此處的KFS是指Kosmos distributed file system,代碼位于http://sourceforge.net/projects/kosmosfs/,之后會寫幾篇相關的文章,以供后來者參考。
KFS里Meta的內存結構主要是一棵B+樹,保存在內存里,具體分析如下:
B-樹,B+樹的定義
關于這些樹的定義,最好還是參考算法導論等經典書,網路上的信息有些不是很準確,為了方便大家還是貼一個鏈接:
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
KFS為何選用B+樹而非B樹?
這是我個人的理解:
雖然B樹可以在非葉子節點命中,會縮短一些平均查找長度,但是B+樹在這種應用一個優勢就是每個節點都有指向next節點的指針,對于范圍查詢或者遍歷操作很適合。對于文件系統的一個ls某個子目錄的需求,用B+樹可以較高效的解決。
KFS里B+樹的類圖
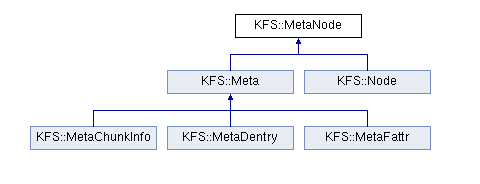
MetaNode:base class for both internal and leaf nodes
Meta:base class for data objects (leaf nodes)
Node:an internal node in the KFS search tree
MetaChunkInfo:chunk information for a given file offset
MetaDentry :Directory entry, mapping a file name to a file id
MetaFattr:File or directory attributes
各節點的介紹
(1)Meta類是子節點的父類,其最主要的成員變量是fid
有三個葉子節點:MetaChunkInfo,MetaDentry,MetaFattr
(2)MetaDentry:實現從文件名到fid的映射,對于每個文件(目錄)都擁有1個MetaDentry
成員變量包括:
dir:文件父目錄的fid
name:dentry的名稱,實際就是文件名
(3)MetaFattr:實現從fid到文件屬性的映射,對于每個文件(目錄)都擁有一個MetaFattr。
成員變量包括:
Type:文件還是目錄
numReplicas:文件有幾份副本
mtime:修改時間
ctime:屬性修改時間
crtime:文件創建時間
chunkcount:連續的chunk數目
filesize:文件大小
nextChunkOffset:最后一個chunk在文件的所處的offset
mode_t mode:文件屬性(rwx位)
key:由KFS_FATTR,fid來構成,可以通過fid直接找到保存文件屬性的節點。
(4)MetaChunkInfo:標志某個文件對應的chunk信息,如果一個文件包含多個chunk,那么需要有多個MetaChunkInfo。
成員變量包括:
offset:chunk在文件中的偏移量,因為一個文件可能由多個chunk組成
chunkId:chunk的id號
chunkVersion:chunk的version值
(5)Node:實現的是B+樹的內部節點,這種節點僅僅作為索引用途,存儲實際元數據信息的節點位于最底部的葉子節點。
成員變量包括:
NKEY = 32:每個節點最多擁有的關鍵字數目,實際上也就是最多擁有的子節點數目,如果多余這個值節點進行分裂
NSPLIT = NKEY / 2:分裂之后每個節點的關鍵字數目
NFEWEST = NKEY - NSPLIT:每個節點最少擁有的關鍵字數目,如果少于這個值兩個節點進行合并
count:節點實際擁有的關鍵字數目
Key childKey[NKEY]:節點存儲的關鍵字列表
MetaNode *childNode[NKEY]:節點指向子節點的指針列表
Node *next:指向下一個同級節點的指針
實際上每個內部節點的階數為32,可以有32個子節點,而每個葉子節點只保存一個key值。
三類子節點在B+樹中如何分布?
可以想象,必定是將同一類的節點聚集在一起。因此對于排序函數就是先比較節點類型,然后再對節點內部的成員變量進行比較。MetaDentry是根據dir(父目錄的id),MetaFattr是根據fid,MetaChunkInfo是根據id和chunkId來排序。
一個不太相關的思考
看上面的三類子節點,我們可以發現chunk的位置信息并沒有保存在B+樹里,它是單獨保存在一個Map數據結構里的,也不會在meta server里進行持久化,而是每次chunk啟動時向meta server來報告。之所以不做持久化,可以這樣來理解:
只有Chunk服務器才能最終確定一個Chunk是否在它的硬盤上。Chunk服務器的錯誤可能會導致Chunk自動消失(比如,硬盤損壞了或者無法訪問了),亦或者操作人員可能會重命名一個Chunk服務器,還是由chunk server來報告比較靠譜。