開始正式的研究key-value形式的持久化存儲方案了,第一個閱讀的項目是tokyo cabinet,版本號是1.4.19.
tokyo cabinet支持幾種數據庫形式,包括hash數據庫,B+樹數據庫,fix-length數據庫,table數據庫。目前我僅看了第一種hash數據庫的實現。之所以選擇這個,是因為第一這種類型的數據庫似乎是TC中使用的最多的一種,其次它的算法比之B+樹又更簡單一些而效率上的表現也絲毫不差。
看看TC中代碼的組織。關于上面幾個分類的數據庫實現,實際上在TC項目的代碼組織中各自以單個文件的形式出現,比如hash數據庫的代碼全都集中在 tchdb.c/h中,也只不過4000多行罷了。除去這幾種數據庫的實現文件,其余的代碼文件功能可以大體上分為兩類,一類是輔助性質的代碼,給項目中各個部分使用上的,另一部分就是單獨的管理數據庫的CLI程序的代碼,比如tchmgr.c/h就是用于管理HASH數據庫的CLI程序的代碼。之所以要交代一下項目中代碼的組織,無非是為了說明,其實如果將問題集中在HASH數據庫或者其他形式的數據庫實現上,起碼在TC中,所要關注的代碼是不多的。
首先來看數據庫文件是如何組織的。
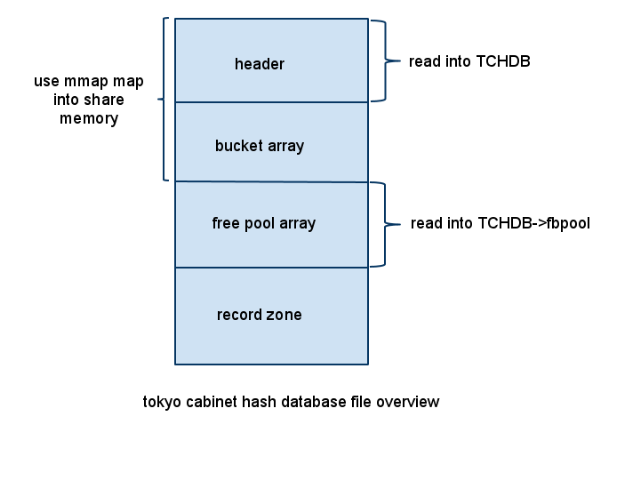
從圖中可以看到,hash數據庫文件大致分為四個部分:數據庫文件頭,bucket 數組,free pool數組,最后的是真正存放record的部分。下面對這幾部分做一個說明。
1)數據庫文件頭
數據庫文件頭部分存放的是關于該數據庫的一些總體信息,包括這些內容:
| name |
offset |
length |
feature |
| magic number |
0 |
32 |
identification of the database. Begins with "ToKyO CaBiNeT" |
| database type |
32 |
1 |
hash (0x01) / B+ tree (0x02) / fixed-length (0x03) / table (0x04) |
| additional flags |
33 |
1 |
logical union of open (1<<0) and fatal (1<<1) |
| alignment power |
34 |
1 |
the alignment size, by power of 2 |
| free block pool power |
35 |
1 |
the number of elements in the free block pool, by power of 2 |
| options |
36 |
1 |
logical union of large (1<<0), Deflate (1<<1), BZIP2 (1<<2), TCBS (1<<3), extra codec (1<<4) |
| bucket number |
40 |
8 |
the number of elements of the bucket array |
| record number |
48 |
8 |
the number of records in the database |
| file size |
56 |
8 |
the file size of the database |
| first record |
64 |
8 |
the offset of the first record |
| opaque region |
128 |
128 |
users can use this region arbitrarily |
需要說明的是,上面這個表格來自tokyocabinet的官方文檔說明,在
這里。同時,數據庫文件中需要存放數據的地方,使用的都是小端方式存放的,以下就不再就這點做說明了。從上面的表格可以看出,數據庫文件頭的尺寸為256 bytes。
在操作hash數據庫的所有API中,都會用到一個對象類型為TCHDB的指針,該結構體中存放的信息就包括了所有數據庫文件頭的內容,所以每次在打開或者創建一個hash數據庫的時候,都會將數據庫文件頭信息讀入到這個指針中(函數tchdbloadmeta)。
2)bucket 數組
bucket array中的每個元素都是一個整數,按照使用的是32位還是64位系統,存放的也就是32位或者64位的整數。這個數組存放的這個整數值,就是每次對 key 進行hash之后得到的hash值所對應的第一個元素在數據庫文件中的偏移量。
3)free pool數組
free pool數組中的每個元素定義結構體如下:
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;
很明顯,僅有兩個成員,一個存放的是在數據庫文件中的偏移量,一個則是該free block的尺寸。free pool數組用于保存那些被刪除的記錄信息,以便于回收利用這些數據區,后續會針對free pool相關的操作,API做一個詳細的分析。
4)record數據區
每個record數據區的結構如下表:
| name |
offset |
length |
feature |
| magic number |
0 |
1 |
identification of record block. always 0xC8 |
| hash value |
1 |
1 |
the hash value to decide the path of the hash chain |
| left chain |
2 |
4 |
the alignment quotient of the destination of the left chain |
| right chain |
6 |
4 |
the alignment quotient of the destination of the right chain |
| padding size |
10 |
2 |
the size of the padding |
| key size |
12 |
vary |
the size of the key |
| value size |
vary |
vary |
the size of the value |
| key |
vary |
vary |
the data of the key |
| value |
vary |
vary |
the data of the value |
| padding |
vary |
vary |
useless data |
當然,上面這個結構只是該record被使用時的結構圖,當某一項record被刪除時,它的結構就變為:
| name |
offset |
length |
feature |
| magic number |
0 |
1 |
identification of record block. always 0xB0 |
| block size |
1 |
4 |
size of the block |
對比兩種情況,首先是最開始的magic number是不同的,當magic number是0XB0也就是該record是已經被刪除的free record時,那么緊跟著的4個字節存放的就是這個free record的尺寸,而record后面的部分可以忽略不計了。
分析完了hash數據庫文件的幾個組成部分,從最開始的數據庫文件示意圖中還看到,從文件頭到bucket array這一部分將通過mmap映射到系統的共享內存中,當然,可以映射的內容可能不止到這里,但是,數據庫文件頭+bucket array這兩部分是一定要映射到共享內存中的,也就是說,hash數據庫中映射到共享內存中的內容上限沒有限制,但是下限是文件頭+bucket array部分。
同時,free pool也會通過malloc分配一個堆上的內存,存放到TCHDB的fbpool指針中。
這幾部分(除了record zone),通過不同的方式都分別的讀取到內存中,目的就是為了加快查找的速度,后面會詳細的進行說明。