版本:0.1
最后修改:2010-12-10
撰寫:李現民
引言
很多游戲都有配套的編輯器,或通用或專用,這樣可以方便策劃及時設計、修改游戲數據。當一個游戲方案確認實施時,如果需要設計配套編輯器,那么它往往先于游戲本身而設計。出于代碼重用和方便維護的需要,大部分核心代碼會在游戲客戶端與編輯器中同時使用,因此有效提取這部分共用代碼并盡量減少與項目其它部分的耦合就成為設計的重點。
關于良好程序架構設計的話題,比如設計模式、領域驅動設計等,相關論著恒河沙數。本文結合實踐中遇到的問題,從工具與技術相結合的角度來闡述相關問題的解決方案。
以下假定程序運行環境為VC6+XP。從本文撰寫時間看(2010-12-10),VC6無論如何都不是一個好的選擇,但限于筆者所在公司環境如此,所以只好將就著來了╮(╯▽╰)╭。
使用宏控制代碼生成策略
盡管我們追求代碼的可重用性,但實際情況往往并不盡如人意,特別是在與特定于游戲客戶端(或編輯器)的功能相結合比較緊密的代碼部分。比如UI(界面),游戲客戶端中有獨立的界面模塊,而編輯器界面可能使用MFC制作。即使同一個函數接口,游戲客戶端與編輯器所需要的功能也可能是不一樣的,這是因為它們擁有各自不同的應用傾向:游戲客戶端傾向于使游戲畫質更加平滑,而編輯器則需要考慮策劃人員快速的編輯修改數據;再比如游戲客戶端可能需要網絡IO功能,而編輯器則一般不需要。
宏(具體的說,C++中的宏),此時可能是一種比較合適的工具。比如,通過在游戲客戶端與編輯器中定義不同的宏變量,可以使游戲客戶端專用的網絡IO代碼在編輯器中根本不生成。
某些情況下可能需要在同一個項目下建立多個configurations(配置),通過定義不同的宏變量以控制生成不同版本的程序,比如:簡化版、完整版、內部版等。
宏在VC環境中有大量的應用案例,比如windows.h頭文件中定義了大量的宏用于控制不同環境下的代碼生成策略。
使用函數控制代碼生成策略并信任編譯器優化
宏控制的原理是將不需要的代碼當作注釋直接移除,因此編譯器不會去審查該部分代碼的正確性。這在某些情況下是必須的,比如編輯器沒有網絡IO相關的代碼接口,因此相關代碼必須被清除,否則編輯器項目將無法正確編譯。
但宏控制有自己的問題:
宏變量通常定義在Project Settings(工程設置)中,因此不容易記憶或查找;
IDE工具通常無法像支持代碼一樣支持此類宏變量的快速查找,特別是存在多個項目相互引用的復雜工程中(比如Visual Assist X有Find Reference功能,可以快速搜索到所有引用指定變量或函數的代碼,但此功能不支持在Project Settings中定義的宏變量);
編譯器無法審查被移除部分代碼的正確性,這可能導致一些代碼修改同步的問題。
針對這些問題,筆者的解決方案是:宏控制變量只使用一次,用于定義一個簡單函數,而該函數返回當前宏控制變量的存在情況,其它原本使用宏控制變量的地方都改為使用這個函數判斷。這樣間接的將宏變量控制轉換為函數控制,從而獲得IDE工具支持與編譯器代碼審查的雙重好處。
比如如下代碼:
namespace
edition
{
#ifdef
_EDITOR
inline
bool
IsEditor()
{ return
true;
}
#else
inline
bool
IsEditor()
{ return
false;
}
#endif
}
void
Print()
{
if
(edition::IsEditor())
{
puts("This
is editor");
}
else
{
puts("This
is not editor");
}
}
宏變量_EDITOR只使用一次,其余地方都使用edition::IsEditor()區分是編輯器代碼還是游戲客戶端代碼。
請注意,我們并不會有任何的運行期性能損失,雖然看起來并非如此。由于在編譯期edition::IsEditor()的值是確定的,因此當打開優化時編譯器會移除不可達代碼,從而得到與宏控制情況下相同的可執行文件。當然,在Debug版本下(優化關閉)所有的代碼都被編譯生成到最終可執行文件中,但我猜您應該不會將Debug版本給最終用戶使用對吧?
