程序是如何運行的作為一個程序員,已不知編了多少行代碼。但若問我程序是如何在計算機中運行的,我怕只有張口結舌。書中第一章就給了我們相關的答案。
首先,看如下最簡單的C語言Helloword的代碼
1 #include <stdio.h>
#include <stdio.h>
2
3int main()
4

 {
{
5 printf("hello, world\n");
printf("hello, world\n");
6 }
}
上面的代碼我們保存在helloworld.c文件中。其本質實際上是由0、1的比特(位)序列構成的。8位為一個字節。每個字節對應某個文本字符。不少系統用ASCII來表示文本字符。實際是由一個唯一的同字節大小的整數值來表示每個字符。下面給出helloworld.c的ASCII表示。
# i n c l u d e <sp> < s t d i o .
35 105 110 99 108 117 100 101 32 60 115 116 100 105 111 46
h > \n \n i n t <sp> m a i n ( ) \n {
104 62 10 10 105 110 116 32 109 97 105 110 40 41 10 123
\n <sp> <sp> <sp> <sp> p r i n t f ( " h e l
10 32 32 32 32 112 114 105 110 116 102 40 34 104 101 108
l o , <sp> w o r l d \ n " ) ; \n }
108 111 44 32 119 111 114 108 100 92 110 34 41 59 10 125
以此類推,在計算機系統中,任何介質中的數據都是比特序列。把他們區分成不同的數據對象,是通過數據對象的上下文來確定的。
程序編譯程序的編譯過程如下圖所示,分為預處理、編譯、匯編、鏈接等幾個階段。
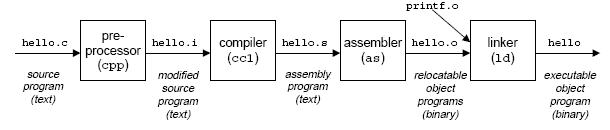
預處理:預處理相當于根據預處理命令組裝成新的C程序,不過常以i為擴展名。
編譯: 將得到的i文件翻譯成匯編代碼。s文件。
匯編: 將匯編文件翻譯成機器指令,并打包成可重定位目標程序的O文件。該文件是二進制文件,字節編碼是機器指令。
鏈接: 將引用的其他O文件并入到我們程序所在的o文件中,處理得到最終的可執行文件。
硬件組成:從下圖中看出一個典型的系統由總線、Cpu、I/O設備、主存等構成。
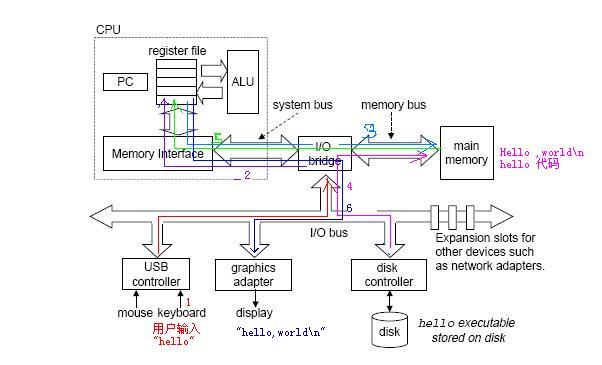
CPU: Central Processing Unit, ALU: Arithmetic/Logic Unit, PC: Program counter, USB: Universal Serial Bus.
程序執行
我們已經討論了可執行文件產生的過程。接下來討論哈可執行文件執行的過程。從上面途中的彩色線條可以清晰的看到這個過程,我們簡單的把它分為6步。
1.shell程序執行指令,等待用戶輸入,這里我們輸入“hello”。
2.shell程序將字符逐一讀到寄存器中
3.再從寄存器取出放到主存中
4.當我們敲入回車時,shell程序得知輸入結束,將hello目標文件的代碼和數據拷貝到主存,從而加載hello文件數據包括最終被輸出的字符串“hello,world\n”.利用了DMA訪問技術,數據可不經CPU直接到主存
5.執行主程序中的機器語言指令,將“hello,world\n”串的字節從主存拷貝到寄存器堆。
6.從寄存器中把文件拷貝到顯示設備。