對于開放列表的維護方案來說,前面我說的,都是一些小花樣了,在一些很小的地圖上用他們并沒有什么太大的問題,但是如果地圖很大,需要搜尋的格子很多,那么開放列表里的元素必然會很多,那么我們是否可以用另外一種思維來考慮一下開放列表的維護工作?
其實我們每次從開放列表里面取值,每次只需要取里面所有元素的最小值就行了,而前面所說的兩種方案都有自己的優點,第一種不需要對開放列表做排序,但每次找起最小值來實在消耗很大,第2種在找最小值的時候只需取第一個元素就行,而麻煩在于需要一直維持開放列表里面所有元素的有序排列,那么我們是不是可以把這兩種方法的優點都結合起來呢
當然,這種方法是有的,那就是很多高級A*程序更苛求速度的一種做法,利用Binary Heap數據結構,也就是二叉堆,來維護開放列表。
其實有關二叉堆,相信了解他的高手很多,我就不再班門弄斧,,其實我也只是剛剛學習他而已,這里只簡單的介紹一下他的一些特點以及在A*中他所起到的作用。
百度百科中對二叉堆的定義:
二叉堆是一種特殊的堆,二叉堆是完全二元樹或者是近似完全二元樹。二叉堆滿足堆特性:父結點的鍵值總是大于或等于任何一個子節點的鍵值。
那么應用于A*的開放列表里,我們只要反過來,父結點的鍵值總是小于或等于任何一個子節點的鍵值,這樣就沒問題了。
利用這種特性進行過排列的開放列表,那么我們可以保證,具有F值特性最小的那個元素,肯定是在這個二插樹的根節點,于是取值的時候,只要把根節點上的值取出來用就行了。(當然,取完以后還得維護開放列表的二叉堆特性,這點我下面會談),一般來說,二叉堆是利用數組來表示,那么正好,我所使用的vector結構便可以派上用場,二插堆的結構填往vector中的時候,利用的是一種類似
前序遍歷的方式順序進入的,也就是按照 當前節點 -- 當前節點的左子節點 -- 當前節點的右子節點這樣的順序來放入vector中,如下圖
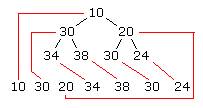
(此圖是借用了
Panic所翻譯的
《在A*尋路中使用二叉堆》一文中的圖片)
不過根節點進入的時候不要放在0號元素上,vector可以隨便先放進一個沒有用的元素,我處理的時候是放了一個NULL型指針進去的,也就是說根節點所在的vector下標為1。而這樣的話對于這個vector中非0下標的任意一個元素,我們要找他的父節或者是子節點就很簡單了,遵循下面一個原則:
具備二叉堆特性的vector中下標為n(n!=0)的一個元素:
他的父節點下標 = n / 2;(小數去掉) 比如下標為9的元素,他的父節點下標就是4
他的左子節點下標 = n * 2; 右子節點下標 = n * 2 +1 比如下標為3的元素他的左子節點下標為6,右子節點下標為7
對于我們的A*來說,在把元素放進開放列表里面的時候就需要按照二叉堆的添加步驟進行操作,而我們在把下標1的F值最小的元素取出來并且刪除掉以后,則需要把二叉堆重新維護下其二叉堆的特性,而在尋路過程中某個開放列表中元素的G值改變以后,我們則需要對這個開放列表再進行次維護,維持他的二叉堆特性。那么綜合以上,我們只需要3個功能函數,BinaryHeapAdd函數,BinaryHeapDelete函數,RetaxisBinaryHeap函數
BinaryHeapAdd函數,
1 把新的要進入開放列表的元素放進vector的末尾,也就是直接push_back進去 (這個新加進的元素為當前處理元素)
2 利用上面所說的父子節點下標關系,找到當前處理元素的父節點下標,然后比較兩個數,如果新的元素比他的父節點小,則把這個元素和他的父節點的位置互換一下,如果產生了互換行為,則針對新位置上的這個當前處理元素再次重復本次動作;
3 直到新的元素大于等于他的父節點,或者找到的父節點下標為0 ,則新元素的位置確定為找到,這個函數可以結束
void AStarBase::BinaryHeapAdd(POINTINFO* indexPoint)
{
int tmpF = indexPoint->F;
_openPoint.push_back(indexPoint); //先把新的元素放在vector最后
int theNewIndex = _openPoint.size()-1; //新元素的下標
while (true)
{
int theParentIndex = theNewIndex / 2; //新元素當前所在位置的父節下標
if (theParentIndex != 0)
{
if (_openPoint[theNewIndex]->F < _openPoint[theParentIndex]->F) //新元素的F值比他的父節點值大
{
//與父節點的位置進行交換
POINTINFO* tmpinfo = _openPoint[theParentIndex];
_openPoint[theParentIndex] = _openPoint[theNewIndex];