使用delegate解耦
在MVC架構下,使用Observer(觀察者)模式將核心邏輯代碼與UI界面代碼分離似乎天經地義的事,這樣做的好處是核心邏輯代碼可以獨立于UI代碼而存在,從而達到重用的目的。但不幸的是,從筆者經手的代碼看,很多程序員并沒有注意到這一點。主要問題可能包括以下兩個方面:
第一是核心邏輯代碼與UI界面代碼相互調用關系錯綜復雜。由于核心邏輯代碼不獨立,因而很難進行提取復用。這種情況相對比較常見。
第二個問題解釋起來可能更復雜一些。由于缺乏從核心邏輯代碼到UI界面代碼的回調機制,程序員可能會被迫使用一些極端的手法來達到偵測指定事件是否發生的目的。比如,我們知道游戲客戶端都有一個主循環main_loop,方法名稱通常叫Update()或Tick(),用于更新每一幀的游戲動畫。這時,程序員可能會在該循環中埋伏一些代碼以偵測核心邏輯狀態的變化情況,從而達到觸發事件的目的。這種手法實現了功能,保持了低耦合,卻降低了代碼執行效率。
這兩個問題的解決之道在于觀察者模式。這個模式在實現上還是比較復雜的,對每一個要處理事件都需要定義對應的觀察者與被觀察者接口。這種代碼復雜性曾使很多人望而卻步(包括本人-___-),為此java中內置了java.util.Observer與java.util.Observable接口,以降低使用該模式的代價。
筆者建議的方案是使用delegate(委托)。沒錯,就是那個C#中的delegate,它能夠極低的設計復雜度實現與觀察者模式相同的解耦效果。具體實例這里不再列舉,因為網上可以找到很多。如果你使用的是C#,那么你是幸運的;如果你使用的是C++,那么網上同樣可以找到設計好的仿真類庫;如果你不幸使用了VC6,并且實在找到出路了,那么同學你也許可以去參考一下我的另一篇文章《VC6中簡易delegate實現》,或許會有點幫助。
結語
本來還想加點靜態變量與通用工廠的話題的,但我發現meyers singleton在VC6中的某種應用模式下會問題(singleton對象的構造函數會被調用兩次,T__T),因此先欠著賬,等待下次有成熟方案的時候再說吧。不過對此問題諸位看官如果有相關寶貴經驗的話不妨提攜一二,感激不盡中。
]]>
版本:0.1
最后修改:2010-11-15
撰寫:李現民
概述
很久以前,我寫過一篇短文討論如何在C++項目中避免使用delete的設想,基本方法是使用域(scope)對象或std::auto_ptr代替。盡管當時已經討論在所有可能的情況,但后面在實際項目實施中發現效果并不好。原因是方面的,比如在使用std::auto_ptr時會存在以下不得因素:
可能的額外開銷外(其實很小);
你需要時刻小心對象所有權的問題。盡管可能只需要稍微注意一下就可以了,但似乎沒有任何程序員喜歡過提心吊膽的日子;
你不能在容器(比如std::vector)中存儲std::auto_ptr對象;
基于以上原因,類似于Text* pText = new Text;這種直接在堆上申請內存的方式還是在代碼得到了大量應用。而接下來就是如何安全、有效的回收這些內存的問題,這也正是本文所討論的話題。
回收單個堆對象
//
delete a object pointer and reset it
template<class
T>
void
delete_null(T*&
p)
{
//
check if T is incomplete type, if it is, the compiler will report an
error
typedef
char
type_must_be_complete[
sizeof(T)?
1: -1 ];
(void)
sizeof(type_must_be_complete);
//
delete the pointer and reset it
delete
p;
p
=NULL;
}
這是一個模板函數,它主要有三個作用:
第一個作用是檢查被刪除對象的類型完整性。這通常無法引起人們的重視,但在某些情況下可能會導致未定義行為,比如以下代碼:
Text*
pText =
new
Text;
void*
pData =
pText;
delete
pData;
Text*類對象pText 被轉換成了擁有void*對象pData,并對pData 調用了delete 刪除操作。在這種情況下編譯器的行為是未知的,但至少有一點:由于編譯器無法推導pData 的原始類型,因此無法調用對象的析構函數。
//
check if T is incomplete type, if it is, the compiler will report an
error
typedef
char
type_must_be_complete[
sizeof(T)?
