大家都知道,對于A*算法,圍繞著開放列表的操作是很多的,開始的時候需要把當前處理點的周圍8個點里,除了障礙點,已在開放列表里和關閉列表的點以外的其他點,計算G,F值以后都放進開放列表里,如果已經在開啟列表里的,還得對它進行一次G值的重檢測,從開放列表里每次要找出新的F值最低的點作為當前要處理的點,并且要把他從開放列表里面刪除,所以,對于開放列表的操作的速度,是影響A*尋路速度的第一個關卡
最簡單的一種做法,也是我一開始所使用的方法,剛開始的點按照訪問順序逐一push_back進代表開放列表的vector中,(我所用的開放列表用vector來擔當),在取最小值的時候,使用一個簡單的算法找出開放列表中具有最小F值的那一個元素,然后把這個元素做為當前處理的點,并從開放列表里刪除,進入關閉列表,
int AStarBase::FindMinFValue() //在開放列表中尋找F值最小的(返回的是下標值),并且從開放列表里面刪除
{
if ( _openPoint.empty())
{
return -1;
}
else
{
int id = 0;
int minIndex = _openPoint[0]->index ;
int theMinF = _openPoint[0]->F; //以第一個點的F值做為參考值
for (size_t i = 0;i< _openPoint.size();i++)
{
if (theMinF > _openPoint[i]->F) //如果找到比他更小的F值,則把新的F值做為當前參考值
{
id = i;
minIndex = _openPoint[i]->index;
theMinF = _openPoint[i]->F;
}
}
_openPoint.erase(_openPoint.begin() + id); //刪除所找到的元素
return minIndex;
}
}
這真的是最容易實現的方法了,他唯一的一點好處是由于開放列表里的所有元素一直都是無序的狀態,所以在后期出現開放列表里某個元素的G值被改變的時候,開放列表不需要重新排序,但是他的執行速度呢?大家可以看一下我的第一篇A*隨筆里所貼的圖片,從POINT(2,2)點尋路到POINT(398,398)的位置,下標元素從802開始尋找到159598,這么多個點,消耗在開放列表尋值的時間是多少呢?
正好,我們的Visual studio給我們提供了一個程序性能分析工具,可以具體的分析出程序中每一個函數的調用情況,我們可以用他大概的查看一下我們的這個函數的執行情況
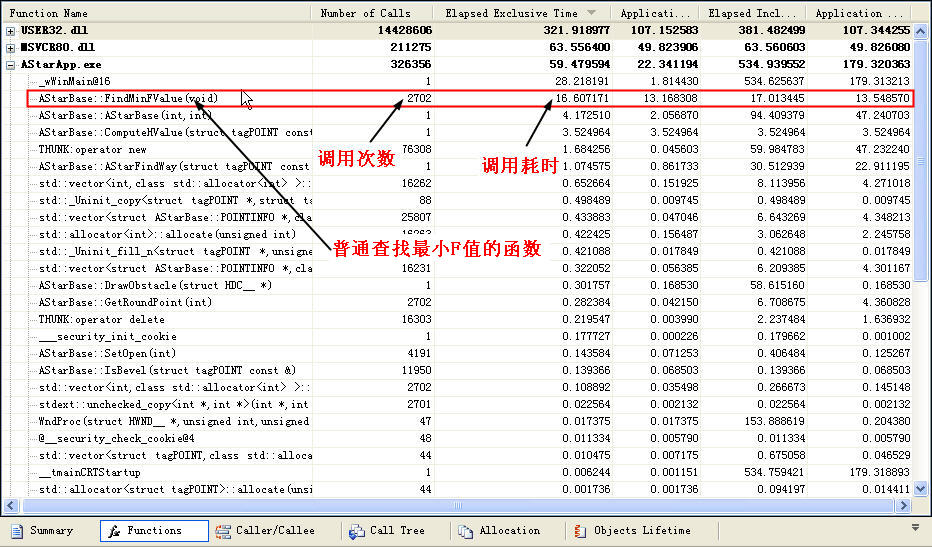
上圖中的可看出,整個尋路過程中,花費在每次找出最小值FindMinFValue()這個函數的總時間為16.60毫秒。恩,這個貌似是很快的么,不是么,才16.6豪秒而已,人類根本是察覺不出這樣的時間花費的,OK,那讓我們接著往下看吧
恩,如果不想每次都花費死工夫在無序的開放列表里面找F最小的元素,那么我們一開始在往里面放東西的時候,就讓他們排好序不就行了嗎?從小到大排序,那么每次具有最小F值的那個元素肯定在首位了,每次取他就行了。 恩,其實有現成的自動排序的STL容器可以用,但我不想用他,用自己的排序方法去維護開放列表好了。
