Dump
調用堆棧的原理以及異常信息的反饋
動機:
在游戲開發(fā)過程中,我們利用
QA
部門來做產(chǎn)品的質量保證,盡可能將絕大部分錯誤消化在內部,保證游戲的版本質量,但是
QA
部門畢竟有他的局限性,盡管經(jīng)過嚴格的測試也很難保證將所有的問題一網(wǎng)打盡.
通過在
Log
中轉儲的錯誤信息,我們可以進一步找出問題,但是
Log
文件產(chǎn)生在終端,我們拿到的也僅僅是公司內部測試部門產(chǎn)生的
Log
文件,顯然公司內部得到的信息是很有限的,如果能從玩家那里拿到異常信息,我們才能最快的去解決問題,盡可能在錯誤產(chǎn)生重大影響之前將其解決,所以我們有必要從被動的獲取異常信息,轉為主動去獲取.
可行性
:
在錯誤發(fā)生時
Dump
調用堆棧,可以讓我們知道錯誤發(fā)生的位置,這比已往普通的
LOG
更加有效的多.我們可以將出錯的堆棧地址反饋回來.這一切在終端出現(xiàn)異常的時候自動進行.
Windows
操作系統(tǒng)提供的
SEH
結構化異常機制可能讓我們在程序崩潰的瞬間處理這些事情.
效率問題
:
SEH
是
windows
的異常機制,除非在編譯時候特別指定不使用,否則總有默認的
SEH
處理機制,
kernel32.dll
中有默認的
SEH
處理接口,當我們需要自己處理異常的時候,我們的處理點會掛接在異常處理鏈的最前端,這種鏈類似
Hook
的鏈.鏈的頭部放在
fs[0]
的位置.也就是說效率的問題是可以不必考慮,
具體實現(xiàn)
:
通過閱讀反匯編代碼可以了解函數(shù)調用過程中堆棧的結構
:
1
函數(shù)調用時
CALL
將下一行指令地址壓入堆棧
2
函數(shù)運行第一行會將
EBP
壓入堆棧
3
保存當前堆棧地址到
EBP (mov ebp,esp)
再遇到
call
時從第一步執(zhí)行,所以每次第二步壓入堆棧的都是上一層函數(shù)調用的
ESP
地址,而這個地址
+4
字節(jié)偏移則是當前調用函數(shù)返回后的下一條指令,也就是上一層函數(shù)的地址,所以我們只要知道當前函數(shù)的
EBP
值
(
也就是當前函數(shù)的棧頂
)
就能夠遍歷得到所有調用堆棧層次.
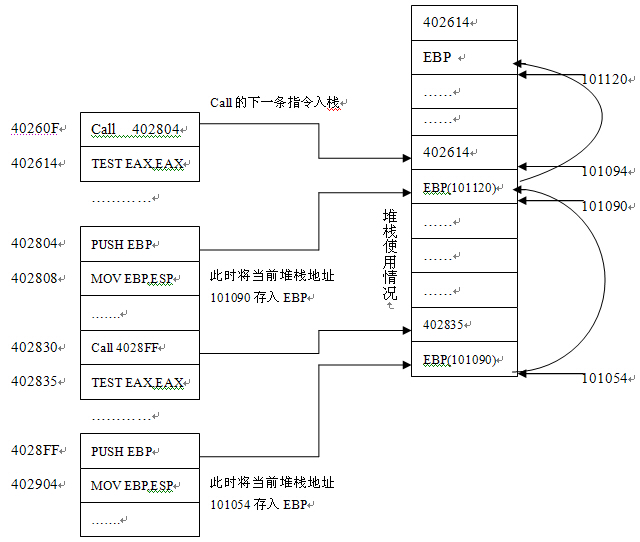
我們將windows SEH 結構化異常引入后,可以在異常發(fā)生的時候得到當前的EBP值,從而通過這個值得到整個調用堆棧的地址.
在發(fā)布工程的時候,我們只需要生成map文件,就可以通過這個地址得到崩潰位置.使用HTTP GET 或POST方式可以將我們所需要的崩潰信息提交到我們指定的網(wǎng)站.這種方式只是通過URL參數(shù)來提交數(shù)據(jù),只需要使用API InternetOpenUrl就可以很方便的將信息提交.此外如果不使用HTTP方式,我們也可以在這個時候創(chuàng)建新的socket 對指定的服務器進行連接來傳輸數(shù)據(jù).

static TCHAR hdrs[] = _T("Content-Type: application/x-www-form-urlencoded");
static const TCHAR* accept= _T("Accept: */*");
static TCHAR action[]=_T("datecomit.aspx");//預提交的頁面
static TCHAR server[]=_T("192.168.9.119");//提交的server地址
static TCHAR frmdata[1024] ={0};
_tcscpy(frmdata,_T("message=this is a test message"); //提交數(shù)據(jù), message為提交名字
// for clarity, error-checking has been removed
HINTERNET hSession = InternetOpen("MyAgent",
INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
HINTERNET hConnect = InternetConnect(hSession, server,
INTERNET_DEFAULT_HTTP_PORT, NULL, NULL, INTERNET_SERVICE_HTTP, 0, 1);
HINTERNET hRequest = HttpOpenRequest(hConnect, "POST", action, NULL, NULL, &accept, 0, 1);
HttpSendRequest(hRequest, hdrs, strlen(hdrs), frmdata, strlen(frmdata));
此后我們只需要定期觀察所提交的內容,便可以立即得知是否有異常出現(xiàn).根據(jù)同一異常出現(xiàn)的幾率可以得知是否是致命的錯誤,是否需要緊急更新.