1: -1 ];
(void)
sizeof(type_must_be_complete);
這兩句代碼可以檢查被刪除對象的類型完整性。其效果發生在編譯期,如果對類型不完整的對象調用delete_null 刪除操作,將引起編譯錯誤。它沒有運行期開銷,因此使用delete_null 帶來的安全性實際上免費的。
更加詳細的解釋可以參考boost庫中的checked_delete.hpp。
delete_null 的第二個作用是回收堆對象,這沒有什么可說的。
delete_null 的第三個作用是將對象指針設置為NULL,這主要是為了應對指針有效性檢查,屬于常規手段。
另外,注意到delete_null 被設計為一個模板函數,在發布版本(Release)中,它將以內聯代碼(inline)的形式存在,因此不會有運用期函數調用開銷。
回收容器中的堆對象
//
delete container (std::vector, std::list) items and reset them to
NULL
template<
typename
InputIterator
> void
delete_null(InputIterator
first,
InputIterator
last)
{
while(last
!= first)
{
delete_null(*first);
++first;
}
}
//
delete functor, used for iterative delete
struct
deleter
{
template<
typename
T
> void
operator()(T*&
p)
{
delete_null(p);
}
};
這段代碼分為兩部分:一個同樣叫delete_null 的模板函數與一個名為deleter的仿函數。
先來看第一部分,它同樣叫delete_null,與前面介紹的那個版本所不同的是它接受一對迭代器作用輸入條件,其作用是回收[first, last) 范圍內所有堆對象。與std::for_each等很多STL標準算法類似,該函數可以同時應用于普通數組或存儲單值的標準容器(包括std::vector, std::list, std::set等,不包含std::map)。
第二部分比較有意思:它是一個仿函數。它可以在一定程度上代替delete_null(first, last),以下代碼展示了分別使用這兩種方式回收容器中的堆對象的方法:
typedef
std::vector<Text*>
TextPack;
TextPack
uTexts1,
uTexts2;
const
int
datasize =
100;
for
(int
i=
0; i<
datasize;
++i)
{
uTexts1.push_back(new
Text);
uTexts2.push_back(new
Text);
}
//
使用delete_null
delete_null(uTexts1.begin(),
uTexts1.end());
//
使用deleter
std::for_each(uTexts2.begin(),
uTexts2.end(),
deleter());
可以看到前者稍微簡潔一些(包括最終的匯編代碼),那么問題來了:為什么還需要代碼量更大一些的deleter 仿函數?
理由是:并不是所有存儲堆對象的集合都是直接存儲對象指針的。比如可以將指針存儲在std::map中“值”部分,甚至有些自定義集合只提供了遍歷函數(類似于std::for_each),但并不公開迭代器接口。在這些情況下,我們就可以使用deleter 仿函數進行堆對象回收。
]]>
]]>
get與set成員函數是為代碼耦合之重要原因
版本:0.1
最后修改:2009-08-21
撰寫:李現民
類數據成員的訪問級別通常需定義為private,以封裝類的實現細節,這樣可以在類的生命演化過程中提供更好實現彈性。
get/set成員函數(訪問級別通常為public)使得client端用戶代碼可以訪問對象的內部數據結構,這會暴露類內部的實現細節。這種暴露使會得用戶代碼與類實現之間產生深層次的依賴關系,而這種過剩的知識將在類實現技術改變時迅速破壞相關的用戶代碼---漣漪效果。
比如Container類輸出了關于實現該類之二叉樹的信息(比如,當它輸出成員函數getLeftChild()與getRightChild()時),用戶將被迫按照二叉樹而不是容器進行思考,這將使用戶代碼變得復雜且難以改變。如果Container類改變了實現結構,則用戶代碼將被迫進行修改(可能是大量的)。
最少知識(least knowledge)原則是用于面向對象編碼中降低類間耦合度的指導原則。該原則認為如果要在相互調用的類(對象)之間保持較低的耦合度,則一個對象所調用的方法應該僅僅局限于以下幾個來源:
-
類對象本身;
-
被當作方法的參數而傳遞進來的對象;
-
此方法所創建或實例化的任何對象;
-
