#
基本網絡框架基于IOCP模型,這次主要在以前寫的IPC通信的基礎上修改,參考了當前項目網絡庫的設計思路。
先介紹幾個主要的類:
1.CSocket重新套接字,CConnection繼承CSocket表示一個連接對象主要重寫Recv和Send接口,以及組包過程。
2.CAccept處理客戶端的鏈接,
3.Cpacket一個消息數據包頭,CMessage繼承CPacket帶數據消息包。
4.CConnectManger保存一個連接CConnection的內存池對象,CAcceptManager一個接收客戶端Accept的線程,CPacketManager參考了Loki的小對象管理做的一個緩沖區數據包內存池。
5.CLibObject包含上面3個Manager(Singleton),CNetWork網絡初始化。
6.CIOCP類主要IO的線程類,接收處理所有的客戶端連接CConnection。
7.CServer類包括一個IOCP初始化和網絡庫管理類,IOCP會把接收到的數據重組成數據包后保存到CServer的一個CMsgQueue中.
8.我們的重寫一個Server只需要繼承CServer,然后實現run和AccedeProcess即可。run從CMsgQueue緩沖區提取一個消息包,AccedeProcess處理消息。
一些細節設計:
1.為了節約帶寬Connection這里采用了Negles算法,這里采用Negle的并沒有馬上把每一個需要發送MSG采用緩存隊列的方式保存起來,而是每一個Connection自身都保存數據,CServer通過一個線程把每一個存在的Connection是否有消息緩存,然后發送。因而讓IOCP只處理接收的消息,發送消息通過CServer來處理。
出網絡庫基本框架如下:
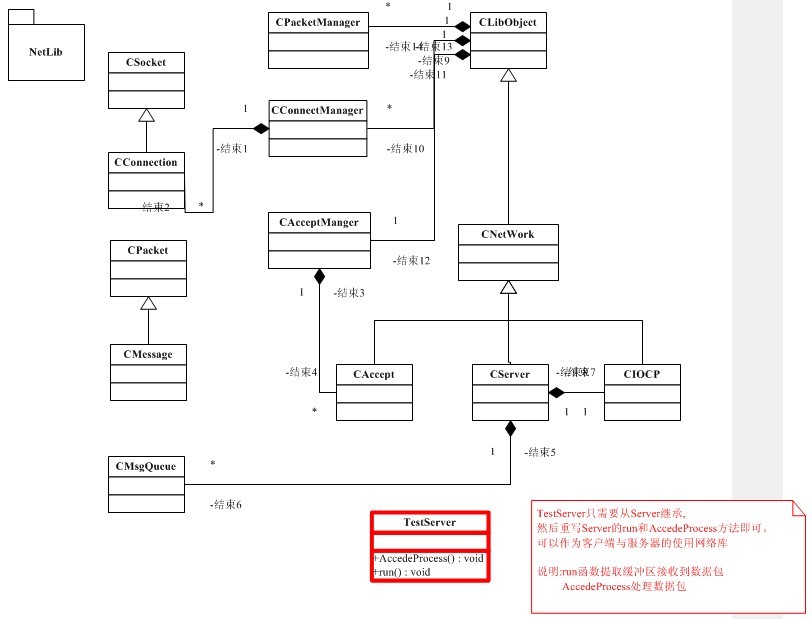
網絡庫代碼的代碼http://code.google.com/p/tpgame/source/browse/#svn/trunk/GServerEngine/NetLibrary
問題肯定較多,希望多多指教。
最近一直在構思與寫一套游戲AI系統,主要是通過狀態機響應事件,更多是想運用自己學習到的一些優秀的算法,以及一些高級
的AI以此來鍛煉對一些復雜的數據結構的編寫和設計思維的提升。
算法和數據結構方面:
1.2D和3D尋路(主要包括2D尋路的初始化條件優化 ,3D的空間劃分以及多叉樹的劃分,以及堆維護)。
2.帶有更多思維的角色系統(附帶更多的數據信息)判斷。
3.查詢線段樹和樹狀數數組的運用。
4.一個線性的字符串過濾程序。
5.一個動態基于角色的最優二叉查找樹的動態維護。(主要解決不同的角色AI觸發頻率建立一顆最優二叉查找樹)
6.追蹤算法以及游戲的群集算法都會整合到現在的AI系統中。
設計方面:
1.盡量讓類之間耦合性更小,復雜度更低,淺顯明確。
注:Ai系統寫完會把代碼和網絡庫的最新代碼更新都會上傳,希望大家多多指教。
最近做一個東西正好需要生成字典的算法,類似一些密碼字典生成器(主要運用在暴力破解)。生成的密碼會根據密碼長度與字典集合的長度成指數關系。
可以用一個函數來表示
f( x , y ) = x ^y ; x表示我們要生產的密碼長度,y表示我們要生成的密碼字典字符集合。
當時想到就有3個算法。
1.循環
關于循環,可以參考水仙花數的多層嵌套求解,主要算法如下:
1
 /**//// Dict 為生成的密碼 , g_Dict為字典集合 2