_openPoint[theNewIndex] = tmpinfo;
_openPoint[theParentIndex]->openIndex = theParentIndex;
_openPoint[theNewIndex]->openIndex = theNewIndex;
theNewIndex = theParentIndex; //置新節點的處理下標為換過位置以后的值
}
else
{
break;
}
}
else //如果父節下標計算出來為0,則停止查找位置
{
break;
}
}
}
BinaryHeapDelete函數
1 把開放列表中1號元素取出并放在最后返回出來使用
2 需要對開放列表進行一次2叉堆特性重新維護,首先把vector中最后一個元素移動到1號下標位置,(1號元素為當前處理元素)
3 對1號下標位置的當前處理元素利用父子節點下標計算關系找出他的左子節點和右子節點,然后把這個元素與他的左子節點元素的F值和右子節點的F值大小分別做比較,如果子節點的比他更小,則把他與子節點的位置進行互換,如果兩個子節點的值都比他小,則與較小的那個子節點進行位置互換,如果產生了互換行為,則針對新位置上的當前處理元素再次進行本次動作
4 如果子節點的值都大于或者等于當前處理元素的值,或者計算出來的子節點下標已經朝出了vector最大元素個數,則停止排序,函數可以返回原來存起來的最小值
AStarBase::POINTINFO* AStarBase::BinaryHeapDelete()
{
if (_openPoint.size() <= 1) //開放列表里面只剩下開始放進去的一個空的POINTINFO指針
{
return NULL;
}
//先把最后一個元素放到1號位置
POINTINFO* tmpinfo = _openPoint[1]; //下標1位置的元素先存儲起來,函數結束的時候要return出去
_openPoint[1] = _openPoint.back(); //把vector中的最后一個元素放到下標1位置
_openPoint.pop_back();
_openPoint[1]->openIndex = 1;
int theSelectIndex = 1; //要處理元素的下標值
while (true)
{
int theLeftChildIndex = theSelectIndex * 2; //左子節點下標值
int theRightChildIndex = theSelectIndex * 2 + 1; //右子節點下標值
if (theLeftChildIndex >= _openPoint.size()) //這個數沒有子節點,則停止排序
{
break;
}
else if ( theLeftChildIndex == (_openPoint.size() -1)) //左子節點正好是vector中最后一個元素,即只有左子節點,沒有右子節點
{
if (_openPoint[theSelectIndex]->F > _openPoint[theLeftChildIndex]->F) //如果父節點的F值比左子節點更大
{
//交換
POINTINFO* tmptmpinfo = _openPoint[theLeftChildIndex];
_openPoint[theLeftChildIndex] = _openPoint[theSelectIndex];
_openPoint[theSelectIndex] = tmptmpinfo;
_openPoint[theLeftChildIndex]->openIndex = theLeftChildIndex;
_openPoint[theSelectIndex]->openIndex = theSelectIndex;
theSelectIndex = theLeftChildIndex;
}
else //如果小,則停止排序
{
break;
}
}
else if (theRightChildIndex < _openPoint.size()) //既有左子節點又有右子節點
{
if (_openPoint[theLeftChildIndex]->F <= _openPoint[theRightChildIndex]->F ) //左右子節點先互相比較 左邊的小
{
if (_openPoint[theSelectIndex]->F > _openPoint[theLeftChildIndex]->F) //處理的父節點F值比左子節點大
{
//交換(與左子節點)
POINTINFO* tmptmpinfo = _openPoint[theLeftChildIndex];
_openPoint[theLeftChildIndex] = _openPoint[theSelectIndex];