對象的任何組件;
一個對象可以任意調用以上四類對象的方法。唯一一類不可調用的方法來源于:通過某個對象的get成員函數所獲取的間接對象的成員函數。很容易想象,當某個類擁有大量get/set成員函數時,該類本身幾乎不可能提供完善的邏輯處理方法(否則也就沒有必要提供這些get/set成員函數了),因此借助get成員函數獲取間接對象并做進一步的處理幾乎是不可避免的。
因此,在有可能的情況下,類設計人員應該盡量不提供get與set成員函數。
當然,不要認為get與set成員函數總是壞的,像CORBA這樣的框架都會為所有的屬性自動提供get/set成員函數。真正的問題是:好的對象總會封裝并在接口后面隱藏某些東西,然而get/set成員函數有時會在暗中暴露對象的秘密。只有當在類外(從用戶的角度)看待這些私有數據仍“有意義”時,為私有數據設置公有的get()和set()成員函數才是合理的。然而在許多情況下, get()/set()成員函數和公有數據一樣差勁:它們僅僅隱藏了私有數據的名稱,而沒有隱藏私有數據本身。
注1:以上文字部分參考了《C++ FAQs》second edition, P73的內容。
注2:我們經常使用get/set成員函數作為急救帶來修補蹩腳的接口。
]]>
基類角色之對象管理器
版本:0.1
最后修改:2009-07-02
撰寫:李現民
問題描述
C++程序設計中,保存一個生命周期不是由類對象自己維護的其它對象的指針通常是個壞主意,因為程序邏輯很難判斷在使用該指針的時刻其所指對象是否已經被銷毀。這種應用需求很常見,例如在網游設計中,由于華麗的裝備加載需要進行大量硬盤I/O,因此加載過程通常由一個獨立的加載線程執行,由于在裝備加載完成的時刻該玩家很可能已經下線,因此加載線程就需要能夠去判斷此時玩家對象是否仍然有效。
為了解決該問題,通常會設計一個PlayerManager類用于跟蹤管理當前所有的玩家對象,而加載線程通過提供玩家id以確認該玩家對象仍然存在。此種設計方案需要一個獨立的PlayerManager類,并提供一個全局的PlayerManager類對象以跟蹤當前的所有玩家對象。
出于代碼復用的目的,我希望實現一個通用基類解決此類問題。該基類需要為子類對象至少提供以下幾方面的能力:
-
為所有的對象分配一個全局唯一的index,通過該index能夠(盡可能快的)獲取到擁有該index的類對象(或NULL);
-
自動跟蹤類對象的生成與銷毀,不需要手工編寫額外代碼;
-
實現迭代器,提供遍歷當前所有有效對象的能力;
-
提供“移除”接口,使得對象可以主動要求放棄被對象管理器跟蹤;
-
各子類實現擁有完全獨立的管理器邏輯;
解決方案
將實現代碼保存為objectman.hpp,內容如下:
created: 2009-06-29
author: lixianmin
purpose: base class for object manager
Copyright (C) 2009 - All Rights Reserved
*********************************************************************/
#ifndef _LIB_OBJECT_MAN_HPP_INCLUDED_
#define _LIB_OBJECT_MAN_HPP_INCLUDED_
#include <cassert>
#include <map>
namespace lib
{
template<typename T>
class objectman
{
public:
typedef int index_t; // 索引類型
typedef std::map<index_t, T*> object_map; // 容器類型
enum { INVAID_INDEX= 0}; // 無效索引
public:
// 迭代器
class iterator
{
public:
iterator(void): _iter(_mObjects.begin()){} // 構造函數
bool has_next(void) const { return (_mObjects.end()!= _iter); } // 測試是否還有下一個對象
T* next(void) { return has_next()? (_iter++->second): NULL; } // 獲取下一個對象指針
private:
typename object_map::iterator _iter;
};
public:
// 構造函數
objectman(void)
{
enable_index();
}
// copy 構造函數
objectman(const objectman& rhs)
{
enable_index();
}
// 析構函數
virtual ~objectman(void)
{
disable_index();
}
// 賦值操作符
