首先我們得明確3D引擎使用多線程的目的所在:
1、在CPU上進行的邏輯計算(比如骨骼動畫粒子發射等)不影響渲染速度
2、較差的GPU渲染速度的低下不影響邏輯速度
第一個目標已經很明確了,我來解釋下需要達到第二個目標的原因:許多動作游戲的邏輯判定是基于幀的,所以在渲染較慢的情況下,邏輯不能跳幀,而仍然需要嚴格執行才能保證游戲邏輯的正確性,這就導致了游戲速度的放慢,而實際上個人認為渲染保持15幀以上就已經可以正常進行游戲了。
在較差的GPU上跑《鬼泣4》《刺客信條》《波斯王子4》簡直就像是慢鏡頭一樣,完全沒法玩。而實際上CPU跑滿幀是沒有問題的,如果能把邏輯幀和渲染幀徹底分離,即使渲染幀達不到要求,但CPU仍能正確的執行游戲邏輯,就可以解決動作游戲對GPU要求過高的問題。
我們先來看多線程Ogre的兩種架構,第一種是middle-level multithread
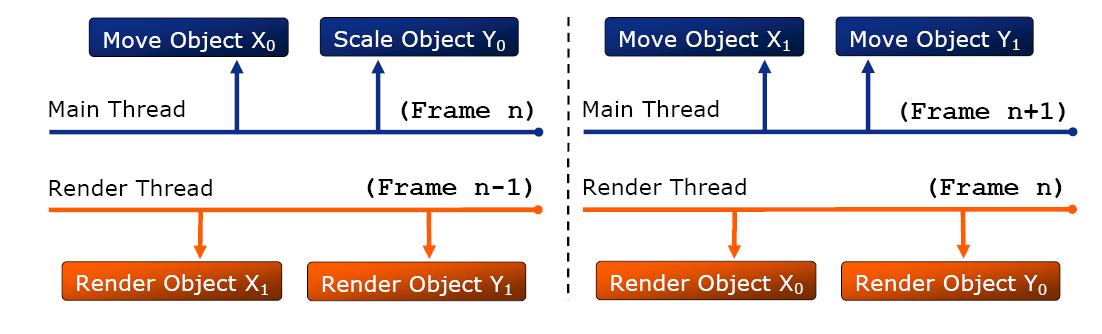
如上圖所示,每個需渲染的實體被復制成了兩份,主線程和渲染線程交替更新和渲染同一個實體的兩個備份,并在一幀結束時同步,這種解決方案達到了第一個目標而并沒有達到第二個目標,同時兩份實體的維護也相對復雜,并且沒法為更多核數的CPU進行擴展優化。
第二種Ogre多線程的方法是 low-level multithread
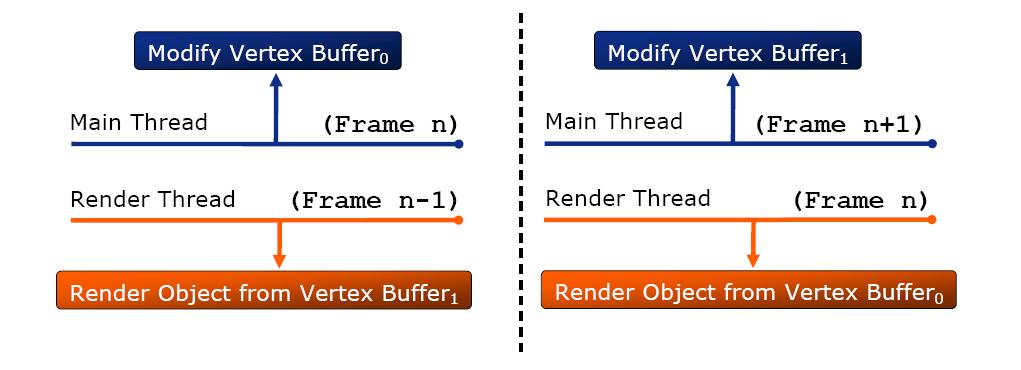
