peakflys原創作品,轉載請保留原作者和源鏈接
項目中和自己代碼中大量使用了STL的容器,平時也沒怎么關注alloc的具體實現細節,主觀認識上還停留在侯捷大師的《STL源碼剖析》中的講解。
以下為書中摘錄截圖:詳見書中2.2.4節內容

前段時間項目中出了一個內存問題,在追查問題的過程中查看了對應的源碼(版本為libstdc++-devel-4.1.2)
源碼文件c++allocator.h中定義了默認的Alloc:#ifndef _CXX_ALLOCATOR_H
#define _CXX_ALLOCATOR_H 1
// Define new_allocator as the base class to std::allocator.
#include <ext/new_allocator.h>
#define __glibcxx_base_allocator __gnu_cxx::new_allocator
#endif
查看new_allocator.h文件,發現new_allocator僅僅是對operator new和operator delete的簡單封裝(感興趣的朋友可自行查看)。
眾所周知libstdc++中STL的大部分實現是取自SGI的STL,而《STL源碼剖析》的源碼是Cygnus C++ 2.91則是SGI STL的早期版本,下載源碼看了一下allocator的實現確實如書中所言。
不知道從哪個版本起,SGI的STL把默認的Alloc替換成了new_allocator,有興趣的同學可以查一下。
知道結果后,可能很多人和我一樣都不禁要問:Why?
以下是兩個版本的源碼實現:
1、new_allocator
// NB: __n is permitted to be 0. The C++ standard says nothing
// about what the return value is when __n == 0.
pointer
allocate(size_type __n, const void* = 0)
{
if (__builtin_expect(__n > this->max_size(), false))
std::__throw_bad_alloc();
return static_cast<_Tp*>(::operator new(__n * sizeof(_Tp)));
}
// __p is not permitted to be a null pointer.
void
deallocate(pointer __p, size_type)
{ ::operator delete(__p); }
2、__pool_alloc
template<typename _Tp>
_Tp*
__pool_alloc<_Tp>::allocate(size_type __n, const void*)
{
pointer __ret = 0;
if (__builtin_expect(__n != 0, true))
{
if (__builtin_expect(__n > this->max_size(), false))
std::__throw_bad_alloc();
// If there is a race through here, assume answer from getenv
// will resolve in same direction. Inspired by techniques
// to efficiently support threading found in basic_string.h.
if (_S_force_new == 0)
{
if (getenv("GLIBCXX_FORCE_NEW"))
__atomic_add(&_S_force_new, 1);
else
__atomic_add(&_S_force_new, -1);
}
const size_t __bytes = __n * sizeof(_Tp);
if (__bytes > size_t(_S_max_bytes) || _S_force_new == 1)
__ret = static_cast<_Tp*>(::operator new(__bytes));
else
{
_Obj* volatile* __free_list = _M_get_free_list(__bytes);
lock sentry(_M_get_mutex());
_Obj* __restrict__ __result = *__free_list;
if (__builtin_expect(__result == 0, 0))
__ret = static_cast<_Tp*>(_M_refill(_M_round_up(__bytes)));
else
{
*__free_list = __result->_M_free_list_link;
__ret = reinterpret_cast<_Tp*>(__result);
}
if (__builtin_expect(__ret == 0, 0))
std::__throw_bad_alloc();
}
}
return __ret;
}
template<typename _Tp>
void
