這幾天一個(gè)學(xué)生在調(diào)試視頻捕捉程序的時(shí)候遇到了一個(gè)問題。他使用capGetVideoFormat函數(shù)獲得視頻的格式時(shí),發(fā)現(xiàn)m_bmpinfo.bmiHeader.biBitCount為16,他認(rèn)為這是表示16位的RGB格式。可是不管他是使用RGB565,還是RGB555格式進(jìn)行轉(zhuǎn)換時(shí),發(fā)現(xiàn)轉(zhuǎn)換后的YUV文件都是不對(duì)的。在我的Sony筆記本上運(yùn)行他的程序,其中的m_bmpinfo.bmiHeader.biCompression的值為1498831189,這說明筆記本的攝像頭所采集的數(shù)據(jù)的格式并不是普通的16位RGB數(shù)據(jù),而是UYVY格式的。UYVY格式是YUV格式的一個(gè)變種,在網(wǎng)上可以找到詳細(xì)的說明,在此就不贅述了。
要想知道biCompression到底有多少種取值,可以參考一下:http://files.codes-sources.com/fichier.aspx?id=45735&f=src/org/hypik/webcamlib/codecs/Codecs.java。在這里詳細(xì)的列出了各種視頻壓縮的編碼。
怎樣才能知道自己的攝像頭到底支持哪種格式的輸出呢?可以使用capDlgVideoFormat函數(shù):
capDlgVideoFormat(m_wndVideo);
這個(gè)函數(shù)會(huì)激活攝像頭驅(qū)動(dòng)的視頻格式設(shè)置對(duì)話框,如下圖所示。
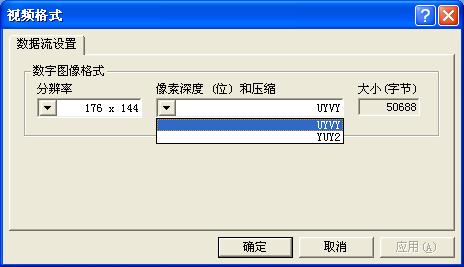
我的這個(gè)攝像頭支持2種輸出格式,一種是UYVY,另一種是YUV2。 如果將m_bmpinfo.bmiHeader.biCompression設(shè)置為這兩種之外的值,再使用capSetVideoFormat改變輸出格式,由于驅(qū)動(dòng)程序不支持而不會(huì)獲得成功。
posted @
2010-11-16 22:30 zealsoft 閱讀(1969) |
評(píng)論 (1) |
編輯 收藏
這兩天一直希望找個(gè)可以移植到VxWorks上的Log庫,早就知道大名鼎鼎的Log4c,但一直想找個(gè)更好的,本來看上了Pantheios,覺得它的架構(gòu)非常清晰,使用也很簡便,特別是其網(wǎng)站上宣傳它的性能非常卓越。但是仔細(xì)看了這個(gè)庫后發(fā)現(xiàn)這個(gè)庫基于STL和STLsoft,STL在VxWorks是很影響性能的,只好放棄。看看其他的Log庫,大多數(shù)都是基于C++的,對(duì)于嵌入式應(yīng)用還是不適合。我覺得一個(gè)理想的輕量級(jí)Log庫,最好具有以下特征:
- 完全用C編寫
- 核心模塊不依賴任何第3方的函數(shù)庫
- 可以動(dòng)態(tài)開關(guān)Log功能。當(dāng)關(guān)閉Log功能時(shí),所產(chǎn)生的開銷應(yīng)當(dāng)明顯小于打開Log功能。
- API接口清晰易用,就象printf一樣。
找了一圈,發(fā)現(xiàn)還是Log4c最合適。所以只好決定在Log4c的基礎(chǔ)上移植了,看來找到一個(gè)輕量級(jí)的Log庫不太容易。
posted @
2009-10-10 22:25 zealsoft 閱讀(3024) |
評(píng)論 (11) |
編輯 收藏
