|
#
有些dbi2的數據庫實現了fetchoneDict接口,畢竟不是強制要求的,但是實際應用中非常有用
import sys,sqlite3,os
def fetchoneDict(cr):
ff = [ r[0] for r in cr.description ]
rr = cr.fetchone()
if rr:
return dict( zip(ff,rr) )
return {}
cnn = sqlite3.connect('e:/tax.db3')
print dir(sqlite3)
cr = cnn.execute('select * from core_bill')
while 1:
r = fetchoneDict(cr)
if not r: break
print r
在應用項目中,我們又很多用戶信息點需要被加載到圖層上,這些點可以使用CustomMarker來顯示。用戶點分布密集程度不一致,而且量很大,一次性的全部加載進行圖層是不可取的,幸好使用的是openscales的wmsc圖層,底圖是瓦片(tile)形式加載,所以最簡單的方式就是當tile加載和釋放的時候通知到用戶層,用戶層實現加載和釋放用戶信息點。 看了一下openscales的代碼,發現tile的申請和釋放并沒有通知到層對象,所以我們不能直接獲取這些事件消息。 wmsc類層次結構: wmsc->wms->Grid->HttpRequest->Layer Grid類維護了瓦片集合的二維數組,當地圖extent改變時,openscales將掃描Grid的瓦片數組,如果發現有空洞則調用wms的addTile()創建新的tile,如果發現可廢棄tile,則調用Grid.removeExcessTiles()。 addTile()之后openscales將通知layer接收TileEvent.TILE_LOAD_START事件,這個TILE_LOAD_START事件是可以利用的,作為tile加載時的通知事件,在使用的wmsc層時添加一個事件偵聽便可獲取tile加載事件; ImageTile從Tile派生下來,當Grid作廢無效Tile時,將調用Tile.destroy()方法,所以我在TileEvent添加新事件TILE_DESTROY,在Tile.destroy()通知layer獲取tile銷毀的消息 1 public function destroy():void {
2 if (this.layer!=null){
3 this.layer.dispatchEvent(new TileEvent(TileEvent.TILE_DESTROY,this));
4 }
5 this.layer = null;
6 this.bounds = null;
7 this.size = null;
8 this.position = null;
10 } 修改文件 TileEvent.as,Tile.as 好了,事件接收只需要在Layer的實例添加如下代碼: addEventListener(TileEvent.TILE_LOAD_START,tileLoadHandler); addEventListener(TileEvent.TILE_DESTROY,tileDestroyHandler);
TileEvent.tile攜帶了tile的boundle信息可供我們去請求feature對象了
啊關的企業在處理用友erp人事數據與稅務報稅時轉換數據時被停滯了,一個小時內完成他的需求 1 # -*- coding:utf-8 -*-
2 # soctt.bin created 2011.8.29
3 # sw2us.com @2011
4 #
5
6 import sys,os,os.path,time,struct,traceback,threading,datetime,string,datetime,calendar
7 import xlrd
8
9 start_year=0
10 start_month= 0
11 start_day =1
12 end_day = start_day
13
14 end_year= 0
15 end_month = 0
16
17 employee_importFile=u'111111111.XLS'
18 tax_importFile=u'題橋工資格式.xls'
19
20 employee_exportFile=u'empolyees.txt'
21 tax_exportFile=u'personTax.txt'
22 employeelistfile='employee_simplelist.txt'
23
24 fixDeduct = 2000.00 #扣除額
25
26 #人員歸檔
27 def employeeAchive():
28 title = u'工號~~姓名~~證件類型~~證件號~~性別~~出生日期~~國家、地區~~開票標志~~申報方式~~職務~~地址~~含稅標志~~郵政編碼~~調入調離~~備注'
29 #rowfmt = u"%s~~ %s~~ 1 ~~%s ~~0 ~~%s ~~142 ~~1 ~~0 ~~ ~~ ~~1 ~~ ~~0 ~~0"
30 rowfmt = u"%s~~ %s~~ 1 ~~%s ~~0 ~~%s ~~142 ~~1 ~~0 ~~ ~~ ~~1 ~~ ~~0 ~~0"
31 rowfmt = rowfmt.replace(' ','')
32
33 wb = xlrd.open_workbook(employee_importFile)
34 sh = wb.sheet_by_index(0)
35 file = open(employee_exportFile,'w')
36 title = title.encode('gbk')
37 file.write(title)
38 file.write('\n')
39
40 file2 = open(employeelistfile,'w') #清單表2
41 for r in range(1,sh.nrows):
42 v = sh.row_values(r)
43 v = map(string.strip,v)
44
45
46 birth = ''
47 try:
48 y,m,d = v[4].split('-')
49 birth = "%04d%02d%02d"%(int(y),int(m),int(d))
50 except:
51 print u'出生年月空缺 (%s,%s)'%(v[1],v[2])
52
53 txt = rowfmt%(v[1],v[2],v[5],birth)
54 txt = txt.encode('gbk')
55 #print len(txt)
56 file.write(txt+'\n')
57
58 txt = "%s~~%s~~%s\n"%(v[1],v[2],v[5])
59 txt = txt.encode('gbk')
60
61 file2.write(txt)
62
63 file.close()
64 file2.close()
65
66
67 def precess_parameters():
68 global start_year,start_month,end_year,end_month,start_day,end_day
69
70 cur = datetime.datetime.now()
71 start_year = cur.year
72 start_month = cur.month
73 #print len(sys.argv)
74 if len(sys.argv) == 4 and sys.argv[1]=='tax':
75 start_year = int(sys.argv[2])
76 start_month = int(sys.argv[3])
77
78 start_day = 1
79 x,end_day= calendar.monthrange(start_year,start_month)
80
81
82
83 def salaryTax():
84 global start_year,start_month,end_year,end_month,start_day,end_day
85
86 precess_parameters()
87
88 hashemployee = {}
89 file = open(employeelistfile,'r')
90 lines = file.readlines()
91 file.close()
92 for line in lines:
93 line = line.strip().split('~~')
94 k = line[0]
95 v = line[2]
96 hashemployee[k] = v
97 #以上建立員工查找表
98
99
100 title = u'證件類型~~證件號碼~~稅目代碼~~含稅標志~~所屬期起~~所屬期止~~天數~~收入額~~扣除額~~應繳稅額~~國家地區~~減免稅額~~實繳稅額'
101 #rowfmt = u"1 ~~%s ~~010000 ~~1 ~~%s ~~%s ~~%s ~~%s ~~%s ~~%s ~~142 ~~0 ~~%s"
102 rowfmt = u"1 ~~%s ~~010000 ~~1 ~~%s ~~%s ~~%s ~~%s ~~%s ~~%s ~~142 ~~0 ~~%s"
103 rowfmt = rowfmt.replace(' ','')
104
105 wb = xlrd.open_workbook(tax_importFile)
106 sh = wb.sheet_by_index(0)
107 file = open(tax_exportFile,'w')
108 title = title.encode('gbk')
109 file.write(title)
110 file.write('\n')
111
112 for r in range(1,sh.nrows):
113 v = sh.row_values(r)
114
115 v = map(unicode,v)
116 v = map(string.strip,v)
117 sid = '' #身份證編號
118 try:
119 sid = hashemployee[v[1]]
120 except:
121 print u'處理異常中斷: 工號不能匹配! 工號: %s'%(v[1])
122 return
123 sys.exit(0)
124 start = "%04d%02d%02d"%(start_year,start_month,start_day)
125 end = "%04d%02d%02d"%(start_year,start_month,end_day)
126 txt = rowfmt%(sid,start,end, end_day-start_day+1,v[22],fixDeduct,v[24],v[24] ) #應發工資 W(v[22])
127 txt = txt.encode('gbk')
128 file.write(txt+'\n')
129 file.close()
130
131
132 if __name__=='__main__':
133 employeeAchive()
134 salaryTax()
135
It can be used to solve linear equation systems or to invert a matrix.高斯消元法用于解決線性代數求多元方程組的解,或者用于求可逆矩陣的逆 嘿嘿,python代碼現成可用: def gauss_jordan(m, eps = 1.0/(10**10)):
"""Puts given matrix (2D array) into the Reduced Row Echelon Form.
Returns True if successful, False if 'm' is singular.
NOTE: make sure all the matrix items support fractions! Int matrix will NOT work!
Written by J. Elonen in April 2005, released into Public Domain"""
(h, w) = (len(m), len(m[0]))
for y in range(0,h):
maxrow = y
for y2 in range(y+1, h): # Find max pivot
if abs(m[y2][y]) > abs(m[maxrow][y]):
maxrow = y2
(m[y], m[maxrow]) = (m[maxrow], m[y])
if abs(m[y][y]) <= eps: # Singular?