objectman& operator= (const objectman& rhs)
{
}
// 通過索引獲取對象
static T* get_by_index(index_t index)
{
object_map::iterator iter= _mObjects.find(index);
if (_mObjects.end()!= iter)
{
T* pObject= iter->second;
assert(NULL!= pObject);
return pObject;
}
return NULL;
}
// 獲取對象索引
index_t get_index(void) const { return _idxObject; }
// 生成索引(使能被對象管理器遍歷到)
void enable_index(void)
{
_idxObject= ++_idxGenderator;
assert(get_index()!= INVAID_INDEX);
assert(_mObjects.find(get_index())== _mObjects.end());
_mObjects.insert(std::make_pair(get_index(), static_cast<T*>(this)));
}
// 移除索引(使不能被對象管理器遍歷到)
void disable_index(void)
{
if (get_index()!= INVAID_INDEX)
{
assert(_mObjects.find(get_index())!= _mObjects.end());
_mObjects.erase(get_index());
_idxObject= INVAID_INDEX;
}
}
private:
friend class iterator;
static object_map _mObjects; // 對象容器
static index_t _idxGenderator; // 索引發生器
index_t _idxObject; // 對象索引
};
template<typename T>
typename objectman<T>::object_map objectman<T>::_mObjects;
template<typename T>
typename objectman<T>::index_t objectman<T>::_idxGenderator= 0;
}
#endif
測試代碼
測試代碼如下:
#include "objectman.hpp"
// 聲明一個類
class Player:public lib::objectman<Player>
{
};
int main(int argc, char* argv[])
{
const int idxDisabled= 5;
// 生成對象
for (int i= 0; i< 10; ++i)
{
Player* pPlayer= new Player;
if (idxDisabled== pPlayer->get_index())
{
// 從對象管理器中移除該對象
pPlayer->disable_index();
}
}
//使用迭代器遍歷類對象
Player::iterator iter;
while(iter.has_next())
{
Player* pPlayer= iter.next();
const int idxPlayer= pPlayer->get_index();
// 斷言之:遍歷不到已經移除的對象
assert(idxPlayer!= idxDisabled);
// 斷言之:可以通過idxPerson取得對象指針
assert(pPlayer== Player::get_by_index(idxPlayer));
// 回收對象
delete pPlayer;
pPlayer= NULL;
}
// 斷言之:所有對象均已被刪除
Player::iterator iter2;
assert(!iter2.has_next());
system("pause");
return 0;
}
vs2008下所有斷言均動作通過。
已知問題
-
在大量生成對象的情況下,index索引空間(代碼定義為int的范圍)有可能使用殆盡,甚至產生重復,這會導致兩個對象擁有相同index的嚴重錯誤;
-
std::map的查找速度不是特別另人滿意;
]]>
版本:0.1
最后修改:2009-05-15
撰寫:李現民
依賴倒置原則(DIP)告訴我們應該優先依賴于抽象類,而避免依賴于具體類。特別是在一個正在進行開發的應用程序,有很多具體都是非常易變的,因此我們應該依賴于抽象接口,以使我們鐘愛大多數變化的影響。
在典型的面向抽象的程序設計邏輯中,依賴于抽象往往意味著會衍生大量的抽象類及(更大量的)子類,從而構成一些樹狀的類族結構。一個必然會出現的問題是:抽象類族中子類對象由誰創建?
