一.XXX
1)概念說明
這里不再具體描述內(nèi)存池的概念和作用,需要了解請(qǐng)看http://baike.baidu.com/view/2659852.htm?fr=ala0_1_1。
2)描述
在開發(fā)一個(gè)長(zhǎng)時(shí)間運(yùn)行的服務(wù)器程序時(shí),一般頻繁的向操作系統(tǒng)動(dòng)態(tài)申請(qǐng)內(nèi)存,而采用堆new分配,速度較慢,而且如果一個(gè)程序頻繁的申請(qǐng)小內(nèi)存塊,很容易產(chǎn)生內(nèi)存碎片,每次查找相對(duì)較慢。
因?yàn)槎咽窍蚋叩刂窋U(kuò)展的數(shù)據(jù)結(jié)構(gòu),每次內(nèi)存分配其實(shí)都是進(jìn)行虛擬內(nèi)存分配,都會(huì)建立虛擬內(nèi)存的到物理內(nèi)存的映射,而是分配的一種不連續(xù)的內(nèi)存區(qū)域,由于系統(tǒng)是用鏈表來存儲(chǔ)的空閑內(nèi)存地址的,而鏈表的遍歷方向是由低地址向高地址。
這里還有一篇關(guān)于關(guān)于頻繁的內(nèi)存分配性能分析 ,圖文并茂的講得很詳細(xì)。
3)實(shí)現(xiàn)目標(biāo).
而設(shè)計(jì)內(nèi)存池的目的是為了保證一個(gè)程序長(zhǎng)時(shí)間高效的運(yùn)行,而該程序?qū)?nèi)存申請(qǐng)頻繁,為了減少系統(tǒng)內(nèi)存碎片的產(chǎn)生,合理分配管理用戶內(nèi)存,從而減少系統(tǒng)中出現(xiàn)有效空間足夠,而無法分配大塊連續(xù)內(nèi)存的情況。
關(guān)于實(shí)現(xiàn)一個(gè)高效與穩(wěn)定內(nèi)存池模塊有如下目標(biāo):
A.如何實(shí)現(xiàn)內(nèi)存的快速分配
B.如何實(shí)現(xiàn)內(nèi)存的快速釋放
C.如何管理內(nèi)存池的穩(wěn)定與效率.
注:本文介紹的內(nèi)存池管理效率相對(duì)較高,且可以針對(duì)任意大小內(nèi)存分配....
二.設(shè)計(jì)
設(shè)計(jì)前我們假設(shè)內(nèi)存申請(qǐng)很頻繁,而且申請(qǐng)小于在5120byte的遠(yuǎn)遠(yuǎn)大于5120byte字節(jié)。
為了讓設(shè)計(jì)的內(nèi)存池的使用更具有通用型和高效性,這里大致介紹通過需求不同指定一種基于內(nèi)存需求策略的方式設(shè)計(jì)出一種內(nèi)存池。
及小于5120字節(jié)的采用小塊內(nèi)存分配,大于5120的通過操作系統(tǒng)分配,內(nèi)存池管理.