return False
for y2 in range(y+1, h): # Eliminate column y
c = m[y2][y] / m[y][y]
for x in range(y, w):
m[y2][x] -= m[y][x] * c
for y in range(h-1, 0-1, -1): # Backsubstitute
c = m[y][y]
for y2 in range(0,y):
for x in range(w-1, y-1, -1):
m[y2][x] -= m[y][x] * m[y2][y] / c
m[y][y] /= c
for x in range(h, w): # Normalize row y
m[y][x] /= c
return True 使用方法 : If your matrix is of form [A:x] (as is usual when solving systems), items of A and x both have to be divisible by items of A but not the other way around. Thus, you could, for example, use floats for A and vectors for x. Example: mtx = [[1.0, 1.0, 1.0, Vec3(0.0, 4.0, 2.0), 2.0], [2.0, 1.0, 1.0, Vec3(1.0, 7.0, 3.0), 3.0], [1.0, 2.0, 1.0, Vec3(15.0, 2.0, 4.0), 4.0]] if gauss_jordan(mtx): print mtx else: print "Singular!" # Prints out (approximately): # # [[1.0, 0.0, 0.0, ( 1.0, 3.0, 1.0), 1.0], # [0.0, 1.0, 0.0, ( 15.0, -2.0, 2.0), 2.0], # [0.0, 0.0, 1.0, (-16.0, 3.0, -1.0), -1.0]] Auxiliary functions contributed by Eric Atienza (also released in Public Domain): def solve(M, b): """ solves M*x = b return vector x so that M*x = b :param M: a matrix in the form of a list of list :param b: a vector in the form of a simple list of scalars """ m2 = [row[:]+[right] for row,right in zip(M,b) ] return [row[-1] for row in m2] if gauss_jordan(m2) else None def inv(M): """ return the inv of the matrix M """ #clone the matrix and append the identity matrix # [int(i==j) for j in range_M] is nothing but the i(th row of the identity matrix m2 = [row[:]+[int(i==j) for j in range(len(M) )] for i,row in enumerate(M) ] # extract the appended matrix (kind of m2[m:,...] return [row[len(M[0]):] for row in m2] if gauss_jordan(m2) else None def zeros( s , zero=0): """ return a matrix of size `size` :param size: a tuple containing dimensions of the matrix :param zero: the value to use to fill the matrix (by default it's zero ) """ return [zeros(s[1:] ) for i in range(s[0] ) ] if not len(s) else zero 算法偽代碼: i := 1j := 1
