我的IOCP網(wǎng)絡(luò)模塊設(shè)計
為了設(shè)計一個穩(wěn)定易用高效的iocp網(wǎng)絡(luò)模塊,我前前后后花了好幾個月的時間,也曾閱讀過網(wǎng)上很多資料和代碼,但是非常遺憾,能找到的資料一般都說得很含糊,很少有具體的,能找到的代碼離真正能商用的網(wǎng)絡(luò)模塊差得太遠(yuǎn),大多只是演示一下最基本的功能,而且大多是有很多問題的,主要問題如下:
1、 很多代碼沒有處理一次僅發(fā)送成功部分?jǐn)?shù)據(jù)的情況。
2、 幾乎沒有找到能正確管理所有資源的代碼。
3、 大多沒有采用用pool,有的甚至畫蛇添足用什么map查找對應(yīng)客戶端,沒有充分使用perhandle, perio。
4、 接收發(fā)送數(shù)據(jù)大多拷貝太多次數(shù)。
5、 接收管理大多很低效,沒有充分發(fā)揮iocp能力。
6、 幾乎都沒有涉及上層如何處理邏輯,也沒有提供相應(yīng)解決方案(如合并io線程處理或單獨(dú)邏輯線程)。
7、 大多沒有分離流數(shù)據(jù)和包數(shù)據(jù)。
…
問題還有很多,就不一一列出來了,有一定設(shè)計經(jīng)驗(yàn)的人應(yīng)該有同感。要真正解決這些問題也不是那么容易的,特別是在win下用iocp的時候資源釋放是個麻煩的問題,我在資源管理上花了很多時間,起初也犯了很多錯誤,后來在減少同步對象上又花了不少時間(起初client用了兩個同步對象,后來減少為1個)。下面我就我所設(shè)計的網(wǎng)絡(luò)模塊的各個部分進(jìn)行簡單的講解
一、內(nèi)存管理。
內(nèi)存管理是采用池模式,設(shè)計了一個基礎(chǔ)池類,可以管理某固定大小的池
class CBufferPool
{
…
void *newobj();
void delobj(void *pbuf);
…
};
在基礎(chǔ)池類上提供了一個模板的對象池
template <class T>
class CObjPool : public CBufferPool
{
public:
T *newobj()
{
void *p = CBufferPool::newobj();
T *pt = new(p) T;
return pt;
}
void delobj(T* pt)
{
pt->~T();
CBufferPool::delobj(pt);
}
};
在基礎(chǔ)池的基礎(chǔ)上定義了一個簡單的通用池
class CMemoryPool
{
private:
CBufferPool bp[N];
…
};
通用池是由N個不同大小的基礎(chǔ)池組成的,分配的時候圓整到合適的相近基礎(chǔ)池并由基礎(chǔ)池分配。
最后還提供了一個內(nèi)存分配適配器類,從該類派生的類都支持內(nèi)存池分配。
class t_alloc
{
public:
static void *operator new(size_t size)
{
return CMemoryPool::instance().newobj(size);
}
static void operator delete(void *p, size_t size)
{
CMemoryPool::instance().delobj(p, size);
}
};
根據(jù)測試CMempool分配速度比CObjpool<>稍微慢一點(diǎn)點(diǎn),所以我在用的時候就直接用t_alloc類派生,而不是用對象池,這是個風(fēng)格問題,也許有很多人喜歡用更高效一點(diǎn)的objpool方式,但這個并不大礙。
在網(wǎng)絡(luò)模塊中OVERLAPPED派生類就要用池進(jìn)行分配,還有CIocpClient也要用池分配,再就是CBlockBuffer也是從池分配的。
如下定義:
struct IOCP_ACCEPTDATA : public IOCP_RECVDATA, public t_alloc
class CIocpClient : public t_alloc
二、數(shù)據(jù)緩沖區(qū)。
數(shù)據(jù)緩沖區(qū)CBlockBuffer為環(huán)形,大小不固定,隨便分配多少,主要有以下幾個元素:
Char *pbase; //環(huán)形首部
Char *pread; //當(dāng)前讀指針
Char *pwrite; //當(dāng)前寫指針
Int nCapacity; //緩沖區(qū)大小
Long nRef; //關(guān)聯(lián)計數(shù)器
