我曾經(jīng)寫過一篇《談?wù)刄nicode編碼,簡要解釋UCS、UTF、BMP、BOM等名詞》(以下簡稱《談?wù)刄nicode編碼》),在網(wǎng)上流傳較廣,我也收到不少朋友的反饋。本文探討《談?wù)刄nicode編碼》中未介紹或介紹較少的代碼頁、Surrogates等問題,補(bǔ)充一些Unicode資料,順帶介紹一下我最近編寫的一個(gè)Unicode工具:UniToy。本文雖然是前文的補(bǔ)充,但在寫作上盡量做到獨(dú)立成篇。
標(biāo)題中的“淺談”是對(duì)自己的要求,我希望文字能盡量淺顯易懂。但本文還是假設(shè)讀者知道字節(jié)、16進(jìn)制,了解《談?wù)刄nicode編碼》中介紹過的字節(jié)序和Unicode的基本概念。
0 UniToy
UniToy是我編寫的一個(gè)小工具。通過UniToy,我們可以全方位、多角度地查看Unicode,了解Unicode和語言、代碼頁的關(guān)系,完成一些文字編碼的相關(guān)工作。本文的一些內(nèi)容是通過UniToy演示的。大家可以從我的網(wǎng)站(www.fmddlmyy.cn)下載UniToy的演示版本。1 文字的顯示
1.1 發(fā)生了什么?
我們首先以Windows為例來看看文字顯示過程中發(fā)生了什么。用記事本打開一個(gè)文本文件,可以看到文件包含的文字:
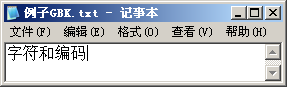
如果我們用UltraEdit或Hex Workshop查看這個(gè)文件的16進(jìn)制數(shù)據(jù),可以看到:
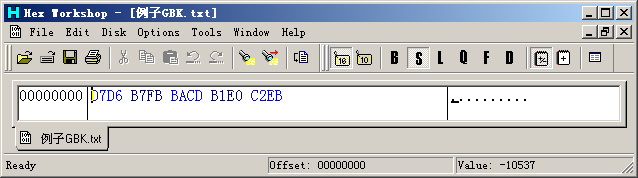
我們看到:文件“例子GBK.txt”有10個(gè)字節(jié),依次是“D7 D6 B7 FB BA CD B1 E0 C2 EB”,這就是記事本從文件中讀到的內(nèi)容。記事本是用來打開文本文件的,所以它會(huì)調(diào)用Windows的文本顯示函數(shù)將讀到的數(shù)據(jù)作為文本顯示。Windows首先將文本數(shù)據(jù)轉(zhuǎn)換到它內(nèi)部使用的編碼格式:Unicode,然后按照文本的Unicode去字體文件中查找字體圖像,最后將圖像顯示到窗口上。 總結(jié)一下前面的分析,文字的顯示應(yīng)該是這樣的:
- 步驟1:文字首先以某種編碼保存在文件中。
- 步驟2:Windows將文件中的文字編碼映射到Unicode。
- 步驟3:Windows按照Unicode在字體文件中查找字體圖像,畫到窗口上。
所謂編碼就是用數(shù)字表示字符,例如用D7D6表示“字”。當(dāng)然,編碼還意味著約定,即大家都認(rèn)可。從《談?wù)刄nicode編碼》中,我們知道Unicode也是一種文字編碼,它的特殊性在于它是由國際組織設(shè)計(jì),可以容納全世界所有語言文字。而我們平常使用的文字編碼通常是針對(duì)一個(gè)區(qū)域的語言、文字設(shè)計(jì),只支持特定的語言文字。例如:在上面的例子中,文件“例子GBK.txt”采用的就是GBK編碼。
如果上述3個(gè)步驟中任何一步發(fā)生了錯(cuò)誤,文字就不能被正確顯示,例如:
在Unicode被廣泛使用前,有多少種語言、文字,就可能有多少種文字編碼方案。一種文字也可能有多種編碼方案。那么我們?cè)趺创_定文本數(shù)據(jù)采用了什么編碼?
1.2 采用了哪種編碼?