/**//// Dict 為生成的密碼 , g_Dict為字典集合 2 for ( int i = 0 ; i < Len ; i++ )
for ( int i = 0 ; i < Len ; i++ )
3 {
{
4 Dict[0] = g_Dict[i];
Dict[0] = g_Dict[i];
5
6 for ( int j = 0 ; j < Len ; j++)
7
 {
{
8 Dict[1] = g_Dict[j];
9
10 for ( int k = 0 ; k < Len ; k++ )
11 {
12 Dict[2] = g_Dict[k];
13
14 /**//*
15 * 幾位密碼就嵌套幾層循環
16 */
*/
17
18 }
19 }
20 }
}
這種方式移植不好,而且代碼臃腫。
2.遞歸
做過字符串的全排列的都明白這個算法,這種也是基于這種方式:但是由于隨著字典集合或者密碼長度的增加,很容易會出現堆棧的內存溢出。
1void solve(int len,int p , int s,int n)
2{
3 int i;
4 if( s == n )
5 {
6 /**////std::cout << Dict << std::endl;
7 return ;
8 }
9 if(s>n||p>n)
10 return;
11 for( i=p ; i < len ; i++ )
12 {
13 solve(len,i+1,s+1,n);
14 }
15}
3.BFS
有了前2種方法的不錯,然后寫了一個非遞歸的算法
主要借用橫向掃描的方式,借鑒一個數組來進行記錄當前應該生成的密碼。
主要算法如下:
1/**//*
2* 生成字典的函數
3* @parm 需要生成的長度
4*/
5void MakeDict( int Len )
6{
7 char Dict[MaxDictLen+1]; // 生成的字典字符串
8 int Array[MaxDictLen]; // 記錄當前應該生成字典數組
9
10 memset( Array , 0 , sizeof(Array) );
11
12 bool bStop = true;
13
14 int i,j;
15 for ( ; bStop ; ) // 是否生成完畢
16 {
17 for ( i = 0 ; i < Len ; i++ )
18 {
19 Dict[i] = g_Dict[Array[i]];
20 }
21 Dict[Len] = '\0';
22
23 std::cout << Dict << std::endl;
24
25 /**//// 字典數組坐標更新
26 for ( j = Len - 1 ; j >= 0 ; j -- )
27 {
28 Array[j] ++ ;
29
30 if ( Array[j] != ((int)g_Dict.length()) )
31 {
32 break;
33 }
34 else
35 {
36 Array [j] = 0;
37 if( j == 0 ) // 生成完畢
38 bStop = false;
39 }
40 }
41 }
42}
附上第三個生成算法源碼:
link
問題描述如下:
2個整數(int32),我需要對這2個數的第n位進行二進制數交換值。是否有一個高效的算法,或者高效的運算。
例子如下:
2個整數10,7,把第1位的數值交換。
整數 二進制 交換后二進制 交換后的值
10 0x1010 0x1011 11
7 0x0111 0x0110 6
我的思路如下:
1.如果要對第n位數值交換,先求出第n位的值(1或者0),如果相等則不交換。
2.交換第n位,通過通過原理發現只需通過加減法運算即可,如果1->0 則減 1<<(n-1) ,否則加1<<(n-1)。
代碼如下:
1void prjfun( int & des , int & src , int n)
2{
3 if( n <= 0 ) return ;
4
5 int x = (des & (1<<(n-1))) >>(n-1); // 求出第n位的數值
6 int y = (src & (1<<(n-1))) >>(n-1); // 求出第n位的數值
7 if ( x != y )
8 {
9 des += (y-x)*(1<<(n-1)); // 交換
10 stc += (x-y)*(1<<(n-1)); // 交換
11 }
12}
是否有一種高效的算法,只是進行一,兩步位與或運算即可。。
關于游戲尋路,網絡上也有很多相關的文章,一般都是已A*為主,他只是一種啟發式搜索,最開始寫A*是在大三,主要還是做一個路徑搜索的算法。
關于游戲中A*的算法優化,由于在搜索的過程中會通過open表和close保存一些結點,為了加快查找效率一般采用對維護的方式,利用map的最小堆(按照估價值的大小排序)來構架數據結構。其實還可以利用線性的hash_map來創建維護。
而3D中游戲尋路也是采用同樣的方法,只是在不同于2D的8個方向搜索而是3*8個方向的搜索。所以他的復雜度之高,在對于一個3維的N*N*N的空間,他的搜索運算為n^3*24,就需要考慮算法中的優化。
總之一句3D尋路費時又費空間!
下面是我總結的優化
1.總體還是利用a*和堆維護。
2.由于點是實心,可以直接進行對角線的行走,也就是對角線行走一步后x,y,z的坐標都會改變,從而降低通過2次二維變換的過程。二步變一步!
3.利用凸包的方式來優化。
4.把一個場景的3D地圖全部細分,利用多叉樹進行管理。
關于凸包的優化可以通過這樣一個例子說明(因為在2D中更好的描述通過2維的地圖):
A、假設1要到2的,通過A*的搜索,他會先到0然后發現不能通過在回溯,重新尋找新的路徑,這樣可能浪費一些搜索時間。
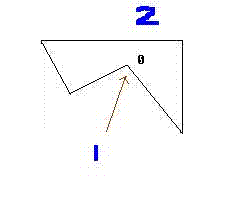
B. 可以通過多邊形的最小矩形凸包的方式,這樣就可以減少不必要的搜索,如圖所示。
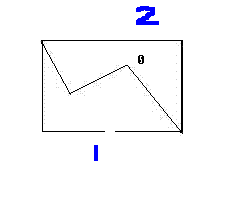
那么1到2就不會經過0點。。因為次區域設置為不可通過。
C. 如果我們要查找的點在我們凸包內,所以我們在尋路最開始應該驗證點是否在凸包內,如果在此區域內,在行走時不能過濾這個矩形空間。
注:游戲中地圖一般是不變的,所以這些都是不變,凸包已知,驗證點在凸包中也是線性的。
由于在計算3D的凸包的時候計算量大,最開始采用靜態的方式來記錄數據。
簡單的3D尋路算法源碼(不包含凸包優化):
/Files/expter/3DAStar.rar
所謂追蹤,相對于另外一個角色來說是逃跑,首先需要做出追和逃跑的決策判斷。
1.坐標追蹤
也是最基本追逐方式,他根據要追蹤對象的坐標來修改追蹤者的坐標,使兩者的距離逐漸縮短。
一個簡單的例子:
Point m_pPrey; /// 被追蹤者