while (i ≤ m and j ≤ n) do
Find pivot in column j, starting in row i:
maxi := i
for k := i+1 to m do
if abs(A[k,j]) > abs(A[maxi,j]) then
maxi := k
end if
end for
if A[maxi,j] ≠ 0 then
swap rows i and maxi, but do not change the value of i
Now A[i,j] will contain the old value of A[maxi,j].
divide each entry in row i by A[i,j]
Now A[i,j] will have the value 1.
for u := i+1 to m do
subtract A[u,j] * row i from row u
Now A[u,j] will be 0, since A[u,j] - A[i,j] * A[u,j] = A[u,j] - 1 * A[u,j] = 0.
end for
i := i + 1
end if
j := j + 1
end while
矩陣是個好玩的東西,在平面軟件處理的時候,逆矩陣都用來轉換鼠標位置到特定的坐標系,教科書是這么寫的 M' x ( F x M) = M numpy 就很簡單了: from numpy import linalg as LA
form numpy import *
m = mat('1 2 3;4 5 6;7 8 9')
mi = LA.inv(m)
print mi
sdk自帶的ZoomBoxHandler實現的功能地圖的ZoomIn unregisterListeners(),registerListeners() 注冊和注銷與地圖的事件關聯 deactiveDrag()函數禁止map的拖動
每一次zoom之后ZoomBoxHandler就失效,每次都必須點擊ZoomBox按鈕 ZoomBox.mxml定義了觸發按鈕,點擊即刻調用handler.deactiveDrag() 考慮改造這個ZoomBoxHandler的觸發規則,比如檢測下按 [shift/ctrl] 自動進入zoom狀態,[shift]放大,[ctrl]縮小
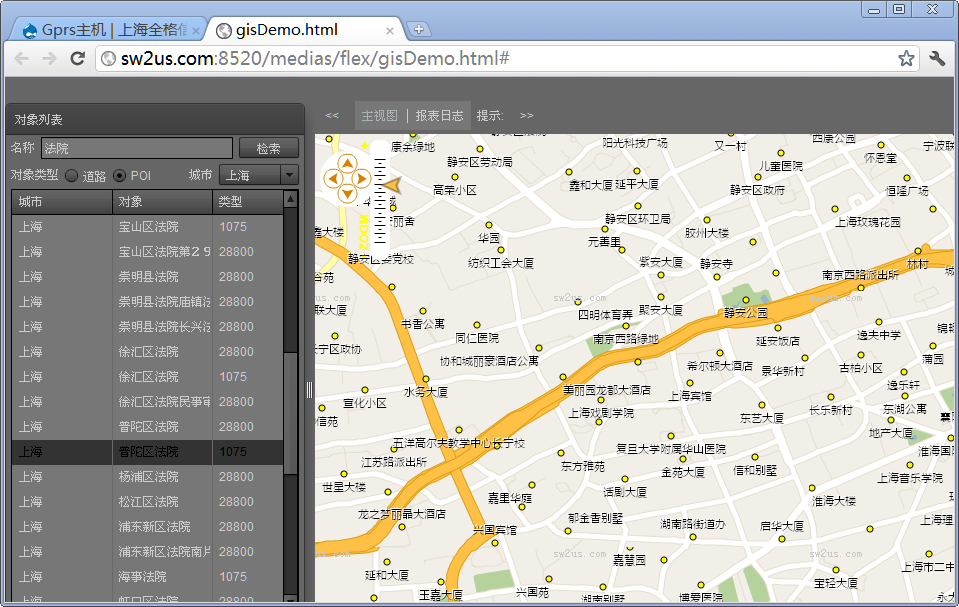
從朋友處得到一份2011年的四維地圖數據,但是數據是未修正偏差的。花了2周時間加工出了效果
有問題請大家指正
截圖 :
有點來不及了,今天開始寫tax金稅開票服務系統的代碼,團購的事情與小風交流之后有點清楚 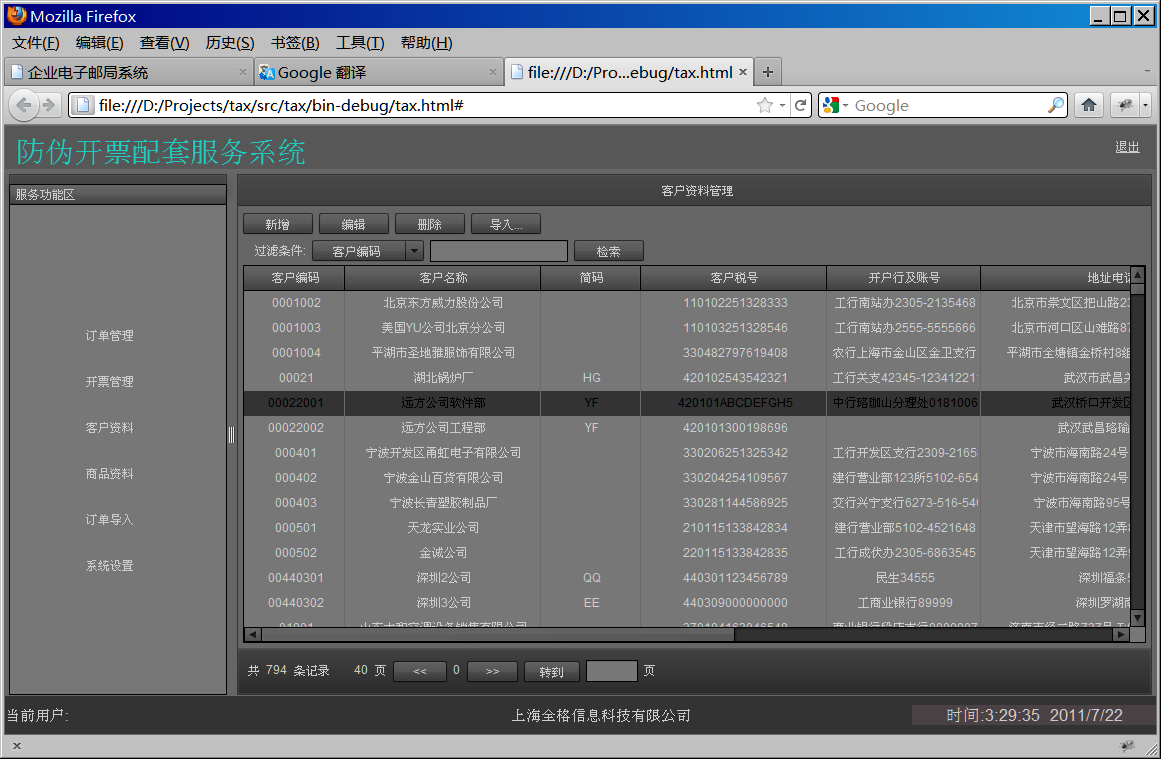
真的自己沒有恒心恐怕要半途而廢了 cxoracle版本與oracle instantclient版本 必須嚴格匹配(花了很多時間)
http://cx-oracle.sourceforge.net/
oracle 10g
cx_Oracle-5.1-10g.win32-py2.6.msi
instantclient-basic-win32-10.2.0.4.zip
解壓instantclient-basic-win32-10.2.0.4.zip ,并將此目錄設置為ORACLE_HOME
將instantclient-basic-win32-10.2.0.4目錄內的dll拷貝到c:\python26\lib\site_packages
運行oracle_test.py測試是否能連接到遠程oracle服務
import cx_Oracle
dsn_tns = cx_Oracle.makedsn('192.168.14.203', 1521,'ORCL') -- ORCL為遠端oracle配置的listener的名稱
print cx_Oracle.connect('tax','tax',dsn_tns)