用這種形式管理緩沖區(qū)有很多好處,發(fā)送數(shù)據(jù)的時候如果只發(fā)送了部分?jǐn)?shù)據(jù)只要修改pread指針即可,不用移動數(shù)據(jù),接收數(shù)據(jù)并處理的時候如果只處理了部分?jǐn)?shù)據(jù)也只要修改pread指針即可,有新數(shù)據(jù)到達(dá)后直接寫到pwrite并修改pwrite指針,不用多次拷貝數(shù)據(jù)。nRef關(guān)聯(lián)計數(shù)還可處理一個包發(fā)給N個人的問題,如果要給N個人發(fā)送相同的包,只要分配一個緩沖區(qū),并設(shè)置nRef為N就可以不用復(fù)制N份。
三、收發(fā)緩沖區(qū)管理
發(fā)送緩沖區(qū)
我把CIocpClient的發(fā)送數(shù)據(jù)設(shè)計為一個CBlockBuffer 的隊列,如果隊列內(nèi)有多個則WSASend的時候一次發(fā)送多個,如果只有一個則僅發(fā)送一個,CIocpClient發(fā)送函數(shù)提供了兩個,分別是:
Bool SendData(char *pdata, int len);
Bool SendData(CBlockBuffer *pbuffer);
第一個函數(shù)會檢測發(fā)送鏈的最后一個數(shù)據(jù)塊能否容納發(fā)送數(shù)據(jù),如果能復(fù)制到最后一個塊,如果不能則分配一個CBlockBuffer掛到發(fā)送鏈最后面,當(dāng)然這個里面要處理同步。
接收緩沖區(qū)
接收管理是比較簡單的,只有一個CBlockBuffer,WSARecv的時候直接指向CBlockBuffer->pwrite,所以如果塊大小合適的話基本上是不用拼包的,如果一次沒有收到一個完整的數(shù)據(jù)包,并且塊還有足夠空間容納剩余空間,那么再提交一個WSARecv讓起始緩沖指向CBlockBuffer->pwrite如此則收到一個完整數(shù)據(jù)包的過程都不用重新拼包,收到一個完整數(shù)據(jù)包之后可以調(diào)用虛函數(shù)讓上層進(jìn)行處理。
在IocpClient層其實(shí)是不支持?jǐn)?shù)據(jù)包的,在這個層次只有流的概念,這個后面會專門講解。
四、IocpServer的接入部分管理
我把IocpServer設(shè)計為可以支持打開多個監(jiān)聽端口,對每個監(jiān)聽端口接入用戶后調(diào)用IocpServer的虛函數(shù)分配客戶端:
virtual CIocpClient *CreateNewClient(int nServerPort)
分配客戶端之后會調(diào)用IocpClient的函數(shù) virtual void OnInitialize();分配內(nèi)部接收和發(fā)送緩沖區(qū),這樣就可以根據(jù)來自不同監(jiān)聽端口的客戶端分配不同的緩沖區(qū)和其他資源。
Accept其實(shí)是個可以有很多選擇的,最簡單的做法可以用一個線程+accept,當(dāng)然這個不是高效的,也可以采用多個線程的領(lǐng)導(dǎo)者-追隨者模式+accept實(shí)現(xiàn),還可以是一個線程+WSAAccept,或者多個線程的領(lǐng)導(dǎo)者-追隨者模式+WSAAccept模式,也可以采用AcceptEx模式,我是采用AcceptEx模式做的,做法是有接入后投遞一個AcceptEx,接入后重復(fù)利用此OVERLAPPED再投遞,這樣即使管理大量連接也只有起初的幾十個連接會分配 OVERLAPPED后面的都是重復(fù)利用前面分配的結(jié)構(gòu),不會導(dǎo)致再度分配。
IocpServer還提供了一個虛函數(shù)
virtual bool CanAccept(const char *pip, int port){return true;}
來管理是否接入某個ip:port 的連接,如果不接入直接會關(guān)閉該連接并重復(fù)利用此前分配的WSASocket。
五、資源管理
Iocp網(wǎng)絡(luò)模塊最難的就是這個了,什么時候客戶端關(guān)閉或服務(wù)器主動關(guān)閉某個連接并收回資源,這是最難處理的問題,我嘗試了幾種做法,最后是采用計數(shù)器管理模式,具體做法是這樣的:
CIocpClient有2個計數(shù)變量
volatile long m_nSending; //是否正發(fā)送中
volatile long m_nRef; //發(fā)送接收關(guān)聯(lián)字
m_nSending表示是否有數(shù)據(jù)已WSASend中沒有返回
m_nRef表示WSASend和WSARecv有效調(diào)用未返回和
在合適的位置調(diào)用
inline void AddRef(const char *psource);
inline void Release(const char *psource);
增引用計數(shù)和釋放引用計數(shù)
if(InterlockedDecrement(&m_nRef)<=0)
{