此內(nèi)存池包括2中分配方式,介紹分配如下:
1) 個(gè)數(shù)固定的不定長(zhǎng)的靜態(tài)內(nèi)存分配(BlockPool)。
A.設(shè)計(jì)思路
這種主要是根據(jù)程序中不同對(duì)象的大小而指定的一種策略,對(duì)于每一種大小又是通過一個(gè)鏈表鏈表管理,每個(gè)鏈表的節(jié)點(diǎn)的內(nèi)存大小不同,而為了方便內(nèi)存的管理,一般在程序初始化的時(shí)候針對(duì)不同的策略大小分配一塊內(nèi)存塊,然后把此內(nèi)存塊劃分為多個(gè)節(jié)點(diǎn)保存到鏈表中,每一個(gè)鏈表中保存的將是空閑的節(jié)點(diǎn)。
B.基本數(shù)據(jù)結(jié)構(gòu)
 基本數(shù)據(jù)結(jié)構(gòu):
基本數(shù)據(jù)結(jié)構(gòu):

 /**//// 指定的策略 enum eBuff_Type
/**//// 指定的策略 enum eBuff_Type
 {
{
 eBT_32 =0,
eBT_32 =0,
eBT_64,
eBT_128,
eBT_256,
eBT_512,
eBT_1024,
eBT_2048,
eBT_5120,
eBT_END,
 };
}; /// 定一個(gè)雙向鏈表的節(jié)點(diǎn)2個(gè)指針
/**////
/// file BaseNode.h
/// brief 一個(gè)雙向鏈表需要的前后指針節(jié)點(diǎn)
///
#pragma once
template < typename T >
class CNode
{
typedef T Node;
public:
Node* next;
Node* prev;
CNode()

 {
{
next = prev = NULL;
 }
}
};
/**//// 節(jié)點(diǎn)struct Buffer: CNode<Buffer>
{
eBuff_Type type;
};
/// 不同大小的數(shù)據(jù)節(jié)點(diǎn).
struct Buffer32 : Buffer { char buf[32]; };
struct Buffer64 : Buffer { char buf[64]; };
struct Buffer128 : Buffer { char buf[128]; };
struct Buffer256 : Buffer { char buf[256]; };
struct Buffer512 : Buffer { char buf[512]; };
struct Buffer1024: Buffer { char buf[1024]; };
struct Buffer2048: Buffer { char buf[2048]; };
struct Buffer5120: Buffer { char buf[5120]; };
/**////TlinkedList為一個(gè)鏈表
///這里包括eBT_END數(shù)組TlinkedList<Buffer> m_MemPool[eBT_END];
m_MemPool主要結(jié)構(gòu)圖如下:
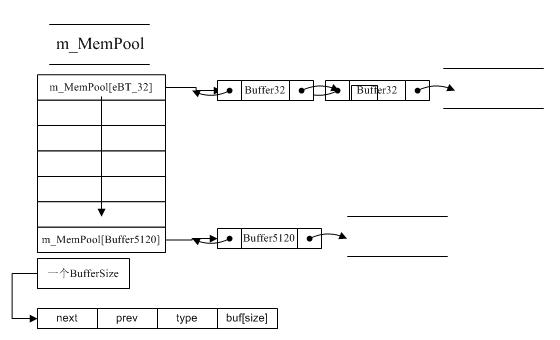
C.性能分析
分配
這里策略只是針對(duì)小于eBT_5120Byte的內(nèi)存進(jìn)行分配,根據(jù)傳入的大小直接Hash利用m_MemPool[idx]返回鏈表頭,返回Buffer節(jié)點(diǎn)的buf數(shù)據(jù)塊。
釋放:根據(jù)傳入要釋放的Mem內(nèi)存地址
/**//// 獲得偏移地址Buffer* buf = (Buffer_Face*)( (char*)Mem - offsetof(Buffer_Face,buf) );
通過偏移地址即可獲得buf的地址,buf里面包括type獲得m_MemPool的索引,然后把釋放的節(jié)點(diǎn)重新Push到m_MemPool[type]中。
性能: 插入,分配都是0(1)
2) 完全動(dòng)態(tài)分配內(nèi)存(HeapPool)。
介紹了上面的靜態(tài)內(nèi)存分配,其實(shí)是在利用已經(jīng)分配好了的內(nèi)存塊里面在進(jìn)行查找,釋放也是直接根據(jù)傳入的直接直接保存到緩存表中。
A.介紹下需要的基本數(shù)據(jù)結(jié)構(gòu)
