一直都隱隱約約的感覺(jué)TIM的網(wǎng)絡(luò)模型還是有點(diǎn)問(wèn)題,但卻總說(shuō)不出具體問(wèn)題來(lái)。時(shí)不時(shí)就會(huì)想起這個(gè)事,今天在車(chē)上,終于恍然大悟。
也許是受wildfire和jabberd2的影響太深了(特別是wildfire),TIM中網(wǎng)絡(luò)和業(yè)務(wù)處理的聯(lián)系過(guò)于緊密,從套接口讀到數(shù)據(jù)流后,馬上就進(jìn)入XML的PullParser分析階段,雖然之后有刻意的分離網(wǎng)絡(luò)操作和業(yè)務(wù)邏輯,但并不徹底。
有時(shí)候業(yè)務(wù)處理還是能夠感覺(jué)到網(wǎng)絡(luò)的存在,我覺(jué)得這是個(gè)不良的設(shè)計(jì)。
讓我耿耿于懷的,是Reactor的單線程特性。或許在某些情況下這是它的優(yōu)勢(shì),但運(yùn)用不當(dāng),就會(huì)成劣勢(shì)。現(xiàn)在的TIM把業(yè)務(wù)邏輯和網(wǎng)絡(luò)IO都擠進(jìn)了Reactor所控制的線程中,只要存在一點(diǎn)點(diǎn)的阻塞,吞吐率將大打折扣。
wildfire敢把網(wǎng)絡(luò)和業(yè)務(wù)綁得那么緊,是因?yàn)樗捎玫膒er-request,per-thread的模型,網(wǎng)絡(luò)IO引起的阻塞不會(huì)影響到其他request處理。我也沒(méi)有wildfire那么大的膽子采用per-request,per-thread,上下文切換的消耗不說(shuō),畢竟線程的數(shù)量也是有限制的,我很懷疑到底能承受多少連接數(shù),如果沒(méi)有記錯(cuò),Linux沒(méi)有重編譯內(nèi)核,一個(gè)進(jìn)程內(nèi)最多是1024個(gè)線程,Windows能多些,好像是65535,數(shù)據(jù)可能不準(zhǔn)確,但也說(shuō)明了線程資源是有限的。同時(shí),WFMOReactor在Windows下每個(gè)線程內(nèi)可同時(shí)監(jiān)視的句柄數(shù)(62個(gè)),也似乎太少了,這點(diǎn)也讓我煩惱。
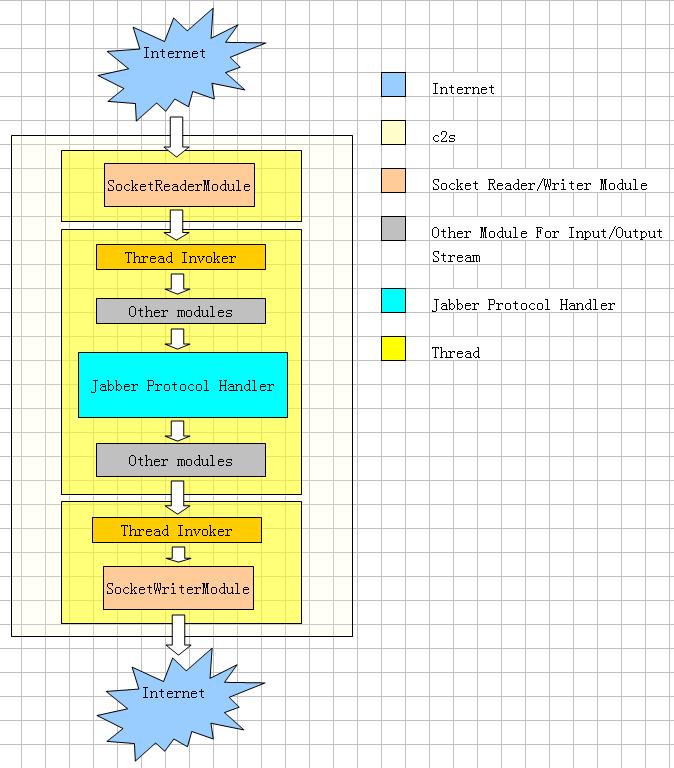
仔細(xì)推敲后,我認(rèn)為還是把網(wǎng)絡(luò)和業(yè)務(wù)完全脫離比較好一點(diǎn),用至少一個(gè)線程專(zhuān)門(mén)操作套接口,突破WaitForMultipleObjects的句柄數(shù)限制,再用另外一個(gè)線程來(lái)完成業(yè)務(wù)。在業(yè)務(wù)線程上使用管道過(guò)濾器模式來(lái)一步一步的處理數(shù)據(jù)。當(dāng)Reactor線程接收到數(shù)據(jù)后,放進(jìn)MessageBlock里面,用Task框架來(lái)處理。
這種模型確實(shí)解決了原先的諸多毛病,但如果在這個(gè)時(shí)候改網(wǎng)絡(luò)模型,對(duì)整個(gè)項(xiàng)目是個(gè)不小的沖擊,極有可能導(dǎo)致在計(jì)劃的時(shí)間內(nèi)不能完成項(xiàng)目。猶豫了一下,為了保證品質(zhì),最終還是在SubVersion上創(chuàng)建了新的試驗(yàn)分支。