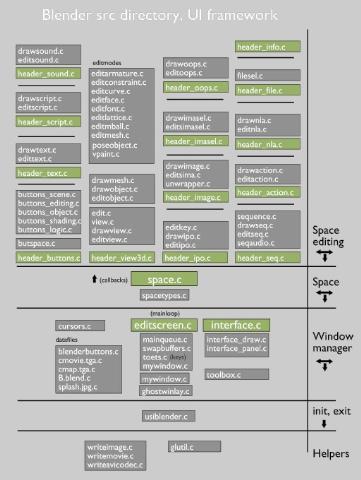
源代碼的布局(Source code layout)
當前源代碼的布局仍然是一個正在進行的工作的一瞥。一些依賴庫已經明確的定了下來,其他仍然只是簡短的決定。
在下圖中你會發(fā)現文檔中提及的目錄
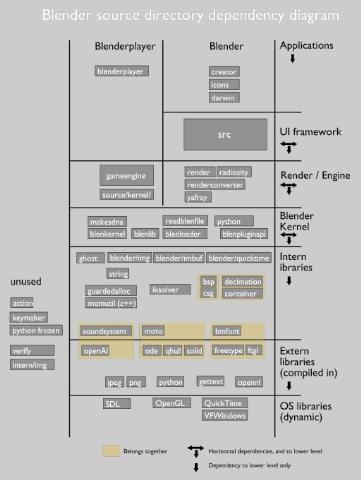
Blender UI framework
在” source/blender/src/”目錄中你可以找到所Blender中所有用戶界面和工具相關的代碼,這個結構非常清晰,也可以反映到一個更好的目錄結構上。