//glog.print("iocpclient %p Release %s ref %d\r\n", this, psource, m_nRef);
m_server->DelClient(this);
}
當(dāng)引用計數(shù)減少到0的時候刪除客戶端(其實(shí)是將內(nèi)存返回給內(nèi)存池)。
六、鎖使用
鎖的使用至關(guān)重要,多了效率低下,少了不能解決問題,用多少個鎖在什么粒度上用鎖也是這個模塊的關(guān)鍵所在。
IocpClient有一個鎖 DECLARE_SIGNEDLOCK_NAME(send); //發(fā)送同步鎖
這個鎖是用來控制發(fā)送數(shù)據(jù)鏈管理的,該鎖和前面提到的volatile long m_nSending;共同配合管理發(fā)送數(shù)據(jù)鏈。
可能有人會說recv怎么沒有鎖同步,是的,recv的確沒有鎖,recv不用鎖是為了最大限度提高效率,如果和發(fā)送共一個鎖則很多問題可以簡化,但沒有充分發(fā)揮iocp的效率。Recv接收數(shù)據(jù)后就調(diào)用OnReceive虛函數(shù)進(jìn)行處理。可以直接io線程內(nèi)部處理,也可以提交到某個隊列由獨(dú)立的邏輯線程處理。具體如何使用完全由使用者決定,底層不做任何限制。
七、服務(wù)器定時器管理
服務(wù)器定義了如下定時器函數(shù),利用系統(tǒng)提供的時鐘隊列進(jìn)行管理。
bool AddTimer(int uniqueid, DWORD dueTime, DWORD period, ULONG nflags=WT_EXECUTEINTIMERTHREAD);
bool ChangeTimer(int uniqueid, DWORD dueTime, DWORD period);
bool DelTimer(int uniqueid);
//獲取Timers數(shù)量
int GetTimerCount() const;
TimerIterator GetFirstTimerIterator();
TimerNode *GetNextTimer(TimerIterator &it);
bool IsValidTimer(TimerIterator it)
設(shè)計思路是給每個定時器分配一個獨(dú)立的id,根據(jù)id可修改定時器的首次觸發(fā)時間和后續(xù)每次觸發(fā)時間,可根據(jù)id刪除定時器,也可遍歷定時器。定時器時間單位為毫秒。
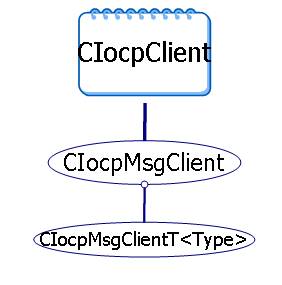
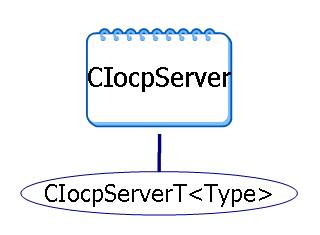
八、模塊類結(jié)構(gòu)
模塊中最重要的就是兩個類CIocpClient和CIocpServer,其他有幾個類從這兩個類派生,圖示如下:
|
 圖表 1 圖表 1
|
 圖表 2 圖表 2
|
CIocpClient是完全流式的,沒有包概念。CIocpMsgClient從CIocpClient派生,內(nèi)部支持包概念:
class CIocpMsgClient : public CIocpClient
{
…
virtual void OnDataTooLong(){};
virtual void OnMsg(PKHEAD *ph){};
bool SendMsg(WORD mtype, WORD stype, const char *pdata, int length);
…
};
template <class TYPE>
class CIocpMsgClientT : public CIocpMsgClient
{
…
void AddMsg(DWORD id, CBFN pfn);
BOOL DelMsg(DWORD id);
…
};
CIocpMsgClientT模板類支持內(nèi)嵌入式定義,如在
CMyDoc中可這樣定義
CIocpMsgClientT<CMyDoc> client;
后面可以調(diào)用client.AddMsg(UMSG_LOGIN, OnLogin);關(guān)聯(lián)一個類成員函數(shù)作為消息處理函數(shù),使用很方便。
CIocpServerT定義很簡單,從CIocpServer派生,重載了CreateNewClient函數(shù)
template <class TClient>
class CIocpServerT : public CIocpServer
{
public:
//如果CIocpClient派生了則也需要重載下面的函數(shù),這里可以根據(jù)nServerPort分配不同的CIocpClient派生類
virtual CIocpClient *CreateNewClient(int nServerPort)
{
CIocpClient *pclient = new TClient;