按照慣例,文本文件中的數(shù)據(jù)都是文本編碼,那么它怎么表明自己的編碼格式?在記事本的“打開”對(duì)話框上:
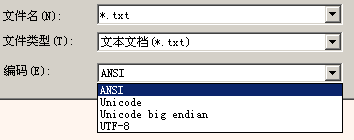
我們可以看到記事本支持4種編碼格式:ANSI、Unicode、Unicode big endian、UTF-8。如果讀者看過《談?wù)刄nicode編碼》,對(duì)Unicode、Unicode big endian、UTF-8應(yīng)該不會(huì)陌生,其實(shí)它們更準(zhǔn)確的名稱應(yīng)該是UTF-16LE(Little Endian)、UTF-16BE(Big Endian)和UTF-8,它們是基于Unicode的不同編碼方案。
在《談?wù)刄nicode編碼》中介紹過,Windows通過在文本文件開頭增加一些特殊字節(jié)(BOM)來區(qū)分上述3種編碼,并將沒有BOM的文本數(shù)據(jù)按照ANSI代碼頁處理。那么什么是代碼頁,什么是ANSI代碼頁?
2 代碼頁和字符集
2.1 Windows的代碼頁
2.1.1 代碼頁
代碼頁(Code Page)是個(gè)古老的專業(yè)術(shù)語,據(jù)說是IBM公司首先使用的。代碼頁和字符集的含義基本相同,代碼頁規(guī)定了適用于特定地區(qū)的字符集合,和這些字符的編碼。可以將代碼頁理解為字符和字節(jié)數(shù)據(jù)的映射表。
Windows為自己支持的代碼頁都編了一個(gè)號(hào)碼。例如代碼頁936就是簡體中文 GBK,代碼頁950就是繁體中文 Big5。代碼頁的概念比較簡單,就是一個(gè)字符編碼方案。但要說清楚Windows的ANSI代碼頁,就要從Windows的區(qū)域(Locale)說起了。
2.1.2 區(qū)域和ANSI代碼頁
微軟為了適應(yīng)世界上不同地區(qū)用戶的文化背景和生活習(xí)慣,在Windows中設(shè)計(jì)了區(qū)域(Locale)設(shè)置的功能。Local是指特定于某個(gè)國家或地區(qū)的一組設(shè)定,包括代碼頁,數(shù)字、貨幣、時(shí)間和日期的格式等。在Windows內(nèi)部,其實(shí)有兩個(gè)Locale設(shè)置:系統(tǒng)Locale和用戶Locale。系統(tǒng)Locale決定代碼頁,用戶Locale決定數(shù)字、貨幣、時(shí)間和日期的格式。我們可以在控制面板的“區(qū)域和語言選項(xiàng)”中設(shè)置系統(tǒng)Locale和用戶Locale:
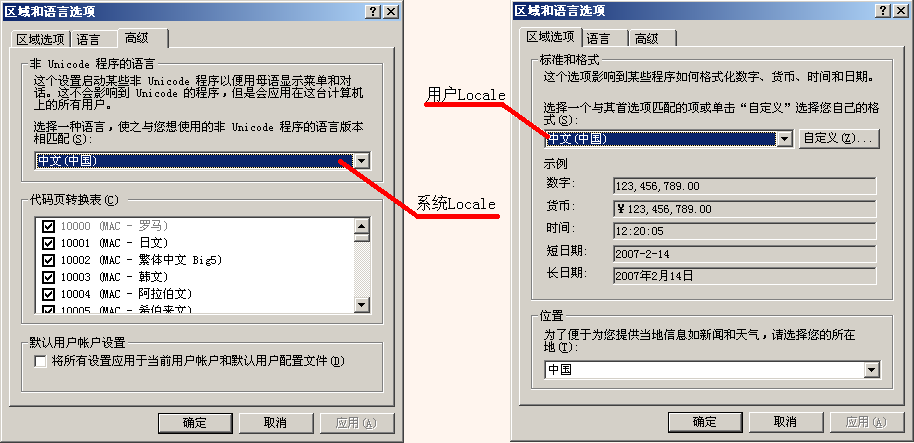
每個(gè)Locale都有一個(gè)對(duì)應(yīng)的代碼頁。Locale和代碼頁的對(duì)應(yīng)關(guān)系,大家可以參閱我的另一篇文章《談?wù)刉indows程序中的字符編碼》的附錄1。系統(tǒng)Locale對(duì)應(yīng)的代碼頁被作為Windows的默認(rèn)代碼頁。在沒有文本編碼信息時(shí),Windows按照默認(rèn)代碼頁的編碼方案解釋文本數(shù)據(jù)。這個(gè)默認(rèn)代碼頁通常被稱作ANSI代碼頁(ACP)。
