今天工作情況依然~
早上收到Yu同學的反饋--取到空單詞。狠狠認真分析了一下其發來的數據,發現其數據跟我處理的有微小的差異,很是奇怪,懷疑是詞典版本或者Lingoes版本差異的問題。唉,把基礎建立在別人上面就有這樣的風險--別人微小的改動,會導致自己全部的垮掉。但,但難不成我也來寫個詞典?!算了,還是專心寫生詞本吧。。。
于是重新分析Lingoes的HTML數據,總結其結果的‘共性’,有點成果,明天整理下,希望可以提高取詞的成功率~
來,看看修正后的 Yu同學的數據,其是用German的,就簡單查了一個'versuchen'(我不認識,麻煩Yu同學解釋吧。。)結果,結果多的很可怕。。。
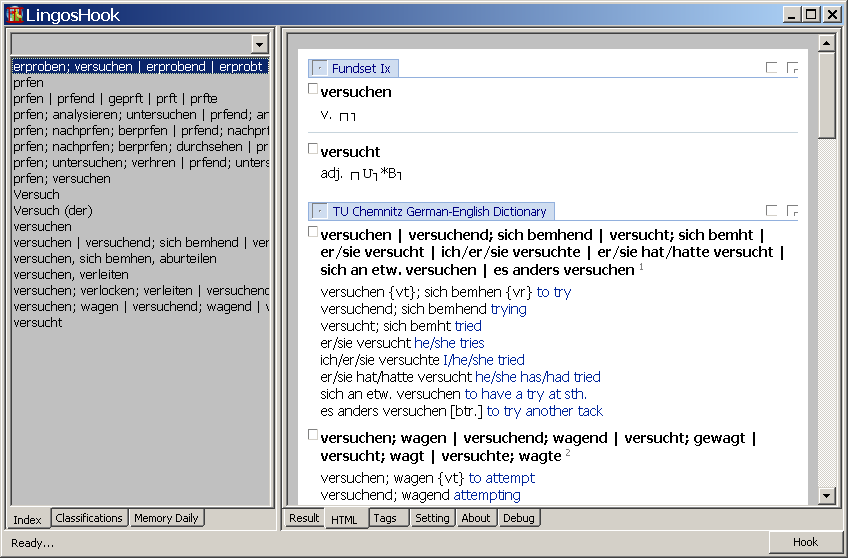
Yu同學很聰明,其只想兩個結果--Fundset詞典的結果,因此開啟‘Skip Html Dictionay ..'選項來禁止其它詞典的解析,只使用Fundset詞典結果,這招太強了,我都沒有想到,所以我才有這么多結果。但杯具的是--Fundset詞典解析失敗了,Yu同學只得到一個空單詞。。。不好意思啊。。。下個版本一定給你改好。。
這個結果也提示了應該快點實現HTML詞典解析配置部分了,目前HTML詞典在顯示上是可以配置的,但在解析上是不能指定解析哪個,不解析哪個的。在設計時,這個配置已經存在了,只是自己想來應該都希望能解析的越多越好,因此一直沒有實現,但上圖又一次刺激了我--不要自以為是。。。。