protobuf簡介
protobuf是google提供的一個開源序列化框架,類似于XML,JSON這樣的數據表示語言,其最大的特點是基于二進制,因此比傳統的XML表示高效短小得多。雖然是二進制數據格式,但并沒有因此變得復雜,開發人員通過按照一定的語法定義結構化的消息格式,然后送給命令行工具,工具將自動生成相關的類,可以支持java、c++、python等語言環境。通過將這些類包含在項目中,可以很輕松的調用相關方法來完成業務消息的序列化與反序列化工作。
protobuf在google中是一個比較核心的基礎庫,作為分布式運算涉及到大量的不同業務消息的傳遞,如何高效簡潔的表示、操作這些業務消息在google這樣的大規模應用中是至關重要的。而protobuf這樣的庫正好是在效率、數據大小、易用性之間取得了很好的平衡。
更多信息可參考官方文檔
例子介紹
先下載protobuf-2.3.0.zip源代碼庫,下載后解壓,選擇vsprojects目錄下的protobuf.sln解決方案打開,編譯整個方案順利成功。其中有一些測試工程,庫相關的工程是libprotobuf、libprotobuf-lite、libprotoc和protoc。其中protoc是命令行工具。在example目錄下有一個地址薄消息的例子,業務消息的定義文件后綴為.proto,其中的addressbook.proto內容為:
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person person = 1;
}
該定義文件,定義了地址薄消息的結構,頂層消息為AddressBook,其中包含多個Person消息,Person消息中又包含多個PhoneNumber消息。里面還定義了一個PhoneType的枚舉類型。
類型前面有required表示必須,optional表示可選,repeated表示重復,這些定義都是一目了然的,無須多說。關于消息定義的詳細語法可參考官方文檔。
現在用命令行工具來生成業務消息類,切換到protoc.exe所在的debug目錄,在命令行敲入:
protoc.exe --proto_path=..\..\examples --cpp_out=..\..\examples ..\..\examples\addressbook.proto
該命令中--proto_path參數表示.proto消息定義文件路徑,--cpp_out表示輸出c++類的路徑,后面接著是addressbook.proto消息定義文件。該命令會讀取addressbook.proto文件并生成對應的c++類頭文件和實現文件。執行完后在examples目錄生存了addressbook.pb.h和addressbook.pb.cpp。
現在新建兩個空控制臺工程,第一個不妨叫AddPerson,然后把examples目錄下的add_person.cc、addressbook.pb.h和addressbook.pb.cpp加入到該工程,另一個工程不妨叫ListPerson,將examples目錄下的list_people.cc、addressbook.pb.h和addressbook.pb.cpp加入到該工程,在兩個工程的項目屬性中附加頭文件路徑../src。兩個工程的項目依賴都選擇libprotobuf工程(庫)。
給AddPerson工程添加一個命令行參數比如叫addressbook.dat用于將地址薄信息序列化寫入該文件,然后編譯運行AddPerson工程,根據提示輸入地址薄信息:
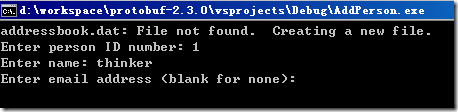
輸入完成后,將序列化到addressbook.dat文件中。
在ListPerson工程的命令行參數中加讀取文件參數..\AddPerson\addressbook.dat,然后在運行ListPerson工程,可在 list_people.cc的最后設個斷點,避免命令行窗口運行完后關閉看不到結果:
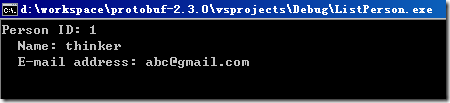
寫入地址薄的操作,關鍵操作就是調用address_book.SerializeToOstream進行序列化到文件流。
而讀取操作中就是address_book.ParseFromIstream從文件流反序列化,這都是框架自動生成的類中的方法。
