近期工作上的事情太雜太瑣碎,好久沒有更新博客了。工作當(dāng)中時有所思所感的東西,每次想記錄下來時,奈何心里的那個黑天使總是跳出來說“太麻煩了”,然后就真的懶得寫了,加之最近有點貪玩《爐石》,所以博客園的這一畝三分地也已荒草叢生。廢話不多說,進入本篇博客正題吧。
對于服務(wù)器程序而言,尤其是云計算時代的服務(wù)器程序,三高標(biāo)準(zhǔn)(高可用、高性能、高擴展)往往是衡量一個優(yōu)秀的服務(wù)器程序的重要指標(biāo)。本篇文章主要聊聊服務(wù)宕機恢復(fù)(高可用的重要內(nèi)容)、負(fù)載均衡(高擴展、高可用的主要內(nèi)容)。以下內(nèi)容均屬個人工作中的見解,如有不妥之處,歡迎指正。 ----peakflys
一、服務(wù)的宕機恢復(fù) 服務(wù)根據(jù)功能定位的劃分,一般可以抽象為前端服務(wù)、狀態(tài)服務(wù)、各種邏輯功能服務(wù)、數(shù)據(jù)存儲服務(wù),這里給出兩個常見的簡單服務(wù)器架構(gòu)(不含數(shù)據(jù)存儲服務(wù))
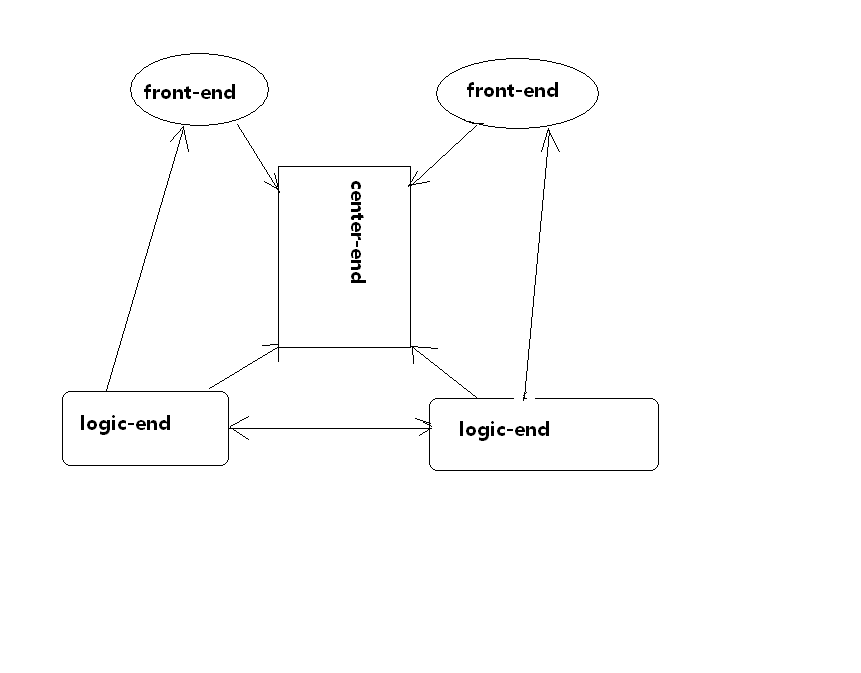

根據(jù)不同的服務(wù)類型,宕機恢復(fù)的具體操作是不同的具體的操作是不同的。
1、前端服務(wù) 前端服務(wù)一般我們又稱之為網(wǎng)管服務(wù),對于這種服務(wù)宕機的情況,我們除了對其他服務(wù)做用戶下線的操作外,前端服務(wù)并沒有其他的宕機恢復(fù)操作,重啟之后,用戶重新連上來并注冊狀態(tài)即可,對于宕機重啟的間歇時間的服務(wù),我們放在下面的高可用相關(guān)的內(nèi)容來講。
2、狀態(tài)服務(wù) 如果業(yè)務(wù)量和用戶量不是特別復(fù)雜的話,我們一般情況下都是把狀態(tài)服務(wù)器設(shè)計成全局的單點服務(wù)器。就如上面圖片中所畫的那兩種簡易服務(wù)器架構(gòu)里的center-end一樣。這個服務(wù)往往存儲用戶所在的網(wǎng)關(guān)信息或者邏輯服務(wù)器的信息,這些信息往往是比較重要的。所以對于他的宕機恢復(fù)我們一般情況下使用這幾種方案。
①、重新注冊 如果狀態(tài)服務(wù)crash重啟,所存狀態(tài)對應(yīng)的所有服務(wù)都過來重新注冊相應(yīng)的狀態(tài)。
優(yōu)點:邏輯簡單,不易出錯,擴展起來方便。
缺點:如果用戶量達(dá)到一定的規(guī)模,此服務(wù)重啟后服務(wù)器的負(fù)載會出現(xiàn)瞬間飆升。
②、cache同步 使用memcache或者redis等作為所存狀態(tài)的緩存(一般和狀態(tài)服務(wù)器不在同一臺物理機)。在狀態(tài)服務(wù)更新某一狀態(tài)時,同時把對應(yīng)的狀態(tài)數(shù)據(jù)刷到緩存服務(wù)器。 這樣在狀態(tài)服務(wù)宕機重啟后,直接從緩存中恢復(fù)(我稱之為積極恢復(fù)),或者其他服務(wù)來查詢對應(yīng)的狀態(tài)時,如果本地內(nèi)存沒有,則去緩存中找,找到時,回應(yīng)狀態(tài) 查詢請求,同時把狀態(tài)恢復(fù)到本地內(nèi)存中(我稱之為惰性恢復(fù))。“積極恢復(fù)”可以馬上使?fàn)顟B(tài)服務(wù)恢復(fù)到宕機前的狀態(tài),“惰性恢復(fù)”則可以在不影響功能的情況下分散 的慢慢的恢復(fù)。
優(yōu)點:邏輯較簡單,不易出錯,擴展性很好。
缺點:如果在狀態(tài)服務(wù)crash前,cache服務(wù)重啟或者關(guān)閉了,則之后狀態(tài)服務(wù)宕機恢復(fù)時,會導(dǎo)致部分狀態(tài)數(shù)據(jù)的缺失。(所以cache服務(wù)要保證穩(wěn)定,最好直接 使用memcache等成熟的解決方案)。同時此類型不方便存儲過于復(fù)雜的數(shù)據(jù)類型。
