注:現在版本的GCC把預處理和編譯兩個步驟合成一個步驟,用cc1工具來完成。gcc其實是后臺程序的一些包裝,根據不同參數去調用其他的實際處理程序,比如:預編譯編譯程序cc1、匯編器as、連接器ld
ld -static crt1.o crti.o crtbeginT.o hello.o -start-group -lgcc -lgcc_eh -lc-end-group crtend.o crtn.o (省略了文件的路徑名)。
語法分析:語法分析器將記號(Token)產生語法樹(Syntax Tree)。yacc工具可實現語法分析(yacc: Yet Another Compiler Compiler)。
源代碼優化:源代碼優化器(Source Code Optimizer),將整個語法書轉化為中間代碼(Intermediate Code)(中間代碼是與目標機器和運行環境無關的)。中間代碼使得編譯器被分為前端和后端。編譯器前端負責產生機器無關的中間代碼;編譯器后端將中間代碼轉化為目標機器代碼。
目標代碼生成:代碼生成器(Code Generator).
鏈接的主要過程包括:地址和空間分配(Address and Storage Allocation),符號決議(Symbol Resolution),重定位(Relocation)等。

夾在ELF頭和節頭部表之間的都是節。一個典型的ELF可重定位目標文件包含下面幾個節:
- .text:已編譯程序的機器代碼。
- .rodata:只讀數據,比如printf語句中的格式串和開關(switch)語句的跳轉表。
- .data:已初始化的全局C變量。局部C變量在運行時被保存在棧中,既不出現在.data中,也不出現在.bss節中。
- .bss:未初始化的全局C變量。在目標文件中這個節不占據實際的空間,它僅僅是一個占位符。目標文件格式區分初始化和未初始化變量是為了空間效率在:在目標文件中,未初始化變量不需要占據任何實際的磁盤空間。
- .symtab:一個符號表(symbol table),它存放在程序中被定義和引用的函數和全局變量(包括引用到的外部變量和函數,不含有局部變量)的信息。一些程序員錯誤地認為必須通過-g選項來編譯一個程序,得到符號表信息。實際上,每個可重定位目標文件在.symtab中都有一張符號表。然而,和編譯器中的符號表不同,.symtab符號表不包含局部變量的表目。
- .rel.text:當鏈接噐把這個目標文件和其他文件結合時,.text節中的許多位置都需要修改。一般而言,任何調用外部函數或者引用全局變量(包括本目標文件內的全局變量,因為在鏈接時要多個目標文件的相同段合并,這樣數據的地址就會改變,所以要重定位)的指令都需要修改。另一方面調用本地函數的指令則不需要修改。注意,可執行目標文件中并不需要重定位信息,因此通常省略,除非使用者顯式地指示鏈接器包含這些信息。
- .rel.data:被模塊定義或引用的任何全局變量的信息。一般而言,任何已初始化全局變量的初始值是全局變量或者外部定義函數的地址都需要被修改。
- .debug:一個調試符號表,其有些表目是程序中定義的局部變量和類型定義,有些表目是程序中定義和引用的全局變量,有些是原始的C源文件。只有以-g選項調用編譯驅動程序時,才會得到這張表。
- .line:原始C源程序中的行號和.text節中機器指令之間的映射。只有以-g選項調用編譯驅動程序時,才會得到這張表。
- .strtab:一個字符串表,其內容包括.symtab和.debug節中的符號表,以及節頭部中的節名字。字符串表就是以null結尾的字符串序列。
旁注:為什么未初始化的數據稱為.bss?
用術語.bss來表示未初始化的數據是很普遍的。它起始于IBM 704匯編語言(大約在1957年)中”塊存儲開始(Block Storage Start)“指令的首字母縮寫,并沿用至今。一個記住區分.data和.bss節的簡單方法是把“bss”看成是“更好地節省空間(Better Save Space)!“的縮寫。
三、靜態鏈接
虛擬存儲器是建立在主存--輔存物理結構基礎上,有附加的硬件裝置及操作系統存儲管理軟件組成的一種存儲體系。

顧名思義,虛擬存儲器是虛擬的存儲器,它其實是不存在的,而僅僅是由一些硬件和軟件管理的一種“系統”。他提供了三個重要的能力:1,它將主存看成一個存儲在磁盤上的地址空間的高速緩存,在主存中只保存活動區域,并根據需要在磁盤和主存之間來回傳送數據(這里存在“交換空間”以及“頁面調度”等概念),通過這種方式,高效地利用主存;2,它為每個進程提供了統一的地址空間(以虛擬地址編址),從而簡化了存儲器管理;3,操作系統會為每個進程提供獨立的地址空間,從而保護了每個進程的地址空間不被其他進程破壞。
虛擬存儲器與虛擬地址空間是兩個不同的概念:虛擬存儲器是假想的存儲器,而虛擬存儲空間是假想的內存。它們之間的關系應該與主存儲器與內存空間之間的關系類似。
鏈接部分:
鏈接就是將不同部分的代碼和數據收集和組合成一個單一文件的過程,也就是把不同目標文件合并成最終可執行文件的過程。當然,務必知道:這個過程不涉及內存。鏈接可以分為三種情形:1,編譯時鏈接,也就是我們常說的靜態鏈接;2,裝載時鏈接;3,運行時鏈接。裝載時鏈接和運行時鏈接合稱為動態鏈接。在此,我們的鏈接部分將主要講述靜態鏈接,而裝載時鏈接我們放在裝載部分講,運行時鏈接忽略。
1、什么是靜態鏈接?