學習過MapGuid,MapServer,Qgis等多種開源地圖處理服務軟件,開發了遵循WMS標準的地圖服務,包括wms接入,地圖渲染服務。 近1年的時間跑的地圖展示都是wms服務器實時請求TileServer進行繪制,Tileserver進程被部署在一臺高端的服務器上,同時啟動了8個服務進程,訪問忙碌的時候機器有點吃不消,就看到cpu那根線飚的很高。 geoserver這個用java做的wms服務器,性能不敢恭維,玩geoserver的時候接觸了tilecahce這個開源軟件,目前跑啥版本就不清楚了,之前將其研究了個明白,知道自己需要的是什么,所以一切還是得自己寫。 對我來講tilecache不實用的原因有多個: 1.支持過多的cahce 存儲方式,什么google的數據庫,oracle的也有,雖然代碼框架的好,但很多東西都不管用,所以代碼維護不夠靈活 2.tilecache通過apache提供web的wms服務,然后tilecahe里再請求后端的geoserver服務,產生的cache根據他定 義的一個網格依次按x,y,z的索引存儲在文件系統里面,并將圖形進行編碼分類。這種實現并沒有問題,但要知道這些cache出來的圖像文件是那么的多且 都零碎,有些圖片還夠不上一個文件系統基本的一個存儲頁大小,所以會大量浪費空間;由于文件零碎且多,移動這些文件也是個相當大的問題,一次為了將這些 cahce tile文件從A機器拷貝到B機器盡然花費了1天的時間。 tilecache有這些不如我意的地方,所以之前自己也考慮再寫一個tilecache的 backend,將渲染出來的東西直接存儲進pgsql數據庫,那以后只要導出數據庫的tablespace就可以了,嗯!的確可行,也跑了一段時間 最后還是決定放棄tilecahce了,畢竟wms自己已經實現了,要再做個backend也是很簡單,做完直接整合進wms服務器。 我考慮采用sqlite來存儲這些瓦片圖形,由于sqlite處理多線程時天性有點問題,多線程不能共享同一個連接(connection),所以實現的時候在每個線程創建了新的連接,開銷是有一些的,那比之前實時請求TileServer要快的多了。 現在wms跑的很開心了,cpu也不忙了,就是累死了硬盤了 一臺機器上渲染的地圖瓦片數據單獨存儲在一個文件里面,要部署到另外一臺機器也很方便了,只需要拷貝一下就可以了 接著看看將這個sqlite換成pgsql,看看性能哪個更強一點 python代碼實現: 1 def getBitmapTile3(self,renderTile,mapid,res,xy,size):
2 if not self.enable:
3 return None #表示需要實時請求地圖數據
4
5 tile = None
6 dbconn = sqlite3.connect(self.dbname)
7 try:
8 #dbconn.text_factory = str
9 cr = dbconn.cursor()
10 cr.execute('select image from tiles where res=? and x=? and y=?',(res,xy[0],xy[1]))
11 r = cr.fetchone()
12 if not r:
13 tile = renderTile(mapid,res,xy,size)
14 if tile and tile.pixmap:
15 b = sqlite3.Binary(tile.pixmap)
16 print '*'*20
17 cr.execute(u'insert into tiles (res,x,y,z,image) values(?,?,?,?,?)',(res,xy[0],xy[1],0,b))
18 else:
19 tile = r[0]
20 self.cacheshooted+=1
21 print 'shooted ',self.cacheshooted
22 except:
23 traceback.print_exc()
24 tile = None
25 dbconn.commit()
26 return tile
27 記得空的時候在flex端寫個自動跑地圖的程序,不能讓機器閑著,沒事的時候把全國地圖的瓦片自動產生一下,免得在訪問地圖系統的時候再去產生瓦片!
|