③、master-slave 每次啟動兩臺狀態(tài)服務(wù),先啟動的作為master服務(wù),后啟動為slave服務(wù),每次master服務(wù)更新某一狀態(tài)時,會同時把對應(yīng)的信息同步到slave服務(wù)器(或者兩者 直接使用共享內(nèi)存等方式)。當(dāng)master服務(wù)宕機時,通過一些方案(例如virtual IP漂移等),使slave服務(wù)轉(zhuǎn)變?yōu)閙aster服務(wù),同時master服務(wù)重啟后變?yōu)?nbsp; slave服務(wù)。
優(yōu)點:可用性更強,服務(wù)的宕機恢復(fù)能力也比較強。所存數(shù)據(jù)的安全性和一致性都比較高,而且存儲的數(shù)據(jù)類型不受限制。
缺點:邏輯比較復(fù)雜,要做的處理比較多,而且容易出錯。
④、master-master(or more) 每次啟動兩臺(或者多臺)狀態(tài)服務(wù),兩臺服務(wù)之間使用共享內(nèi)存等方式共享狀態(tài)信息,這樣任何一臺服務(wù)的宕機重啟均不影響狀態(tài)的查詢服務(wù),而且重啟之后不 需要恢復(fù)做什么額外的恢復(fù)操作。
優(yōu)點:服務(wù)本身不存儲狀態(tài),服務(wù)的高可用性更強,宕機恢復(fù)速度也比較快。
缺點:狀態(tài)存儲的一致性需要保證,而且使用的共享內(nèi)存等存儲帶來了另外的單點隱患,一旦宕機,影響重大。
這幾種方案各有優(yōu)缺點,在項目早期,用戶量不大,而且項目進度很趕的情況下,第一種方案,無疑是最適合的方案;如果所存儲的狀態(tài)是天然的key-value形式, 則第二種方案很適合;如果項目時間充裕,而且存儲的狀態(tài)很多或者很復(fù)雜的話,可以優(yōu)先考慮第三或者第四種。
3、數(shù)據(jù)存儲服務(wù) 這個服務(wù)是大家討論最多,解決方案也比較成熟的話題,目前我了解到的很多都是使用master-master或者master+多slave(memcache或redis集群)的方案,另外一些數(shù)據(jù)庫提供商本身就提供了很多高可用方案(例如SQL Server的AlwaysOn,Mysql最新存儲引擎的宕機恢復(fù)機制等),開發(fā)者本身不用太過關(guān)注。反倒是開發(fā)者最為關(guān)注的應(yīng)該是數(shù)據(jù)庫讀寫性能的優(yōu)化。
4、邏輯功能服務(wù)
這一項是最為復(fù)雜的,需要結(jié)合具體的邏輯功能來說。一般情況下,我認(rèn)為有以下幾種方案:
①、用戶重登陸處理 主要的邏輯服務(wù)宕機后,直接使用戶在其他服務(wù)做下線處理,然后客戶端程序自動做重連接,重新注冊到其他的邏輯功能服務(wù)器,恢復(fù)對應(yīng)的服務(wù)。
優(yōu)點:邏輯處理簡單,用戶狀態(tài)的維持不易出錯。
缺點:如果邏輯功能服務(wù)會保存一些用戶狀態(tài),則這種方案用戶感受度不好。而且如果登陸過程比較復(fù)雜時,其他服務(wù)器的負(fù)載也會比較高(例如賬號驗證一般放 在前端服務(wù)器來做,如果認(rèn)證過程過多等,前端服務(wù)的負(fù)載和出錯率都會升高)。
②、前端服務(wù)重新選擇 在用戶不斷開和前端服務(wù)器(即gateway服務(wù)器)連接的情況下,直接由前端服務(wù)器重新為用戶選擇新的邏輯功能服務(wù)。
優(yōu)點:僅作前端服務(wù)和邏輯服務(wù)之間的重連,響應(yīng)速度比較快。
缺點:如果邏輯功能服務(wù)會保存一些用戶狀態(tài),則這種方案用戶感受度不好。
其他邏輯更為復(fù)雜的,只能結(jié)合著具體業(yè)務(wù)來定制方案,在此不作過多的分析。
上面的服務(wù)舉例僅僅是一個便于講述的精簡版,如果要做高強度的高可用,尤其是在云時代的大數(shù)據(jù)量的高可用,服務(wù)器架構(gòu)里必然要消除單點服務(wù)!
時間不早了,負(fù)載均衡相關(guān)的東西放在下一篇博客討論,待續(xù)……