今天嘗試用Visual Studio 2005編譯以前用Visual Studio 2003編譯成功過的一個(gè)Wireshark插件,生成后發(fā)現(xiàn)居然無法在官方的Wireshark中加載插件。在 KenThompson的“Creating Your Own Custom Wireshark Dissector”一文中提到使用Visual Studio 2005編譯生成的插件只能在使用Visual Studio 2005生成的Wireshark版本中測(cè)試。使用自己采用Visual Studio 2005生成的Wireshark版本測(cè)試,發(fā)現(xiàn)確實(shí)可以,而官方的就不行了。使用Dependency Walker看了看,發(fā)現(xiàn)使用Visual Studio 2005生成的DLL文件需要使用MSVCR80.DLL,而官方的Wireshark使用的是MSVCRT.DLL,兩者不兼容,所以會(huì)出現(xiàn)錯(cuò)誤。在微軟的網(wǎng)站上可以找到解決的方法:
mt.exe –manifest MyLibrary.dll.manifest -outputresource:MyLibrary.dll;2
將這樣處理后的DLL再拷貝到官方的Wireshark的插件目錄中就可以了。不過采用Visual Studio 2005生成的插件要分發(fā)時(shí)必須同時(shí)分發(fā)Visual Studio 2005的C語言運(yùn)行庫,看來不如Visual Studio 2003方便。
posted @
2009-04-24 23:26 zealsoft 閱讀(2836) |
評(píng)論 (4) |
編輯 收藏
今天甲方通知要統(tǒng)計(jì)一下我們協(xié)議棧代碼的行數(shù),好久沒有關(guān)心過這樣的問題,上一次統(tǒng)計(jì)代碼行數(shù)好像是好多年前的事情了,也忘記了用的什么工具。最開始想用NLOC,因?yàn)樾枰?NET 2.0,我的機(jī)器裝不上。為了這個(gè)工具安裝.NET 2.0有點(diǎn)不劃算。又找了一個(gè)C++編寫的工具Code Counter Tool。這個(gè)工具可以支持Visual C++ 6.0的工程。不過我們的工程是VxWorks工程,對(duì)于非VC6的工程需要建立一個(gè).map文件,里面包括所有需要統(tǒng)計(jì)的文件。這個(gè)工作可以在命令行中完成:
dir /b > prj.map
其中的/b參數(shù)表示只顯示文件名,dir的結(jié)果會(huì)寫入prj.map文件,正好可以滿足要求。
最后的統(tǒng)計(jì)結(jié)果表明,我們的協(xié)議棧有109個(gè)文件(不包括需要的運(yùn)行庫),共161,688行代碼,其中空白行13,554,注釋行為38,311。這是一個(gè)小巧的,但是完整的基站協(xié)議棧代碼。
posted @
2009-01-22 16:30 zealsoft 閱讀(1284) |
評(píng)論 (1) |
編輯 收藏
因?yàn)門ETRA標(biāo)準(zhǔn)中分組數(shù)據(jù)的壓縮協(xié)議為V.42 bis,讓學(xué)生在網(wǎng)上找個(gè)代碼來用。學(xué)生找了半天,只找到LZW的代碼,沒有找到V.42bis,雖然兩者差別較少,但是還是不同的,只好自己找。其實(shí)找起來很容易,在
Google CodeSearch上輸入v42bis就找到了。找到的是
SpanDSP這個(gè)庫中的一個(gè)文件,寫得很清晰,注釋也比較全。SpanDSP是一個(gè)專用于電話領(lǐng)域的信號(hào)處理庫,包括各種語音編碼、采用的協(xié)議處理等等,象項(xiàng)目中用到的
HDLC協(xié)議在這里也可以找到。在查找代碼方面,Google CodeSearch比直接使用Google方便多了。
posted @
2009-01-21 22:07 zealsoft 閱讀(1293) |
評(píng)論 (0) |
編輯 收藏