_openPoint[theSelectIndex] = tmptmpinfo;
_openPoint[theLeftChildIndex]->openIndex = theLeftChildIndex;
_openPoint[theSelectIndex]->openIndex = theSelectIndex;
theSelectIndex = theLeftChildIndex;
}
else
{
break;
}
}
else //右邊的比較小
{
if (_openPoint[theSelectIndex]->F > _openPoint[theRightChildIndex]->F) //處理的F值比右子節點大
{
//交換(與右子節點)
POINTINFO* tmptmpinfo = _openPoint[theRightChildIndex];
_openPoint[theRightChildIndex] = _openPoint[theSelectIndex];
_openPoint[theSelectIndex] = tmptmpinfo;
_openPoint[theRightChildIndex]->openIndex = theRightChildIndex;
_openPoint[theSelectIndex]->openIndex = theSelectIndex;
theSelectIndex = theRightChildIndex;
}
else
{
break;
}
}
}
}
return tmpinfo;
}
大家可以看到,上面的兩個函數所做的添加和刪除操作,可以保證開放列表里,1號位置的元素的F值肯定是最小的,而其他地方的大小位置關系,我們可以不需要理會,我們只要保持一個原則,2叉堆里的父節點元素F值不能比子節點大,就可以了
而尋路過程中由于F值重計算而導致的重排序,其實和添加操作的原理是一樣的,我們只需要把那個改過F值的元素,把他和他的父節點的F值進行比較,如果改過的值小,則互換,如果并不小或者沒有了父節點,則停止
void AStarBase::RetaxisBinaryHeap(int index)
{
int theNewIndex = index; //當前處理的下標
while (true)
{
int theParentIndex = theNewIndex / 2; //當前處理節點的父節點下標值
if (theParentIndex != 0)
{
if (_openPoint[theNewIndex]->F < _openPoint[theParentIndex]->F) //新進來的F值比他的父節點值大
{
//進行交換
POINTINFO* tmpinfo = _openPoint[theParentIndex];
_openPoint[theParentIndex] = _openPoint[theNewIndex];
_openPoint[theNewIndex] = tmpinfo;
_openPoint[theParentIndex]->openIndex = theParentIndex;
_openPoint[theNewIndex]->openIndex = theNewIndex;
theNewIndex = theParentIndex;
}
else
{
break;
}
}
else
{
break;
}
}
}
利用上面3個操作函數所算出來的尋路結果,與一開始使用在無序開放列表里每次利用比較法找出最小F值所得到的結果是一樣的,
POINT(2,2)尋路到 POINT(398,398)
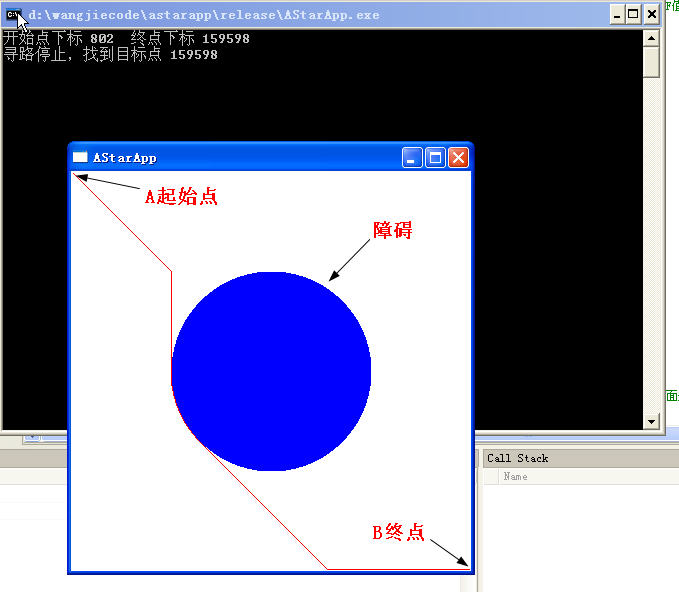
好吧,其實我們用他的目的是什么?就是要看看他消耗的速度而已,讓我們來看一下性能分析表
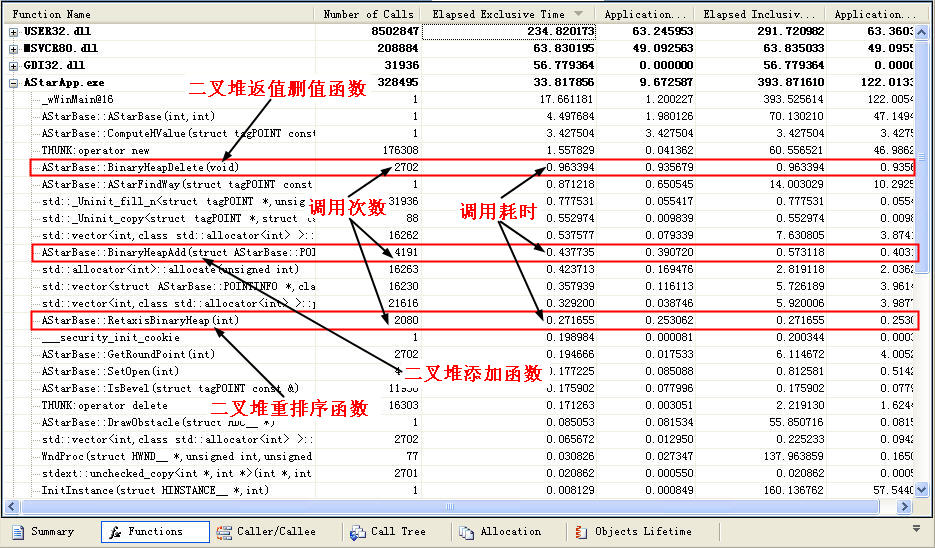
大家可以看到,在整個程序中這3個函數所消耗的時間為 0.963394 + 0.437735 + 0.271655 = 1.672784毫秒,是無序找最小值方法所使用時間的十分之一左右,是使用正常一些全排序方法消耗速度的六分之一左右,這還是在路徑非常簡單的情況下,而一旦障礙更多,路徑更復雜,開放列表里的元素更多的時候,Binary Heap方法能體現他更大的速度優勢
以上代碼沒有經過任何優化工作,僅僅是實現了下二叉堆的功能,各位將就著看了 ^O^
如果對A*尋路基礎算法原理不清楚并且有興趣的朋友,可以去gameres上看一下這篇文章
http://data.gameres.com/message.asp?TopicID=25439
posted on 2008-03-11 11:48
火夜風舞 閱讀(3171)
評論(0) 編輯 收藏 引用