…
return pclient;
}
};
八、應(yīng)用舉例
class CMyClient : public CIocpMsgClient
{
public:
CMyClient() : CIocpMsgClient()
{
}
virtual ~CMyClient()
{
}
virtual void OnConnect()
{
Printf(“用戶連接%s:%d連接到服務(wù)器\r\n”, GetPeerAddr().ip(),GetPeerAddr().port());
}
virtual void OnClose()
{
Printf(“用戶%s:%d關(guān)閉連接\r\n”, GetPeerAddr().ip(),GetPeerAddr().port());
}
virtual void OnMsg(PKHEAD *phead)
{
SendData((const char *)phead, phead->len+PKHEADLEN);
}
virtual void OnSend(DWORD dwbyte)
{
Printf(“成功發(fā)送%d個字符\r\n”, dwbyte);
}
virtual void OnInitialize()
{
m_sendbuf = newbuf(1024);
m_recvbuf = newbuf(4096);
}
friend class CMyServer;
};
class CMyServer : public CIocpServer
{
public:
CMyServer() : CIocpServer
{
}
virtual void OnConnect(CIocpClient *pclient)
{
printf("%p : %d 遠(yuǎn)端用戶%s:%d連接到本服務(wù)器.\r\n", pclient, pclient->m_socket,
pclient->GetPeerAddr().ip(), pclient->GetPeerAddr().port());
}
virtual void OnClose(CIocpClient *pclient)
{
printf("%p : %d 遠(yuǎn)端用戶%s:%d退出.\r\n", pclient, pclient->m_socket,
pclient->GetPeerAddr().ip(), pclient->GetPeerAddr().port());
}
virtual void OnTimer(int uniqueid)
{
If(uniqueid == 10)
{
}
Else if(uniqueid == 60)
{
}
}
//這里可以根據(jù)nServerPort分配不同的CIocpClient派生類
virtual CIocpClient *CreateNewClient(int nServerPort)
{
// If(nServerPort == ?)
// …
CIocpClient *pclient = new CMyClient;
…
return pclient;
}
};
Int main(int argc, char *argv[])
{
CMyServer server;
server.AddTimer(60, 10000, 60000);
server.AddTimer(10, 10000, 60000);
//第二個參數(shù)為0表示使用默認(rèn)cpu*2個io線程,>0表示使用該數(shù)目的io線程。
//第三個參數(shù)為0表示使用默認(rèn)cpu*4個邏輯線程,如果為-1表示不使用邏輯線程,邏輯在io線程內(nèi)計算。>0則表示使用該數(shù)目的邏輯線程
server.StartServer("1000;2000;4000", 0, 0);
}
從示例可看出,對使用該網(wǎng)絡(luò)模塊的人來說非常簡單,只要派生兩個類,集中精力處理消息函數(shù)即可,其他內(nèi)容內(nèi)部全部包裝了。
九、后記
我研究iocp大概在2005年初,前一個版本的網(wǎng)絡(luò)模塊是用多線程+異步事件來做的,iocp網(wǎng)絡(luò)模塊基本成型在2005年中,后來又持續(xù)進(jìn)行了一些改進(jìn),2005底進(jìn)入穩(wěn)定期,2006年又做了一些大的改動,后來又持續(xù)進(jìn)行了一些小的改進(jìn),目前該模塊作為服務(wù)程序框架已經(jīng)在很多項(xiàng)目中穩(wěn)定運(yùn)行了1年半左右的時間。在此感謝大寶、Chost Cheng、Sunway等眾多網(wǎng)友,是你們的討論給了我靈感和持續(xù)改進(jìn)的動力,也是你們的討論給了我把這些寫出來的決心。若此文能給后來者們一點(diǎn)點(diǎn)啟示我將甚感欣慰,若有錯誤歡迎批評指正。
oldworm
oldworm@21cn.com
2007.9.24