ANSI代碼頁還有一層意思,就是微軟自己定義的代碼頁。在歷史上,IBM的個(gè)人計(jì)算機(jī)和微軟公司的操作系統(tǒng)曾經(jīng)是PC的標(biāo)準(zhǔn)配置。微軟公司將IBM公司定義的代碼頁稱作OEM代碼頁,在IBM公司的代碼頁基礎(chǔ)上作了些增補(bǔ)后,作為自己的代碼頁,并冠以ANSI的字樣。我們?cè)?#8220;區(qū)域和語言選項(xiàng)”高級(jí)頁面的代碼頁轉(zhuǎn)換表中看到的包含ANSI字樣的代碼頁都是微軟自己定義的代碼頁。例如:
- 874 (ANSI/OEM - 泰文)
- 932 (ANSI/OEM - 日文 Shift-JIS)
- 936 (ANSI/OEM - 簡體中文 GBK)
- 949 (ANSI/OEM - 韓文)
- 950 (ANSI/OEM - 繁體中文 Big5)
- 1250 (ANSI - 中歐)
- 1251 (ANSI - 西里爾文)
- 1252 (ANSI - 拉丁文 I)
- 1253 (ANSI - 希臘文)
- 1254 (ANSI - 土耳其文)
- 1255 (ANSI - 希伯來文)
- 1256 (ANSI - 阿拉伯文)
- 1257 (ANSI - 波羅的海文)
- 1258 (ANSI/OEM - 越南)
在UniToy中,我們可以按照代碼頁編碼順序查看這些代碼頁的字符和編碼:
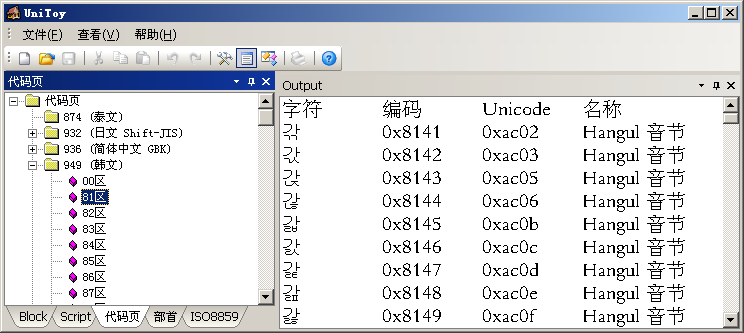
我們不能直接設(shè)置ANSI代碼頁,只能通過選擇系統(tǒng)Locale,間接改變當(dāng)前的ANSI代碼頁。微軟定義的Locale只使用自己定義的代碼頁。所以,我們雖然可以通過“區(qū)域和語言選項(xiàng)”中的代碼頁轉(zhuǎn)換表安裝很多代碼頁,但只能將微軟的代碼頁作為系統(tǒng)默認(rèn)代碼頁。
2.1.3 代碼頁轉(zhuǎn)換表
在Windows 2000以后,Windows統(tǒng)一采用UTF-16作為內(nèi)部字符編碼。現(xiàn)在,安裝一個(gè)代碼頁就是安裝一張代碼頁轉(zhuǎn)換表。通過代碼頁轉(zhuǎn)換表,Windows既可以將代碼頁的編碼轉(zhuǎn)換到UTF-16,也可以將UTF-16轉(zhuǎn)換到代碼頁的編碼。代碼頁轉(zhuǎn)換表的具體實(shí)現(xiàn)可以是一個(gè)以nls為后綴的數(shù)據(jù)文件,也可以是一個(gè)提供轉(zhuǎn)換函數(shù)的動(dòng)態(tài)鏈接庫。有的代碼頁是不需要安裝的。例如:Windows將UTF-7和UTF-8分別作為代碼頁65000和代碼頁65001。UTF-7、UTF-8和UTF-16都是基于Unicode的編碼方案。它們之間可以通過簡單的算法直接轉(zhuǎn)換,不需要安裝代碼頁轉(zhuǎn)換表。
在安裝過一個(gè)代碼頁后,Windows就知道怎樣將該代碼頁的文本轉(zhuǎn)換到Unicode文本,也知道怎樣將Unicode文本轉(zhuǎn)換成該代碼頁的文本。例如:UniToy有導(dǎo)入和導(dǎo)出功能。所謂導(dǎo)入功能就是將任一代碼頁的文本文件轉(zhuǎn)換到Unicode文本;導(dǎo)出功能就是將Unicode文本轉(zhuǎn)換到任一指定的代碼頁。這里所說的代碼頁就是指系統(tǒng)已安裝的代碼頁:
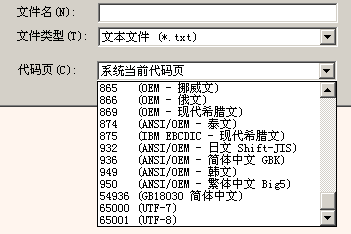
其實(shí),如果全世界人民在計(jì)算機(jī)剛發(fā)明時(shí)就統(tǒng)一采用Unicode作為字符編碼,那么代碼頁就沒有存在的必要了。可惜在Unicode被發(fā)明前,世界各國人民都發(fā)明并使用了各種字符編碼方案。所以,Windows必須通過代碼頁支持已經(jīng)被廣泛使用的字符編碼。從這種意義看,代碼頁主要是為了兼容現(xiàn)有的數(shù)據(jù)、程序和習(xí)慣而存在的。
2.1.4 SBCS、DBCS和MBCS
SBCS、DBCS和MBCS分別是單字節(jié)字符集、雙字節(jié)字符集和多字節(jié)字符集的縮寫。SBCS、DBCS和MBCS的最大編碼長度分別是1字節(jié)、兩字節(jié)和大于兩字節(jié)(例如4或5字節(jié))。例如:代碼頁1252 (ANSI-拉丁文 I)是單字節(jié)字符集;代碼頁936 (ANSI/OEM-簡體中文 GBK)是雙字節(jié)字符集;代碼頁54936 (GB18030 簡體中文)是多字節(jié)字符集。
單字節(jié)字符集中的字符都用一個(gè)字節(jié)表示。顯然,SBCS最多只能容納256個(gè)字符。
雙字節(jié)字符集的字符用一個(gè)或兩個(gè)字節(jié)表示。那么我們從文本數(shù)據(jù)中讀到一個(gè)字節(jié)時(shí),怎么判斷它是單字節(jié)字符,還是雙字節(jié)字符的首字符?答案是通過字節(jié)所處范圍來判斷。例如:在GBK編碼中,單字節(jié)字符的范圍是0x00-0x80,雙字節(jié)字符首字節(jié)的范圍是0x81到0xFE。我們順序讀取字節(jié)數(shù)據(jù),如果讀到的字節(jié)在0x81到0xFE內(nèi),那么這個(gè)字節(jié)就是雙字節(jié)字符的首字節(jié)。GBK定義雙字節(jié)字符的尾字節(jié)范圍是0x40到0x7E和0x80到0xFE。
GB18030是多字節(jié)字符集,它的字符可以用一個(gè)、兩個(gè)或四個(gè)字節(jié)表示。這時(shí)我們又如何判斷一個(gè)字節(jié)是屬于單字節(jié)字符,雙字節(jié)字符,還是四字節(jié)字符?GB18030與GBK是兼容的,它利用了GBK雙字節(jié)字符尾字節(jié)的未使用碼位。GB18030的四字節(jié)字符的第一字節(jié)的范圍也是0x81到0xFE,第二字節(jié)的范圍是0x30-0x39。通過第二字節(jié)所處范圍就可以區(qū)分雙字節(jié)字符和四字節(jié)字符。GB18030定義四字節(jié)字符的第三字節(jié)范圍是0x81到0xFE,第四字節(jié)范圍是0x30-0x39。
2.2 代碼頁實(shí)例
2.2.1 實(shí)例一:GB18030代碼頁
1.1節(jié)的“錯(cuò)誤2”中演示了一個(gè)全被顯示成'?'的文件。這個(gè)文件的數(shù)據(jù)是:
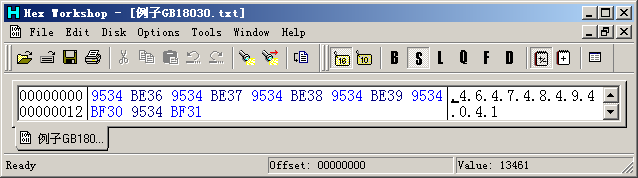
其實(shí),這是一個(gè)包含了6個(gè)四字節(jié)字符的GB18030編碼的文件。記事本按照GBK顯示這些數(shù)據(jù),而GB18030的四字節(jié)字符編碼在GBK中是未定義的。Windows根據(jù)首字節(jié)范圍判斷出12個(gè)雙字節(jié)字符,然后因?yàn)檎也坏狡ヅ涞霓D(zhuǎn)換而將其映射到默認(rèn)字符'?'。使用UniToy按照GB18030代碼頁導(dǎo)入這個(gè)文件,就可以看到:
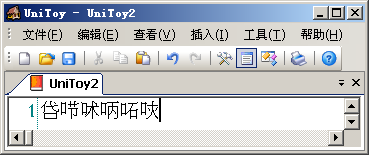
這個(gè)GB18030編碼的文件是用UniToy創(chuàng)建的,編輯Unicode文本,然后導(dǎo)出到GB18030編碼格式。
2.2.2 實(shí)例二:GBK和Big5的轉(zhuǎn)換
綜合使用UniToy的導(dǎo)入、導(dǎo)出功能就可以在任意兩個(gè)代碼頁之間轉(zhuǎn)換文本。其實(shí),由于各代碼頁支持的字符范圍不同,我們一般不會(huì)直接在代碼頁間轉(zhuǎn)換文本。例如將以下GBK編碼的文本:
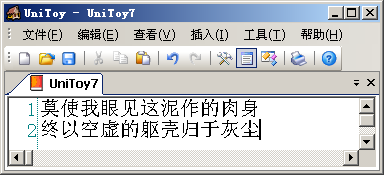
直接轉(zhuǎn)換到Big5編碼,就會(huì)看到:
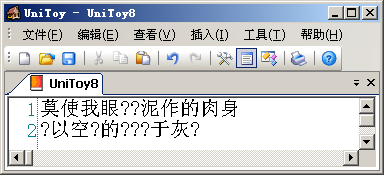
變成'?'的字符都是Big5編碼不支持的簡化字。在從Unicode轉(zhuǎn)換到Big5編碼時(shí),由于Big5編碼不支持這些字符,Windows就用默認(rèn)字符'?'代替。在UniToy中,我們可以先將簡體字轉(zhuǎn)換到繁體字,然后再導(dǎo)出到Big5編碼,就可以正常顯示:
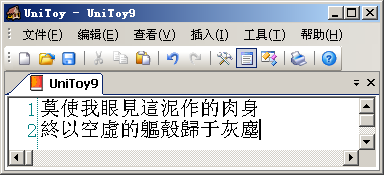
同理,將Big5編碼的文本轉(zhuǎn)換到GBK編碼的步驟應(yīng)該是:
- 將Big5編碼的文本導(dǎo)入到Unicode文本;
- 將繁體的Unicode文本轉(zhuǎn)換簡體的Unicode文本;
- 將簡體的Unicode文本導(dǎo)出到GBK文本。
2.3 互聯(lián)網(wǎng)的字符集
2.3.1 字符集
互聯(lián)網(wǎng)上的信息繽紛多彩,但文本依然是最重要的信息載體。html文件通過標(biāo)記表明自己使用的字符集。例如:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
或者:
<meta http-equiv="charset" content="iso-8859-1">
那么我們可以使用哪些字符集(charset)呢?在IETF(互聯(lián)網(wǎng)工程任務(wù)組)的網(wǎng)頁上維護(hù)著一份可以在互聯(lián)網(wǎng)上使用的字符集的清單:CHARACTER SETS。如果有新的字符集被登記,IETF會(huì)更新這份文檔。