如圖,將D3D對象復制兩份,同樣是在幀結束時同步并交換,和上面的優缺點類似。兩種多線程Ogre的解決方案都是在引擎層完成的,對上層應用透明,對于用戶而言無需考慮多線程細節,這點是非常不錯的。
接下來我們來看SIGGRAPH2008上,id soft提出的多線程3D引擎的方案
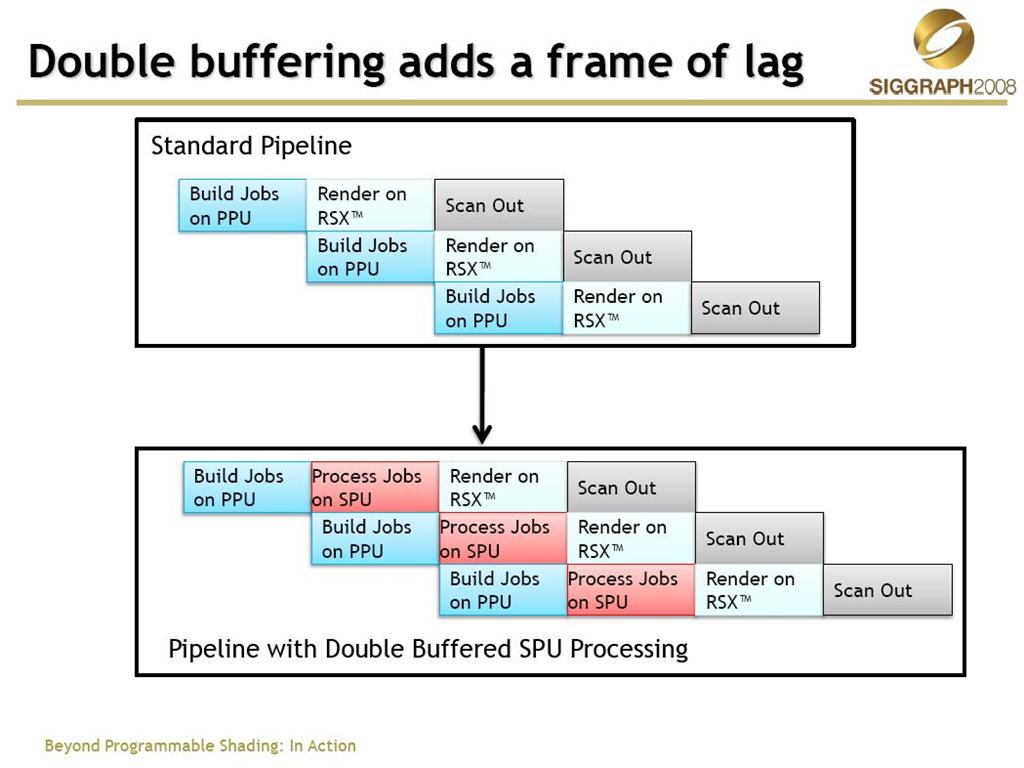
這里是已PS3的引擎結構為例的,與PC有較大的差別,其中SPU是Cell芯片的8個協處理器,擁有強大的并行能力,id的解決方案在SPU上進行了諸如骨骼動畫、形變動畫、頂點和索引緩存的壓縮、Progressive Mesh的計算等諸多內容,同時與PPU上的物理計算RSX上的渲染工作交錯進行,最大化的利用了PS3的硬件結構,最終的游戲產品《Rage》很快就會面世了!
最后是我的解決方案
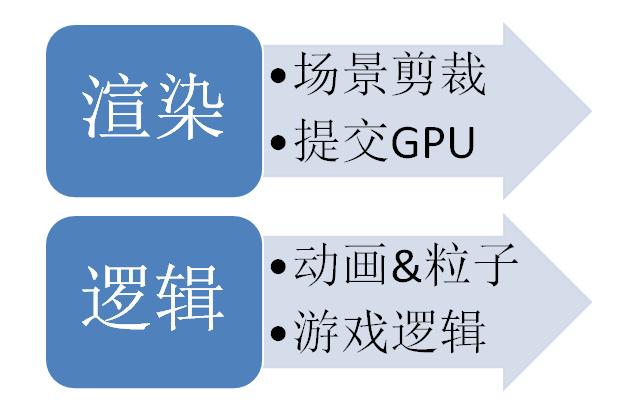
特點是邏輯完全分離,無需同步,雖然成功的達到了文章開始提出的兩個目標,但對于引擎的使用者必須考慮多線程的諸多問題,各種計算需放在哪個線程,如何在兩個線程間交互,都需要深入思考,所以要應用到實際的游戲制作,恐怕還有很長的一段路要走。
結合目前的架構和上面看到的幾種多線程架構,同時也為了迎接DX11的到來,我準備將我的方案進一步改進成如下所示
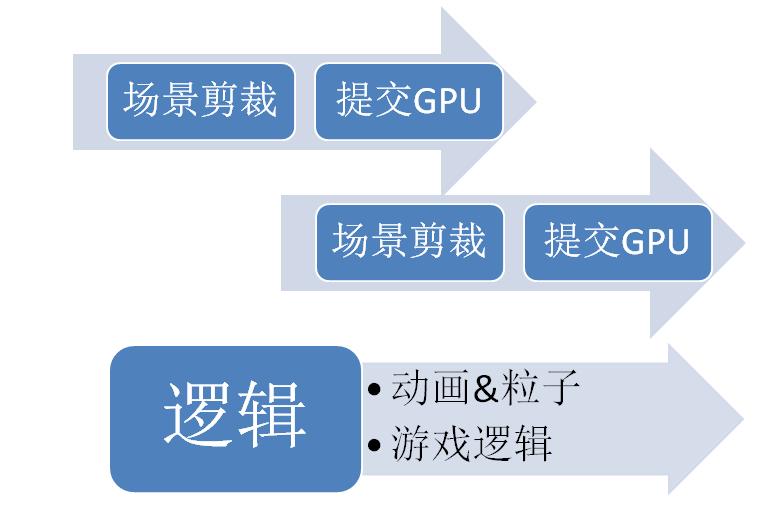
場景剪裁與提交渲染交替進行,并在渲染幀末進行一次同步,而多個渲染表面的場景剪裁可再并行執行。
圖片多,文字少,需更詳細資料請自行google,本文就此結束!