顯然,這不應該交由客戶代碼處理(我們不是要依賴于抽象嘛:))。一個典型的基于Factory Method解決方案結構如下: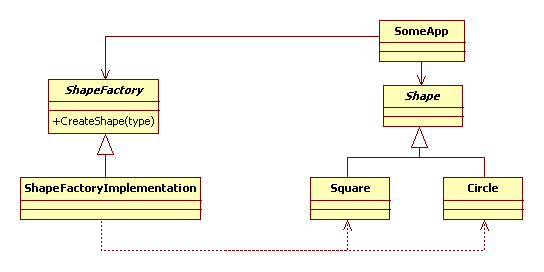
該類圖展現了這樣的一個應用場景:類SomeApp通過接口Shape與ShapeFactory對產品類(Shape類族)進行操作。SomeApp完全沒有使用Square類或者Circle類的任何特定方法。并且由于ShapeFactory的介入,SomeApp對這兩個實現類的創建過程也一無所知。我知道您的疑問:“對具體類ShpeFactoryImplementation的依賴如果處理?”。答案是:工廠類對象往往由main或者由一個隸屬于main的初始化函數創建出來。
使用Factory Method是有代價的:它很復雜,為了創建一個新類,就必須要創建出4個新類,這4個類是:2個表示該新類及其工廠的接口類,2個實現這些接口的具體類。尤其是在一個正在演化的設計的初期,如果缺省使用它們,就會棉套的增加擴展設計的難度。
另一個很常見的問題是:在整個項目的生命周期中,ShapeFactory很可能會自始至終保持僅有ShpeFactoryImplementation一個子類。結果是這帶來了設計上的復雜性,但卻在易于擴展性上得到實際的好處。
一個折衷的解決方案是使用Simple Factory,其類圖結構如下所示:
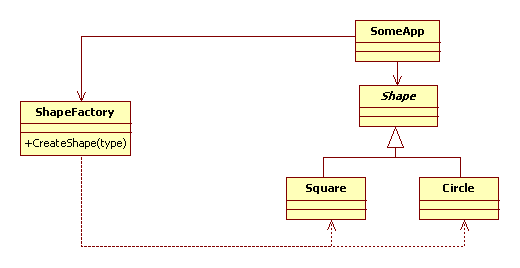
注意Simple Factory雖然為很多設計模式的書所津津樂道,但其實并不是GOF的23種設計模式之一。同時,聰明的你一定已經發現現在ShapeFactory類已經不再是一個接口了。難道我們又陷入到對具體類的依賴中去了?哦,如果是的話,至少此時我們所依賴的具體類只有ShapeFactory一個,這并不會隨著抽象類Shape子類的增多而增多。
新的問題是:除非ShapeFactory負責所有Shape對象的管理與維護(這時通常應該叫ShapeMan云云。注意:Man for manager,工廠類的命名中不一定要含有Factory字樣的:)),否則它極容易成為一個貧血類----僅僅含有一個CreateShape()函數的類,它披著class的皮,干著function的事。
既然如此,何必要額外創建一個ShapeFactory對象(計算機說:這會降低效率的),把CreateShape() 交給Shape類不就得了?反正是她的孩子,也算天經地義(其實,不完全這樣!)。新的類圖呈現為下面的樣子:
來看看我們的戰果:
-
Factory職能由Shape類承擔。通常CreateShape()可由一個static函數實現;
-
完全消除了非必需類,這避免了創建額外新類的代價;
-
SomeApp類僅依賴一個唯一的類Shape,并且Shape是一個抽象類,這降低了客戶代碼與實現類之間的耦合度;
已知的代價:
-
依賴關系環。敏感的讀者一定已經發現Shape與其實現類之間形成了一種環狀依賴,其代價是每添加一種新的Shape實現就必須修改CreateShape()函數的實現(能夠做到不更改接口)。唯一值得慶幸的是:在Factory Method與Simple Factory的方案中,我們同樣無法避免這種雙向修改;
-
Shape所有權問題。盡管繼承是一種比關聯強得多的實體關系,但在打包時Shape最好與它的客戶代碼SomeApp在一起。SomeApp的實現離不開Shape,但理論上Shape卻是可以脫離Shape單獨存在。依賴關系環的出現會強迫Shape與它的實現類打包在一起;
-
違反了依賴倒置原則(DIP),我們的抽象類開始依賴于具體類;
-
Shape不再是一個接口。如果說Factory Method與Simple Factory中的Shape還有可能是接口的話,那么在最后一方案中具體函數CreateShape()的加入則完全打破了這種可能。
如果:在一個項目演化的初期,您還不確信您需要創建一些Factory類;或者,您已經確信可以承受該方案的代價并且期望得到它所帶來的好處的話,那么您不妨嘗試一下。
參考文獻
-
《敏捷軟件開發 原則、模式與實踐》 P239:FACTORY模式;P279:ABSTRACT SERVER模式;
]]>
]]>