最近太太的學(xué)校使用思維導(dǎo)圖總結(jié)教學(xué)中的知識(shí)點(diǎn),她因?yàn)殡娔X不熟,我?guī)土讼旅ΓY(jié)果發(fā)現(xiàn)這個(gè)思維導(dǎo)圖真的很方便!今天用思維導(dǎo)圖整理了一下項(xiàng)目的知識(shí)體系,為下一步安排學(xué)生課題、申請(qǐng)專利和發(fā)表文章做準(zhǔn)備。由于課題內(nèi)容比較敏感,下面用一些簡單的例子代替實(shí)際做的工程。
使用思維導(dǎo)圖的最大好處是方便,只要使用Enter鍵就可以添加一個(gè)節(jié)點(diǎn),而使用Tab鍵就可以添加一個(gè)子節(jié)點(diǎn),如果發(fā)現(xiàn)節(jié)點(diǎn)的層次或順序不對(duì),可以隨意地拖動(dòng)節(jié)點(diǎn)進(jìn)行調(diào)整,一起都很方便,不象Visio或者SmartDraw,必須點(diǎn)幾下鼠標(biāo)才能完成這些操作。你可以想到哪里,就畫到哪里,特別適合邊思考,邊整理,比在紙上比劃還方便。下面就是一個(gè)簡單的例子。
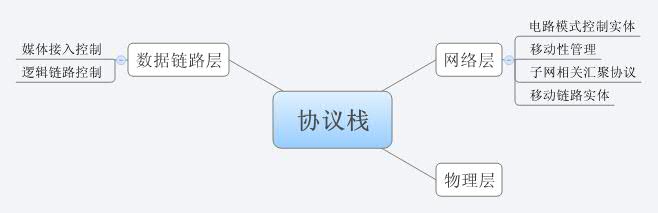
以前我整理項(xiàng)目的知識(shí)體系,往往使用SmartDraw(Visio在這方面比SmartDraw更難使)。使用SmartDraw,一是操作比思維導(dǎo)圖麻煩,二是如果圖太大了,為了便于閱讀,就必須將體系結(jié)構(gòu)圖按照層次分割成很多文件,然后利用SmartDraw的鏈接功能將它們鏈接到一起。而在思維導(dǎo)圖中,這一切就變得很容易。你可以在一張圖中畫下所有層次關(guān)系,如果覺得層次多了,可以用鼠標(biāo)點(diǎn)下節(jié)點(diǎn)右側(cè)“減號(hào)”,就可以把子節(jié)點(diǎn)都收起來,象下圖一樣。如果想看子節(jié)點(diǎn),再點(diǎn)一下節(jié)點(diǎn)右側(cè)“加號(hào)”就可以,收縮自如,非常方便。

有時(shí)候子節(jié)點(diǎn)太多,希望在一個(gè)單獨(dú)的窗口中編輯或顯示,可以選擇Drill down功能,它可以把所有子節(jié)點(diǎn)都顯示在一個(gè)單獨(dú)的窗口中,而選擇Drill up功能又可以回到頂層。這樣既可以方便地觀察全局,又可以照顧導(dǎo)細(xì)節(jié),比SmartDraw/Visio方便多了。
其實(shí)最早接觸思維導(dǎo)圖,是前段時(shí)間在廣州,七所的吳挺用MindMap制作了一個(gè)項(xiàng)目的進(jìn)度表,每個(gè)節(jié)點(diǎn)前可以加上Marker清晰地看出每個(gè)項(xiàng)目進(jìn)展的情況,象下面這張圖一樣。不過當(dāng)時(shí)誤以為這個(gè)軟件是類似Visio或者Project那樣的軟件,沒有重視,現(xiàn)在才發(fā)現(xiàn)完全不是那么回事。
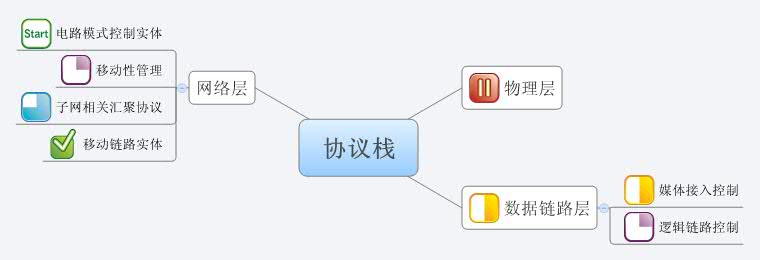
在網(wǎng)上搜索了一下,對(duì)思維導(dǎo)圖的介紹還真是很多,可惜我今天才用上。我推薦百度百科的相關(guān)介紹,值得一讀。
支持思維導(dǎo)圖的軟件很多,前面的博客已經(jīng)說了,我要盡量使用開源軟件。在網(wǎng)上真找到一款相當(dāng)不錯(cuò)的:XMind。
posted @
2008-12-11 23:29 zealsoft 閱讀(3607) |
評(píng)論 (7) |
編輯 收藏
Google CTemplate提供了調(diào)節(jié)器(Modifier)功能。所謂調(diào)節(jié)器,類似于在模板中可以使用的用戶自定義函數(shù),也就是對(duì)于相同的數(shù)據(jù)字典內(nèi)容,模板中使用不同的調(diào)節(jié)器就可以顯示不同的內(nèi)容。
要編寫一個(gè)調(diào)節(jié)器,需要從template_modifiers::TemplateModifier派生一個(gè)類:

 Code
Code