struct listNode : CNode<listNode>
{
long size;
/**//// 指向的內(nèi)存
char* ptr;
};
struct HeapNode
{
/**//// memory request rate
__int64 m_Count;
/**//// all free memory list
TlinkedList<listNode> m_FreeList;
/**//// using memory list
TlinkedList<listNode> m_Used;
HeapNode( )
{
m_Count = 0 ;
m_FreeList.ReleaseList();
m_Used.ReleaseList();
}
};
typedef std::map<unsigned long,HeapNode* > MHEAPLIST; /// 其中map的key是分配的大小。
HeapNode的結(jié)構(gòu)圖如下:
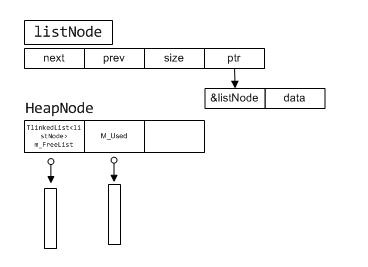
B.設(shè)計(jì)思路
根據(jù)策略程序一般大于5120Byte字節(jié)的相對(duì)比較少,而程序請(qǐng)求大小也是相對(duì)比較規(guī)則,散列不是太大。
HeapNode有2個(gè)鏈表m_FreeList和m_Used,其中鏈表的節(jié)點(diǎn)如圖ListNode所示
listNode有一個(gè)ptr表示需要配的內(nèi)存,ptr指向的前8個(gè)地址為listnode的地址值(根據(jù)Cpu的最大尋址為64位),ptr+8則是分配的內(nèi)存地址,為什么這么設(shè)計(jì)呢?
我是這樣想的外界使用內(nèi)存空間為data區(qū)域,那么我們釋放的時(shí)候的只是需要傳入data的地址,即可通過求出listnode的地址,
/**//// 根據(jù)MemAddr的地址求listnode地址__int64 pAddr = *(__int64*)((char*)MemAddr-8);
listNode* pNode = (listNode*)pAddr;
得到listNode地址后即可進(jìn)行找到對(duì)應(yīng)的HeapNode,然后進(jìn)行釋放或者放入緩存列表的操作。
關(guān)于HeapNode的管理,為了節(jié)約內(nèi)存我們不可能一直申請(qǐng)內(nèi)存而不釋放,所以我們約定m_FreeList只是保存m_Used中一半大小的結(jié)點(diǎn)。當(dāng)m_FreeList過多的節(jié)點(diǎn)時(shí)需要釋放一定空間。(這個(gè)約定可以根據(jù)不同的需求而制定).
上面介紹了為什么如此的設(shè)計(jì)這個(gè)數(shù)據(jù)結(jié)構(gòu),下面介紹分配策略。分配的時(shí)候先查找是否有緩存數(shù)據(jù),沒有則分配一個(gè),否則直接返回m_FreeList的一個(gè)listNode(結(jié)點(diǎn))的ptr+8;
C.性能分析
通過上面描述可以確定基于完全動(dòng)態(tài)分配的效率
分配的時(shí)候 lg(n);
釋放的時(shí)候 lg(n);
而map的查找基于AVL樹,所以查找基本是常量型的。
三.實(shí)現(xiàn)
上面只是介紹了分配方式,下面介紹實(shí)現(xiàn)。
通過上面描述可知,對(duì)于大于5120byte的內(nèi)存分配采用HeapPool分配,否則采用BlockPool分配。
為了方便外界使用我們使用一個(gè)CMemFactory內(nèi)存分配工廠,通過使用者申請(qǐng)Size和釋放pAddr即可快速進(jìn)行分配和釋放。
代碼如下:
http://code.google.com/p/tpgame/source/browse/#svn/trunk/MemPool/MemPool
具體代碼打包如下:
/Files/expter/Pool.rar
注:如需了解跟多的內(nèi)存池是實(shí)現(xiàn)可以閱讀STL SGI, Loki, Boost內(nèi)存池的實(shí)現(xiàn)...
附帶最新內(nèi)存池,實(shí)現(xiàn)和介紹...
http://www.shnenglu.com/expter/archive/2011/01/18/138787.html