靜態鏈接就是將多個目標文件組合在一起形成一個可執行文件,如將a.o 和 b.o 鏈接在一起形成 可執行文件ab。
2、靜態鏈接的過程包括哪幾個部分?
靜態鏈接包括兩個大部分:一是空間和地址的分配;二是符號解析和重定位
(1)空間和地址的分配
編譯器在將a.o 和 b.o 是如何合并在一起的??
第二種方法就是 相似段合并:顧名思義 就是把不同目標文件的相同名字的段合并成一個段,如下圖:
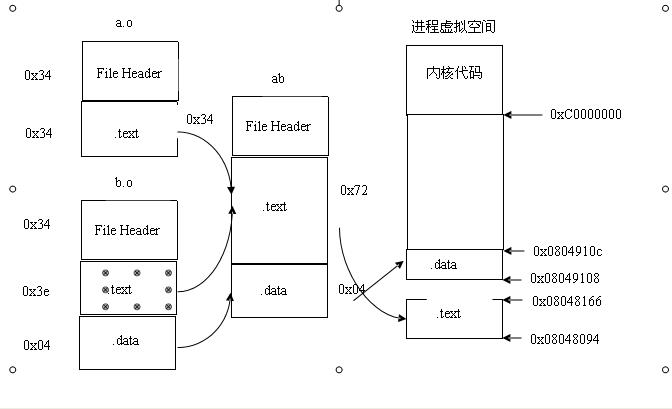
圖1
這是編譯器實際進行合并目標文件的策略。
/*a.c*/
extern int shared; int main() { int a = 100; swap(&a,&shared); }
/*b.c*/
int shared = 1; void swap(int *a,int *b) { *a ^= *b ^= *a ^= *b; }
編譯這兩個文件得到“a.o”和“b.o”兩個目標文件
§gcc -c a.c b.c
從代碼中可以看到三個符號:share,swap和main。
靜態鏈接的整個過程分為兩步:
第一步:空間和地址分配。掃描所有的輸入目標文件,獲得他們的各個段的長度、屬性和位置,并且將輸入目標文件中的符號表中所有的符號定義和符號引用收集起來,統一放到一個全局符號表。這樣,連接器將能夠獲得所有輸入目標文件的段長度,并且將它們合并,計算出輸出文件中各個段合并后的長度與位置,并建立映射關系。
這里可能會有一個問題:建立了什么樣的映射關系。如上面的圖1,你可能就會有所了解。映射關系就是指可執行文件與進程虛擬地址空間之間的映射。那么,這里程序還沒有執行,更不會出現進程,哪里來的進程地址空間呢?此時虛擬存儲器便發揮了很大的作用:雖然此時沒有進程,但是每個進程的虛擬地址空間的格式都是一致的。所以,為可執行文件的每個段甚至每個符號符號分配地址也就不會有什么錯了。注意:在鏈接之前,目標文件中的所有段的虛擬地址都是0,因為虛擬空間還沒有被分配,默認都為0.等到鏈接之后,可執行文件中的各個段已經都被分配到了相應的虛擬地址
第二步:符號解析與重定位
首先,符號解析。解析符號就是將每個符號引用與它輸入的可重定位目標文件中的符號表中的一個確定的符號定義聯系起來。
若找不到,則出現編譯時錯誤。
其次是重定位;
不同的處理器指令對于地址的格式和方式都不一樣。我們這里采用的是32位的x86處理器,介紹兩種尋址方式。
X86基本重定位類型 |
宏定義 | 值 | 重定位修正方法 |
R_386_32 | 1 | 絕對尋址修正S + A |
R_386_PC32 | 2 | 相對尋址修正S + A - P |
注:
A:保存在被修正位置的值,對于32位cpu的話,采用
R_386_PC32尋址的話
它應該為0xFFFFFFFC即-4,它是代表地址的四個字節;而采用
R_386_32尋址,它應該為0.