class BitStringModifier : public template_modifiers::TemplateModifier {
void Modify(const char* in, size_t inlen,
const ctemplate::PerExpandData* per_expand_data,
ExpandEmitter* outbuf, const std::string& arg) const;
};
BitString 調(diào)節(jié)器的作用是將數(shù)值型數(shù)據(jù)轉(zhuǎn)換為二進(jìn)制字符串顯示。其在模板中的使用如下所示:
bstr = bstr + '{{item_type3id:x-bitstring=4}}'b;
用戶自定義的調(diào)節(jié)器一般采用“x-”開頭。調(diào)節(jié)器可以帶有用戶參數(shù),例如上例的“=4”就是用戶參數(shù),表示生成的二進(jìn)制串的長度為4,如果不足4位,前面自動(dòng)補(bǔ)0。
調(diào)節(jié)器的主要功能是在Modify函數(shù)中實(shí)現(xiàn)的,在該函數(shù)中調(diào)用outbuf->Emit函數(shù)來輸出所需要的結(jié)果。
Code
void BitStringModifier::Modify(const char* in, size_t inlen,
const ctemplate::PerExpandData* per_expand_data,
ExpandEmitter* outbuf, const std::string& arg) const
{
int x = atoi(string(in, inlen).c_str());
unsigned int len = atoi(arg.c_str() + 1);
string sID = itoa(x, 2);
while(sID.size() < len)
sID = "0" + sID;
outbuf->Emit(sID);
}
要在程序中支持調(diào)節(jié)器,還需要調(diào)用google::template_modifiers::AddModifier函數(shù)添加BitStringModifier的實(shí)例。如:
Code
BitStringModifier bitStringModifier;
/// 注冊(cè)自定義的Modifier
google::template_modifiers::AddModifier("x-bitstring=", &bitStringModifier);
posted @
2008-10-15 22:03 zealsoft 閱讀(1511) |
評(píng)論 (0) |
編輯 收藏
TAU G2程序本身的仿真功能很強(qiáng),如果程序在目標(biāo)機(jī)上運(yùn)行時(shí)出現(xiàn)邏輯錯(cuò)誤,你總是可以在TAU G2的仿真環(huán)境下模擬出這個(gè)錯(cuò)誤并找到出錯(cuò)的原因,一般不需要借助操作系統(tǒng)的C代碼調(diào)試工具。但是如果是在TAU G2中調(diào)用了C語言的函數(shù),或者在環(huán)境函數(shù)中出現(xiàn)錯(cuò)誤,問題就復(fù)雜了,因?yàn)門AU G2的仿真環(huán)境無法跟蹤這些C語言的代碼,你只能借助操作系統(tǒng)自身的調(diào)試功能了。