對于排序算法,網上現成的算法有很多了,什么選擇啊,冒泡啊,快速啊,恩,我自己稍微寫了一下,用的還是一種比較死的方法,就是每次在往開放列表里放新元素的時候,找好了位置再放,保證放過以后開放列表里面的所有元素都是按F從小到大進行排列的。
void AStarBase::InsertToOpenList(POINTINFO* indexPoint) //利用插入法往開放列表里放點(F值從小到大)
{
int tmpF = indexPoint->F;
if (_openPoint.empty())
{
_openPoint.push_back(indexPoint);
return;
}
for (AStarBase::PixelContain::iterator it = _openPoint.begin();it != _openPoint.end();it++)
{
if ( (*it)->F >= tmpF) //找到比F值大的了,就插在他的前面
{
_openPoint.insert(it,indexPoint);
return;
}
}
_openPoint.push_back(indexPoint);
}
其實比他快的方法還有很多,比如先push_back,再利用快速排序對整個開放列表進行排序,但這里我這里也就簡單的寫寫了,好吧,我們看下這種方法的結果,不過很可惜,僅僅這么做得到的是錯誤的結果,
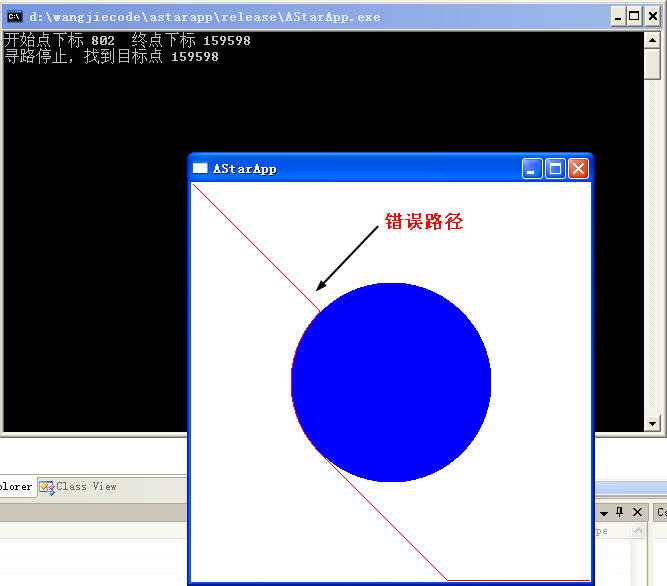
為什么說他是錯誤的呢,因為在尋路過程中少做了一步針對開放列表的重排序,因為在有一個步驟中,開放列表里的有些點的G值會經過重新計算可以得到一個更小的G值,而F值也會更小,所以這時候需要對開放列表做下重排序,重排序其實也很簡單,只要找到這個改過g值的元素在開放列表里的位置,然后把他和處于他前面的元素進行下比較,把他重新放在一個合適他的位置就可以保持開放列表的有序了,這一步我就沒有做了,我僅僅想看一下這個每次插入排序所用的時間消耗
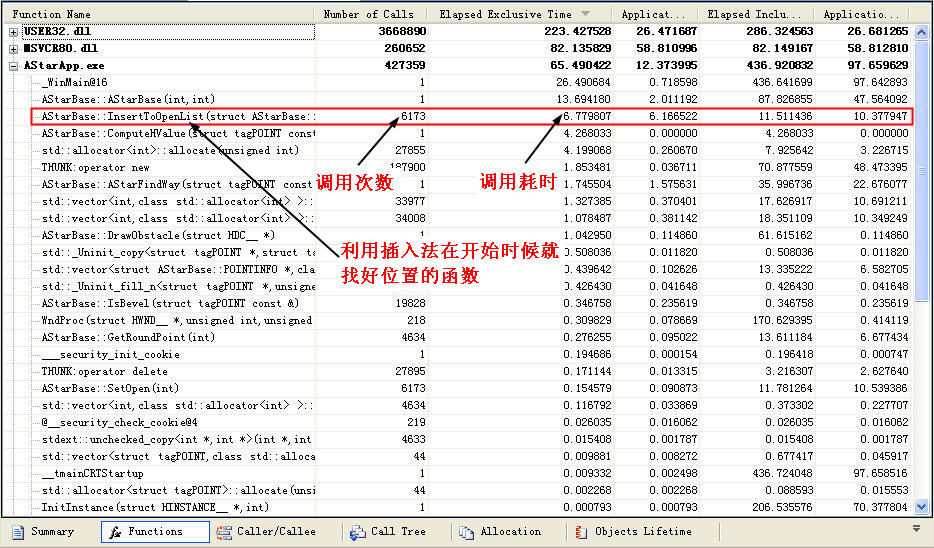
大家可以看到,這個函數總共耗時在6.7毫秒,而這個程序中并沒有處理F值改變時候的開放列表重排序問題,不過我估計,如果把這個處理函數加進去,他的消耗也不會比上面這個函數所用的時間更多,估計大概在不到5毫秒左右的時間,也就是說,針對開放列表進行排序維護的話,總時間消耗大概在12毫秒左右,如果使用一些小的技巧,一些好的常用排序算法針對排序進行優化的話,這個時間還能縮短到10毫秒以內,很不錯的不是嗎?在維護開放列哦上的效率能提高的接近50%呢。
(呵呵,這里有些偷懶,并沒有針對常用的排序方法把這里做完,只是弄了一個錯誤的東西上來估計了一下,大家莫怪,其實這些肯定是大家早已經研究過很多次的地方了,而我想談論的重點,也并不在于此)
以上只是一個A*初學者對于A*的一些想法,還請高手多多指正
如果對A*尋路基礎算法原理不清楚并且有興趣的朋友,可以去gameres上看一下這篇文章
http://data.gameres.com/message.asp?TopicID=25439
posted on 2008-03-10 15:49
火夜風舞 閱讀(1794)
評論(4) 編輯 收藏 引用