P:被修正的位置。考慮以下程序
...
1023: 11 11 11
1026:e8
fc
ff ff ff
102b: 11 11 11
...
上述藍色fc標記處即是被修正的位置,即0x1027.
S:符號的實際地址。也就是第一步中空間和地址分配時得到的符號虛擬地址。
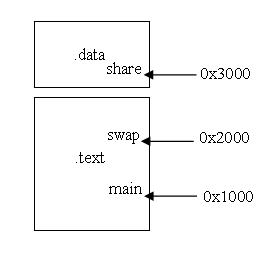
舉例來說吧!鏈接成的可執行文件中,假設main函數的虛擬地址為0x1000,swap函數的虛擬地址為0x2000;shared變量的虛擬地址為0x3000;
絕對地址修正:對shared變量的地址修正。
l
S:shared的實際地址為0x3000;
l
A:被修正位置的值,即0.
所以最后這個重定位修正地址為:0x3000,不變!
相對尋址修正:對符號“swap”進行修正。
l
S:符號swap的實際地址,即0x2000;
l
A:被修正位置的值,即0xFFFFFFFC(-4);
l
P:被修正位置,及0x1027
最后的重定位修正地址為:S + A -P = 0x2000 +(-4)- 0x1027 = 0xFD5.即修正后的程序為:
...
1023: 11 11 11
1026:e8
d5 0f 00 00
102b: 11 11 11
...
發現熟悉的規則了嗎?下一條指令(PC)的地址為0x102b,加上這個修正值正好等于0x2000,
0x102b + 0xFD5 = 0x2000,剛好是swap函數的地址。
以上內容沒有涉及到c標準庫,僅僅是自己實現的兩個c語言程序之間的鏈接狀況,也就是“程序里面的printf怎么處理”沒有說明。這里,我們就要提及“靜態庫”的概念。其實一個靜態庫可以簡單地看成一組目標文件的集合,即很多目標文件經過壓縮打包后形成的一個文件。與靜態庫鏈接的過程是這樣的:ld鏈接器自動查找全局符號表,找到那些為決議的符號,然后查出它們所在的目標文件,將這些目標文件從靜態庫中“解壓”出來,最終將它們鏈接在一起成為一個可執行文件。也就是說只有少數幾個庫和目標文件被鏈接入了最終的可執行文件,而非所有的庫一股腦地被鏈接進了可執行文件。
四、裝載:
以Linux內核裝載ELF為例簡述一下裝載過程。當我們在Linux系統的bash下輸入一個命令執行某個ELF程序時,在用戶層面,bash進程會調用fork()系統調用創建一個新的進程,然后新的進程調用execve()來執行指定的ELF文件,原先的bash進程繼續返回等待剛才啟動時新進程結束,然后繼續等待用戶輸入命令。這里需注意,隨著一個新進程的出現,操作系統會為它創建一個獨立的虛擬地址空間。
【創建虛擬地址空間】我們知道一個虛擬空間由一組映射函數將虛擬空間的各個頁映射到相應的物理空間,那么創建一個虛擬空間實際上并不是創建空間而是創建映射函數所需要的數據結構。舉例來說,在x86的Linux下創建虛擬地址空間實際上只是分配一個頁目錄(頁表)就可以了,甚至不設置頁映射關系,這些映射關系等到后面程序發生“缺頁”時在進行設置。
在進入execve()系統調用之后,Linux內核就開始進行真正的裝載工作。在內核中,execve()系統調用相應的入口是sys_execve(),作用:參數的檢查復制;調用do_execve(),流程:查找被執行的文件,讀取文件的前128個字節以判斷文件的格式是elf還是其它;調用search_binary_handle(),流程:通過判斷文件頭部的魔數確定文件的格式,并且調用相應的裝載處理程序。ELF可執行文件的裝載處理過程叫load_elf_binary(),它的主要步驟如下:
1,檢查ELF可執行文件格式的有效性,比如魔數、程序頭表中段的數量。
2,尋找動態鏈接的“.interp”段,找到動態鏈接器的路徑,以便于后面動態鏈接時會用上。
3,讀取可執行文件的程序頭,并且創建虛擬空間與可執行文件的映射關系。
【讀取可執行文件的程序頭(存儲了哪些部分被映射),并且創建虛擬空間與可執行文件的映射關系】創建虛擬空間時的頁映射關系函數是虛擬空間到物理內存的映射關系,而這一步所做的事虛擬空間與可執行文件的映射關系。我們知道,當程序發生缺頁是,操作系統會為物理內存分配一個物理頁,然后將該缺頁從磁盤中讀取到內存,在設置缺頁的虛擬頁與物理頁之間的映射關系,這樣程序才可以得以正常運行。但是明顯的一點是,當操作系統捕獲到缺頁錯誤時,他應當知道程序當前需要的頁在可執行文件中的哪一個位置。而這就是虛擬存儲與可執行文件之間的映射關系。實際上,這種映射關系僅僅是保存在操作系統內部的一個數據結構。當發生缺頁錯誤是,CPU將控制權交給操作系統,操作系統利用專門的缺頁處理例程來查詢這個數據結構(映射關系),然后找到所需頁所在的虛擬內存區域,以及在可執行文件的偏移,然后把該頁加載進物理內存,同時將該虛擬頁與物理頁之間建立映射關系,最后把控制權還給進程,進程從剛才缺頁位置重新開始執行。
4,初始化ELF進程環境。
5,將系統調用的返回地址修改成ELF可執行文件的入口點,這個入口點取決于程序的鏈接方式,對于靜態鏈接的ELF可執行文件,它就是ELF文件的文件頭中e_entry所指的地址;對于動態鏈接的ELF可執行文件,程序入口點就是動態鏈接器。
【將CPU指令寄存器設置成可執行文件的入口,啟動運行】對動態鏈接來講,此時就啟動了動態鏈接器。
當load_elf_binary()執行完畢,返回至do_execve()在返回至sys_execve()時,系統調用的返回地址已經被改寫成了被裝載的ELF程序的入口地址了。所以,當sys_execve()系統調用從內核態返回到用戶態時,EIP寄存器直接跳轉到ELF程序的入口地址。此時,ELF可執行文件裝載完成。接下來就是動態鏈接器對程序進行動態鏈接了。
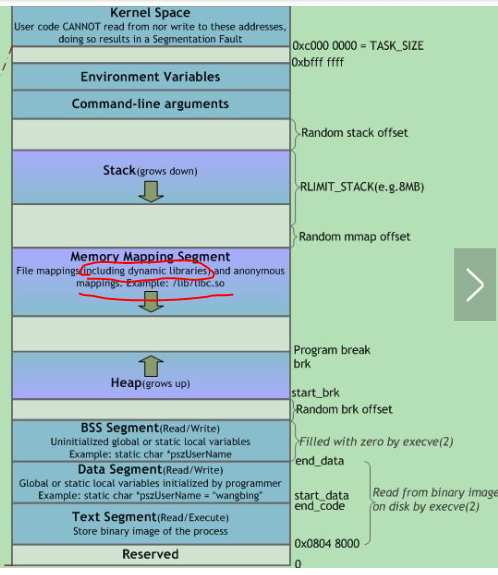
進程的虛擬空間:
五、動態鏈接
動態鏈接ELF文件的生成過程
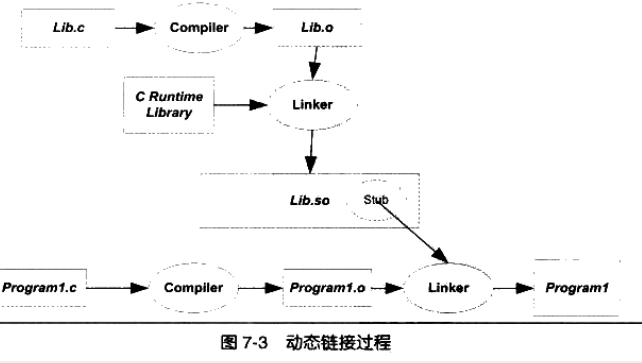
主要原因有兩個:第一,考慮內存和磁盤空間。靜態鏈接極大地浪費內存空間。因為在靜態鏈接的情況下,假設有兩個程序共享一個模塊,那么在靜態鏈接后輸出的兩個可執行文件中各有一個共享模塊的副本。如果同時運行這兩個可執行文件,那么這個共享模塊將在磁盤和內存中都有兩個副本,對磁盤和內存造成極大地浪費;第二,程序的更新。一旦程序中的一個模塊被修改,那么整個程序都要重新鏈接、發布給用戶。如果這個程序相當的大,那么后果就會更加嚴重!
對于一個共享對象(linux下共享的模塊),要實現被其他程序之間的共享,就要使其代碼和數據分開,每個程序都會有該模塊的數據部分的副本,代碼部分是共享的。
共享模塊被映射的虛擬地址空間就在上面進程虛擬空間中的 (Memery Mapping部分)
共享模塊被映射的模樣是
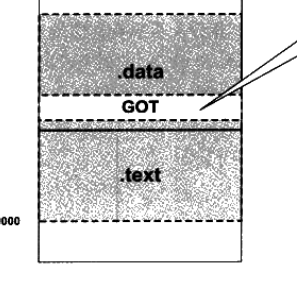
動態鏈接做了什么?