TAU G2生成的程序至少是2個(gè)線程:一個(gè)是主線程,就是main函數(shù)所在的線程,象環(huán)境函數(shù)中的xInitEnv和xInEnv都是在主線程中的,主線程設(shè)置斷點(diǎn)很容易,只要在啟動(dòng)調(diào)試器后,使用Debug菜單中的Toggle Breakpoint(F9)就可以了,因?yàn)檎{(diào)試器默認(rèn)就是把主線程當(dāng)作當(dāng)前線程的;另一個(gè)線程是UML代碼所在的線程,通常你不需要在生成的UML代碼中設(shè)置斷點(diǎn),但是xOutEnv在這個(gè)線程中,而且如果在UML代碼中調(diào)用了C語言的函數(shù),那么這些C語言的函數(shù)也在這個(gè)線程中,而在這個(gè)線程中如果還是用F9直接設(shè)置斷點(diǎn)就往往不會(huì)成功了,程序往往不會(huì)停下來而是繼續(xù)執(zhí)行。
要想在xOutEnv或者自己編寫的C語言函數(shù)中設(shè)置斷點(diǎn)進(jìn)行調(diào)試,可以使用Debug菜單中的Toggle Global Breakpoint(Shift F9)設(shè)置全局?jǐn)帱c(diǎn)。設(shè)置全局?jǐn)帱c(diǎn)后,當(dāng)UML代碼所在的線程執(zhí)行到斷點(diǎn)處,這個(gè)線程就會(huì)停下來,此時(shí)可以使用Debug菜單中的Attach功能,將當(dāng)前線程由主線程變?yōu)閁ML線程,這樣就可以單步跟蹤調(diào)試了。UML線程在Attach對(duì)話框中通常是最后一個(gè)線程,默認(rèn)情況下其名字應(yīng)該為t1,但是有的時(shí)候線程名會(huì)顯示為亂碼。
posted @
2008-10-13 23:18 zealsoft 閱讀(1333) |
評(píng)論 (0) |
編輯 收藏
模板引擎(Template engine)是實(shí)現(xiàn)模型和視圖分離的一個(gè)重要手段。如果你從未接觸過模板引擎可以看看
Wiki的介紹。模板引擎的流行最初是因?yàn)榫W(wǎng)站開發(fā)的需要,象比較重要的幾個(gè)模板引擎:SMARTY、Velocity、StringTemplate都是來源于網(wǎng)頁設(shè)計(jì)的。當(dāng)然,除了網(wǎng)頁設(shè)計(jì),模板引擎還可以應(yīng)用于其他領(lǐng)域,而我主要將其應(yīng)用與代碼生成器的設(shè)計(jì)中。
有關(guān)模板引擎,我推薦StringTemplate的作者Terence Parr 寫的一篇
英文論文。Terence Parr是一個(gè)大學(xué)教授,寫的文章自然學(xué)術(shù)性比較強(qiáng),較難懂,但是很有參考價(jià)值。借助這篇文章的分析,我們可以發(fā)現(xiàn)當(dāng)前模板引擎有著兩種不同的思路:一種是嚴(yán)格將模型和視圖分開的,設(shè)計(jì)模板系統(tǒng)時(shí)往往提供的模板語言比較簡單,避免在模板語言中加入運(yùn)算符號(hào)等,另一種是提供強(qiáng)大的模板語言功能,模板語言具有類似高級(jí)語言的功能,如各種條件判斷語句,甚至數(shù)學(xué)運(yùn)算能力。顯然從模板編寫者的角度看,后者具有更強(qiáng)大的功能,幾乎無所不能,但是安全性不如前者,模板的編寫者更容易利用系統(tǒng)漏洞做模板系統(tǒng)設(shè)計(jì)者沒有想到的事情。這個(gè)問題仁者見仁,智者見智,好在由很多的模板系統(tǒng)可以選擇。
絕大多數(shù)模板引擎都是支持Java、PHP、Python的,這當(dāng)然和模板引擎的應(yīng)用領(lǐng)域相關(guān)。我的代碼生成器是用C++寫的,而且必須支持Windows平臺(tái),所以選擇的范圍就比較有限了,從網(wǎng)絡(luò)上搜索了一下,似乎只有
Teng、
CT++和
Google CTemplate可以使用了。我對(duì)3個(gè)系統(tǒng)進(jìn)行了簡單的評(píng)估,并實(shí)際使用過CT++和CTemplate,現(xiàn)在總結(jié)一下自己的心得,希望對(duì)大家有一些幫助。
1、操作系統(tǒng)的支持