簡單瀏覽一下,2006年12月7日的版本列出了253個(gè)字符集。其中也包括微軟的CP1250 ~ CP1258,在這里它們不會(huì)被稱作什么ANSI代碼頁,而是被簡單地稱作windows-1250、windows-1251等。其實(shí)在Unicode被廣泛使用前,除了中日韓等大字符集,世界上,特別是西方使用最廣泛的字符集應(yīng)該是ISO 8859系列字符集。
2.3.2 ISO 8859系列字符集
ISO 8859系列字符集是歐洲計(jì)算機(jī)制造商協(xié)會(huì)(ECMA)在上世紀(jì)80年代中期設(shè)計(jì),并被國際標(biāo)準(zhǔn)化(ISO)組織采納為國際標(biāo)準(zhǔn)。ISO 8859系列字符集目前有15個(gè)字符集,包括:
- ISO 8859-1 大部分的西歐語系,例如英文、法文、西班牙文和德文等(Latin-1)
- ISO 8859-2 大部分的中歐和東歐語系,例如捷克文、波蘭文和匈牙利文等(Latin-2)
- ISO 8859-3 歐洲東南部和其它各種文字(Latin-3)
- ISO 8859-4 斯堪的那維亞和波羅的海語系(Latin-4)
- ISO 8859-5 拉丁文與斯拉夫文(俄文、保加利亞文等)
- ISO 8859-6 拉丁文與阿拉伯文
- ISO 8859-7 拉丁文與希臘文
- ISO 8859-8 拉丁文與希伯來文
- ISO 8859-9 為土耳其文修正的Latin-1(Latin-5)
- ISO 8859-10 拉普人、北歐與愛斯基摩人的文字(Latin-6)
- ISO 8859-11 拉丁文與泰文
- ISO 8859-13 波羅的海周邊語系,例如拉脫維亞文等(Latin-7)
- ISO 8859-14 凱爾特文,例如蓋爾文、威爾士文等(Latin-8)
- ISO 8859-15 改進(jìn)的Latin-1,增加遺漏的法文、芬蘭文字符和歐元符號(hào)(Latin-9)
- ISO 8859-16 羅馬尼亞文(Latin-10)
其中缺少的編號(hào)12據(jù)說是為了預(yù)留給天城體梵文字母(Deva-nagari)的。印地文和尼泊爾文都使用了這種在七世紀(jì)形成的字母表。由于印度定義了自己的編碼ISCII(Indian Script Code for Information Interchange),所以這個(gè)編號(hào)就未被使用。ISO 8859系列字符集都是單字節(jié)字符集,即只使用0x00-0xFF對(duì)字符編碼。
大家都知道ASCII吧,那么大家知道ANSI X3.4和ISO 646嗎?在1968年發(fā)布的ANSI X3.4和1972年發(fā)布的ISO 646就是ASCII編碼,只不過是不同組織發(fā)布的。絕大多數(shù)字符集都與ASCII編碼保持兼容,ISO 8859系列字符集也不例外,它們的0x00-0x7f都與ASCII碼保持一致,各字符集的不同之處在于如何利用0x80-0xff的碼位。使用UniToy可以查看ISO 8859系列所有字符集的編碼,例如:
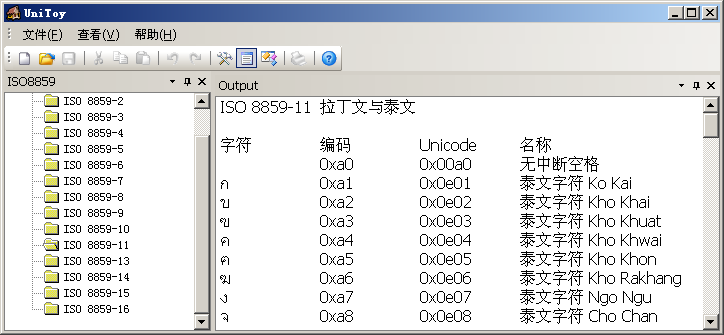
通過這些演示,大家是不是覺得代碼頁和字符集都是很簡單、樸實(shí)的東西呢?好,在進(jìn)入U(xiǎn)nicode的話題前,讓我們先看一個(gè)很深?yuàn)W的概念。