務必知道,動態鏈接是相對于共享對象而言的。動態鏈接器將程序所需要的所有共享庫裝載到進程的地址空間,并且將程序匯總所有為決議的符號綁定到相應的動態鏈接庫(共享庫)中,并進行重定位工作。
對于共享模塊來說,要實現共享,那么其代碼對數據的訪問必須是地址無關(就是代碼中的地址是固定的,當然這是用的相對地址嘍)的,如何做到地址無關,編譯器是這么干的,每一個共享模塊,都會在其代碼段有一個GOT(global offset table)段,如上圖所示,Got是一個指針數組,用來存儲外部變量的地址,而代碼相對于Got的距離是固定的,當對外部模塊變量數據和函數進行訪問時,就去訪問變量在GOT中的位置。
共享模塊對于數據的訪問方式:
本模塊的全局變量和函數------相對地址
外模塊的全局變量和函數-------GOT段
動態鏈接重定位時修改GOT中的值就實現了對變量的正確訪問。
動態鏈接的ELF文件啟動過程
動態鏈接基本分為三步:先是啟動動態鏈接器本身,然后裝載所有需要的共享對象,最后重定位和初始化。
1,動態鏈接器自舉
就我們所知道的,對普通的共享對象文件來說,它的重定位工作是由動態鏈接器來完成;它也可以依賴于其他共享對象,其中被依賴的共享對象由動態鏈接器負責鏈接和裝載。那么,對于動態鏈接器本身呢,它也是一個共享對象,它的重定位工作由誰完成?它是否可以依賴于其他的共享對象文件?
動態鏈接器有其自身的特殊性:首先,動態鏈接器本身不可以依賴其他任何共享對象(人為控制);其次動態鏈接器本身所需要的全局和靜態變量的重定位工作由它自身完成(自舉代碼)。
我們知道,在Linux下,動態鏈接器ld.so實際上也是一個共享對象,操作系統同樣通過映射的方式將它加載到進程的地址空間中。操作系統在加載完動態鏈接器之后,就將控制權交給動態鏈接器。動態鏈接器入口地址即是自舉代碼的入口。動態鏈接器啟動后,它的自舉代碼即開始執行。自舉代碼首先會找到它自己的GOT(全局偏移表,記錄每個段的偏移位置)。而GOT的第一個入口保存的就是“.dynamic”段的偏移地址,由此找到動態鏈接器本身的“.dynamic”段。通過“.dynamic”段中的信息,自舉代碼便可以獲得動態鏈接器本身的重定位表和符號表等,從而得到動態鏈接器本身的重定位入口,然后將它們重定位。完成自舉后,就可以自由地調用各種函數和全局變量。
2,裝載共享對象
完成自舉后,動態鏈接器將可執行文件和鏈接器本身的符號表都合并到一個符號表當中,稱之為“全局符號表”。然后鏈接器開始尋找可執行文件所依賴的共享對象:從“.dynamic”段中找到DT_NEEDED類型,它所指出的就是可執行文件所依賴的共享對象。由此,動態鏈接器可以列出可執行文件所依賴的所有共享對象,并將這些共享對象的名字放入到一個裝載集合中。然后鏈接器開始從集合中取出一個所需要的共享對象的名字,找到相應的文件后打開該文件,讀取相應的ELF文件頭和“.dynamic”,然后將它相應的代碼段和數據段映射到進程空間中。如果這個ELF共享對象還依賴于其他共享對象,那么將依賴的共享對象的名字放到裝載集合中。如此循環,直到所有依賴的共享對象都被裝載完成為止。
當一個新的共享對象被裝載進來的時候,它的符號表會被合并到全局符號表中。所以當所有的共享對象都被裝載進來的時候,全局符號表里面將包含動態鏈接器所需要的所有符號。
3,重定位和初始化
當上述兩步完成以后,動態鏈接器開始重新遍歷可執行文件和每個共享對象的重定位表,將表中每個需要重定位的位置進行修正,原理同前。
重定位完成以后,如果某個共享對象有“.init”段,那么動態鏈接器會執行“.init”段中的代碼,用以實現共享對象特有的初始化過程。
此時,所有的共享對象都已經裝載并鏈接完成了,動態鏈接器的任務也到此結束。同時裝載鏈接部分也將告一段落!接下來便是程序的執行了。。。