__pool_alloc<_Tp>::deallocate(pointer __p, size_type __n)
{
if (__builtin_expect(__n != 0 && __p != 0, true))
{
const size_t __bytes = __n * sizeof(_Tp);
if (__bytes > static_cast<size_t>(_S_max_bytes) || _S_force_new == 1)
::operator delete(__p);
else
{
_Obj* volatile* __free_list = _M_get_free_list(__bytes);
_Obj* __q = reinterpret_cast<_Obj*>(__p);
lock sentry(_M_get_mutex());
__q ->_M_free_list_link = *__free_list;
*__free_list = __q;
}
}
}
從源碼中可以看出new_allocator基本就沒有什么實現,僅僅是對operator new和operator delete的封裝,而__pool_alloc的實現基本和《STL源碼剖析》中一樣,所不同的是加入了多線程的支持和強制operator new的判斷。
無論從源碼來看,還是實際的測試(后續會附上我的測試版本),都可以看出__pool_alloc比new_allocator更勝一籌。
同很多人討論都不得其解,網上也很少有關注這個問題的文章和討論,倒是libstdc++的官網文檔有這么一段:

(peakflys注:文檔地址:https://gcc.gnu.org/onlinedocs/libstdc++/manual/memory.html#allocator.default)
從文檔的意思來看,選擇new_allocator是基于大量測試,不幸的是文檔中鏈接的測試例子均無法訪問到……不過既然他們說基于測試得出的結果,我就隨手寫了一個自己的例子:
#include <map>
#include <vector>
#ifdef _POOL
#include <ext/pool_allocator.h>
#endif
static const unsigned int Count = 1000000;
using namespace std;
struct Data
{
int a;
double b;
};
int main()
{
#ifdef _POOL
map<int, Data, less<int>, __gnu_cxx::__pool_alloc<pair<int, Data> > > mi;
vector<Data, __gnu_cxx::__pool_alloc<Data> > vi;
#else
map<int, Data> mi;
vector<Data> vi;
#endif
for(int i = 0; i < Count; ++i)
{
Data d;
d.a = i;
d.b = i * i;
mi[i] = d;
vi.push_back(d);
}
mi.clear();
#ifdef _POOL
vector<Data, __gnu_cxx::__pool_alloc<Data> >().swap(vi);
#else
vector<Data>().swap(vi);
#endif
for(int i = 0; i < Count; ++i)
{
Data d;
d.a = i;
d.b = i * i;
mi[i] = d;
vi.push_back(d);
}
return 0;
}
因為當數據大于128K時,__pool_alloc同new_allocator一樣直接調用operator,所以例子中構造出的Data小于128K,來模擬兩個分配器的不同。同時如libstdc++官網中說的,我們同時使用了sequence容器vector和associate容器map。
例子中模擬了兩種類型容器的插入-刪除-插入的過程,同時里面包含了元素的構造、析構以及內存的分配和回收。
以下是在我本地機器上運行的結果:
1、-O0的版本:
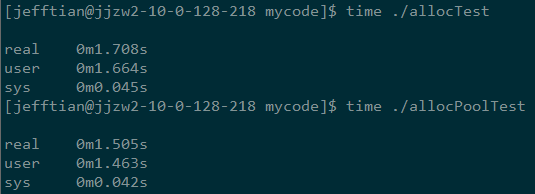
2、-O2的版本:
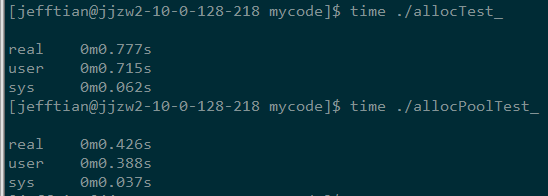
多線程的測試例子我就不貼了,測試結果大致和上面相同,大家可以自行測試。
從多次運行的結果來看__pool_alloc的性能始終是優于new_allocator的。
又回到那個問題,為什么SGI STL的官方把默認的Alloc從__pool_alloc變為new_allocator。
本篇文章不能給大家一個答案,官方網站上也未看到解釋,自己唯一可能的猜測是
1、__pool_alloc不利于使用者自定義operator new和operator delete(其實這條理由又被我自己推翻了,因為通過源碼可以知道置位_S_force_new即可解決)
2、malloc性能的提升以及硬件的更新導致使用默認的operator new即可。
如果大家有更好,更權威的答案請告訴我(peakflys@gmail.com)或者留言,謝謝。
by peakflys 16:49:49 Wednesday, January 14, 2015