其他操作都是業務消息的字段set/get之類的對象級操作,很明了。更詳細的API參考官方文檔有詳細說明。
在TCP網絡編程中的考慮
從上面的例子可以看出protobuf這樣的庫是很方便高效的,那么自然的想到在網絡編程中用來做業務消息的序列化、反序列化支持。在基于UDP協議的網絡應用中,由于UDP本身是有邊界,那么用protobuf來處理業務消息就很方便。但在TCP應用中,由于TCP協議沒有消息邊界,這就需要有一種機制來確定業務消息邊界。在TCP網絡編程中這是必須面對的問題。
注意上面的address_book.ParseFromIstream調用,如果流參數的內容多一個字節或者少一個字節,該方法都會返回失敗(雖然某些字段可能正確得到結果了),也就是說送給反序列化的數據參數除了格式正確還必須有正確的大小。因此在tcp網絡編程中,要反序列化業務消息,就要先知道業務數據的大小。而且在實際應用中可能在一個發送操作中,發送多個業務消息,而且每個業務消息的大小、類型都不一樣。而且可能發送很大的數據流,比如文件。
顯然消息邊界的確認問題和protobuf庫無關,還得自己搞定。在官方文檔中也提到,protobuf并不太適合來作大數據的處理,當業務消息超過1M時,就應該考慮是否應該用另外的替代方案。當然對于大數據,你也可以分割為多個小塊用protobuf做小塊消息封裝進行傳遞。但對很多應用這樣的作法顯得比較多余,比如發送一個大的文件,一般是在接收方從協議棧收到多少數據就寫多少數據到磁盤,這是一種邊接收邊處理的流模式,這種模式基本上和每次收到的數據量沒有關系。這種模式下再采用分割成小消息進行反序列化就顯得多此一舉了。
由于每個業務消息的大小和處理方式都可能不一樣,那么就需要獨立抽象出一個邊界消息來區分不同的業務消息,而且這個邊界消息的格式和大小必須固定。對于網絡編程熟手,可能早已經想到了這樣的消息,我們可以結合protobuf庫來定義一個邊界消息,不妨叫BoundMsg:
message BoundMsg
{
required int32 msg_type = 1;
required int32 msg_size = 2;
}
可以根據需要擴充一些字段,但最基本的這兩個字段就夠用了。我們只需要知道業務消息的類型和大小即可。這個消息大小是固定的8字節,專門用來確定數據流的邊界。有了這樣的邊界消息,在接收端處理任何業務消息就很靈活方便了,下面是接收端處理的簡單偽代碼示例:
if(net_read(buf,8))
{
boundMsg.ParseFromIstream(buf);
switch(boundMsg.msg_type)
{
case BO_1:
if(net_read(bo1Buf,boundMsg.msg_size))
{
bo1.ParseFromIstream(bo1Buf);
....
}
break;
case BO_2:
if(net_read(bo2Buf,boundMsg.msg_size))
{
bo2.ParseFromIstream(bo2Buf);
....
}
break;
case FILE_DATA:
count = 0;
while(count < boundMsg.msg_size)
{
piece_size = net_read(fileBuf,1024);
write_file(filename,fileBuf,piece_size);
count = count + piece_size;
}
break;
}
}
注意上面如果FILE_DATA消息后,還緊接其他業務消息的話,需要小心,即count累計出的值可能大于
boundMsg.msg_size的值,那么多出來的實際上應該是下一個邊界消息數據了。為了避免處理的復雜性,上面所有的循環網絡讀取操作(上面BO_1,BO_2都可能需要循環讀取,為了簡化沒有寫成循環)的緩沖區位置和大小參數應該動態調整,即每次讀取時傳遞的都是還期望讀取的數據大小,對于文件的話,可能特殊點,因為邊讀取邊寫入,就沒有必要事先要分配一個文件大小的緩沖區來存放數據了。對于文件分配一個小緩沖區來讀,注意確認下邊界即可。
上面是我的一點考慮,不妥之處還請大家討論交流。想想借助于ACE、MINA這樣的網絡編程框架,然后結合protobuf這樣的序列化框架,網絡編程中技術基礎設施層面的東西就給我們解決得差不多了,我們可以真正只關注于業務的實現。