我的主要工作是在Windows上的,而模板引擎絕大多數(shù)是面向Unix/Linux的,這和我的需求有一定距離。當(dāng)初曾經(jīng)下載過Teng,但是折騰了半天也沒有能夠讓其在Visual Studio 2003下成功編譯,所以就放棄了,后來將CT++ 1.8簡單地處理了一下就可以跑了,很開心。而Google CTemplate更提供了完全的Windows支持,這對(duì)于我這樣的用戶當(dāng)然是非常省心了。
2、軟件開發(fā)的活躍度
這些軟件都是開源的,軟件開發(fā)的活躍度當(dāng)然是我關(guān)心的,有的工具剛開始用的時(shí)候很開心,但是后來開發(fā)者沒有興趣不玩了,而又沒有人接手,BUG也無法更新了,就比較苦了,典型的象TurboPower。Teng似乎已經(jīng)很長時(shí)間不更新了,CT++一直在更新,但是開發(fā)者是俄羅斯人,全部文檔是俄文的,包括程序注釋,以前1.8還有英文文檔,從2.0以后就沒有了,雖然最近承諾2.4以后會(huì)報(bào)告英文文檔,但是我擔(dān)心他哪天不高興就不玩了,所以最后下定決心轉(zhuǎn)到CTemplate去了。CTemplate雖然是Google的,而且據(jù)說Google內(nèi)部也在使用,但是在模板引擎領(lǐng)域的名氣卻不大,好像作者的熱情仍然很高,持續(xù)更新,而且可能很快要升級(jí)到1.0版本了,這給我很大的信心。
3、模板語言的功能
在我看來,模板語言的功能越強(qiáng),提供的函數(shù)越多,它可能越受模板編寫者的歡迎,但是可能不符合模型和視圖嚴(yán)格分離的原則。Teng和CT++都屬于模板語言功能強(qiáng)的一類,象Teng甚至提供了大量的運(yùn)算符,而CTemplate顯然是嚴(yán)格按照模型和視圖分離原則設(shè)計(jì)的,它甚至沒有提供if/else這樣在其他模板系統(tǒng)中都有的功能。如前所述,這個(gè)問題仁者見仁,智者見智,不爭論了。下面簡單地列個(gè)表比較一下。由于CT++ 2沒有英文文檔,一直就沒有使用過,可能會(huì)遺漏一些新功能。
|
Teng |
CT++ |
CTemplate |
| 變量 |
支持 |
支持 |
支持 |
| 函數(shù) |
支持 |
支持 |
支持(Modifier) |
| 包含 |
支持 |
支持 |
支持 |
| 條件語句 |
支持 |
支持 |
不支持 |
| 循環(huán) |
支持 |
支持 |
支持 |
| 計(jì)算 |
支持 |
不支持 |
不支持 |
| 賦值 |
支持 |
不支持 |
不支持 |
| 注釋 |
支持 |
支持 |
支持 |
| 安全性設(shè)計(jì) |
不支持 |
不支持 |
支持 |
| 用戶定義函數(shù) |
不支持 |
支持 |
支持 |
4、C++ API
基本的API幾個(gè)軟件都差不多,我覺得CTemplate更完善一些,特別喜歡它的調(diào)試功能。
總體來說,我對(duì)CT++還是有些難舍,但是綜合考慮之后還是決定轉(zhuǎn)到CTemplate上。
posted @
2008-09-17 21:42 zealsoft 閱讀(2705) |
評(píng)論 (2) |
編輯 收藏
最近開始嘗試使用Doxygen生成程序的文檔。程序的源代碼采用的是GB2312的格式存儲(chǔ)的,而Doxygen輸出的文檔是UTF-8格式的,出現(xiàn)了亂碼。雖然Visual Studio 2003支持以UTF-8格式存儲(chǔ)源代碼,但是要把所有文件都轉(zhuǎn)換擔(dān)心太麻煩。于是,在配置文件中增加了一行代碼:
INPUT_ENCODING = GB2312
這下問題解決了,Doxygen在生成文檔時(shí)自動(dòng)將文件的編碼從GB2312轉(zhuǎn)換為UTF-8,輸出就沒有亂碼了。
posted @
2008-09-09 16:49 zealsoft 閱讀(1979) |
評(píng)論 (0) |
編輯 收藏