實用云計算環境簡述
如今it領域沒聽說過云計算的絕對是out了,雖然大家都知道云計算,雖然很多高校很多專業都開設了云計算專業,雖然很多人都在討論云計算,雖然也有少數人走在了應用云計算的前列,然而,可悲的是,大多數人對云計算的認識僅限于amazon、google、microsoft、ibm有能力架設云計算環境,其他公司都靠邊,甚至唯他們的云計算才叫云計算,別的企業根本不可能做云計算,各級政府部門最搞笑了,動不動花多少錢引進某某云計算環境,填補某某空白,多少cpu多少機器每秒多少萬億次計算,最終是不是一堆浪費電力的擺設也沒有人知道,也沒人去過問。
略感欣慰的是,很多企業都在務實地部署自己的云計算環境,大如騰訊、淘寶、百度、小如我們這樣剛成立的小公司,其實要部署一個私有云計算環境并沒有那么難,以我個人的經驗來看,如果有一個精干的小團隊,幾個人一個月部署一個私有云計算環境是完全可能可行的。在我看來,所謂云計算就是分布式存儲+分布式計算,不局限于底下os是win還是*nix,也不局限于是局域網環境還是廣域網環境,也不管上面跑的是c++的程序還是javascript的程序,下面簡單介紹下我設計的一個即時查詢價格的云計算體系:
我一直在win下開發,win用得非常熟練,所以我把云計算環境部署在windows之上,當然也考慮到windows的機器眾多,tasknode可輕易找到非常多的目標機器,我部署的云計算環境主要分兩類節點,jobserver和tasknode,jobserver主管任務切割、任務調度,tasknode是計算節點。另外還有一些節點,jobowner可連接jobserver并提交任務,并可查詢該任務的執行情況,admin可連接jobserver查詢jobserver的狀態。
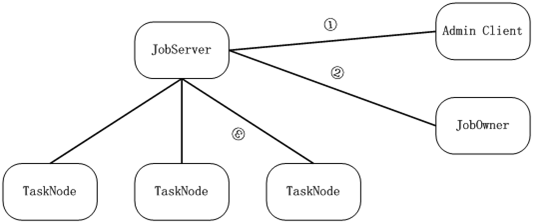
其實這些上篇博客已經寫過,我再講的詳細一點,看具體的執行情況,首先jobowner給jobserver提交package,這個package是一個zip文件,包含一組文件,jobowner提交package之后jobserver會根據約定的規則管理package,并在jobserver展開該package,如下:

Jobowner連到jobserver之后,發出如下的命令到jobserver
0x49 0x0 0x0 0x0 0x2 0x0 0xb 0x0 127.0.0.1 0x0 ppsget.dll 0x0
{type:[0,1,2,3,4],rmax:5,wb:"pc",text:"諾基亞 e63"} 0x0
上面是用我設計的一種混合顯示格式顯示的包數據,可以看到里面帶上了ppsget.dll,這就是指定包內部名,其實還可以這樣ppsget.dll:getpage,如此一個dll就可支持多個IJobTask輸出,getpage只是獲得其中一個IJobTask接口(關于IJobTask接口參考上一篇云計算實踐2的文章)。具體命令是json格式,主要是為了方便信息傳輸和解析。Jobserver接收到該命令之后,調用ppsget.dll的IJobTask接口中的split函數,將該任務分解,之后調度Tasknode執行,tasknode收到jobserver發過來的任務之后,檢查包名稱,如果缺少就會主動向jobserver要求發送相應的包,并進行部署,待部署完成之后從包獲取指定的IJobTask接口,執行該接口的map函數,將結果按照約定的格式發給jobserver,最后由jobserver調用IJobTask中的reduce函數進行打包,最后將結果發給jobowner并記錄相關Log。
上圖中還可看到一個HashCrackCloud.dll,這是另一個云計算環境下破解md5密碼的dll,這個上篇文章也寫了一下,這里就不詳述了。
為使得tasknode可適應各種機器環境,我把tasknode設計為一個dll,該dll內部自己管理消息及任務執行,該dll可被加載到各種容器進程(如gui進程、console進程、service進程)等執行,看下我的tasknode和它的容器進程:
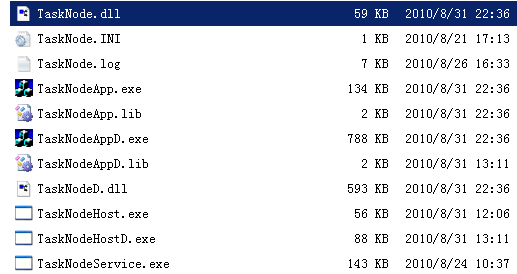
這也算是我的得意設計吧,這樣設計的tasknode在windows系統下的確具有很高的靈活性。
這樣的tasknode甚至可直接加載在jobserver進程,也可被任意win系列機器的任意進程加載參與運算,用主動加載或被動加載都很方便,極大的方便了云計算環境的部署,反正具體執行的任務都由package完成,tasknode只要按照約定的規則部署 package即可,所以這種云計算環境是非常輕量級又非常靈活的,開發一個新的任務只要做一個新的IJobTask即可,目前我這套體系除了沒有考慮太多安全性之外,這個云計算環境的實施還是非常容易的,實際上我們這個價格查詢的后臺云計算環境只用了不到2周的時間就開發完成。
再看下jobserver記錄的每個job的log:

從log中可很容易的分析出一個job每個task的執行情況,并可根據這些數據進行相應的優化處理。
之所以把jobserver和tasknode以及package都寫出來,主要是為了表達一個看法,要實現一個簡單的云計算環境其實并不難,有經驗的團隊很容易就能做出來,參考下google的map/reduce論文,按照自己的需要簡化實現,真理在實踐中,如果只是仰望google、amazon,那就真的是在云中霧里,另一個想要表達的就是云的形式是多種多樣的,并不一定amazone、google的云計算環境才是標準的,對實用派來說,形式都是次要的,實用才是關鍵的。