Point m_pAtta; /// 追蹤者
對于追蹤者來說: 新位置 = 舊位置 + XY速度 ;
1if( m_pAtta.x < m_pPrey.x )
2 m_pAtta.x ++;
3else if( m_pAtta.x > m_pPrey.x )
4 m_pAtta.x --;
5
6
7if( m_pAtta.y < m_pPrey.y )
8 m_pAtta.y ++;
9else if( m_pAtta.y > m_pPrey.y )
10 m_pAtta.y --;
2.視線追蹤
視線追蹤方式,主要是描述每一時刻都追蹤者會沿著被追逐者之間的直線方向運動。如圖所示:
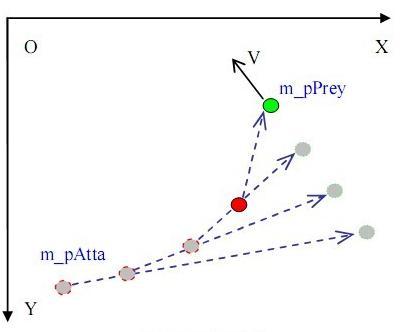
通過圖可以更好描述此問題,此問題的求解關鍵在于求出連接追蹤者與獵物之間的直線,可以通過向量知道:2個向量想減即可得到。
可以分別用追蹤者與獵物的位置坐標構造出兩個向量,假設b 代表追蹤者位置向量,a 代表獵物位置向量。做向量減法a-b 便得到了向量c,將c 的起點置于追蹤者的位置上,就得到了一條指向獵物的向量c. 此時,令:
追蹤者X 方向速度 / 追蹤者Y 方向速度 = c 向量x 軸分量/ c 向量y 軸分量 .即可求解。
3.攔截追蹤
所謂攔截追蹤,如果考慮的是被追逐的目標太遠,如果2者速度一樣,或者相差不大,有可能很難追上,玩過實況足球的都知道,如果采用上面的2中追逐方式,可能錯過最佳的防守位置。下面是攔截追蹤的一個示例圖:
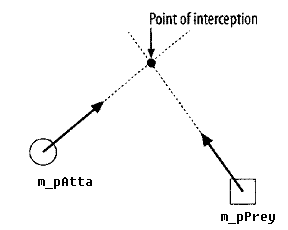
對于追蹤者來說,他只需要知道被追蹤者的位置,方向與速度,講會計算一個最佳的攔截位置。然后你會發現這只是一個簡單的追蹤問題。且需要的時間t最少。
整個3種追蹤的源碼代碼 以及 demo都共享:
/Files/expter/chase.rar
下一篇通過實例demo來記錄學習的聚類算法:
摘要: 定制自己的new 和 delete,讓對象在靜態塊上進行分配。
一般常見的new和delete操作符,就意味著使用堆進行內存分配,使用new操作符是名為operator new的函數調用,且函數返回返回一個指向某塊內存分配器分配內存指針。
對于內存的分配到底從哪兒來沒有任何限制,它可能來自一個特殊的堆,也可能來自一個靜態分配的塊,也可能來自一個標準容器內部,也可能來自某個函數范圍的局部存儲區。而對于現在的各自軟件中主流內存管理方式,一般通過內存池的管理方式,它可能即包含靜態分配也同時包含動態分配。
閱讀全文
在多線程過程中,對于線程間的數據共享同步問題,具體針對多線程需要對一個Vector進行讀與寫的操作,不考慮緩沖區的操作,一般情況下為了保證穩定性的同時在讀寫的時候都要進行加鎖,其實可以通過一個技巧,就是通過一個臨時變量在寫數據的時候把第一個值付給臨時變量,那么在讀取數據的線程中會直接讀取臨時變量,此時只需要加鎖一次即可。
我寫了一個測試例子,就是關于開3個讀,寫,刪的操作。。。一般情況進行加鎖,與通過通過臨時變量來減少一次加鎖速度與效率明顯低于后者。
針對1000000個數據的操作,操作1比操作2快2倍以上。
下面是我的測試代碼,簡單。。。只是為了說明問題
/Files/expter/l_thread.rar
摘要: 編譯DShow程序出現 無法打開包括文件:“dsound.h”
閱讀全文
摘要: 關于IE插件,關于BHO的彈出窗口
閱讀全文